 夜雨聆风
夜雨聆风





Motus 源码入门分析
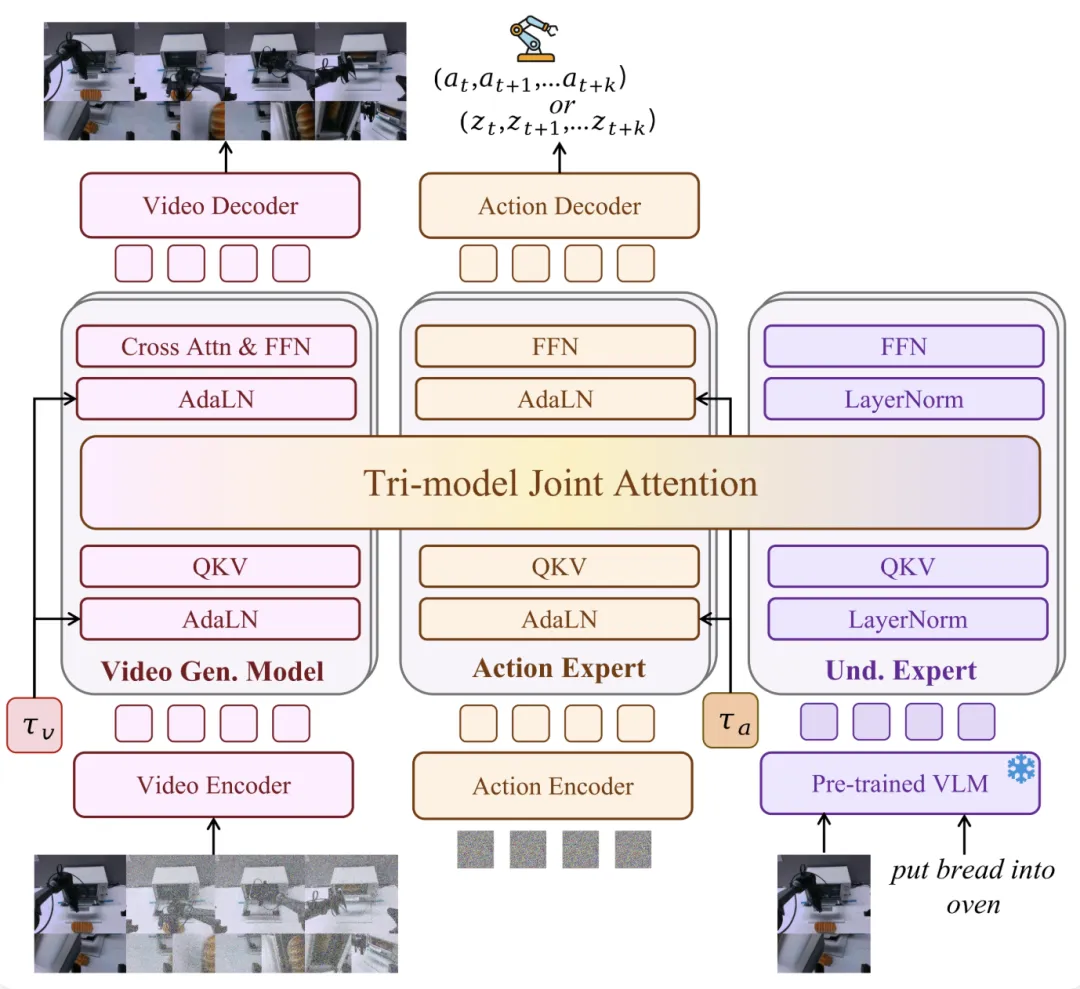
Motus 是一个联合 VLM 与 World Model 来共同用于机器人 action 预测的模型,它由三个 Expert 组成:WAN 2.2 作为 Video Expert,Qwen3-VL 作为理解 Expert,以及一个自定义的 Action Expert,在每一层里通过 self-attention 做三模态联合注意力:
如果先记一句话,可以把它理解成:
Motus = 冻结/半冻结的视频生成骨干(WAN) + 冻结的视觉语言骨干(Qwen3-VL) + 一个可训练的动作扩散分支 + 一个可训练的理解适配分支 + 三者在每层共享一次联合 self-attention
最核心的实现都集中在 models/motus.py、models/action_expert.py、models/und_expert.py 里。
一、Motus 的配置层:哪些超参在控制模型
MotusConfig 定义在 models/motus.py。里面最关键的是:
-
num_layers=30:三条分支层数对齐,做 1:1层级融合。 -
action_expert_dim、und_expert_hidden_size:决定动作分支和理解分支容量。 -
num_video_frames、video_action_freq_ratio:决定视频预测长度和动作 chunk 长度。 -
training_mode:pretrain 或 finetune,直接改变动作分支的输入形式。 -
load_pretrained_backbones:决定是否先加载 WAN/Qwen 的原始预训练权重。
一个很重要的 derived parameter 是 action chunk 的长度:action_chunk_size = num_video_frames * video_action_freq_ratio,比如 robotwin.yaml 中是 8 * 2 = 16。
视频生成模型是可以一次预测多个 frames,由参数
num_video_frames来决定,但要注意一个细节:
它在像素语义上是“一次预测 num_video_frames个未来帧”但在 latent 空间里,因为 WAN VAE 有时间压缩,所以不是一帧对应一个 latent frame,而是像 motus.py 那样用 1 + num_video_frames // 4个 latent frame 表示整段视频。
二、一个 training_step 是怎样的
一个 training_step() 是 Motus 的“单个 batch 联合训练主循环”。它做的事情其实很工整,主线就是:
-
把视频做成扩散训练样本 -
把动作也做成扩散训练样本 -
从 VLM 提取理解 token,从 T5 准备文本条件 -
让视频、动作、理解三条分支一起过 30 层 MoT -
分别预测视频 velocity 和动作 velocity -
算联合 loss
2.1 输入是什么
它接收的主要输入是:
-
first_frame: 当前观测帧,size 为 [B, C, H, W] -
video_frames: 未来若干帧,作为 target frames,size 为 [B, num_frames, C, H, W] -
state: 当前机器人状态, [B, state_dim] -
actions: 未来动作序列, [B, chunk_size, action_dim] -
language_embeddings: 给 WAN 用的 T5 文本特征 -
vlm_inputs: 给 Qwen3-VL 用的图文输入
所以这一步不是纯视频训练,也不是纯策略训练,而是视频、动作、语言、理解一起参与。
2.2 先处理视频分支
