夜雨聆风
夜雨聆风





VoxCPM 拆解文档
1. 一句话概括
VoxCPM 用 AudioVAE 连续潜变量(按时间 patch)代替离散语音 token;MiniCPM4 式双路语言模型负责文本对齐的语义与残差声学上下文;Conditional Flow Matching + 局部 DiT 在每一步自回归中从噪声积分得到下一 patch 的潜变量,最后 VAE 解码为波形。即:无离散语音码本,但在潜空间仍做层次化建模。
2. 模块组成
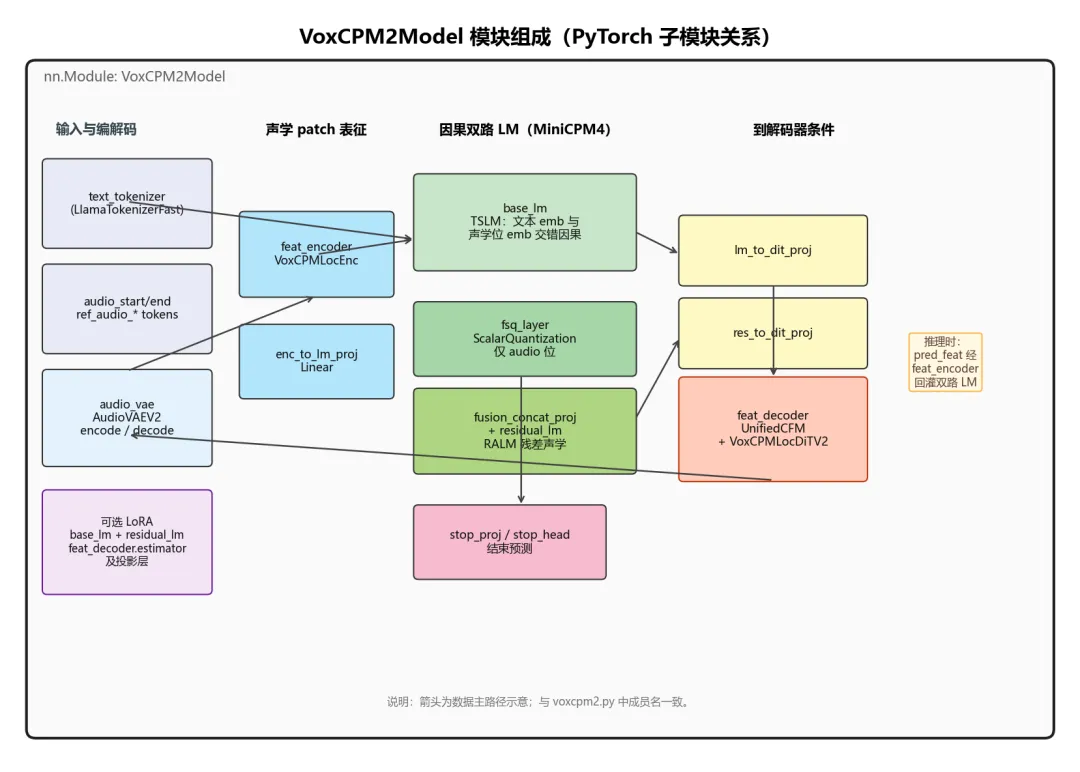
-
feat_encoder 即 LocEnc,把每个时间步的 P×D patch 压成 LM 可用的向量。
-
base_lm 与 residual_lm 共享「因果序列」思路,但输入不同:后者经 fusion_concat_proj 融合 base 输出与声学位特征。
-
feat_decoder 同时受 lm_to_dit_proj、res_to_dit_proj 两路条件驱动
-
可选 LoRA。
3. 架构原理
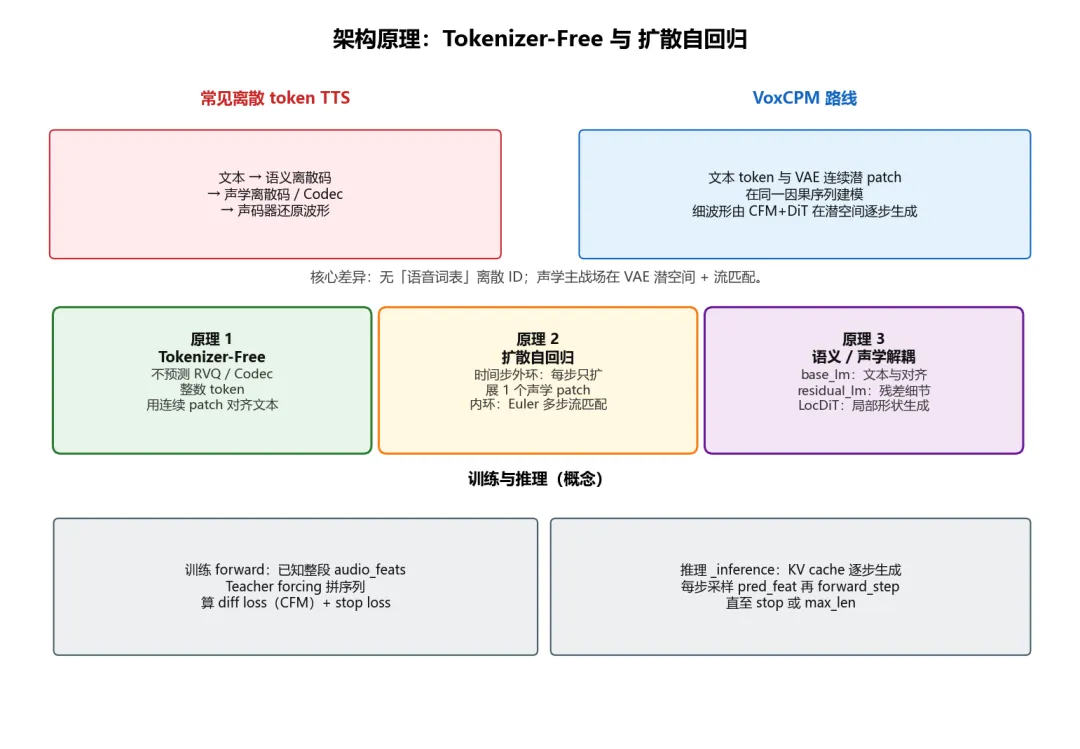
|
原理 |
含义 |
|
Tokenizer-Free |
不在中间阶段预测多码本离散 ID;声学以 VAE 潜变量 patch 与文本交错建模。 |
|
扩散自回归 |
外环:时间维逐步增加 patch;内环:每步用 CFM 在潜空间做多步积分(Euler + CFG)。 |
|
语义 / 声学解耦 |
