 夜雨聆风
夜雨聆风





【Claude Code源码杂谈(1)】使用轻量模型节约agent成本
- 2026年4月4日
【Claude Code源码杂谈(1)】使用轻量模型节约agent成本
📌 注:本文所有成本数据基于代码中硬编码的标准定价(来自
src/utils/modelCost.ts),源自官方定价文档。实际定价可能会随时间变化,最新定价请参考platform.claude.com/docs/en/about-claude/pricing
Claude Code 采用 多层级模型架构,根据不同的计算场景使用不同性能的模型。
Haiku 4.5 作为轻量级模型,在以下关键场景中被系统性地使用:
-
成本驱动 的边缘任务
Web Search、Token Counting
-
低延迟 的实时反馈任务
Away Summary、Session Search
-
高吞吐 的后台工作
Rate Limit Processing
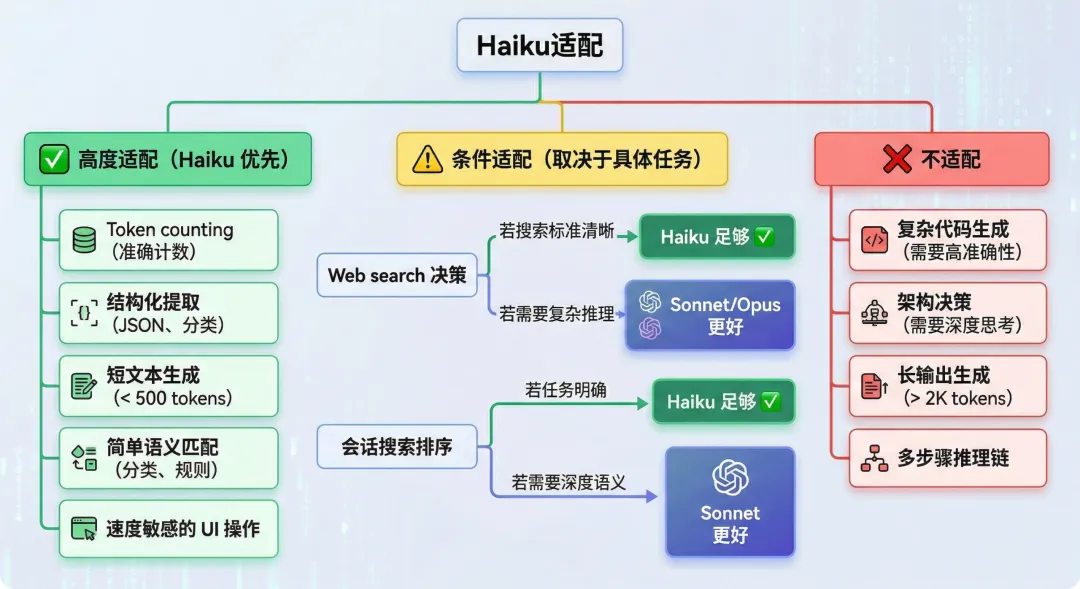
Claude Code中Haiku 4.5 的核心使用场景
1️⃣:Web Search Tool 的快速执行
触发条件:Feature Flag tengu_plum_vx3 启用时
tengu_plum_vx3是一个功能开关,用于控制 WebSearchTool 是否使用 Haiku。
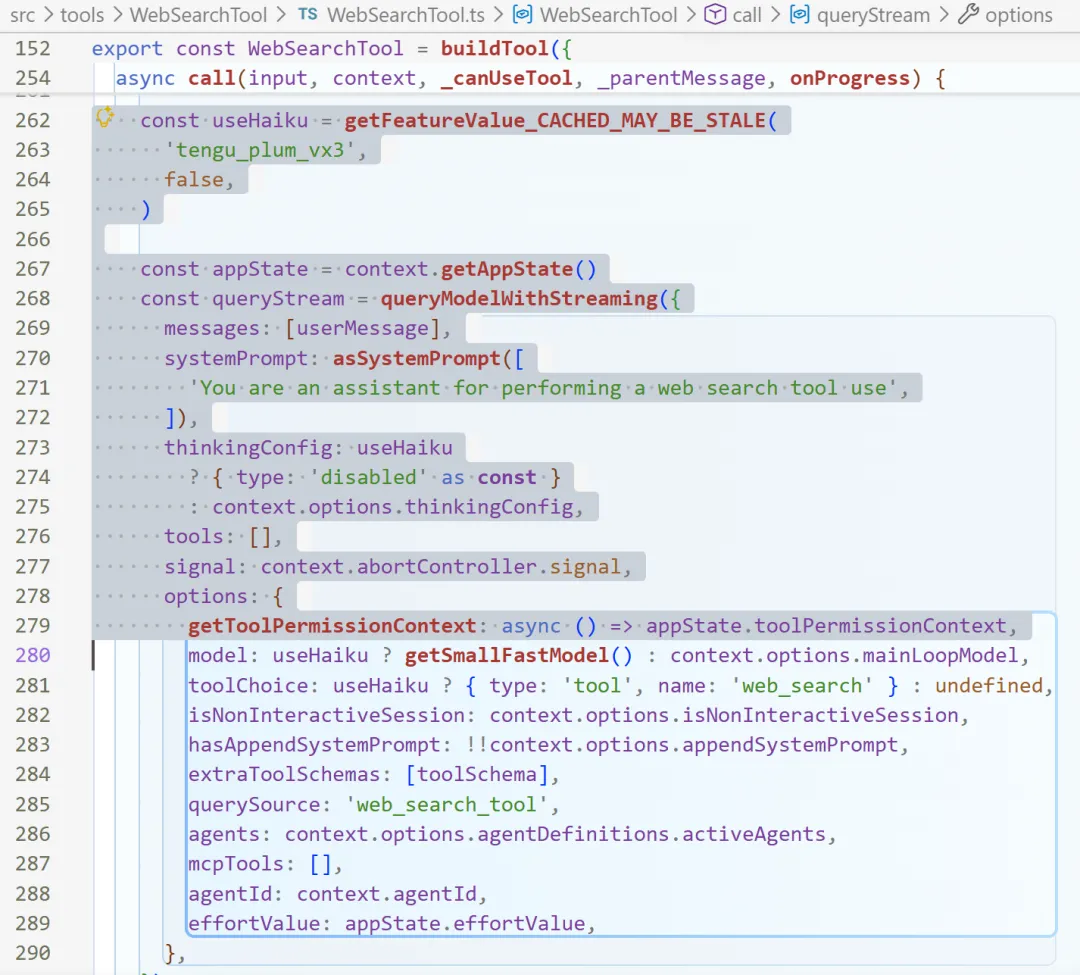
-
useHaiku = true时:使用getSmallFastModel()进行网络搜索,禁用思考配置 (thinkingConfig: disabled) -
useHaiku = false时:使用常规主模型 (context.options.mainLoopModel)
Web 搜索不需要复杂推理,这个标志可让网络搜索操作更轻量、更快速/低成本 。
2️⃣:Token Counting Fallback
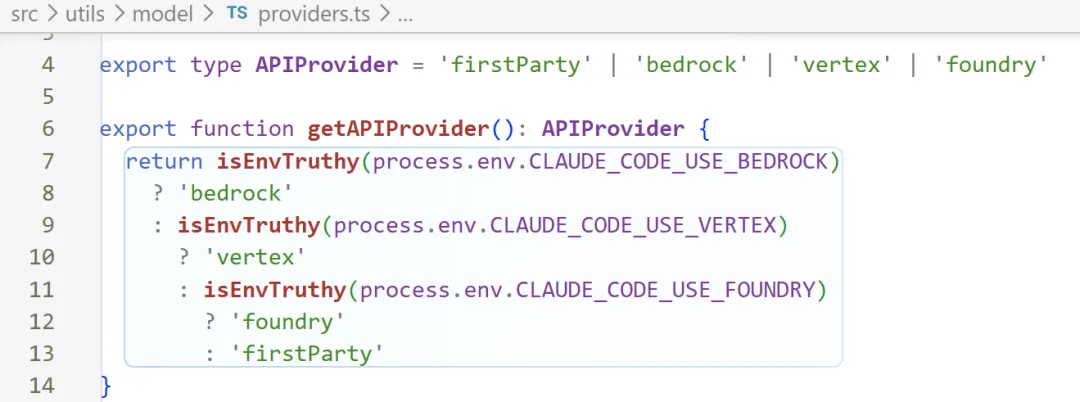
目前支持的api provider:
|
|
|
|
|---|---|---|
firstParty |
|
|
bedrock |
|
|
vertex |
|
|
foundry |
|
|
而较为准确的token使用情况有以下作用:
-
当上下文使用量 > 阈值 → 自动压缩对话历史
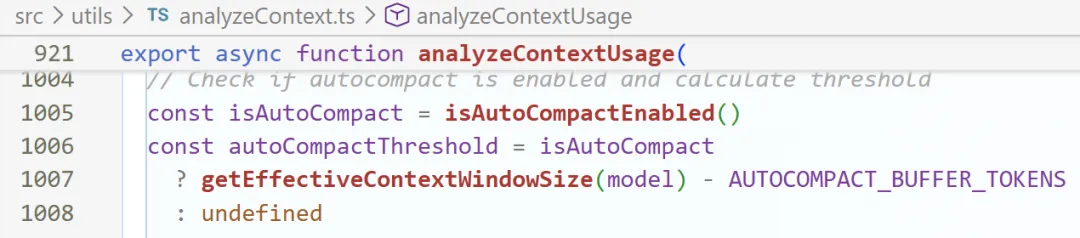
-
用户可以在UI上直观查看上下文使用状态
-
防止超过 Context Window
如果 token 计数不准确,可能:
-
发送超过 200k tokens 的请求 → API 报错 -
或者压缩时机不对 →不知道用了多少,就没法决定什么时候该压缩。导致 上下文被意外截断
