 夜雨聆风
夜雨聆风





Claude Code 源码架构深度解析:Harness Engineering 究竟解决了什么工程问题?
sdfsdf
2026 年 3 月 31 日,Anthropic 工程师推了一个 npm 包更新,顺手把调试用的 source map 文件一起塞了进去。
那个 source map 文件指向自家 Cloudflare R2 上的一个公开 ZIP 包,里面是 Claude Code 完整的 TypeScript 源码:51.2 万行,1906 个文件。
几小时内,全球工程师把它扒光了。
工程师们发现的不是模型权重,不是训练数据,而是一件让很多人沉默的事:Claude Code 好用,根本不是因为用了更好的模型,而是因为有一套极其认真的工程架构在驱动它。
这套架构,有个名字叫 Harness Engineering。
本文会从源码出发,逐层拆解 Claude Code 的核心架构:Query Loop、工具系统、多层上下文压缩、权限体系、多 Agent 协调。读完之后,你会明白为什么同样调 Claude API,Claude Code 和你自己写的 Agent 表现差距如此悬殊——以及你能从中借鉴什么。
先搞清楚:Harness 是什么
很多人把 AI Agent 理解成”LLM + 工具调用”。这没错,但不完整。
一个能真正在生产中稳定运行的 Agent,需要的是:
-
• 怎么给模型喂干净的输入(不是原始对话,是经过治理的上下文) -
• 模型输出之后,怎么调度工具执行(不是随便跑,是有权限管控的) -
• 出错了怎么恢复(不是崩掉,是按照恢复策略继续工作) -
• 上下文快满了怎么压缩(不是截断,是保留工作语义的摘要) -
• 多个 Agent 协作时怎么隔离状态(不是共享内存,是受控的状态传递)
把以上这些工程问题全部处理好,包裹在模型调用外面的那层结构,就是 Harness。
下图是 Claude Code 整体架构的五层视图:
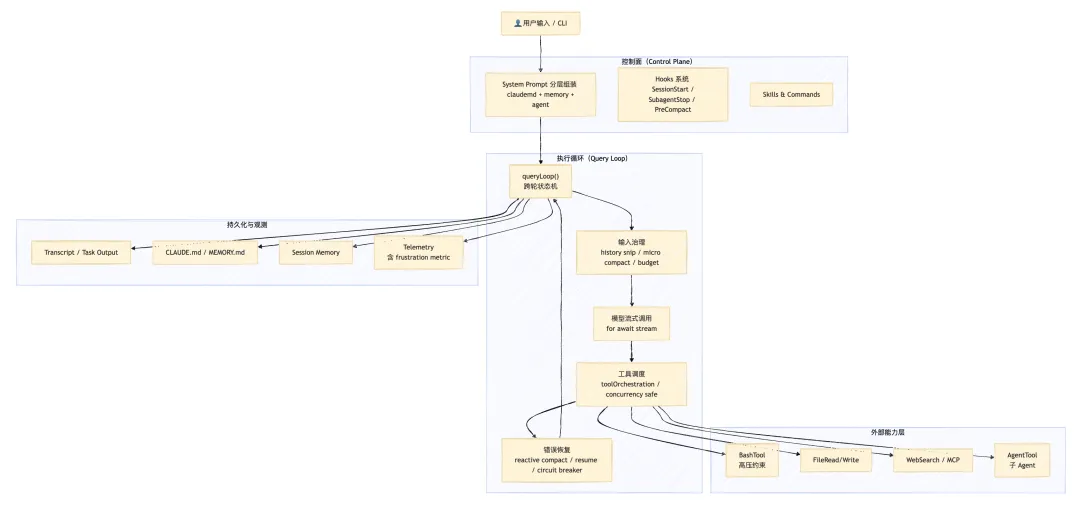
接下来,我们逐层拆开看。
第一层:Query Loop——心跳,不是问答
很多 AI 工具把每次对话当成独立的请求-响应。Claude Code 不是。
它的核心是 src/query.ts 里的 queryLoop(),一个持续运行的有状态执行循环。
先看它在每轮调用模型之前会做什么:
