 夜雨聆风
夜雨聆风





FastWAM 源码入门分析
1. FastWAM 论文的核心做法
FastWAM 也是以世界模型(World Model)作为 backbone 构建的机器人控制模型,其核心理念是: 在训练时保留视频共训练(保持世界建模能力),但在推理时跳过未来预测(直接生成动作),从而解耦这两个因素。
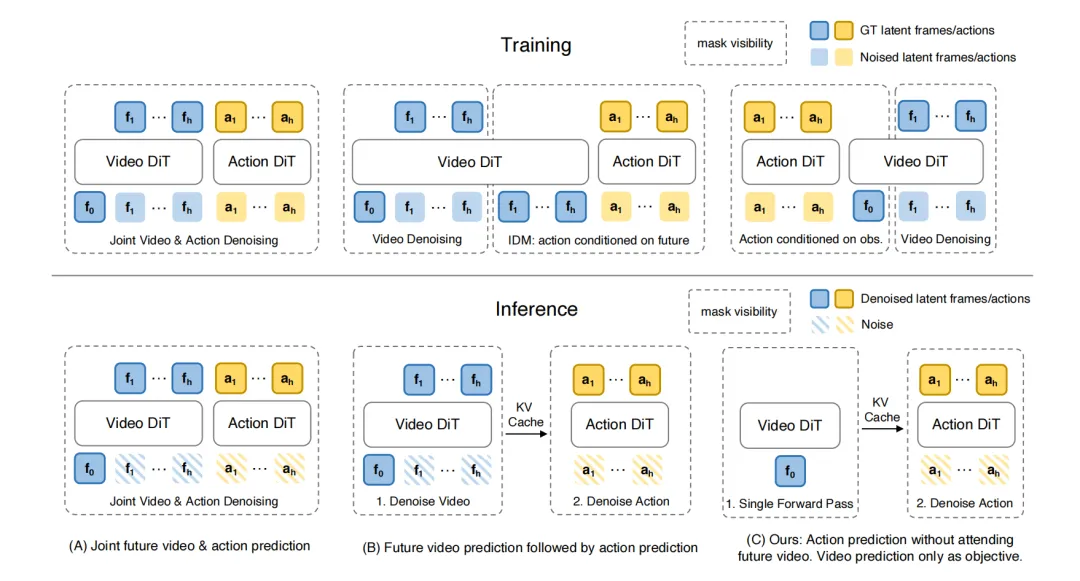
FastWAM 关键设计
关键设计:
-
训练阶段:联合优化动作生成和视频去噪目标,让视频 DiT 学习物理有意义的运动和交互结构 -
推理阶段:不显式生成未来视频帧,而是将视频 DiT 作为单次前向世界编码器,直接输出潜在表示供动作专家使用 -
控制实验:构建多个对照变体来隔离变量: -
Fast-WAM-Joint:联合去噪未来视频和动作(传统 WAM 范式 A) -
Fast-WAM-IDM:先生成未来视频,再条件化预测动作(传统 WAM 范式 B) -
Fast-WAM w.o. video co-train:移除视频共训练目标,作为对照组
主要发现:
-
Fast-WAM(无显式未来生成)与 imagine-then-execute 变体性能相当 -
移除视频共训练导致性能显著下降,说明视频预测的主要价值在于训练时改善世界表示,而非测试时生成未来观察 -
推理延迟仅为 190ms,比现有 imagine-then-execute WAMs 快 4 倍以上
模型架构
基础骨干: 基于预训练的 Wan2.2-5B(视频扩散 Transformer),包含视频 DiT、文本编码器和视频 VAE。
架构组件(Mixture-of-Transformer, MoT):
输入层:
├── 文本编码器 (T5):编码任务指令,通过 Cross-Attention 提供给所有 token
├── VAE 编码器:将视觉观察映射为潜在视频 token
└── 动作编码器:处理动作块
核心架构(共享注意力机制):
├── Video DiT(视频分支):
│ └── 处理观察帧的潜在 token(第一帧为干净 token,未来帧为噪声 token,仅训练时使用)
└── Action DiT(动作专家分支,1B 参数):
└── 处理动作 token,维度 d_a = 1024
注意力掩码设计(关键创新):
├── 训练时:
│ ├── 未来视频 token 可在视频分支内双向交互,并可访问第一帧
│ ├── 动作 token 可在动作分支内双向交互,并可访问第一帧
│ └── 动作 token 不能访问未来视频 token(防止未来信息泄露)
└── 推理时:
└── 仅保留第一帧干净 token,通过 Video DiT 单次前向传递 → 生成世界潜在表示 z(o,l) → 供 Action DiT 去噪动作
训练目标:
-
联合流匹配损失: -
:动作生成(flow matching on action tokens) -
:视频共训练(flow matching on future video latents)
推理流程:
-
当前观察帧通过 VAE 编码为干净潜在 token -
单次通过 Video DiT → 获得世界潜在表示 -
Action DiT 基于 和语言指令,通过 10 步去噪生成动作块 -
完全跳过未来视频帧的生成,实现实时推理(190ms 延迟)
