 夜雨聆风
夜雨聆风





Claude 源码泄露真相:51 万行代码,暴露的不是功能,而是 AI Agent 内核
2026 年 3 月 31 日,全球成千上万的开发者不约而同做了同一件事:将 Claude Code 的源码输入 Claude,让它自行解读。
Anthropic 这款旗舰级命令行工具,因 npm 包中意外打包了源码映射文件,导致整整 51.2 万行 TypeScript 代码库彻底泄露。短短数小时内,全网就梳理出 44 个功能开关、内置 18 种物种与抽卡机制的电子宠物系统。
但功能清单从不是重点,这类文章早已铺天盖地。此次泄露的真正价值,不在于 Claude Code 能做什么,而在于它的思考逻辑。开发者付费按 Token 消耗,让 Claude 解析自家产品的源码,这绝非讽刺,而是本文的核心论点。
掌控框架,才是产品本身
多数人默认 Claude Code 只是 Claude API 的简易 CLI 封装:一个发送提示词、流式返回结果、处理少量文件操作的终端界面。
但泄露的源码颠覆了这一认知:Anthropic 真正交付的,是 51.2 万行 TypeScript 构建的庞大体系 —— 搭载双缓冲屏幕输出与 Yoga 弹性布局的自定义 React 终端渲染器、60 余个权限管控且延迟加载的工具、可生成并协调并行工作智能体的多智能体编排系统、后台静默运行的记忆整合引擎,还有永不崩溃的自愈查询循环。
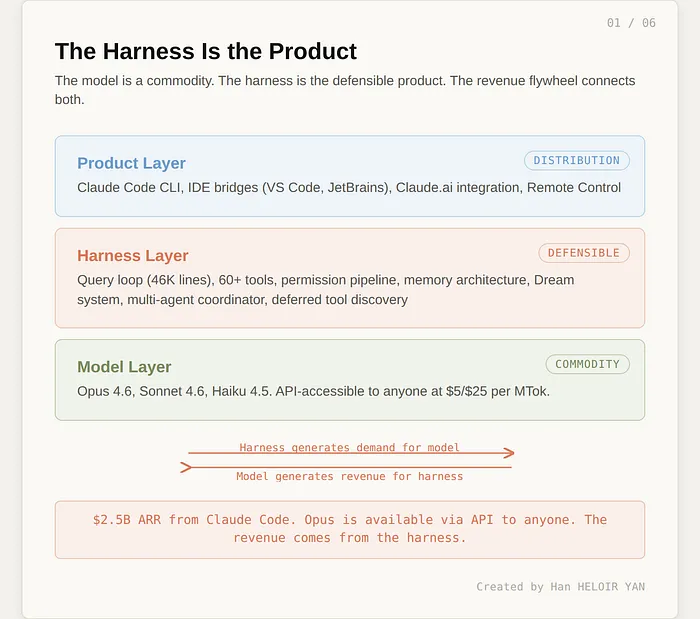
这绝非简单封装,而是AI 智能体的专属操作系统。
黑客新闻社区为此分成两派:一派用赌场比喻不屑一顾,“老虎机源码对赌场管理者毫无意义”,认为大模型才是核心,CLI 只是附属;另一派则持相反观点:模型是荷官,而掌控框架才是赌场,赌场的搭建难度远超想象。
数据站在了后者一边。Opus 4.6 模型 API 对所有人开放,定价为每百万 Token 5/25 美元,可据 VentureBeat 报道,仅 Claude Code 就实现了 25 亿美元年化 recurring revenue,其中 80% 来自企业客户。开发者付费的对象并非模型,而是让模型真正落地实用的框架:工具编排、权限体系、上下文管理、错误恢复。剥离这些,它只是昂贵的自动补全工具。
3 月 31 日形成的自循环营收闭环印证了这一点:有开发者搭建 MCP 服务器,让用户通过 Claude Code 交互式探索泄露源码;有人凌晨四点用 Claude Code 将其核心架构移植到 Python;国内有团队基于泄露源码打造了 12 节逆向工程课程。开发者 Jingle Bell 一语道破:“Claude 今日的收入,源于所有人用 Claude 解析它自身的源码。”
框架催生模型需求,模型反哺框架收益,这一飞轮,才是产品的本质。
下文将从泄露源码中提炼三大架构模式,无关功能与代号,而是驱动运转的工程底层逻辑。
模式一:自愈查询循环(Self-Healing Query Loop)
Claude Code 最昂贵的工程设计并非 AI 本身,而是错误处理机制。
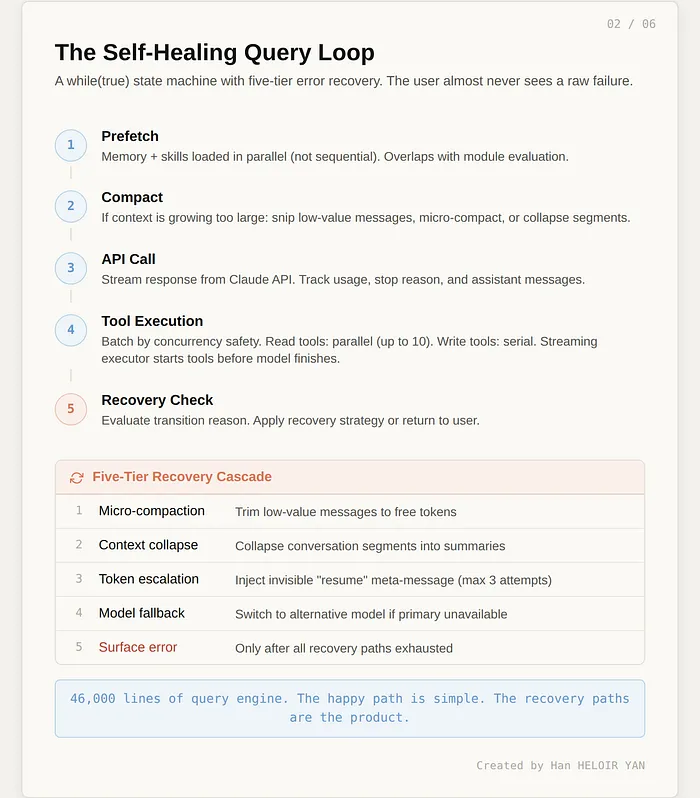