// src/query.ts(简化示意)async function* queryLoop(state: State, ...) { while (shouldContinue(state)) { // ① 输入治理阶段(模型调用前) await prefetchMemoryAndSkills(state) // 预取 memory / skill state.messages = sliceAfterCompactBoundary(state.messages) // 截取有效消息 state.messages = applyToolResultBudget(state.messages) // 压缩大 tool result state.messages = historySnip(state.messages) // 裁剪过长历史 await tryMicroCompact(state) // 就地编辑缓存 await tryContextCollapse(state) // staged collapse 提交 await tryAutoCompact(state) // 阈值触发全量压缩 // ② 模型调用阶段(流式消费) for await (const event of streamModel(state)) { // 处理 text delta / tool_use block / usage / stop_reason } // ③ 工具执行阶段 if (hasToolUse) { await runTools(state) } // ④ 错误恢复 / 继续决策 state = await handleRecovery(state) }}关键点是循环维护的跨轮状态对象 State,它包含:
|
|
|
|---|---|
messages |
|
toolUseContext |
|
autoCompactTracking |
|
maxOutputTokensRecoveryCount |
|
hasAttemptedReactiveCompact |
|
turnCount |
|
transition |
|
为什么要维护这套状态?
因为代理系统的失败不是偶发的,是结构性的。prompt too long 会来,max_output_tokens 会来,用户会打断,工具会超时。没有跨轮状态,每次出问题都要从头开始,等于设计上直接放弃了长任务的可用性。
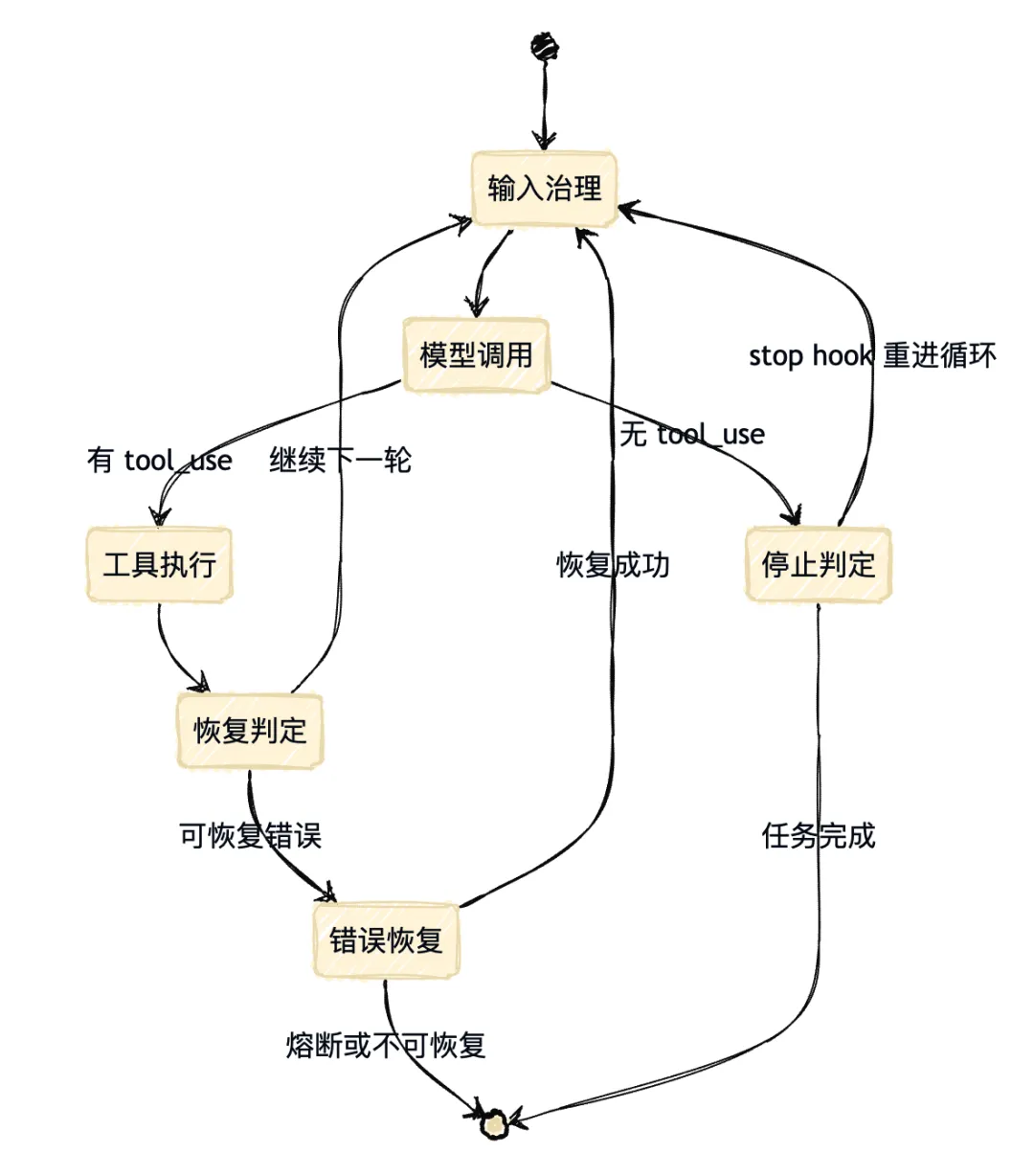
工程洞察: 一个 Agent 是否成熟,最直接的判断标准不是它能做什么,而是它在第 20 轮对话仍然知道自己在做什么。Query Loop 的跨轮状态,是这种连续性的物质基础。
