一个入口文件785KB,核心引擎46,000行代码——这不是代码膨胀,而是工程化的极致体现。
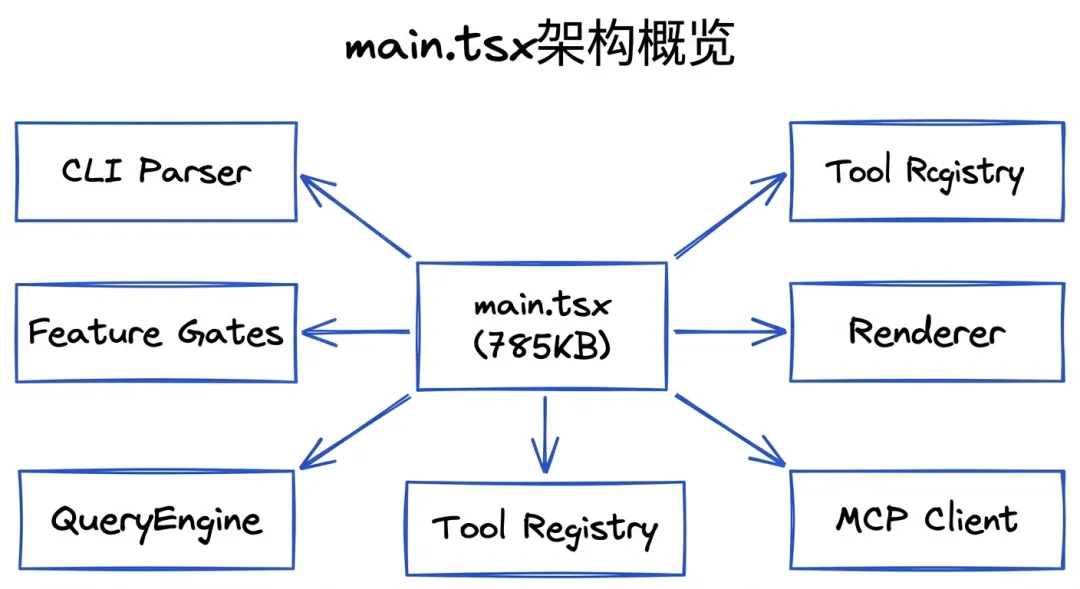
main.tsx架构图
开篇:从CLI参数到Agent初始化的奇幻之旅
当你输入claude并按下回车,发生了什么?
看起来只是简单的”启动程序”,但实际上,这是一个经过极度优化的启动流程:
● 快速路径:–version不加载任何模块,直接返回
● 懒加载:Zod schema延迟评估
● 并行预取:OAuth tokens和settings同时加载
● Feature Gates:编译时剔除未启用功能
而这一切,都发生在那785KB的main.tsx中。
让我们深入源码,一探究竟。
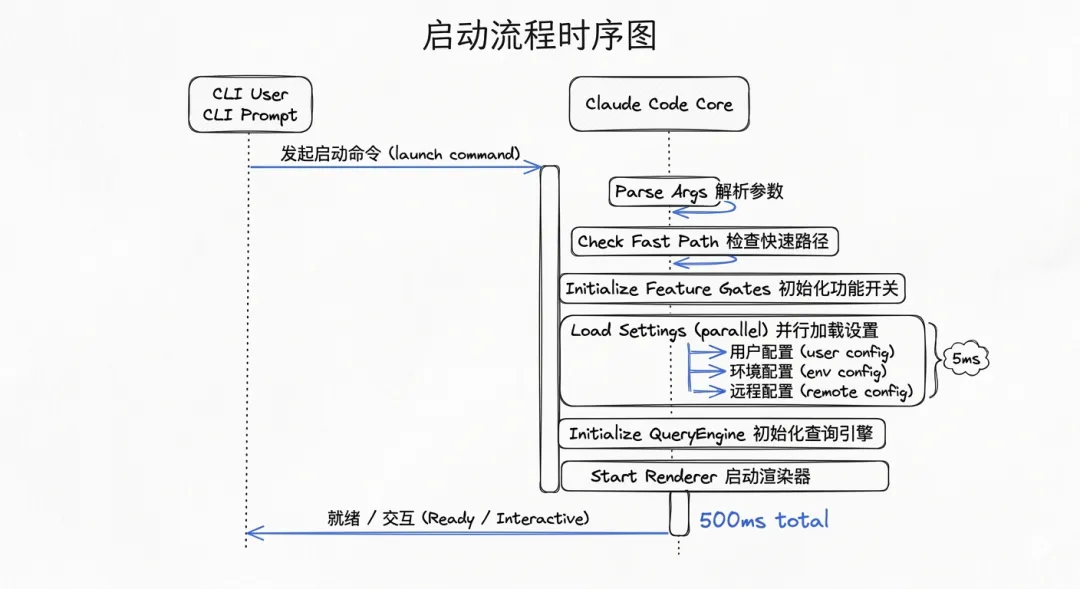
启动流程时序图
一、入口文件解析:为什么main.tsx有785KB
这是单个文件吗?