为什么此处需要haiku:
-
Anthropic 直连 API 有
countTokens()支持 -
AWS Bedrock 的
CountTokensCommand支持 -
Google Vertex 有 beta 支持
但 Bedrock 有些情况下 countTokens 不可用,可能返回 null
countTokensWithFallback (analyzeContext.ts:77)
├─ countMessagesTokensWithAPI (tokenEstimation.ts:140)
│ ├─ Bedrock → countTokensWithBedrock (可能返回 null)
│ └─ 其他 → anthropic.beta.messages.countTokens
│
└─ (如果上面返回 null) → countTokensViaHaikuFallback (tokenEstimation.ts:251)
└─ 实际调用 Haiku 模型 + 统计 usage.input_tokens
async function countTokensWithFallback(
messages: Anthropic.Beta.Messages.BetaMessageParam[],
tools: Anthropic.Beta.Messages.BetaToolUnion[],
): Promise<number | null> {
try {
// 第一优先级:用 native API 计数
const result = await countMessagesTokensWithAPI(messages, tools)
if (result !== null) return result
} catch (err) { /* ... */ }
try {
// 第二优先级:Haiku fallback(成本最低)
const fallbackResult = await countTokensViaHaikuFallback(messages, tools)
return fallbackResult
} catch (err) { /* ... */ }
// 最后手段:粗略估算(不调用 API)
return roughTokenCountEstimation(content)
}
Haiku Fallback 通过发送 max_tokens=1 的虚假请求,最小化成本,来从response.usage.input_tokens 读取实际 token 数
export async function countTokensViaHaikuFallback(
messages: Anthropic.Beta.Messages.BetaMessageParam[],