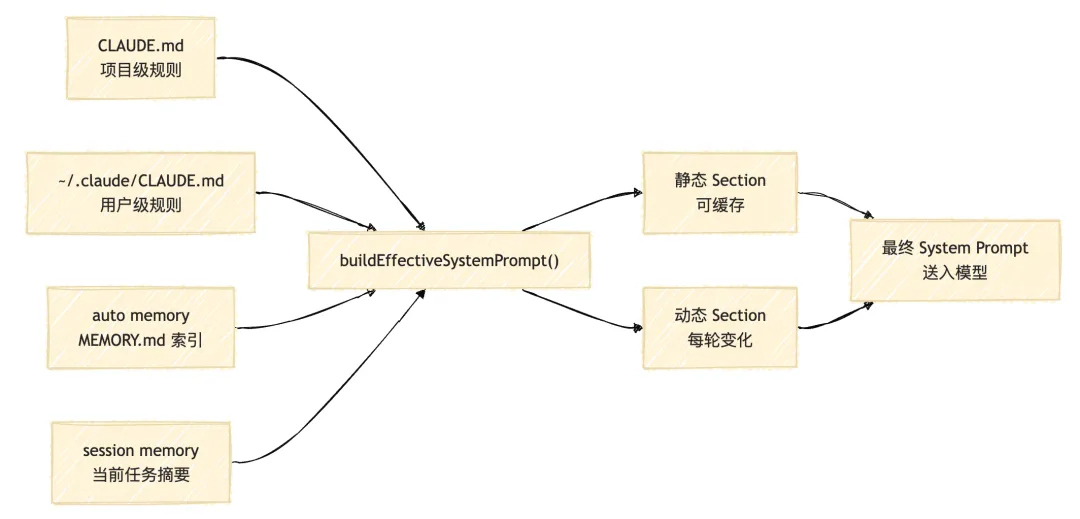
第二层:System Prompt 分层组装——控制面,不是文案
Claude Code 的 system prompt 不是一段话,是一套按优先级动态拼装的控制结构。
在 src/utils/systemPrompt.ts 的 buildEffectiveSystemPrompt() 中,优先级链如下:
override system prompt ← 最高优先级 ↓coordinator system prompt ← 多 Agent 协调者模式 ↓agent system prompt ← 子 Agent 专属行为 ↓custom system prompt ← 用户自定义 ↓default system prompt ← 基线约束 ↓append system prompt ← 全局追加在 src/constants/prompts.ts 的 getSystemPrompt() 里,返回的不是字符串,是一个按段组织的数组,每段对应不同的控制职责:
-
• 身份与总任务(第 175 行起):代理角色定义、安全边界(如不猜测 URL) -
• 系统级规则(第 186 行起):工具调用触发审批、被拒绝后不能机械重试、tool result 内嵌 system reminder -
• 工程性约束(第 199 行起):不要越权改动、不要把”验证失败”说成”验证通过”、不要在没必要时制造抽象
还有一个性能细节:src/constants/systemPromptSections.ts 把 prompt section 分成两类:
// 可被 prompt cache 命中的静态部分type CacheableSection = { type: 'cacheable'; content: string }// 每轮都会变化、会打破缓存的动态部分type UncachedSection = { type: 'DANGEROUS_uncached'; content: string }为什么叫 DANGEROUS_uncached?因为动态 section 每次都会导致 cache miss,直接拉高 token 成本。Anthropic 工程师用这个命名,是在给自己的团队提醒:这个字段要谨慎加内容。
第三层:工具系统——受管执行接口
Claude Code 默认启用约 19 个工具,完整工具集超过 60 个。工具系统的核心设计有三点。
