 夜雨聆风
夜雨聆风





Claude Code 源码意外泄露 7 小时:8 大隐藏功能、26 条秘密指令、6 级安全架构,全被扒干净了
听说 Claude Code 的源码被泄露了,我抬手就是一个 git clone。
备份仓库 instructkr/claude-code 瞬间飙到 2 万多星。
事情离谱到什么程度呢?Claude Code 发布 v2.1.88 版本时,一个 60MB 的 source map 文件被误打误撞打进了 npm 包。
后果相当惨烈——1906 个源文件完整曝光,51 万行代码,全都能直接读。
甚至能做到让 Claude Code 自己解读自己:

好家伙,Claude 团队这下可真是比 OpenAI 还“Open”了。
那么问题来了,source map 到底是什么?怎么会把家底都漏了?
简单说,它是开发调试用的映射文件,能把压缩后的代码还原回原始源码。重点强调:它绝对不应该出现在正式发布的 npm 包里。
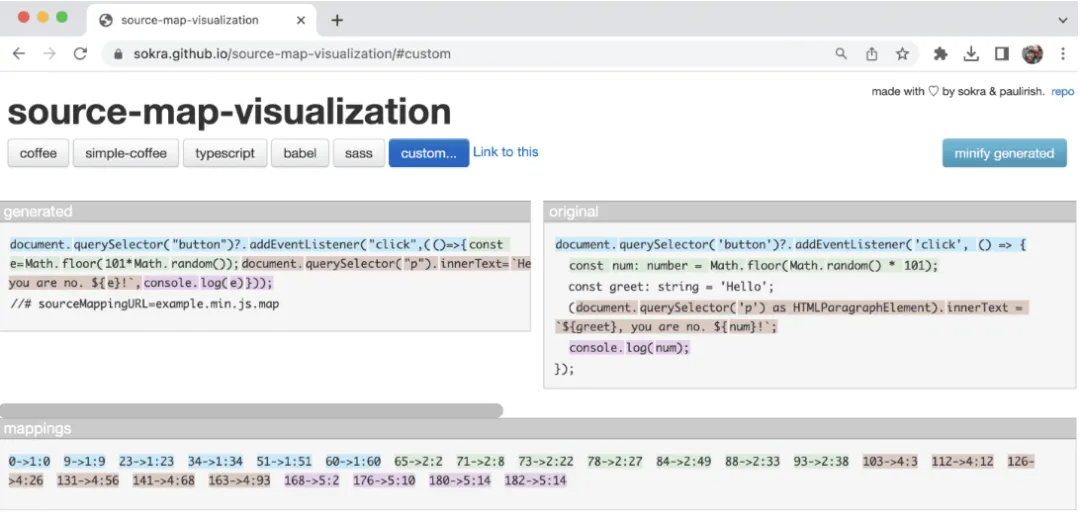
如果是普通 Web 项目,在 npm 里暴露前端代码,别人顶多抄抄界面和交互逻辑,核心业务还在后端。
可偏偏 Claude Code 是一个 CLI 编程工具,大家最眼馋的功能全都在用户本地的客户端里跑。
换句话说,任何人拿到这份代码,都能自己复刻一个出来。
评论区有人说 6 个月内就能复制出来——只能说,这估计还是太保守了。