tools: Anthropic.Beta.Messages.BetaToolUnion[],
): Promise<number | null> {
const model =
getVertexRegionForModel(getSmallFastModel()) === 'global'
? getDefaultSonnetModel() // Vertex global 不支持 Haiku
: hasThinkingBlocks(messages) && getAPIProvider() === 'bedrock'
? getDefaultSonnetModel() // Bedrock 的 Haiku 3.5 不支持 thinking
: getSmallFastModel() // 其他情况用 Haiku 4.5
// 关键技巧:发送 max_tokens=1 的虚假请求
const response = await queryModel({
model,
messages,
tools,
max_tokens: 1, // 最小化成本:不会实际输出任何 tokens
})
// 从 response.usage.input_tokens 读取实际 token 数
return response.usage.input_tokens
}
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
3️⃣:离线会话摘要
用户长时间离开后,生成”用户回来时”的快速摘要卡片
export async function generateAwaySummary(
messages: readonly Message[],
signal: AbortSignal,
): Promise<string | null> {
const memory = await getSessionMemoryContent()
// 只取最近 30 条消息(≈15 轮对话)
const recent = messages.slice(-30)
const response = await queryModelWithoutStreaming({
model: getSmallFastModel(), // ← Haiku 4.5
thinkingConfig: { type: 'disabled' },
systemPrompt: [],
messages: [
...recent,
createUserMessage({
content: `用户离开了。写 1-3 句话总结:
1) 高层任务(他们在构建/调试什么)
2) 下一个具体步骤
忽略实现细节和 commit 摘要。`,
}),
],
// ...