设计一:工具调度先分批,再执行
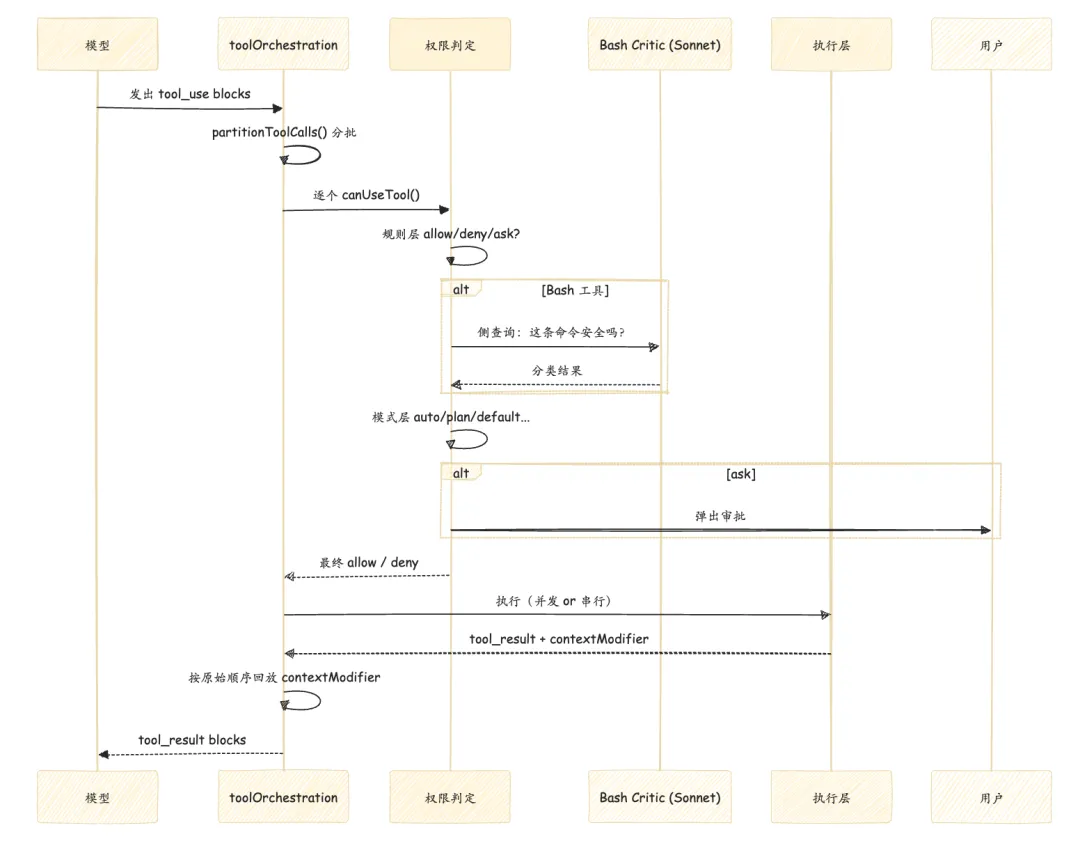
src/services/tools/toolOrchestration.ts 的 runTools() 收到一批 tool_use block 之后,第一件事不是执行,而是分组:
// 伪代码示意async function runTools(toolUseBlocks: ToolUseBlock[]) { const batches = partitionToolCalls(toolUseBlocks) // batches[0] = 并发安全组(可并行跑) // batches[1..n] = 串行组(一个一个来) for (const batch of batches) { if (batch.isConcurrentSafe) { // 并发执行,但 contextModifier 按原始 block 顺序回放 const results = await Promise.all(batch.map(runToolUse)) replayModifiersInOriginalOrder(results) } else { // 串行,直接修改上下文 for (const tool of batch) { await runToolUse(tool) } } }}关键细节:即使工具并发执行,contextModifier(修改当前上下文的副作用)仍然按原始 block 顺序回放。并发提升吞吐量,但因果顺序不能乱。
设计二:权限判定是独立语义,不是布尔值
src/utils/permissions/PermissionResult.ts 里,权限结果有三种:allow、deny、ask。
ask 这个状态很重要。它意味着系统承认存在”运行时自己不该决定”的情况。ask 路径会触发人工审批流程,这是把”理解意图”和”拥有授权”显式分开的设计。
六种权限模式(default、acceptEdits、plan、auto、dontAsk、bypassPermissions)控制哪些操作走哪条路径。auto 模式下,一个基于 Sonnet 4.6 的后台分类器(注意:这个分类器看到的是工具调用,但看不到模型的推理文本)来判断某个操作是否需要人工确认。Anthropic 特意让分类器不看模型的推理,原因是防止模型”说服”分类器放行危险操作。
设计三:Bash 是特等公民