在函数前半段,它先把 first_frame 和 video_frames 拼成一个完整视频序列,然后送进 VAE 编码成 latent。接着它会像 diffusion / flow matching 一样:
-
随机采一个 timestep -
给视频 latent 加噪 -
构造训练目标 video_target = noise – clean
同时它保留第一帧作为条件帧,不让模型去预测它,而是 teacher forcing 固定住。所以视频分支学的不是“直接重建未来帧”,而是“预测视频 latent 的 velocity / residual”。
2.3 再处理动作分支
动作分支也做几乎同样的事:
-
对真实 action sequence 加噪 -
采样 action branch 的 timestep -
构造 action_target = noise – actions
然后根据训练模式决定动作 token 怎么构造:
-
pretrain:只输入 noisy actions -
finetune:输入 state + noisy actions
所以动作 expert 本质上也是一个扩散式动作预测器,不是普通的监督回归头。
2.4 提取理解分支和文本条件
接下来会准备两套语言/理解信息:
-
und_tokens = self.und_module.extract_und_features(vlm_inputs) -
这是从 Qwen3-VL 提取出来的理解 token -
processed_t5_context = self.video_module.preprocess_t5_embeddings(language_embeddings) -
这是给 WAN cross-attention 用的 T5 文本 embedding
这里非常关键的一点是:
-
Qwen3-VL 负责“视觉-语言理解” -
T5 embedding 负责“视频生成条件” -
两条条件通路同时存在
2.5 三模态一起过 MoT 主干
这是整个函数的核心。它会做一个 30 层循环。每层里顺序基本是:
-
计算 video/action 的时间调制参数 AdaLN -
做 trimodal joint attention -
video token -
action token -
understanding token -
一起进共享 attention -
视频分支再做一次 WAN 的 text cross-attention -
三个分支分别做各自的 FFN
所以每层不是串行“先理解再动作再视频”,而是:
-
先共享注意力融合 -
再私有 FFN 更新
这就是 Motus 最核心的实现思想。
2.6 最后分别出头
30 层之后:
-
视频分支用 WAN 的 output head 还原出视频 latent 的 velocity -
动作分支用 Action decoder 还原出动作 velocity
然后它会根据模式裁掉不需要的 token:
-
finetune 时,动作输出里第一个 token 对应 state,不参与动作 loss -
register token 也不参与动作监督
2.7 算 loss
最后 loss 很直接:
-
video_loss = MSE(video_pred, video_target),但会 mask 掉条件第一帧 -
action_loss = MSE(action_pred, action_target)
总 loss 就是:
-
total_loss = video_loss_weight * video_loss + action_loss_weight * action_loss
所以 training_step() 本质上是一个“视频 flow matching + 动作 flow matching”的联合训练。
training_step() 总结如下:
-
把未来视频和未来动作都加噪, -
再让视频 expert、动作 expert、理解 expert 在统一 transformer 里联合去噪, -