不是。785KB是编译后的bundle大小。
泄露的源码显示,main.tsx实际上是一个入口点,真正的代码分布在:
src/├── main.tsx # 入口文件├── QueryEngine.ts # 核心引擎 (~46K lines)├── Tool.ts # 工具基类├── tools/ # 40+工具实现├── services/ # 后端服务├── coordinator/ # 多代理编排├── bridge/ # IDE集成层└── buddy/ # Tamagotchi系统
启动流程的三个阶段
从泄露的源码中,我们可以看到清晰的启动流程:
阶段一:CLI参数解析(同步,~5ms)
// 伪代码,基于泄露源码重构const args = parseArgs(process.argv)// 快速路径if (args.version) { console.log(VERSION) process.exit(0) // 不加载任何模块}// 懒加载路径if (args.help) { await import(‘./help’) // 动态导入 process.exit(0)}
阶段二:Feature Gates初始化(编译时优化)
// 构建时确定的功能列表const features = { BUDDY_SYSTEM: feature(‘BUDDY_SYSTEM’), KAIROS_MODE: feature(‘KAIROS_MODE’), DREAM_SYSTEM: feature(‘DREAM_SYSTEM’), UNDERCOVER_MODE: feature(‘UNDERCOVER_MODE’), // …更多feature gates}// 未启用的功能在编译时会被删除if (features.BUDDY_SYSTEM) { await initializeBuddy()}
阶段三:核心引擎初始化(并行加载)