其核心是一个查询循环,并非简单的请求 – 响应流程,而是一个while(true)状态机,跨迭代管理可变状态对象,核心设计目标:绝不向用户展示原始错误。
每次迭代流程固定:首先并行预加载记忆与技能(而非串行执行,避免延迟翻倍);上下文过大时执行消息压缩;调用 API 进行流式传输;执行模型请求的工具;判断循环继续或终止。每一步都会记录未终止原因,存入状态供下次迭代自适应调整。
真正的工程精髓在于错误恢复 cascade,故障发生时循环不会崩溃,而是逐级启用更激进的恢复策略:
- 微压缩:剔除上下文中低价值消息,释放 Token 空间
- 上下文折叠:压缩无效时,将整段对话摘要整合
- Token 扩容:模型输出配额耗尽时,注入隐形元指令 “直接继续,无需道歉与回顾”,连续尝试最多 3 次后终止
- 模型降级:主模型不可用时自动切换备用模型
- 展示错误:所有恢复路径失效后,用户才会看到失败提示
有开发者从压缩 JS 中逆向解析 12 个版本的 Claude Code 后发现,5.4% 的工具调用会无声失效:模型发起请求、工具执行完毕,结果却无法返回。而自愈循环的设计,正是为了让用户无感解决这类故障。
工具执行层面同样做了优化:循环不会逐个运行工具,而是根据并发安全等级分组。每个工具通过isConcurrencySafe()方法声明是否支持并行,grep、文件读取等只读工具可同时运行 10 个,文件编辑、带副作用的终端命令则串行执行,读写批次交替执行。流式执行器还能在模型生成输出时同步运行工具,重叠计算与 I/O 降低延迟。

工具系统同样遵循资源最优原则:60 余个工具中仅 40 个随请求加载,剩余 18 个为延迟加载,模型需通过专用工具搜索工具查找后才会可见。LSP 集成、后台任务、定时调度等能力,均在模型需要时才加载,让上下文窗口节省 20 万 Token 空间。
工具列表按字母排序也并非美观考量,而是缓存优化:固定排序提升提示词缓存命中率,避免因工具列表变动重新处理数千行 Schema 定义。
这给智能体开发者带来反直觉启示:可靠性并非核心流程完成后的附加功能,核心流程本身就是可靠性系统。Claude Code 查询引擎 4.6 万行代码的体量,并非源于正常流程复杂,而是因为恢复路径过于繁琐。
模式二:睡眠时计算(Sleep-Time Compute)—— autoDream
Claude Code 最重要的能力,发生在用户未使用它的时候。
所有 AI 编程工具都面临同一痛点:长时间协作积累的架构决策、调试思路、构建命令、个人偏好等上下文,会在关闭终端后彻底消失,下次会话从零开始,重复沟通、重复犯错。
Claude Code 的解决方案是autoDream(自动梦境)系统,顾名思义,这是 Claude 的 “梦境思考”。
会话间隙,Claude Code 会派生子智能体,专职负责记忆整合。子智能体读取项目记忆目录、复盘会话日志,筛选值得留存的新信息,重构记忆文件,让其更简洁精准,适配下次会话。子智能体的系统提示直白定义了自身使命:“你正在进入梦境,对记忆文件进行反思梳理,将近期所学整合为持久有序的记忆,让后续会话快速适配。”
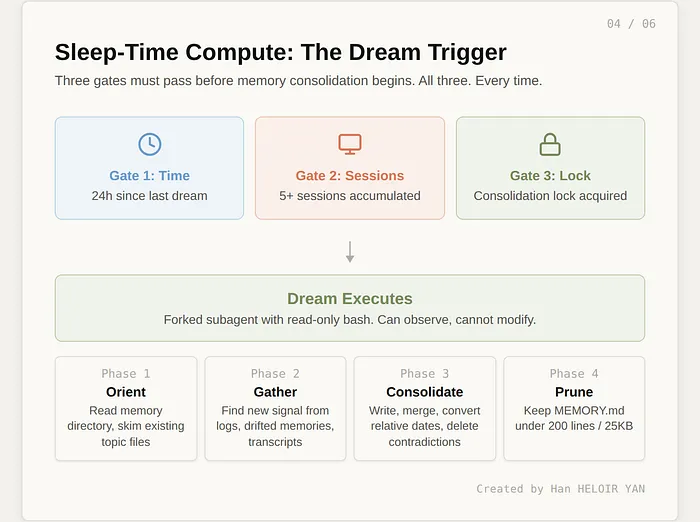