说时迟那时快,泄露的代码被眼疾手快的网友们迅速备份到多个 GitHub 仓库,全网开始疯狂研究。
仅仅 7 个小时,大家就把代码扒了个底朝天,发现:
8 大新功能、26 条隐藏指令、6 级安全架构,外加一个愚人节彩蛋。
整体项目架构相当优秀,但代码里也藏着一座“屎山”。
01
新功能:电子宠物、长期记忆助手、30 分钟深度规划
代码里不光是已经上线的东西。社区很快挖出了一堆被 feature flag 关着的隐藏模块。
有人甚至专门搭了 ccleaks.com 网站,把所有隐藏内容都展示出来。
从代码中提取出:35 个编译时特性标志、120 多个隐藏环境变量、200 多个远程控制开关。
最让人意想不到的发现之一:Claude Code 里居然藏了一个 电子宠物系统。
代号 Buddy,一个 Tamagotchi 风格的 ASCII 虚拟宠物,会出现在你的终端里。
18 个物种——鸭子、章鱼、水豚、蘑菇……6 种稀有度,普通款占 60%,传奇款只有 1%,甚至还有闪光版设定。
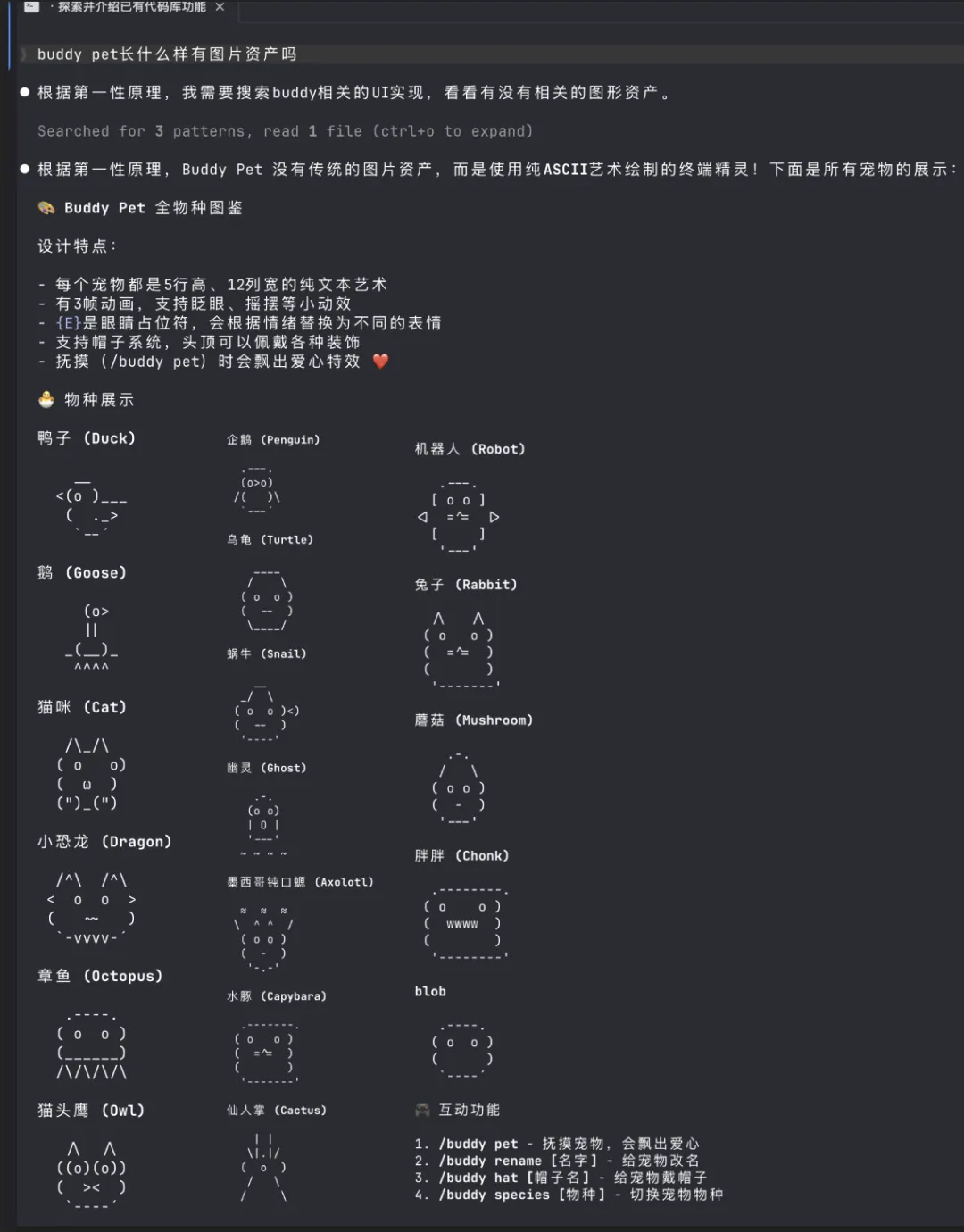
每只宠物由账户 ID 唯一生成。上号抽卡,你的那只全世界独一份。
不过看代码里的时间戳,Buddy 计划在 4 月 1 日首次亮相。大概率是个愚人节彩蛋。
接下来是正经的新功能。
代号 Kairos,一个持久化助手模式,让 Claude 拥有跨会话的长期记忆。