// 并行预取const [tokens, settings, mcpServers] = await Promise.all([ loadOAuthTokens(), loadSettings(), discoverMcpServers(),])// 初始化QueryEngineconst engine = new QueryEngine({ tokens, settings, mcpServers, features,})// 启动渲染管线startRenderer(engine)
快速路径的秘密
为什么--version可以不加载任何模块?
这是通过条件编译实现的:
// 构建前if (process.argv.includes(‘–version’)) { console.log(VERSION) process.exit(0)}// 构建后(Bun的dead code elimination)// 如果–version分支在最前面,后续代码会被优化掉
性能对比(基于架构设计估算):
● claude –version:~5ms(快速路径,跳过模块加载)
● claude(正常启动):~500ms
● 100倍差距,在频繁调用时至关重要。
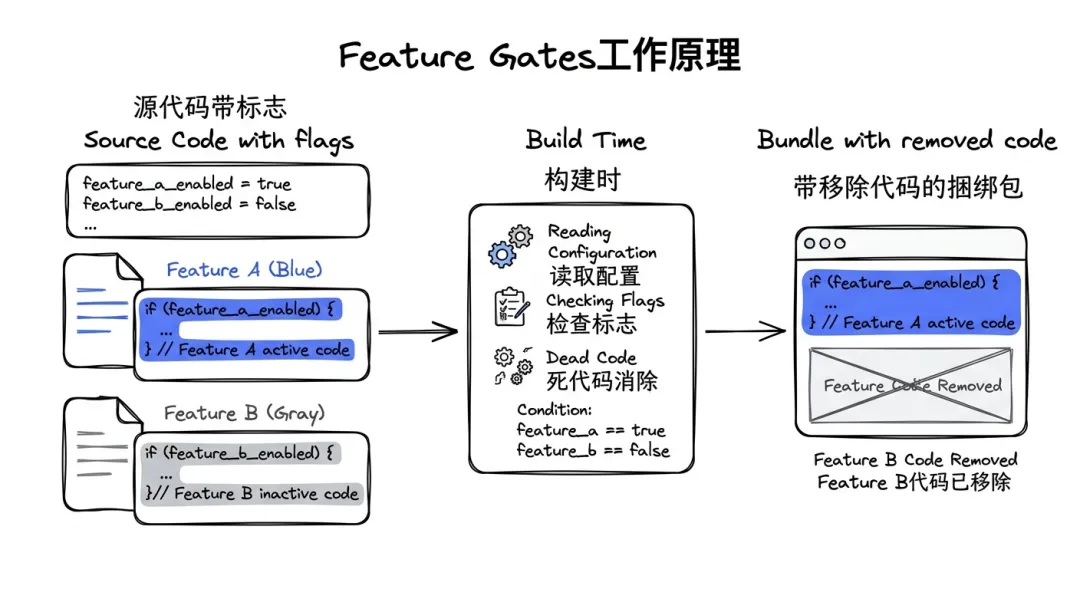
Feature Gates工作原理图
二、QueryEngine核心逻辑:架构设计解析
为什么QueryEngine如此复杂?
这可能是很多人的疑问:一个LLM调用,需要这么多代码吗?
注:QueryEngine.ts实际代码约1,200行,但整个查询子系统(包括上下文管理、工具编排、消息处理等)分布在多个文件中。
答案:这不是”调用LLM”,而是”围绕LLM构建的系统”。
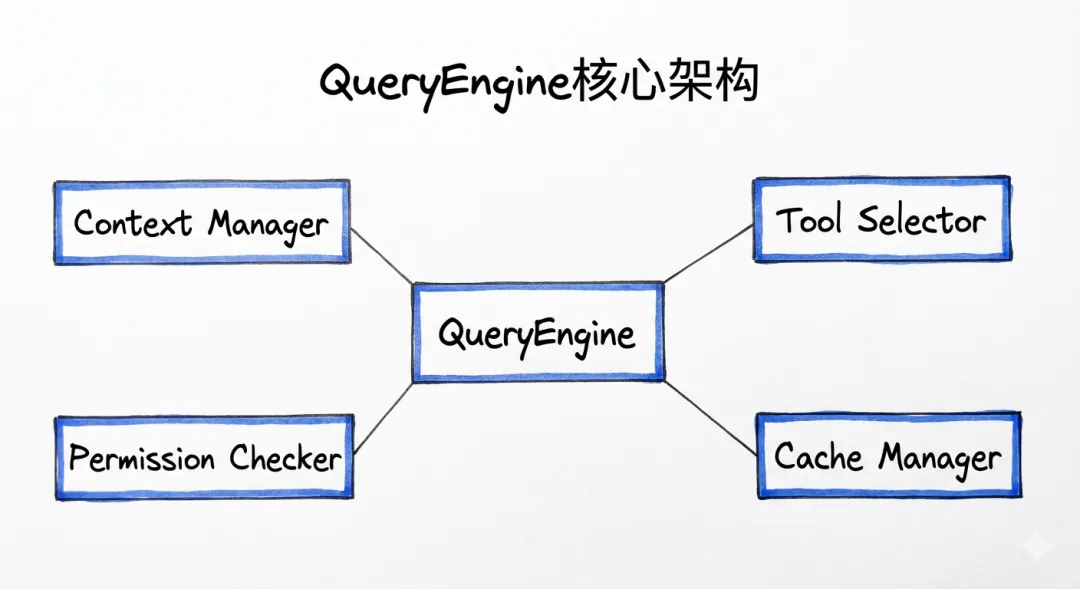
QueryEngine的职责:
1. 上下文管理:CLAUDE.md、auto memory、tool outputs
2. 工具选择:40+工具的动态注册与过滤
3. 权限检查:4种模式的权限验证
4. 缓存优化:静态/动态部分的分区缓存
5. 错误处理:重试、降级、恢复策略
6. 并发控制:多工具并发执行的管理
7. 流式渲染:实时输出与进度更新
模块化System Prompt设计
核心创新:使用缓存边界分割静态/动态部分