梦境触发并非随机,需通过三重关卡校验:
- 时间关卡:距上一次梦境至少间隔 24 小时,避免频繁短会话导致过度整合
- 会话关卡:距上一次梦境至少完成 5 次会话,确保积累足够有效信息
- 锁关卡:获取整合锁,防止多实例同时触发梦境
全部通过后,梦境分四阶段执行:
- 定位:遍历记忆目录,读取索引文件,梳理现有状态
- 收集信息:按优先级提取新信息,优先每日日志,其次更新的记忆,再是工作中发现的模式
- 整合:更新记忆文件,转换相对时间为绝对时间,删除矛盾信息,合并冗余内容
- 修剪索引:将索引文件控制在 200 行、25KB 左右,清理失效指向,解决内容冲突
梦境子智能体仅拥有只读终端权限,可查看项目但无法修改,构筑安全边界,避免整合过程影响代码库。
这一架构契合加州大学伯克利分校的睡眠计算研究:利用闲置算力优化后续推理效率。autoDream不预测未来,而是整理过往记忆,设计理念一致:在用户无感知时投入算力,让下次会话启动更快、上下文更优质。
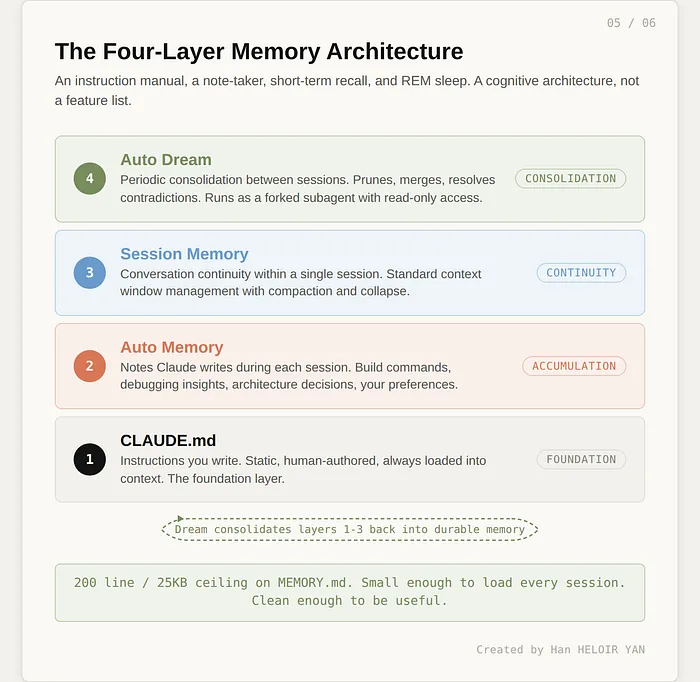
最终形成了行业独有的四层记忆架构:
- CLAUDE.md:用户自定义指令,静态人工编写,全程加载
- 自动记忆:会话中自动生成的笔记,包含构建命令、调试思路、架构决策等
- 会话记忆:单次会话的对话上下文,标准上下文管理
- 自动梦境:跨层周期性记忆整合,相当于垃圾回收、碎片整理、快速眼动睡眠
使用手册、实时笔记、短期记忆、梦境整合,这不是功能堆砌,而是一套完整的认知架构。
模式三:编译时特性消除(Compile-Time Feature Elimination)
此次源码映射泄露,恰恰源于安全机制的 “有效执行”:代码被构建剔除,却未从映射文件中移除。
Anthropic 同一套代码库面向两类人群:内部员工可使用全天候智能助手 KAIROS、电子宠物 BUDDY、多智能体编排等实验功能;外部用户则完全无法接触。外部构建包中没有隐藏在条件语句中的死代码,而是物理上彻底消失。
实现机制依托 Bun 的feature()函数,该函数在编译期执行而非运行期。构建外部包时,所有feature('KAIROS')都会被判定为假,Bun 打包器直接剔除整段代码,最终 JS 文件中无任何内部功能痕迹。
这是双层功能系统的第一层,第二层是通过 GrowthBook 实现的运行期功能开关,代码中以tengu_为前缀,用于功能逐步发布、A/B 测试与紧急关停。校验方法命名为getFeatureValue_CACHED_MAY_BE_STALE(),直白体现设计理念:功能开关可接受数据延迟,速度优先于实时性,智能体绝不能因校验功能开关而阻塞。
双层机制分工明确:编译期剔除是安全边界,确保内部功能彻底不对外暴露;运行期开关是发布管控,用于已合规功能的逐步上线与故障止损。

在此之上还有第三层:通过USER_TYPE === 'ant'管控员工专属功能,包括测试 API、调试提示词导出、隐秘模式(开源贡献中隐藏 AI 身份)等内部工具。