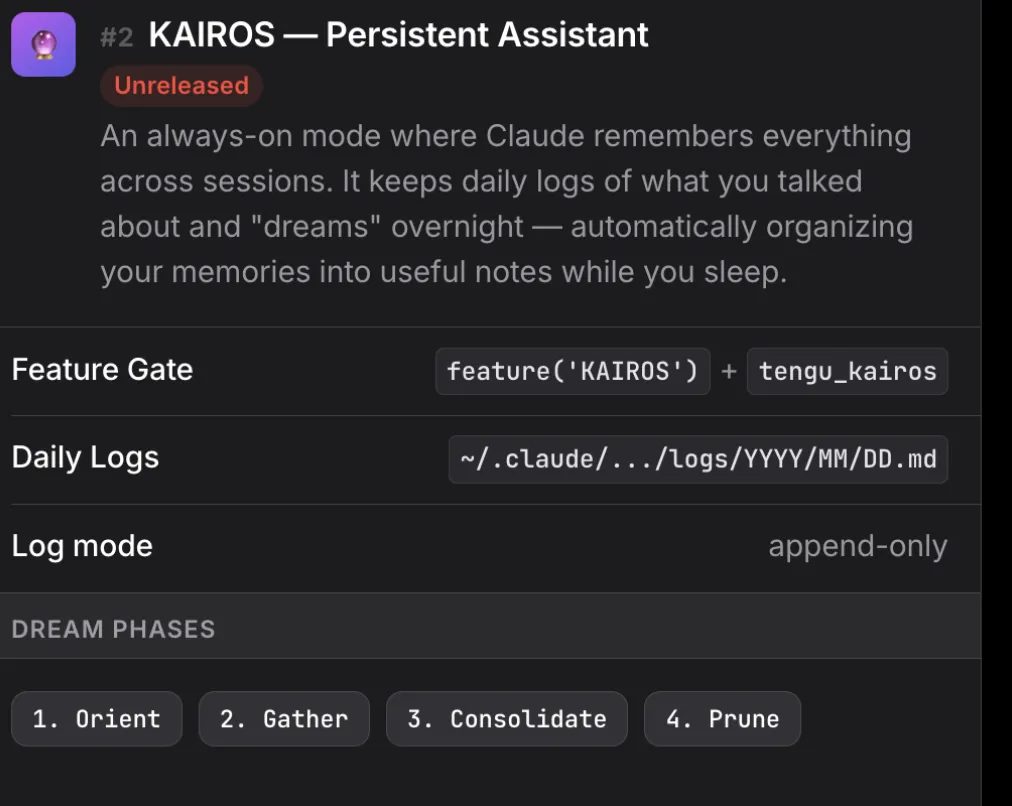
当你不用 Claude Code 的时候,Kairos 会自动执行四阶段记忆整合:定向 → 收集 → 整合 → 修剪。
换句话说,AI 在你睡觉的时候,自动把你之前聊的零散信息整理成结构化的笔记。

此外,代码里还发现了一系列尚未公布的隐藏功能:
-
Ultraplan:用 Opus 4.6 模型,支持最长 30 分钟的深度任务规划,适合复杂项目的全流程设计
-
多 Agent 协调模式:同时启动多个独立 Agent 实例分工协作,并行任务效率提升 3 倍以上
-
跨会话进程通信:同一台机器上跑多个 Claude 会话时,它们可以互相发消息
-
守护进程模式:像系统服务一样在后台运行 Claude 会话,并配有会话管理器
还有 26 条不在 help 里的隐藏斜杠指令,其中包含已经公布的 btw。
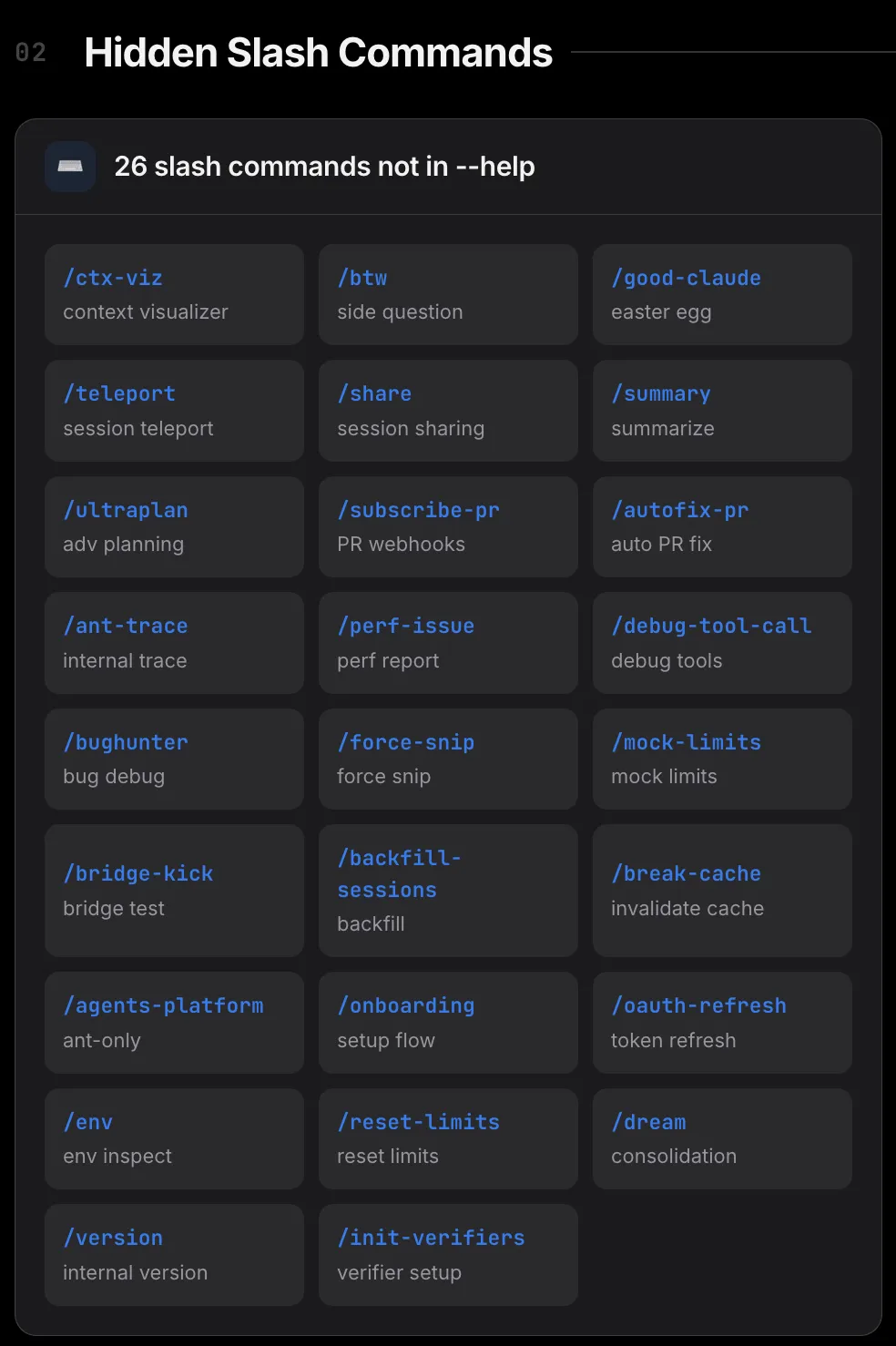
还有一个隐藏功能引发了不小的争议:
卧底模式(Undercover mode):向开源代码仓库提交 PR 时,自动移除所有跟 Anthropic 相关的信息。
代码里明确写着要让 AI “伪装成人类”,这让很多开发者感到不太舒服。
不过,这些隐藏功能在发布的包里大多只有接口实现,完整代码尚未泄露。
但除了未发布的新功能,整整 51 万行代码里,还有更多值得深挖的地方。
02
51 万行代码里的惊喜与惊吓