TSLM 管对齐与高层语义;RALM 补残差;LocDiT 管局部 patch 形状与细节。 |
4. 总体流水线
下图概括从原始波形/参考音频到主干张量,再到声学解码的路径( LocEnc → TSLM → RALM → LocDiT )。
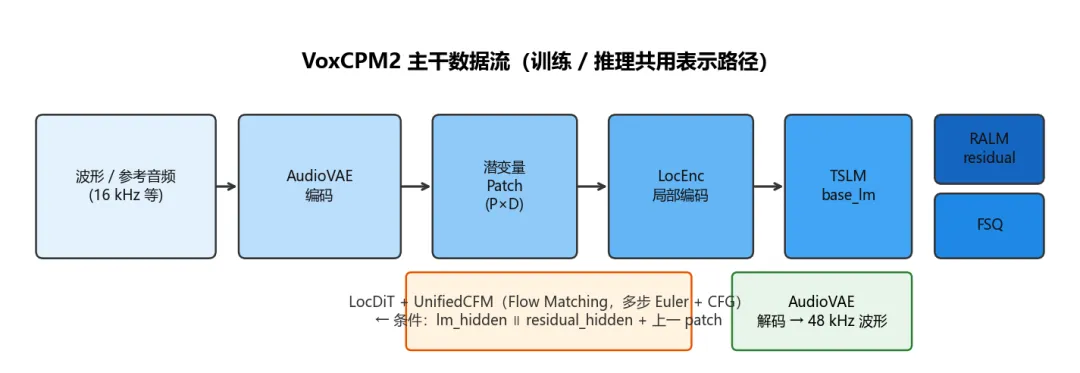
|
阶段 |
作用 |
|
AudioVAE |
波形 ↔ 低帧率潜序列;V2 支持非对称编解码与更高输出采样率 |
|
LocEnc |
每个时间步的 P×D patch 压成单个向量,供 LM 消费 |
|
TSLM |
文本 token 与声学位向量在同一因果序列中联合建模 |
|
RALM |
融合 base 输出与声学位特征,补残差声学信息 |
|
LocDiT + CFM |
以 LM 状态为条件,对下一 patch 做 Flow Matching 采样 |
5. 四大模块职责
5.1 LocEnc(局部编码器)
输入形状为 [B, T, P, D]:batch、时间、patch 内帧数、潜维度。对每个时间步,将 P 个向量与 可学习的 special token 拼成局部序列,经小型 Transformer 后取 CLS 位置作为该步嵌入,再投影进入主 LM。
5.2 TSLM / RALM
TSLM:text_mask 位置用文本 embedding,audio_mask 位置用 LocEnc 输出经 enc_to_lm_proj 后的向量;因果自注意力后,在 仅声学位 上通过 FSQ 层(见下节)。