2. FastWAM 代码库的结构
FastWAM 代码库可以按 4 层来理解:
-
Hydra 配置层
-
入口是 scripts/train.py和configs/train.yaml。 -
任务配置会把 data/model/task 拼起来,例如 configs/task/libero_uncond_2cam224_1e-4.yaml选择data=libero_2cam、model=fastwam。
-
训练运行层
训练主链在 src/fastwam/runtime.py 和 src/fastwam/trainer.py。
-
run_training()做三件事:实例化模型、实例化数据集、交给 Wan22Trainer。 -
Wan22Trainer只优化 model.dit,而在 FastWAM 里 model.dit = model.mot,这说明真正被 finetune 的核心是 MoT 主干,而不是整个 Wan 全量参数。
-
模型实现层
最核心的文件是:
-
src/fastwam/models/wan22/fastwam.py -
src/fastwam/models/wan22/fastwam_joint.py -
src/fastwam/models/wan22/fastwam_idm.py -
src/fastwam/models/wan22/mot.py -
src/fastwam/models/wan22/action_dit.py
-
数据与评测层
-
数据主入口是 src/fastwam/datasets/lerobot/robot_video_dataset.py和src/fastwam/datasets/lerobot/processors/fastwam_processor.py。 -
LIBERO 评测看 experiments/libero/eval_libero_single.py,RoboTwin 部署看experiments/robotwin/fastwam_policy/deploy_policy.py。
3. FastWAM 模型代码实现
如果只用一句话概括源码结构:FastWAM = Wan 视频专家 + ActionDiT 动作专家 + MoT 共享多层注意力 + VAE + 可选文本编码器
3.1 顶层类 FastWAM
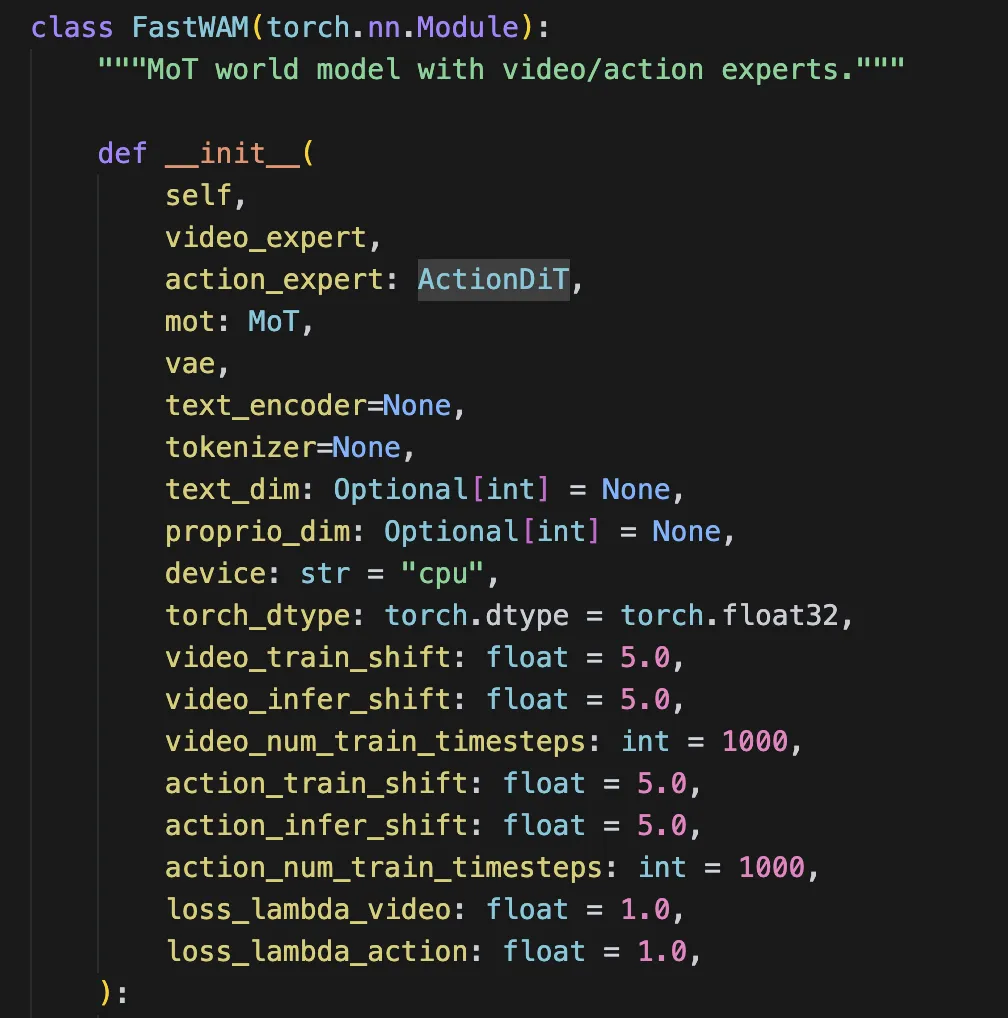
它的构造函数里挂了这些核心成员:
-
self.video_expert:视频分支,类型是 WanVideoDiT -
self.action_expert:动作分支,类型是 ActionDiT -
self.mot:把两路 expert 拼起来做混合注意力 -
self.vae:视频 VAE,用来把像素视频编码到 latent -
self.text_encoder/self.tokenizer: 文本编码器,训练时通常不加载,改用预缓存 context -
self.proprio_encoder: 把机器人状态映射到文本维度,作为额外一个 conditioning token -
train/infer video scheduler -
train/infer action scheduler