Claude Code 的架构设计水平远超预期,但代码质量却是参差不齐。
最先引起开发者注意的,是它的安全设计。
每一次工具调用——无论是执行 Shell 命令还是读写文件——都要先经过六级权限验证系统。
验证通过还不算完。还要再经过四层决策管道,逐层检查权限和执行分析,最后才能真正执行。
所有外部命令和插件都在独立的沙箱环境里运行。

系统还用了独立的非阻塞缓冲区处理输入输出,一边给你回复,一边在后台继续干活,一心多用。
当对话 token 超过阈值时,自动触发上下文压缩,智能保留最关键的逻辑链条。
到这里,社区的评价基本上是正面的:架构扎实,安全机制很认真。
但是! 翻到 src/cli/print.ts 这个文件时,画风突然就变了。
一个函数,3000 多行,12 层嵌套,圈复杂度直接爆炸。

最后,社区还发现了一个有趣的细节:Claude Code 检测用户负面情绪的方式。
不是用 AI 模型做情感分析,而是用最原始的正则表达式,匹配 ffs(for fuck’s sake)、shitty 这类关键词。
所有这些发现,让人忍不住想问一个问题:一向标榜 AI 安全的 Anthropic,怎么自己漏成了筛子?
03
Anthropic “安全人设” 连续翻车
Claude Code 源码泄露不是孤立事件。就在几天前,Anthropic 刚刚经历了另一场大型泄露。
3 月 26 日,由于第三方 CMS 系统配置错误,Anthropic 近 3000 个内部资产被公开访问。