RALM:将 base 的 enc_outputs 与 audio_mask * feat_embed 拼接,经 fusion_concat_proj 再送入第二路 MiniCPM,得到 residual_hidden。
5.3 LocDiT + UnifiedCFM
UnifiedCFM 在推理时从随机噪声出发,沿时间网格做 Euler 求解,步数由 inference_timesteps 控制;内部使用 Classifier-Free Guidance(与条件/无条件双分支相关)。估计器为 VoxCPMLocDiTV2,在 patch 维度上工作。
5.4 Stop 预测
stop_head 对 lm_hidden 做二分类,用于在 _inference 循环中提前结束生成,避免固定拖长到 max_len。
6. 推理:自回归 × Flow Matching
核心循环:先做 prefill 填满 KV cache,再 每步
用当前 hidden 构造 CFM 条件;
调用 feat_decoder 多步积分得到 pred_feat;
将 pred_feat 再编码回 LM 输入,执行 forward_step 推进;
直至 stop 或达到 max_len。
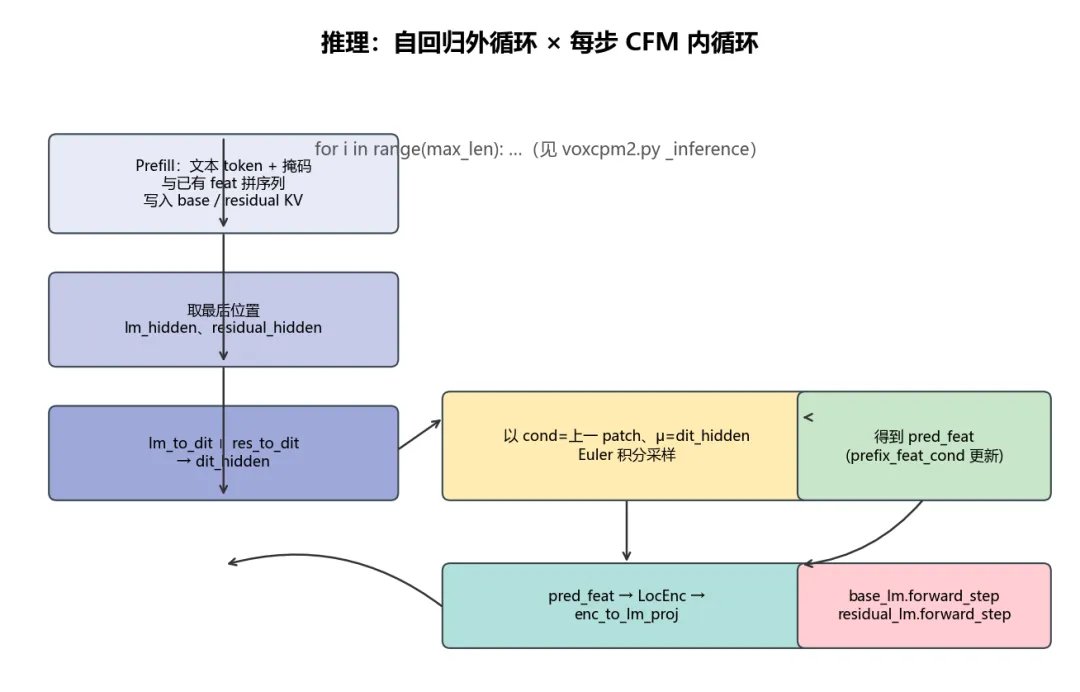
计算特点:外循环长度约等于生成 patch 数;内循环为 n_timesteps 次 DiT 前向(CFG 下常近似双倍),因此 RTF 与 inference_timesteps、cfg_value 强相关。
高吞吐场景可参考官方推荐的 Nano-vLLM-VoxCPM。