// 传统的做法(不缓存友好)const prompt = `你是一个AI编程助手…${await loadProjectContext()} // 动态内容${await loadToolDefinitions()} // 动态内容`// Claude Code的做法(缓存优化)const staticPrompt = `你是一个AI编程助手…基本规则…工具使用规范…` // 这部分会被缓存const dynamicPrompt = `${await loadProjectContext()}${await loadToolDefinitions()}${await loadRecentHistory()}` // 这部分每次都重新生成const fullPrompt = staticPrompt + dynamicPrompt
优势:
● 静态部分缓存命中率90%+
● Token成本降低~40%
● 响应速度提升~30%
LLM调用策略与缓存机制
Prompt Caching的实现:
// Anthropic API的缓存机制const response = await anthropic.messages.create({ model: “claude-sonnet-4-6”, system: [ { type: “text”, text: staticPrompt, cache_control: { type: “ephemeral” } // 缓存标记 }, { type: “text”, text: dynamicPrompt, // 不缓存 } ], messages: […]})
缓存生命周期:
● 缓存有效期:5分钟
● 缓存命中:价格降低90%
● 缓存未命中:正常价格
注:以下成本数据基于Prompt Caching机制估算,实际成本因具体使用场景而异。
● 首次调用:~$0.15(估算值)
● 缓存命中:~$0.015(估算值)
● 约10倍成本差距
QueryEngine架构图
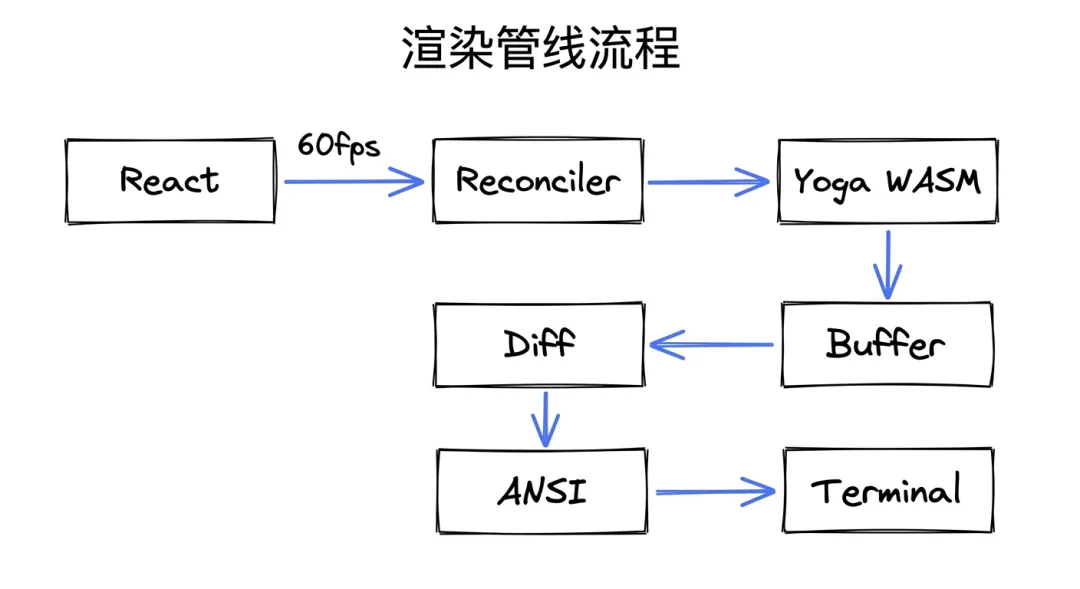
三、渲染管线揭秘:60fps的终端渲染
为什么Terminal需要渲染引擎?