这批资产里曝光了一个代号 Capybara 的未发布模型 Claude Mythos。内部文件称其为 AI 能力的“阶跃式提升”。
泄露材料中关于 Mythos 能“以远超人类防御者的速度利用漏洞”的描述,直接导致几家网络安全公司股价下跌。
两周之内:一次 CMS 配置错误泄露了未发布模型,一次 source map 打包失误泄露了完整源码。
把时间线再拉长一点:Claude Code 在 2025 年 2 月首发时就已经泄露过一次 source map。
同一个错误,犯了两次。
事件本身的损害也许有限。有人说,护城河是模型,而不是 CLI。
核心模型权重、训练数据、用户数据都没有泄露,CLI 只是一个客户端包装。
但产品架构和完整的未发布功能路线图已经暴露。竞争对手等于是拿到了一份免费的技术蓝图。
对于一家把“AI 安全”写进公司使命的企业来说,运营安全反复失控所传递的信号,可能比技术漏洞本身更加致命。
这是 vibe coding 时代自动化构建流程带来的新型风险?还是高速迭代下质量控制的系统性缺失?
又或者,在一个 AI Agent 已经能自主写代码、提交 commit、管理发布流程的时代——谁能百分百确定这一定是人为失误呢?
04
写在最后
我们让 Claude Code 自己整理了一份对自己代码库的分析报告。
后台私信 “claude code” 获取。
(附:51 万行源码深度解析也已整理完毕,关注后私信即可获取。)