src/tools/BashTool/bashPermissions.ts 专门为 Bash 做了一套独立的安全判定,包括:
-
• shell 语义解析(处理管道、重定向、复合命令) -
• 命令前缀白名单 / 黑名单 -
• subcommand 数量上限(防止复合命令绕过检查) -
• 安全环境变量过滤 -
• 基于 Sonnet 的侧查询(”这条命令安全吗?”——把命令单独发给模型做 critic)
为什么要这么复杂?因为 Bash 的攻击面是无边界的。越通用的接口,越需要越细的规矩。
第四层:三层上下文压缩——工作内存管理
这是整个 Harness 里对外部工程团队最有直接借鉴价值的部分。
Claude Code 使用三种策略,分级触发,成本从低到高:
Level 1:MicroCompact(就地编辑,零 API 调用)
当历史消息里的 tool result 体积过大,直接在缓存里截断旧的工具输出,把大 result 替换为摘要占位符。没有 API 调用,没有延迟,对用户完全透明。
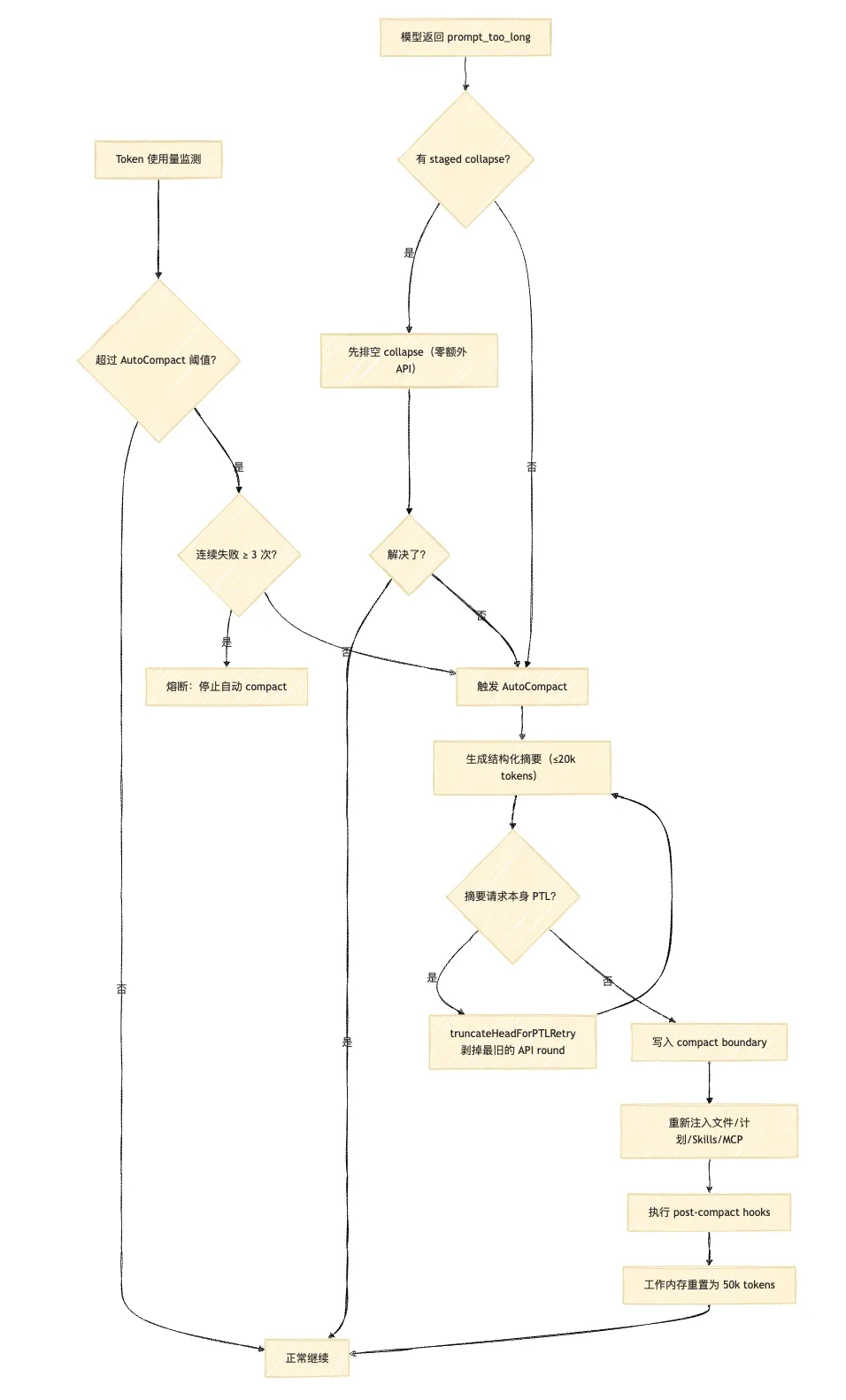
Level 2:AutoCompact(阈值触发,带熔断)
触发条件:当前上下文 token 数超过有效窗口 – 13000(AUTOCOMPACT_BUFFER_TOKENS)。
执行逻辑:
-
1. 预留 20000 tokens 给 summary 输出( MAX_OUTPUT_TOKENS_FOR_SUMMARY) -
2. 调用模型生成结构化摘要 -
3. 用 compact boundary message 标记压缩点,记录 pre-compact token 数 -
4. 清空旧的 readFileState,重新注入必要 attachment
熔断机制:AutoCompactTrackingState.consecutiveFailures 计数,超过 3 次停止自动触发。
// autoCompact.ts 关键逻辑(简化)const MAX_CONSECUTIVE_AUTOCOMPACT_FAILURES = 3function shouldAutoCompact(tracking: AutoCompactTrackingState): boolean { if (tracking.consecutiveFailures >= MAX_CONSECUTIVE_AUTOCOMPACT_FAILURES) { return false // 熔断:别再烧 API 了 } return currentTokens > effectiveWindowSize - AUTOCOMPACT_BUFFER_TOKENS}Level 3:ReactiveCompact(被动触发,最后一道防线)