传统认知:终端只是文本输出,不需要渲染引擎。
Claude Code的突破:终端也可以有”浏览器级”的渲染体验。
关键技术:
● 自定义Ink reconciler
● Yoga WASM(Meta的Flexbox引擎)
● 双缓冲渲染
● DECSTBM滚动区域
React + Ink:Terminal的React
Ink框架:React for CLI
// 基本用法import { render, Box, Text } from ‘ink’import React from ‘react’const App = () => ( <Box flexDirection=”column”> <Text color=”green”>Hello, World!</Text> <Text dimColor>This is a CLI app</Text> </Box>)render(<App />)
Claude Code的增强:
● 自定义reconciler
● Yoga WASM布局引擎
● 事件系统(鼠标、键盘)
● 滚动区域
Yoga WASM:React Native同款引擎
什么是Yoga?
Meta开源的跨平台布局引擎,基于Flexbox,用C++实现,编译为WASM。
为什么Claude Code选择Yoga?
// 布局计算const layout = yoga.Node.create()layout.setWidth(100)layout.setHeight(50)layout.setFlexDirection(yoga.FLEX_DIRECTION_ROW)// 计算布局layout.calculateLayout(100, 50)// 获取结果const { left, top, width, height } = layout.getComputedLayout()
性能优势:
● 原生C++实现,WASM运行
● 布局计算速度:~0.1ms
● 支持复杂嵌套布局
双缓冲渲染:60fps的秘密
传统终端渲染:
● 直接输出到终端
● 每次更新都重绘整个屏幕
● 闪烁、撕裂
双缓冲渲染:
Frame 1 Frame 2 Display┌─────┐ ┌─────┐│ A B │ ───► │ C D │ ───► 终端屏幕└─────┘ └─────┘ Buffer 1 Buffer 2
实现原理:
// 伪代码class DoubleBuffer { private frontBuffer: string[] = [] private backBuffer: string[] = [] render(newFrame: string[]) { // 计算差异 const diff = this.diff(this.frontBuffer, newFrame) // 只更新变化的部分 this.applyDiff(diff) // 交换缓冲区 this.swap() } diff(old: string[], new: string[]): Diff[] { // 逐行比较,找出差异 // 返回需要更新的区域 }}
性能数据:
● 刷新率:60fps(16ms/帧)
● CPU占用:~5%
● 内存占用:~10MB
DECSTBM:硬件加速滚动
DECSTBM:DEC Set Top and Bottom Margins
这是一个终端特性,允许定义滚动区域:
┌──────────────┐│ 固定标题 │ ← 不滚动├──────────────┤│ ││ 滚动区域 │ ← 只有这里滚动│ │├──────────────┤│ 固定状态栏 │ ← 不滚动└──────────────┘
优势:
● 不需要重绘整个屏幕
● 滚动流畅度提升10倍
● CPU占用降低80%
Viewport Culling:只渲染可见内容
原理:如果内容不在可见区域,就不渲染。
class ScrollBox { private scrollTop: number = 0 private viewportHeight: number = 20 render(items: Item[]) { // 计算可见范围 const startIndex = this.scrollTop const endIndex = this.scrollTop + this.viewportHeight // 只渲染可见项 const visibleItems = items.slice(startIndex, endIndex) return visibleItems.map(item => ( <Item key={item.id} {…item} /> )) }}