最终同时学习未来视觉动态和未来控制动态。
三. 三个 Expert 是如何拼起来的?
3.1 Video Expert:WAN 是主干,不只是一个条件模块
WAN 在 wan_model.py 中被包装成 WanVideoModel class,它负责如下功能。
1)用 VAE 把视频从像素空间编码到 latent 空间
defencode_video(self, video_pixels: torch.Tensor) -> torch.Tensor:
"""
Encode video pixels to latent space.
Args:
video_pixels: Video in pixel space [B, C, T, H, W], range [-1, 1]
Returns:
Video latents [B, C', T', H', W']
"""
with torch.no_grad():
return self.vae.encode(video_pixels)
这里 VAE 做了两类压缩:
-
空间压缩:H, W 变成 H/32, W/32 -
时间压缩:视频帧数被压缩
其中 H 和 W 分别表示 video_height 和 video_width。
这个 encode_video 的调用代码在训练代码中,如下:
clean_full_latent = self.video_model.encode_video(full_video.to(self.dtype))
condition_frame_latent = self.video_model.encode_video(first_frame_norm.to(self.dtype))
其中 clean_full_latent 是整段视频的 latent,它编码的是 full_video,而 full_video 是当前条件帧 first_frame 加上未来目标帧 video_frames 拼起来的一整段视频,所以它表示的是“完整真实视频序列”的 latent,用来作为视频扩散训练里的 clean sample,size 往往是 [B, 48, T_lat, H_lat, W_lat],例如 1 张条件帧 + 8 张未来帧时,可能是 [B, 48, 3, 12, 10]。后来的 clean_full_latent 还会被用于加 noisy 并构建训练目标 video_target:
noisy_video_latent = clean_full_latent * (1 - sigma) + video_noise * sigma
noisy_video_latent[:, :, 0:1] = condition_frame_latent
video_target = video_noise - clean_full_latent
video_target[:, :, 0:1] = 0
为什么 9 帧得到的 latent 里 只有 3? 因为代码里模型并不是逐像素逐帧在 latent 中保留原始时间长度,而是经过 WAN VAE 的时间压缩。对于条件帧 + 8 帧未来帧,总共 9 帧,latent 时间长度是:
1 + num_video_frames // 4 = 1 + 8//4 = 3,可以粗略理解成:第 1 个 latent frame 对应条件帧,后面 2 个 latent frame 表示未来 8 帧的压缩时序信息。所以这个视频生成模型虽然语义上预测 8 帧,但内部不是 8 个显式时间步 token,而是更紧凑的 latent 时序表示。
当然,还有一个对应的反向方法:decode_video:
defdecode_video(self, video_latents: torch.Tensor) -> torch.Tensor:
"""
Decode video latents to pixel space.