当模型调用返回 prompt_too_long 错误时触发。按成本从低到高排列的处理顺序:
① 先排空已 staged 的 context collapse → 成本最低② 进入 reactive compact,生成摘要 → 一次 API 调用③ compact 自身也 prompt too long? → truncateHeadForPTLRetry() (把最旧的 API round 成组剥掉,缩小 compact 请求体)④ 连续失败?跳过 stop hooks,直接 surface 错误为什么 compact 请求本身也会 prompt too long?因为 compact 需要把整段历史发给模型做摘要,如果历史本身已经极长,摘要请求也会超限。Anthropic 用 truncateHeadForPTLRetry 解决这个”救火工具本身着火”的问题。
Compact 成功后,系统会重新注入以下内容(不然 compact 后等于失忆):
✅ 清空旧 readFileState✅ 重新注入最近访问文件(每文件上限 5000 tokens)✅ 重新注入 plan attachment✅ 重新注入 plan mode 标记(不然模型忘了自己在 plan 模式)✅ 重新注入 invoked skills(含 per-skill token 上限)✅ 重新注入 deferred tools / MCP instructions delta✅ 执行 post-compact hooks✅ 写入 compact boundary message(记录 pre-compact token 数和边界)工程洞察: Compact 的目标不是生成一份好总结,而是重建”下一轮能继续干活”的运行时环境。这是两个根本不同的目标。
第五层:多 Agent 架构——状态隔离,职责分工
src/utils/forkedAgent.ts 里的注释直接说明了 forked agent 的第一职责:
1. 与父 Agent 共享 cache-critical params,确保 prompt cache hit2. 跟踪整个 query loop 的 usage3. 记录指标4. 隔离可变状态,防止干扰主循环注意顺序:cache 命中率放在第一位。原因是 forked agent 会继承父 agent 的上下文,如果 systemPrompt、userContext、toolUseContext 等参数和父请求不一致,prompt cache 就无法共享,等于每个子 agent 都在烧全量 token。