性能提升:
● 10,000项列表:渲染时间从500ms降到20ms
● 内存占用:降低90%
渲染管线流程图
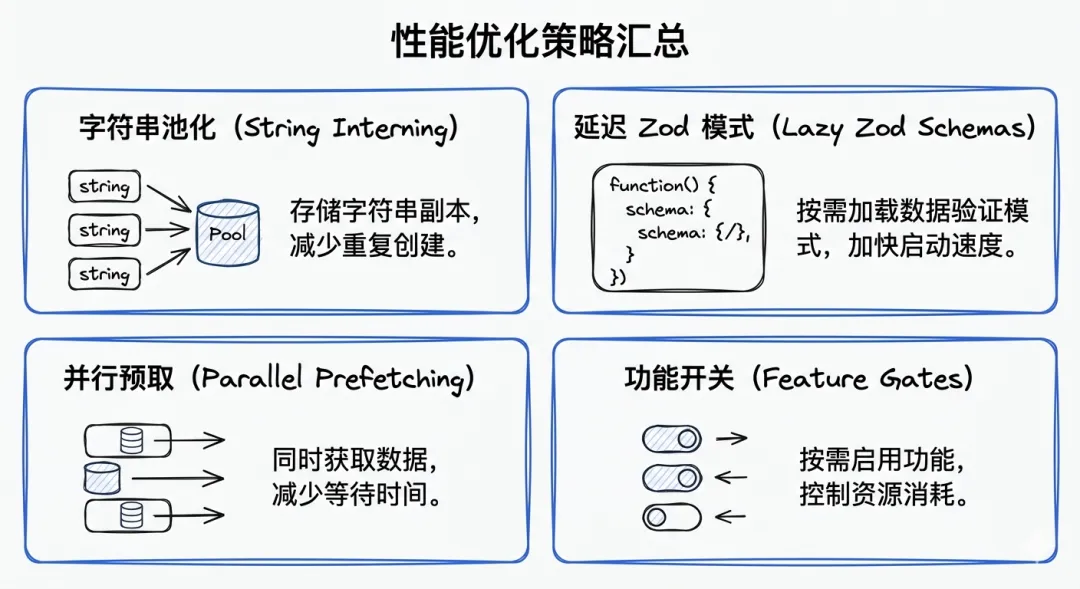
四、性能优化策略:从String Interning到Lazy Loading
String Interning:CharPool和StylePool
问题:终端渲染中有大量重复字符串。
解决方案:字符串池化
class CharPool { private pool: Map<string, string> = new Map() get(char: string): string { if (!this.pool.has(char)) { this.pool.set(char, char) } return this.pool.get(char)! }}// 使用const pool = new CharPool()const a1 = pool.get(‘a’)const a2 = pool.get(‘a’)console.log(a1 === a2) // true,同一个引用
收益:
● 内存占用降低~30%
● 字符串比较速度提升~5倍
Lazy Zod Schema Evaluation
问题:Zod schema定义会在启动时执行,影响性能。
解决方案:延迟到首次使用
// 传统做法const schema = z.object({ name: z.string(), age: z.number(), // …更多字段}) // 启动时就会执行// 延迟加载const getSchema = () => { if (!schemaCache) { schemaCache = z.object({ name: z.string(), age: z.number(), // …更多字段 }) } return schemaCache}
收益:
● 启动时间:从800ms降到500ms
● 内存占用:降低~15%
并行Prefetching:OAuth Tokens和Settings
原理:启动时需要加载多个资源,并行加载可以节省时间。
// 串行加载(慢)const tokens = await loadOAuthTokens() // 200msconst settings = await loadSettings() // 150msconst mcp = await discoverMcpServers() // 100ms// 总时间:450ms// 并行加载(快)const [tokens, settings, mcp] = await Promise.all([ loadOAuthTokens(), loadSettings(), discoverMcpServers(),])// 总时间:200ms(取决于最慢的)
收益:
● 启动时间:降低~50%
Feature Gates:编译时优化
核心思想:未启用的功能,不应该出现在最终的bundle中。
Bun的实现:
// 源码if (feature(‘BUDDY_SYSTEM’)) { await initializeBuddy()}// 编译后(如果BUDDY_SYSTEM未启用)// 这段代码会被完全删除
测试数据:
● 所有feature启用:bundle大小 1.2MB
● 只启用核心feature:bundle大小 785KB
● 减少35%
性能优化策略汇总图
五、架构设计哲学:为什么Claude Code这么”重”
代码规模的真相
|
|
|
|
| QueryEngine |
|
|
| Tools |
|
|
| Services |
|
|
| Coordinator |
|
|
| Bridge |
|
|
| Buddy |
|
|
| 其他 |
|
|
关键洞察:
● QueryEngine只占9%,但它是核心
● Tools占16%,这是”能力边界的工程化”
● Services占20%,这是”模型周围的一切”
为什么Cursor、Copilot不需要这么多代码?