Args:
video_latents: Video latents [B, C, T, H, W]
Returns:
Video pixels [B, C', T', H', W'], range [-1, 1]
"""
with torch.no_grad():
video_pixels = []
for i in range(video_latents.shape[0]):
pixels = self.vae.decode([video_latents[i]])[0]
video_pixels.append(pixels)
result = torch.stack(video_pixels, dim=0)
return result
2)用 WAN 的 patch embedding 把视频 latent 变成 token
Video Expert 并不是直接拿一个 5D 的视频 latent 张量去做 transformer,而是先把它切成一串可被 transformer 处理的“视频 token”。所以需要 patch embedding 来把视频 latent 变成 token。
这个代码如下:
video_patched = self.video_model.wan_model.patch_embedding(noisy_video_latent)
video_features = video_patched.flatten(2).transpose(1, 2)
可以把它分成两步理解。
path_embedding 在做什么
输入的 noisy_video_latent 是一个 5D 张量,size 为 [B, C, T, H, W],比如 [B, 48, 3, 12, 10]。但这仍然是“网格状”的时空特征图,不是 transformer 喜欢的序列格式。所以 patch embedding 的作用就是把这个视频 latent 是做一个时空体,对这个时空体做局部 patch 投影,然后把每个局部 patch 映射到 WAN 的隐藏维度 3072,输出就变成 [B, 3072, T', H', W']。在 Motus 的代码实现中,时空分辨率通常没再改,更多是通道从 48 -> 3072。
为什么还要 flatten + transpose
Transformer 模型需要的是序列 [B, seq_len, hidden_dim],而不是 3D 网络 [B, hidden_dim, T', H', W'],所以需要先通过 video_patched.flatten(2) 将 (T', H', W') 三个维度展平成一个长度 [B, 3072, T'*H'*W'];然后再 .transpose(1,2) 变成 [B, T'*H'*W', 3072],这就是 video tokens。
比如原本 latent 是 [B, 48, 3, 12, 10],经过转换后就变成了 [B, 360, 3072],这时的 360 个 tokens,每个 token 对应一个时空位置。后面 WAN 的 self-attention 就是在这些 tokens 上做建模。
3)用 WAN 的 time_embedding / time_projection 做扩散时间调制
在扩散模型里,模型不能只看 noisy sample,还得知道“现在噪声强度处于哪一个 timestep”。所以每次 forward 时,都把时间步 t 编码成一个 vector 再注入到网络里。
在 Motus 的视频分支中,它直接复用 WAN 原本的时间调制机制 time_embedding / time_projection 来实现的这一点。具体原理可以参考 WAN。
4)用 WAN 的 cross_attn 消化 T5 文本 embedding
这块是 Video Expert 里“语言条件怎么注入视频生成”的主通路。
在 training_step() 中传进来的 language_embeddings 是预先编码好的 T5 embedding,来自于数据集中预存的 umt5_wan/*.pt:
-
每条样本是一串 token embedding -
单个 token embedding 维度通常是4096 -
序列长度不固定
将 T5 Embedding 通过 cross-attn 传入到 WAN model 的核心代码:
defprocess_cross_attention(self, video_tokens, video_adaln_params, layer_idx, processed_t5_context):
