 夜雨聆风
夜雨聆风





电商AI助手:用户嘴上说想要,实际却依赖什么?——一项多方法研究揭秘功能需求错配
英文标题:Say-one-thing-and-mean-another consumers? A multi-method study of functional demand mismatch in e-commerce AI assistants
作者:Shuai Chen, Yang Zhao
期刊:Journal of Retailing and Consumer Services, 2026, Vol. 89, 104561
DOI:10.1016/j.jretconser.2025.104561
📌 一句话摘要
电商AI助手的功能开发往往是“技术驱动”而非“用户需求驱动”。研究发现:用户主观偏好的功能(如智能定价)与客观依赖的功能(如24小时自动回复)存在显著错配。平台应区分“基础型功能”与“成长型功能”,采取双轨策略。
🧠 研究背景:AI助手遍地开花,但真的懂用户吗?
淘宝的“AI购物助手”、京东的“京言”、亚马逊的“Rufus”……各大电商平台纷纷集成大语言模型(LLM)和自然语言处理(NLP)技术,试图用AI重塑购物体验。
然而,这些AI功能真的是用户想要的吗?
目前,AI助手功能的开发仍以“技术驱动”为主——工程师有什么技术就上什么功能,而忽略了用户的真实需求。用户往往自己也说不清想要什么,导致供需错配。
问题:用户“主观偏好”与“客观需求”之间,到底存在怎样的结构性差异?
🎯 研究目标
本研究提出一个多源数据融合框架,结合:
-
BERTopic主题建模(分析海量用户评论,提取客观需求)
-
语义嵌入映射(将用户话题与AI功能对齐)
-
MaxDiff偏好实验(测量用户主观偏好)
最终揭示AI助手功能的供需错配,并为平台提供功能优先级排序依据。
📚 理论基础
🔹 Andersen行为模型
用户需求可分为两类:
-
主观需求:用户自己认为需要的功能
-
客观需求:基于外部数据(如行为、评论)推断出的真实依赖
两者往往不一致——这正是本研究的切入点。
🔹 BERTopic
一种结合预训练语言模型与聚类的无监督主题建模技术,流程包括:文本编码 → UMAP降维 → HDBSCAN聚类 → c-TF-IDF提取关键词。
🔹 MaxDiff(最大差异 scaling)
一种多属性比较方法:让用户从一组功能中选出最想要和最不想要的,从而测量偏好强度。相比李克特量表,MaxDiff能避免“中庸偏向”,区分度更高。
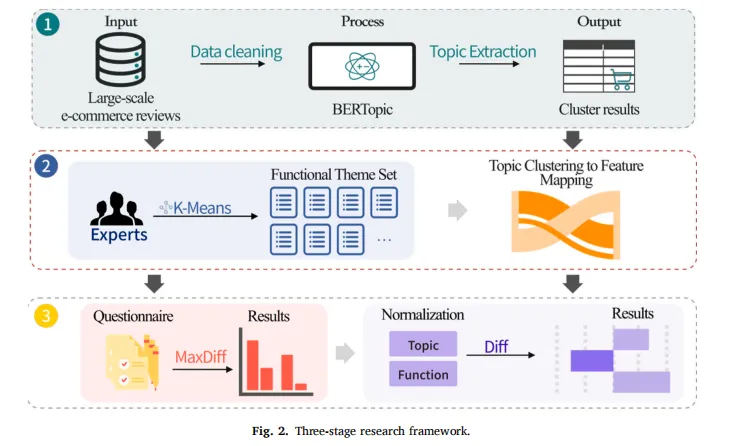
🧪 研究设计与方法(三阶段框架)
阶段一:用户评论挖掘(客观需求)
-
数据来源:天池平台“RecTmall”数据集,共11,224,814条评论,取前600万条分析
-
情感分析:使用SnowNLP,提取负面评论(评分<0.5),得到1,718,723条负面评论
-
分词与高频词统计:Jieba分词 + 四川大学机器智能实验室停用词表
-
主题建模:BERTopic(UMAP: n_neighbors=10, n_components=5; HDBSCAN: min_cluster_size=100),最终得到50个核心用户话题
📊 高频负面词示例:物流、速度、卖家、客服、态度、色差、价格……
阶段二:AI功能提取与语义映射
-
专家调查:通过Credamo平台邀请75名电商与HCI领域专家,开放问卷收集AI助手的典型应用场景,最终保留35份有效回复(161条文本)
-
文本编码:使用预训练模型
paraphrase-multilingual-MiniLM-L12-v2生成语义向量 -
聚类:KMeans聚类 + TF-IDF关键词提取,人工标注出8大核心AI功能:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
-
语义映射:计算50个用户话题向量与8个功能向量的余弦相似度,保留 top-3 且 >0.2 的匹配,生成桑基图(Sankey diagram)。