还有一个很关键的小设计:self.dit = self.mot,这是为了兼容训练器,因为训练器默认只训练 model.dit。在 FastWAM 里这意味着真正被训练的是 MoT,而不是把整个 Wan 模型当黑盒端到端训练。
3.2 视频专家 WanVideoDiT 代码
代码位于 wan_video_dit.py 中,它本质上是一个视频 latent Transformer,组成如下:
-
patch_embedding:Conv3d,把 VAE latent 切成 patch token -
text_embedding: 把文本 token 映射到 Transformer hidden dim -
time_embedding + time_projection:生成时间步调制向量t_mod -
blocks: 多层 DiTBlock -
head: 把 token 还原回视频 latent patch
它的输入不是 RGB,而是 VAE latent,shape 是 [B, C, T, H, W],然后通过 patchify() 变成 token 序列:
x_tokens: [B, S, D]
S = f * h * w
这里的 f,h,w 是 latent patch 网格大小。
这样,最终视频会被切成 token 序列 S = num_frames * tokens_per_frame,tokens_per_frame 表示一帧 latent 图像对应多少个 patch token。
pre_dit() 是这个类最重要的函数之一,它负责做 5 件事:
-
检查输入 shape -
把视频 latent patchify 成 token -
生成 3D RoPE 位置编码 freqs -
生成时间调制 t_mod -
把文本 context 也投影到 hidden dim
最终返回一个字典:
-
tokens -
freqs -
t_mod -
context -
context_mask -
meta.grid_size -
meta.tokens_per_frame
这里的 tokens_per_frame 非常重要,后面做 attention mask 时会用它判断“哪些 token 属于第一帧”。
3.3 DiTBlock 每层在干什么
DiTBlock 是一个单层结构,每层都是标准 DiT 风格:
-
norm1 -> self-attn -
norm3 -> cross-attn(text/proprio) -
norm2 -> FFN
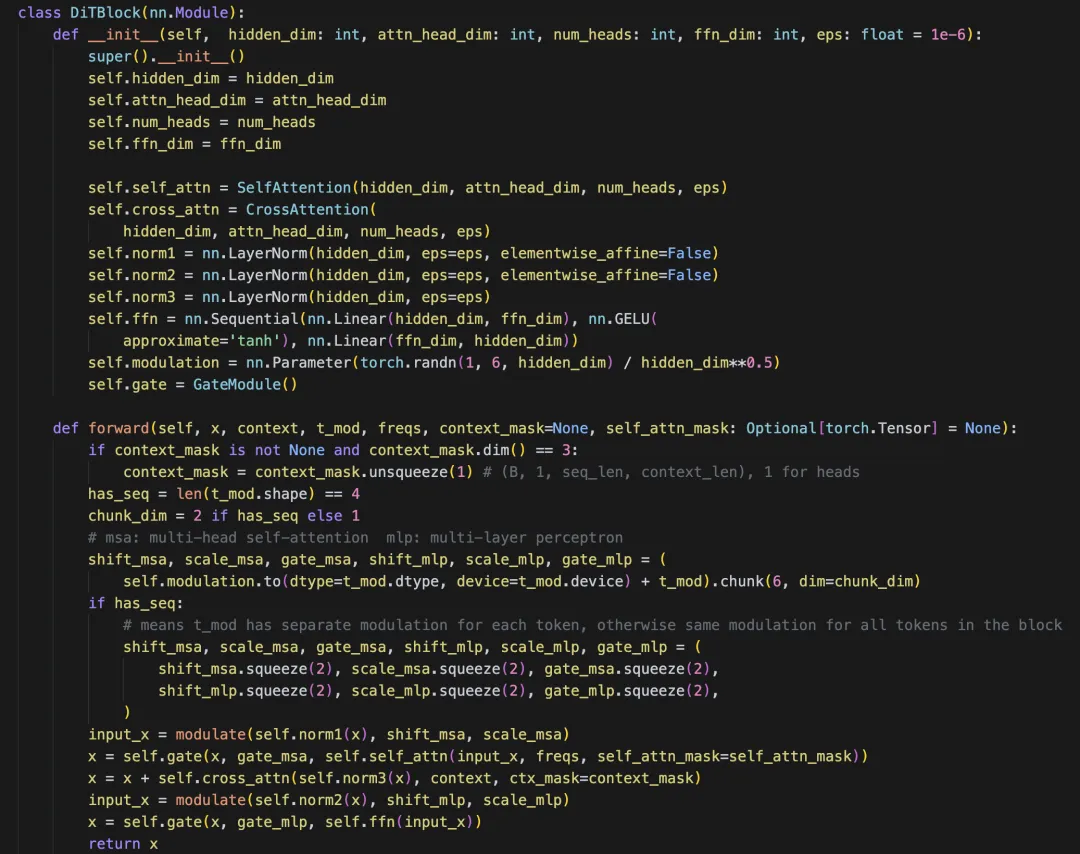
但它不是普通 residual,而是用 time modulation 做 FiLM 风格调制:
-
shift_msa, scale_msa, gate_msa -
shift_mlp, scale_mlp, gate_mlp
也就是每层都被 diffusion timestep 控制。这个调制不是在顶层做一次,而是每层都做。
timestep 作为调制信号
扩散模型里的 timestep t 表示“当前噪声有多大”。网络在不同的 t 下,应该需要做不同的事情:
-
噪声很大时,要更偏向粗粒度恢复 -
噪声很小时,要更偏向细节修正
在代码实现上,先在 pre_dit() 里把 timestep 编码成向量:
-
sinusoidal_embedding_1d(self.freq_dim, timestep) -