而泄露的根源极具结构性讽刺:源码映射文件用于关联编译产物与原始代码,无论编译剔除多少代码,原始内容都会保留在sourcesContent中。死代码剔除保护了执行文件,却无法保护映射文件。Bun 默认生成源码映射,未被配置关闭,.npmignore也未排除相关文件,最终 59.8MB 的 JSON 文件将完整内部代码库公之于众。
这并非首次发生,2025 年 2 月 Claude Code 上线时就出现过同类问题,Anthropic 静默修复后,13 个月后的 2.1.88 版本再次复发,打包流程的漏洞始终未被修补。一家拥有顶尖大模型、专门设计隐秘模式防止信息泄露的 AI 公司,却栽在了.npmignore缺失的一行配置上。
这给开发者带来结构性启示:智能体产品必须搭建双层功能系统,编译期剔除保障安全,运行期开关管控发布,同时构建流程需严格校验发布产物,每次发布前执行npm pack --dry-run。
框架与模型之争的终极答案
3 月 31 日全网热衷于盘点趣味功能:电子宠物、动物代号、检测用户辱骂 AI 的正则表达式,这些博人眼球,却毫无价值。

真正关键的是三大核心模式:以可靠性为核心的自愈查询循环,4.6 万行代码倾注于恢复路径,工具分组执行、延迟加载、缓存优化,只为让用户零感知故障;利用闲置算力整合记忆的睡眠计算系统,四层记忆架构构筑量产编程工具中首个认知体系,三重关卡保障运行合理;编译期剔除与运行期开关结合的双层功能管控,从产物层面筑牢安全边界,却因配置疏漏导致泄露。
这些不是功能,而是底层基石,是所有量产 AI 智能体的必备能力,无论基于 Claude、GPT 还是开源模型。此次泄露的并非 Claude Code 的竞争优势,而是整个 AI 智能体赛道的工程标准。
竞争对手如今拥有了参考架构,有人连夜移植 Python 版本,有人打造逆向课程,Rust 移植也已启动,模式注定会被复制。
但知晓架构不等于能落地执行。Claude Code 历经 13 个月量产打磨,12 个版本迭代优化恢复路径,权限规则适配真实企业场景,拥有五种公开模式、机器学习自动审批分类器、执行前静默修改参数的钩子。源码只是瞬间快照,而实战经验无法被复制。
3 月 31 日的自循环闭环给出最终结论:开发者为模型付费解析框架,框架让模型具备实用价值,模型让框架实现盈利。这种飞轮效应无法从源代码映射中复制,它本身就是产品。
参考与延伸阅读
- https://github.com/Kuberwastaken/claurst
- https://sathwick.xyz/blog/claude-code.html
- https://venturebeat.com/technology/claude-codes-source-code-appears-to-have-leaked-heres-what-we-know
- https://www.penligent.ai/hackinglabs/claude-code-source-map-leak-what-was-exposed-and-what-it-means/
- https://thehuman2ai.com/blog/claude-code-source-leak
- https://github.com/shareAI-lab/learn-claude-code