wan_layer = self.video_model.wan_model.blocks[layer_idx]
context_lens = None
cross_out = wan_layer.cross_attn(
wan_layer.norm3(video_tokens),
processed_t5_context,
context_lens
)
return video_tokens + cross_out
-
当前层的视频 token 先经过 norm3 -
把文本 embedding 当作 context -
用 WAN block 自带的 cross_attn 做跨模态注意力 -
输出再 residual 加回视频 token
你可以把它理解成:
-
视频 token 去“读”文本 token -
文本 token 不更新,视频 token 被文本条件修正
5)用 WAN 的 self_attn 作为整个三模态联合注意力的“宿主”
Video Expert 不仅仅是“也参加注意力”这么简单,而是:
-
真正执行注意力计算的那套算子、head 组织方式、RoPE、时空布局,都是 WAN 自己的 self_attn -
Action Expert 和 Understanding Expert 并不各自再写一套完整 attention -
它们只是把自己的 token 投影到 WAN attention 所使用的 head space 里 -
然后统一交给 WAN 的 self_attn 一次性完成三模态联合注意力
3.2 Action Expert:不是独立 transformer,而是“借 WAN attention 的动作分支”
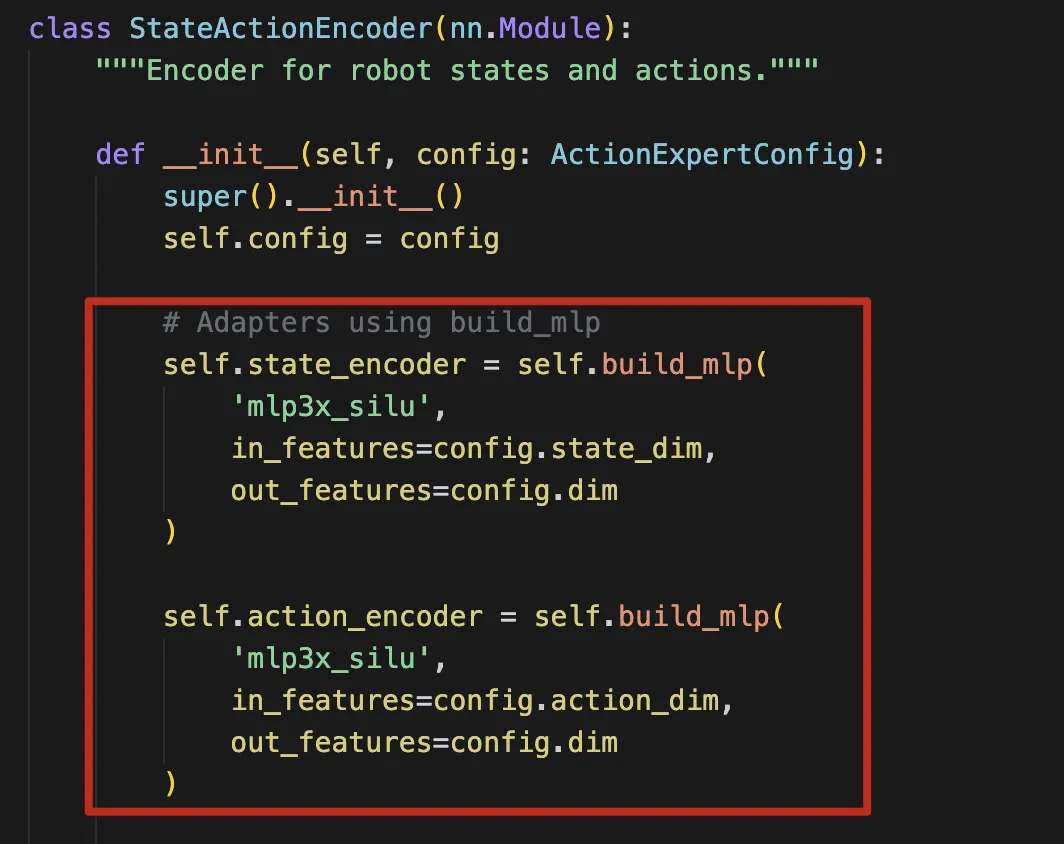
动作分支定义在 models/action_expert.py。
输入编码器分成两种:
-
StateActionEncoder:finetune 时输入 state + noisy actions -
ActionEncoder:pretrain 时只输入 noisy actions
每层 ActionExpertBlock 不自己实现完整 self-attention,而是提供:
-
wan_action_qkv -
wan_action_o -
自己的 norm1/norm2 -
自己的 FFN -
自己的 AdaLN modulation
所以它本质上是:
-
attention 部分借 WAN 的 self-attn 内核 -
FFN、输入编码、输出解码是自己独立的
具体来说,Action Expert 自己并没有完整实现一套“从头到尾独立运行的 self-attention”,而是把自己的 action token 先投影成 WAN attention 能读懂的 Q/K/V,再交给 WAN 的 self_attn 去真正完成注意力计算。
Action Expert 自己有什么:ActionExpertBlock 里包含:
-
norm1/norm2 -
wan_action_qkv -
wan_action_o -
wan_action_norm_q -
wan_action_norm_k -
自己的ffn -
自己的modulation
也就是说,它有:(i)把 action token 映射到 attention 空间的参数;(ii)attention 后再映射回 action 空间的参数;(iii)自己的 FFN。
但它没有什么:它没有自己真正执行 softmax(QK^T / sqrt(d)) V 这一步计算,也就是没有自己管理:
-
视频时空 RoPE -
WAN 的 head 组织方式 -
真正的 multi-head attention kernel
这些都交给了 WAN block 的 self_attn。
大致的完整链条如下:
-
action token -
wan_action_qkv投成 WAN attention 的 Q/K/V -
WAN self_attn统一做注意力 -
wan_action_o投回 action 空间 -
residual 更新
具体细节可以参考原代码。
为什么这样设计?
-
复用 WAN 已经训练好的注意力结构 -
让动作 token 和视频 token 在同一个 attention 图里交互 -
少写一套独立 attention,参数和实现都更省 -
保持“共享 attention,分离 FFN”的 MoT 结构
3.3 Understanding Expert:本质是一个 VLM 特征适配器 + MoT 分支