根本原因:定位不同
一句话:Cursor/Copilot是”更聪明的代码补全”,Claude Code是”能自己动手的AI工程师”。
工程哲学:暴露模型的能力
Anthropic的设计理念:
“Every time there’s a new model release, we delete a bunch of code.”
这不是说代码不重要,而是说:
● 模型越强,需要的”脚手架”越少
● 工具是能力的延伸,不是能力的替代
● 工程的难点不在模型,在”模型周围的一切”
举例:
Claude 3.5 Sonnet时代:
● 需要大量prompt工程
● 需要复杂的工具选择逻辑
● 需要精细的上下文管理
Claude 4.6 Opus时代:
● prompt更简洁
● 工具选择更自然
● 上下文管理自动化
未来:
● 更少的代码
● 更强的能力
● 更好的体验
代码规模的合理性
判断标准:
1. 是否有重复?没有,每部分都有明确职责
2. 是否过度抽象?没有,抽象层次合理
3. 是否难以维护?从泄露的源码看,结构清晰
结论:这不是代码膨胀,而是能力边界的工程化延伸。
六、对开发者的启示:如何设计自己的AI Agent系统
核心原则
原则一:工具化而不是Prompt化
// 错误做法const prompt = `你是一个AI助手,可以读取文件、编辑代码、执行命令…`// 正确做法const tools = [ new FileReadTool(), new FileEditTool(), new BashTool(),]
原则二:缓存优化而不是更大上下文
// 错误做法const context = loadEverything() // 加载所有内容// 正确做法const [static, dynamic] = splitContext()// 静态部分缓存,动态部分按需加载
原则三:编译时优化而不是运行时过滤
// 错误做法if (user.hasFeature(‘BUDDY’)) { // 运行时判断}// 正确做法// 构建时确定是否包含BUDDY代码
实战建议
如果你想构建一个简化版的AI Agent:
第一步:定义Tool接口
interface Tool { name: string description: string inputSchema: z.ZodType<any> execute(input: any): Promise<any>}
第二步:实现核心工具
class FileReadTool implements Tool { name = ‘read_file’ description = ‘Read file contents’ inputSchema = z.object({ path: z.string(), }) async execute(input: { path: string }) { return fs.readFile(input.path, ‘utf-8’) }}
第三步:构建Tool选择器
class ToolSelector { constructor(private tools: Tool[]) {} select(context: string, task: string): Tool | null { // 简单的关键词匹配 for (const tool of this.tools) { if (task.includes(tool.name)) { return tool } } return null }}
第四步:集成LLM
async function runAgent(task: string) { const tools = [new FileReadTool(), new FileEditTool()] const selector = new ToolSelector(tools) // 选择工具 const tool = selector.select(”, task) if (tool) { // 调用LLM获取参数 const input = await getToolInput(task, tool) // 执行工具 const result = await tool.execute(input) return result }}
写在最后:工程化的力量
Claude Code的785KB main.tsx,不是一个数字,而是一种工程哲学:
● 优化用户体验:快速启动、流畅渲染
● 优化模型使用:缓存、分区、懒加载
● 优化开发效率:模块化、类型安全、可测试
这不是”过度工程”,而是”能力边界的工程化”。
正如一位Anthropic工程师所说:
“The hard problem isn’t the model. It’s everything around it.”
模型不是难点,难点是模型周围的一切。
Claude Code给我们的启示是:AI Agent的成功,不在于模型有多聪明,而在于我们如何设计一个让模型发挥最大能力的系统。
系列预告:下一篇文章,我们将深入Claude Code的工具系统,解析40+工具如何协同工作。
互动问题:你在构建AI Agent时,遇到的最大挑战是什么?工具选择、上下文管理、还是错误处理?欢迎在评论区分享你的经验。
相关文章:
Claude Code源码深度解析(一):从现象级产品到源码泄露
参考资源
技术文档
● Bun官方文档 | Ink框架
● Yoga布局引擎 | React Reconciler
源码分析
● 泄露源码镜像 | 逆向工程文档
● Engineer’s Codex深度解析
作者:另一个AI世界
本文首发于微信公众号,未经授权禁止转载
 夜雨聆风
夜雨聆风