})
return extractMessageText(response)
}
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
而Haiku 推理快速,成本低,足以生成短文本摘要
4️⃣:会话历史搜索
帮助用户快速找到相关的历史对话
export async function agenticSessionSearch(
query: string,
logs: LogOption[],
signal?: AbortSignal,
): Promise<LogOption[]> {
// 第一轮:快速 grep 过滤
const matchingLogs = logs.filter(log =>
logContainsQuery(log, query.toLowerCase())
)
// 第二轮:用 AI 进行语义重排序
const userMessage = `Sessions:
${sessionList}
Search query: "${query}"
Find the sessions most relevant to this query.`
const response = await queryModel({
model: getSmallFastModel(), // ← Haiku 4.5
messages: [{ role: 'user', content: userMessage }],
max_tokens: 256,
})
// 解析 AI 返回的排序结果
return parseRelevantSessions(response)
}
5️⃣:Rate Limit 降级处理
Claude.ai 用户有强制 rate limits(5 hour / 7 day)
export async function checkClaudeAIRateLimits(): Promise<ClaudeAILimits> {
try {
// 发送最小化请求以获取 rate limit 头信息
const model = getSmallFastModel() // Haiku 4.5
const response = await queryModel({
model,
messages: [{ role: 'user', content: '.' }],
max_tokens: 1,
})
// 从响应头读取 rate limit 信息
const utilization = parseHeaders(response.headers)
return {
status: utilization > 0.9 ? 'limited' : 'allowed',
utilization,
}
} catch (error) {
// ...处理错误
}
}
6️⃣:权限决策中的安全分类(Bash 权限检查)
文件位置:docs/safety/why-safety-matters.mdx
Bash 命令执行前需通过 5 层权限检查
Layer 1: AST 解析(tree-sitter) ← 不用 AI
Layer 2: 精确规则匹配 ← 不用 AI
Layer 3: 分类器检查
↓
用 Haiku 对 deny/ask 规则进行语义匹配
Layer 4: 沙箱虚拟化 ← 不用 AI
Layer 5: Hooks & 预算 ← 不用 AI
Haiku 在权限中的角色:
// 用户定义规则(来自配置):
const denyRules = [
"避免访问 /etc/passwd",
"阻止向 AWS 发送 sensitive 数据"
]
// Bash 命令:bash("grep admin /var/log/auth.log")
// 步骤 1-2 失败(不是字面上的 /etc/passwd,有文件读权限)
//
// 步骤 3:用 Haiku 做语义检查
const semanticMatch = await queryModel({
model: getSmallFastModel(), // Haiku 4.5
messages: [{
role: 'user',
content: `规则:"${denyRules[0]}"
命令:"grep admin /var/log/auth.log"
命令是否违反规则?(yes/no)`
}],
max_tokens: 10,
})
// 返回:"no" - 因为 /var/log/auth.log ≠ /etc/passwd
// 命令被允许
为什么这里用 Haiku:
-
关键时刻:安全决策,必须准确 -
Haiku 能力足够:规则匹配是 LLM 的强项 -
成本极低:每次检查 < $0.000001 -
延迟包容:安全检查可接受 100-200ms 延迟
附录:模型定价对比
定价来源:src/utils/modelCost.ts 中的硬编码标准定价配置
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
成本对比(1M input + 100K output):
Haiku 4.5: $1 + $0.5 = $1.5
Sonnet 4.6: $3 + $1.5 = $4.5
Opus 4.6: $15 + $7.5 = $22.5
相关资料:
-
基于 Claude Code npm 发布包 source map 还原版本
-
Caylent — Claude Haiku 4.5 Deep Dive: Cost, Capabilities, and the Multi-Agent Opportunity
https://caylent.com/blog/claude-haiku-4-5-deep-dive-cost-capabilities-and-the-multi-agent-opportunity