createSubagentContext() 默认行为:
// 默认隔离的字段readFileState: cloneDeep(parent.readFileState) // 克隆,不共享abortController: new AbortController() // 子 abort controllersetAppState: noOp // 写回操作默认禁用permissionDenials: new Set() // 独立集合// 只有显式 opt-in 才共享shareSetAppState?: booleanshareAbortController?: boolean这是”默认安全”原则:子 Agent 的本地状态变化(读取的文件、中间决策、临时工具结果)不会自动污染父 Agent 的上下文。
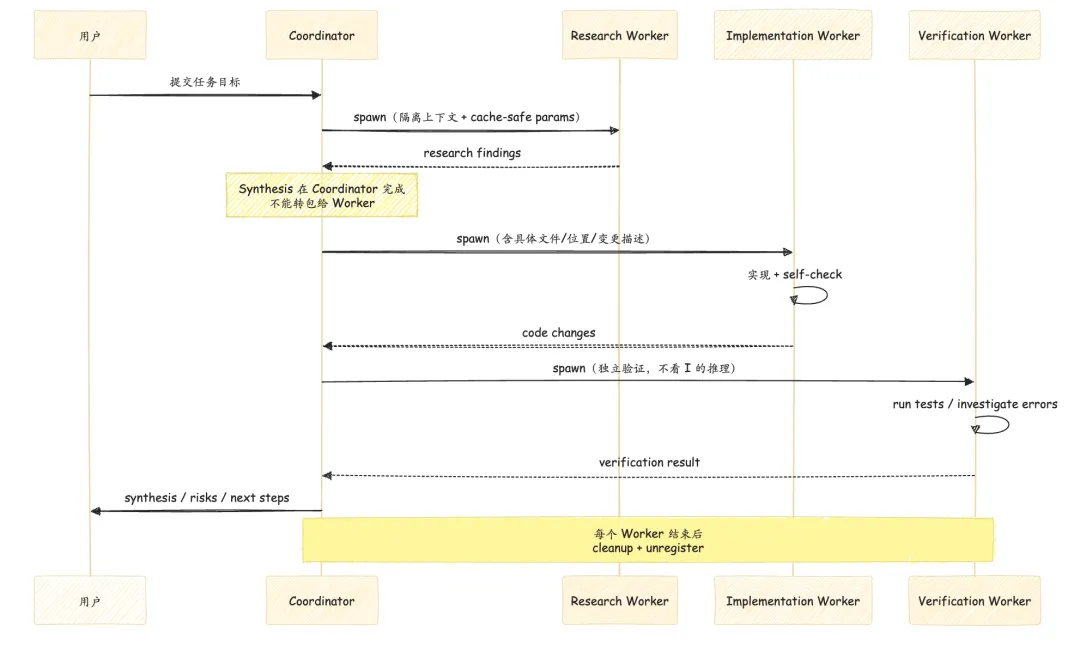
Coordinator-Worker 分工模式的核心逻辑在 src/coordinator/coordinatorMode.ts:
-
• Coordinator 负责 Research → Synthesis → Implementation dispatch → Verification -
• Synthesis(综合理解)不能外包给 worker:coordinator 必须读懂 research worker 的报告,然后写出包含”具体文件、具体位置、具体变更”的 implementation prompt,而不是”根据前面的结论继续” -
• Verification worker 和 Implementation worker 必须角色分离,不能让实现者自证
子 Agent 生命周期由 hooksConfigManager 暴露两个节点:SubagentStart(启动时,含 agent_id 和 agent_type)和 SubagentStop(结束前,含 agent_transcript_path,允许 exit code 2 把 stderr 反馈给子 agent 继续运行)。
关键设计模式提炼
从 51 万行源码里,可以提炼出以下几个可直接复用的工程模式:
模式一:侧查询 Critic 模式