过 time_embedding -
再过 time_projection
最后得到 t_mod
对于视频分支来说,t_mod 被整理成和每层调制对应的结构,大致可理解为:
-
每层需要 6 组调制参数 -
分别给 attention 和 MLP 用
在 DiTBlock.forward() 里,这行代码最关键:
shift_msa, scale_msa, gate_msa, shift_mlp, scale_mlp, gate_mlp = ...
这 6 个量来自:
-
block 自己的可学习参数 self.modulation -
加上 timestep 生成的 t_mod
所以每一层都会得到一套“与当前 timestep 相关”的控制参数。
这些参数怎么作用到 block 里?主要有两处。
第一处,控制 self-attention 之前的输入:
input_x = modulate(self.norm1(x), shift_msa, scale_msa)
x = self.gate(x, gate_msa, self.self_attn(...))
也就是 timestep 会决定:
-
attention 前输入怎么缩放、平移 -
attention 输出残差该加多少
第二处,控制 MLP 之前的输入:
input_x = modulate(self.norm2(x), shift_mlp, scale_mlp)
x = self.gate(x, gate_mlp, self.ffn(input_x))
也就是 timestep 还会决定:
-
MLP 前特征怎么调制 -
MLP 残差强度有多大
所以不是简单地“把 t 拼到输入里”,而是:
-
timestep -> 生成调制参数 -
调制参数 -> 改写每层 attention/MLP 的工作方式
这就是 DiT 里常见的 AdaLN / FiLM 式 conditioning。
Video Expert 中的注意力模式
在视频专家里,self-attention 的 mask 可以切换模式,见 build_video_to_video_mask():
-
bidirectional:所有视频 token 都可以互相看见,不区分过去、当前、未来。如果你想把第一帧当作“测试时可用观测”,这种模式不适合 FastWAM 的核心设定。 -
per_frame_causal:以“帧”为单位做因果 masking,每个 frame 只能看到以前的 frames,看不到未来 frames,同一 frame 内的所有 patch tokens 彼此全可见。 -
first_frame_causal:第一帧是特殊锚点,第一帧 token 不能看后面的帧,后面的帧可以看第一帧,也可以彼此互看。这是 FastWAM 默认用的模式。
FastWAM 默认配置用的是 first_frame_causal。这很关键,因为它让第一帧成为一个特殊的信息锚点:
-
训练时第一帧对应“真实当前观测” -
未来帧是噪声 latent,需要被建模 -
推理时只保留第一帧,所以训练时也希望第一帧表征不要依赖未来帧,避免信息泄露 -
同时又希望未来帧在训练里能充分交互,学到更强的视频世界表示
所以它本质上是一个“保护首帧因果性,但放松未来帧之间约束”的折中设计。
3.4 动作专家 ActionDiT 是怎么写的?