理解分支在 models/und_expert.py。
它非常轻量,做的事情是:
-
从 Qwen3-VL 的 hidden states 取特征 -
用 vlm_adapter 从2048 -> 512做投影 -
每层通过 wan_und_qkv投到 WAN head space,参加联合 attention
它没有 decoder,也没有 register token。
所以理解分支在这个实现里更像一个“condition carrier”,作用是把图像+指令理解后产生的 token,持续注入三模态联合 attention。
3.4 最核心的实现:Tri-model Joint Attention

VideoModule.process_joint_attention() 做了几件事:
-
先对视频 token 做 WAN 风格 AdaLN 归一化。 -
对 action token 做 ActionExpert 自己的归一化。 -
把 action token 用 wan_action_qkv投成 WAN 头空间的 q/k/v。 -
把 und token 用 wan_und_qkv投成 WAN 头空间的 q/k/v。 -
调用 wan_layer.self_attn(...),把 video/action/und 三组 token 一起送进同一个 attention。 -
attention 输出后: -
视频输出直接 residual 到 video token -
动作输出再用 wan_action_o 投回动作空间 -
理解输出再用 wan_und_o 投回理解空间
所以它不是 “video attends to action” 这种显式 cross-attn,而是更强的:
-
三种 token 在同一个 attention 图里共同竞争注意力权重 -
但每个模态的 FFN 和 norm 是各自独立的
四、Understanding 分支到底从 Qwen3-VL 里拿了什么
理解特征提取在 motus.py 中,流程是:
-
dataset 里先把 instruction + first_frame 处理成 Qwen3-VL processor 输入。 -
_process_vlm_inputs_to_tokens()把 input_ids、pixel_values、image_grid_thw 和 attention_mask 转成 VLM 可直接 forward 的 token/position 形式 -
调 self.vlm_model.model.language_model(..., output_hidden_states=True)。 -
只取 hidden_states[-1],也就是最后一层输出 -
用 und_expert.vlm_adapter压到 und hidden dim。
五、训练时在学什么:联合 flow-matching
它不是传统的自回归 action prediction,而是视频和动作都做 flow matching / diffusion-style velocity prediction。
5.1 视频分支
-
把 first_frame + future video_frames 拼成完整视频 -
用 VAE 编到 latent 空间 -
对 latent 做噪声混合: -
noisy = clean * (1-sigma) + noise * sigma -
第一帧始终 teacher forcing,直接替换成真实条件帧 latent -
目标是预测 velocity:noise – clean
所以视频头输出的不是重建帧,而是 flow matching velocity。
5.2 动作分支
-
对动作序列也做同样的 noise interpolation -
目标同样是 action_noise - actions
所以动作 expert 也是 diffusion-style 的,不是一次性回归 clean action。
5.3 三模态 forward
每层顺序是:
-
trimodal joint self-attention -
WAN cross-attn with T5 -
三个模态各做自己的 FFN
这个顺序很关键。它说明:
-
“视觉-动作-理解”先在共享注意力里融合 -
然后视频分支再额外吸收 T5 文本 -
再各自做私有非线性变换
5.4 loss 函数
-
视频 loss:MSE,且 mask 掉第一帧 -
动作 loss:MSE -
最终加权和
六、推理时是怎么 rollout 的?
