 夜雨聆风
夜雨聆风





RAGFlow:基于深度文档理解的开源RAG引擎
RAGFlow是一款开源的检索增强生成(RAG)引擎,它旨在为大语言模型(LLM)提供高质量的上下文信息,从而解决大模型普遍存在的“幻觉”问题。与传统的向量数据库不同,RAGFlow不仅关注检索,更强调对复杂文档的深度理解和精准解析,使其在处理企业级非结构化数据时表现出色。
Part.01
核心理念与工作流程
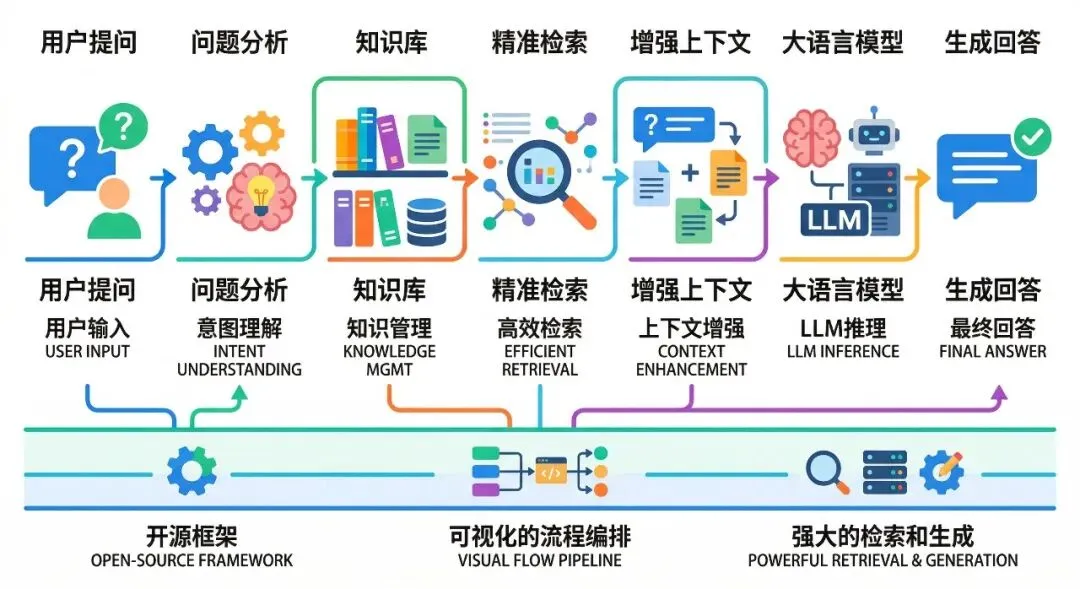
Part.02
主要功能亮点
-
多样化的数据支持:支持上传本地文件(PDF, DOCX, TXT等),也支持通过API接入各种数据源。
-
可视化编排:提供直观的图形用户界面,允许用户通过拖拽的方式配置RAG流程,包括数据清洗规则、检索参数和提示词模板。
-
自动分块与清洗:系统能根据文档结构自动进行智能分块,去除页眉、页脚、乱码等噪声,确保输入给大模型的内容纯净有效。
-
多模型适配:兼容多种主流大语言模型(如Qwen, Llama, GPT等)以及多种向量模型,用户可以根据需求灵活切换。
Part.03
技术架构与应用场景
从技术架构上看,RAGFlow通常由以下几个组件构成:
-
企业知识库问答:快速构建基于内部文档的智能客服或员工助手。 -
法律/金融文档分析:精准提取合同、财报中的关键条款和数据。 -
学术研究辅助:帮助研究人员在海量文献中快速定位相关信息。