动作专家的代码实现在 action_dit.py 中。它和视频专家非常像,但简化很多:
-
输入是动作 token [B, T_action, action_dim] -
action_encoder 先升维到 hidden dim -
也有 text_embedding -
也有 time_embedding / time_projection -
也有一串 DiTBlock -
最后 head 直接回归动作噪声
最关键的约束是它必须和视频专家“层数、头数、head dim 完全一致”,因为 MoT 要在每一层把两边的 Q/K/V 拼起来混合注意力。这个检查在 FastWAM.from_wan22_pretrained() 里写得很明确。
3.5 MoT 到底做了什么
MoT 在 mot.py 中实现,是最核心的“共享世界表征”实现。
它不是简单地把两个网络串联,而是:
-
对 video expert 当前层,算出 q_v, k_v, v_v -
对 action expert 当前层,算出 q_a, k_a, v_a -
把两路在序列维拼起来: -
q_cat = [q_v, q_a] -
k_cat = [k_v, k_a] -
v_cat = [v_v, v_a] -
用一个联合的 attention_mask 做一次 mixed attention -
再把输出切回 video/action 两支,分别走各自 block 的后半段
所以论文里的 “Mixture-of-Transformer with shared attention” 在代码里就是这套 “每层 QKV 拼接 + 联合 mask” 的实现。
你可以把它理解成:
-
token embedding、输出头、MLP、cross-attn 都还是 expert-specific -
只有 self-attention 的 token mixing 是共享的
3.6 FastWAM 主方法的 forward 逻辑
论文主方法对应 FastWAM.training_loss() 和 FastWAM.infer_action()。
训练时
-
build_inputs(),把 video/action/proprio/context 读进来,并用 VAE 编码视频 -
视频 latent 加噪,得到 latents -
动作序列加噪,得到 noisy_action -
video_expert.pre_dit(...)和action_expert.pre_dit(...)分别把两路 token 变成 Transformer 输入。 -
_build_mot_attention_mask(...)决定谁能看谁 -
self.mot(...)做共享 mixed attention -
video_expert.post_dit(...)和action_expert.post_dit(...)分别回到视频预测和动作预测 -
算 loss_video + lambda * loss_action
这里最关键的是 _build_mot_attention_mask(),在 FastWAM 主方法里规则是:
-
video -> video: 按视频分支自己的 mask -
action -> action: 全可见 -
action -> video: 只能看第一帧 token
这正是论文里“训练时有视频共训练,但动作不直接偷看未来视频”的代码落点。
推理时
FastWAM 相比于以往的 WAM 方法,推理速度加快了。他的推理逻辑是:
-
只把当前图像编码成 first_frame_latents -
用 video_expert.pre_dit()得到视频 token -
用 mot.prefill_video_cache()一次性把视频分支每一层的 K/V 全缓存下来 -
后续动作去噪每一步,只跑 action branch -
action branch 通过 forward_action_with_video_cache()去访问缓存的视频 K/V -
完全不 rollout 未来视频 latent
也就是说,FastWAM 在测试时不是“先生成未来,再预测动作”,而是:首帧 -> 世界 latent cache -> 动作去噪
这个 cache 机制就在 prefill_video_cache() 和 forward_action_with_video_cache()。
3.7 scheduler 在模型里的角色
扩散/flow matching 调度器在 scheduler_continuous.py。
视频和动作各自有一套:
-
sample_training_t(): 训练时采 timestep -
add_noise(): 加噪 -
training_target(): 目标是noise - sample -
build_inference_schedule(): 推理时生成步长 -
step(): 更新 latent
所以 FastWAM 是“视频 diffusion + 动作 diffusion”双调度器并行存在,只不过在主方法测试时只真正迭代动作那一路。
四、部署模型
部署模型的相关代码在 deploy_policy.py 中,它展示了真实控制时的接口边界:
-
把当前 observation 转成拼接图像 -
归一化机器人状态为 proprio -
调 model.infer_action(...) -
再把输出反归一化成环境动作