流程是:
-
用首帧编码出 condition latent -
视频未来 latent 随机初始化 -
动作 latent 随机初始化 -
提前算一次 T5 context 和 VLM tokens -
做从 t=1 -> 0 的迭代 denoising -
每一步: -
当前 video/action latent 转成 token -
走完整个 30 层 MoT -
得到 video_velocity 和 action_velocity -
用 Euler 方法更新 latent -
再把第一帧 latent 强制设回 condition
最终:
-
视频 latent decode 成未来视频帧 -
动作 latent 直接作为预测动作输出
很关键的一点是:当前正式启用的是最简单的 Euler integration。文件里虽然保留了更复杂的 DPM++ / UniPC 版本,但都被注释掉了。
七、训练模式的差别:pretrain 和 finetune 到底怎么切
pretrain
-
training_mode: “pretrain” -
动作输入只有 latent action,没有 state -
ActionEncoder 被启用 -
register token 数量设为 0 -
action loss 对象是 latent action,而不是机器人真实关节动作
finetune
-
training_mode 默认是 finetune -
动作输入是 state + action -
StateActionEncoder 被启用 -
有 4 个 register token -
可以调用 load_pretrain_weights()从 pretrain checkpoint 迁移,但会跳过 action input encoder 和 decoder
这个迁移策略很合理: 因为 pretrain 阶段是 action-only latent action,finetune 阶段变成 state-conditioned real action,所以输入头和输出头不完全兼容。
register token可以理解成一类“额外插进去的可学习记忆 token”。它们不对应真实的状态、动作或图像 patch,而是模型自己带着的一小组辅助槽位,用来存全局信息、跨 token 汇总信息,或者给注意力提供中转站。register token 不代表真实物理量,没有显式语义标签,它更像是模型为了更好地做注意力和信息汇总,自己拥有的几个“空白记事本”。在 Motus 里,你可以把它理解成:
给动作分支额外几个全局 memory slot
让 action token 在和 video/understanding token 联合 attention 时,有地方暂存全局控制信息
什么在 finetune 里有,而 pretrain 里没有?直觉上说,latent-action 预训练阶段任务更简单,可以先不加 memory token;真实机器人 finetune 时,state-conditioned action prediction 更复杂,加入少量 register token 有助于建模。
八、总结
从代码实现上看,Motus 并不是简单把 VLM、World Model 和 Policy 拼接起来,而是围绕 WAN 这一视频生成主干,构建了一个真正统一的三模态生成框架:视频分支负责世界动态建模,理解分支负责提供视觉语言语义,动作分支负责未来控制序列预测,而三者在每一层里通过共享 self-attention 发生深度融合。也正因为如此,Motus 学到的不是孤立的“看图做动作”映射,而是一种同时建模视觉未来、动作未来与任务语义的联合表示。