7. FSQ 与 Stop 头
ScalarQuantizationLayer 对 hidden 做 tanh、按 scale 做标量量化;
训练用 STE,推理直接 round。
在 forward / _inference 中仅作用于 audio_mask 为 1 的位置,文本位置保持原 hidden。
设计意图:在 连续潜空间 主流程之外,为 LM 的声学位增加 有限精度瓶颈,减轻 LM 直接记忆高频细节的压力,与「完全离散 token」路线不同。
8. VoxCPM2 条件模式
VoxCPM2 在 generate / build_prompt_cache 中通过 token 序列 + text_mask / audio_mask + feat 对齐 统一多种用法;下图从「序列拼装」角度示意(非严格张量尺寸)
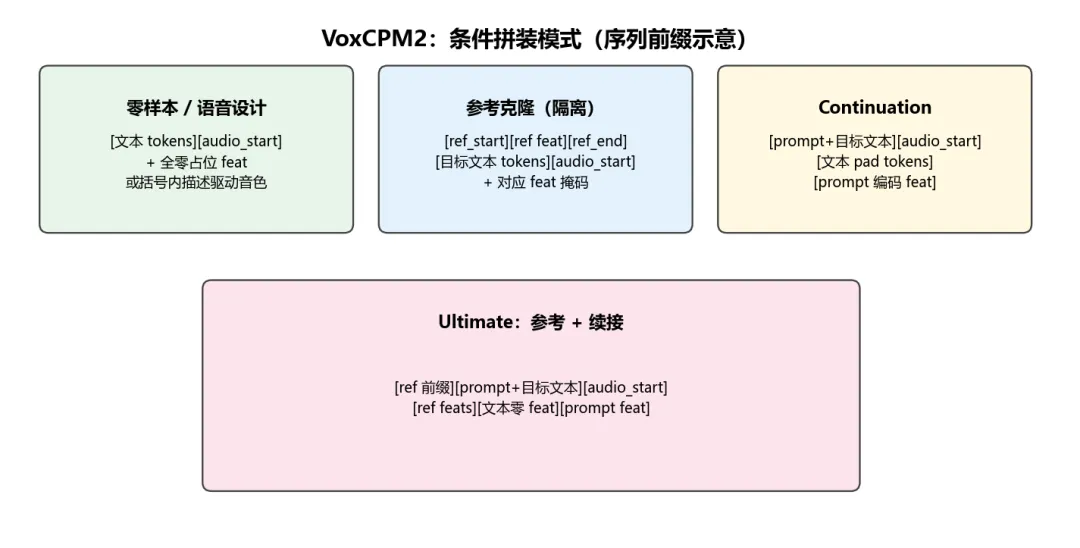
|
模式 |
说明 |
|
零样本 / 语音设计 |
文本侧占位 feat 全零;设计能力依赖训练与提示格式 |
|
参考克隆 |
ref_audio_start_token … ref_audio_end_token 包裹参考编码,与目标文本隔离 |
|
Continuation |
提示文本与目标拼接;feat 侧左段为零、右段为 prompt 编码 |
|
Ultimate |
参考前缀 + 文本段 + prompt 段拼接,兼顾音色与韵律延续 |
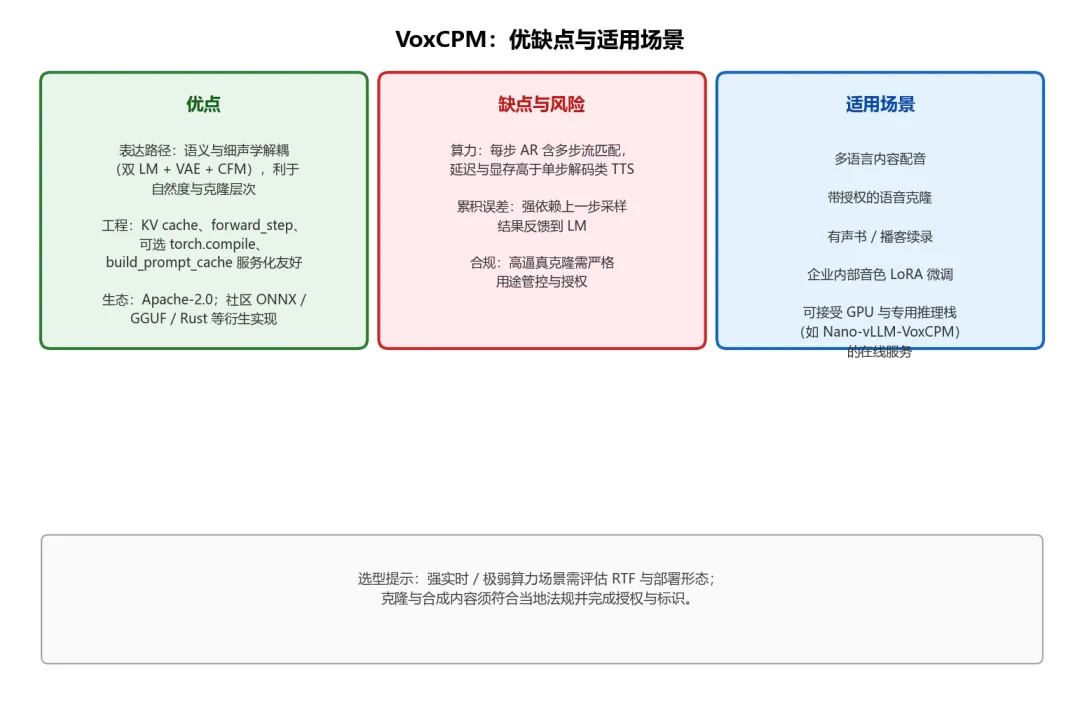
9. 优缺点与适用场景