-
客观重要性(EBI):聚合每个功能的所有匹配相似度,得到嵌入重要性值。
阶段三:MaxDiff用户偏好实验(主观偏好)
-
被试:通过Credamo招募291名活跃电商用户,经质量筛选后保留246份有效问卷(女性68.7%,21-30岁占52.8%)
-
实验设计:8个功能属性,使用平衡不完全区组设计,每位用户在8个任务中分别选出 “最希望优先开发” 和 “最不希望开发” 的功能
-
统计模型:多项logit模型(Multinomial Logit),计算每个功能的偏好份额(归一化)
-
错配计算:Diff = 客观重要性(EBI) − 主观偏好份额
由于样本量较小,不使用±1σ,而是分别取正、负Diff值的中位数作为阈值,识别显著错配功能。
📊 主要结果
✅ 功能错配分布(Diff值)
下图展示了8个功能的Diff值分布:
-
正Diff(客观 > 主观):24小时自动回复、客服调度、物流监控
-
负Diff(主观 > 客观):智能定价、虚拟试穿、多模态搜索
-
接近零:个性化推荐、情感化交互
🔍 详细结果如图4所示(原文Fig. 4)。
🧭 功能分类:两类截然不同的角色
|
|
|
|
|
|---|---|---|---|
| 基础型功能 |
|
|
|
| 成长型功能 |
|
|
|
💡 个性化推荐和情感化交互处于中间地带,供需相对匹配。
💡 理论贡献
-
整合框架:首次将BERTopic主题建模与MaxDiff偏好实验结合,实现客观需求与主观偏好的量化对比。
-
拓展Andersen模型:将“主客观需求二分法”应用于新兴技术(AI助手)场景,揭示错配机制。
-
可复用的方法论:为后续人-AI协作、技术接受研究提供了结构化的需求分析工具。
🛠 实践启示(双轨产品策略)
🔧 基础型功能(如24小时回复、客服调度)
-
策略:防御型(Defensive Strategy)
-
持续提升算法稳定性与知识覆盖
-
通过界面设计增强“可见价值”,例如提示“AI已为您节省XX秒”
-
避免因“隐形效用”导致的负面评价
🚀 成长型功能(如智能定价、虚拟试穿)
-
策略:进攻型(Offensive Strategy)——MVP先行
-
优先上线高敏感度功能,小范围试点
-
建立用户反馈闭环,积累高质量数据
-
同时关注透明度、公平性与算法可解释性,降低用户焦虑
🌍 更广泛的社会责任
-
基础型功能需关注老年人、低数字素养群体的可及性
-
成长型功能需平衡商业效率与社会包容性
⚠️ 研究局限
-
客观需求的代理变量为负面评论,可能无法捕捉潜在的新兴需求
-
MaxDiff测量的是相对偏好,未必完全反映真实行为
-
功能分类具有时效性,随技术和市场变化可能调整
-
未使用传统信效度检验(如Cronbach’s α),但通过多方法三角验证(评论挖掘+专家评估+MaxDiff)增强稳健性
-
数据来源仅淘宝平台,未来需跨平台、跨文化验证
📌 总结一句话
用户对AI助手的“嘴上说想要”和“实际离不开”往往是两回事。平台需要区分基础型功能(默默支撑但易被忽视)和成长型功能(用户渴望但尚未实现),采取双轨策略,才能真正实现以用户为中心的AI创新。
📚 参考文献(部分)
-
Chen, S., Zhao, Y. (2026). Say-one-thing-and-mean-another consumers? Journal of Retailing and Consumer Services, 89, 104561.
-
Grootendorst, M. (2022). BERTopic: Neural topic modeling with a class-based TF-IDF procedure. arXiv.
-
Cohen, S. (2003). Maximum difference scaling. Sawtooth Software Research Paper.
英文文献阅读全流程:从文献如何“搜”到怎么“管”再到“读”的一站式攻略


END
点击关注,发送 “AI Consumer” 即可获取全文PDF