对高风险操作,不用规则白名单,而是把操作描述发给一个独立的轻量模型做二次判断。成本极低(一次 Haiku/Sonnet 调用),但把”静态规则无法覆盖的语义判断”变得可行。
# 伪代码:Critic 模式async def can_execute_bash(command: str, context: str) -> bool: critic_prompt = f"Is this bash command safe to execute?\nCommand: {command}\nContext: {context}\nRespond with only: safe / unsafe / needs_review" result = await quick_model_call(critic_prompt, model="claude-haiku") return result == "safe"模式二:工作内存分层
把上下文来源分成三类,分别治理:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
模式三:错误分层恢复,不用统一重试
错误类型 → 恢复策略prompt_too_long → ① collapse drain → ② reactive compact → ③ 截断历史max_output_tokens → ① 提升 cap 上限 → ② 注入续写指令(不道歉,直接续)工具执行失败 → synthetic tool_result(补齐因果链)用户中断 → 消费剩余 streaming results → 生成 synthetic abort result连续失败 → circuit breaker,不再自动重试模式四:可观测的 Agent 行为
Claude Code 埋了两个非传统 telemetry 指标:
-
• 咒骂频率(frustration metric):用户在终端里骂人的次数,作为 UX 质量的领先指标 -
• “continue” 输入计数:用户手动输入”continue”的次数,代理停滞的代理指标
这两个指标捕捉到了标准 error rate、latency 覆盖不到的失败模式。
总结:Harness Engineering 的本质
泄露发生后,有人在 6 小时内用 Python 复刻了核心架构,仓库拿到了 10 万 star。
但一周后,没有人能直接用那个复刻版代替 Claude Code。
原因不是复刻者水平不行,而是这套 Harness 里有大量针对真实工程场景的微调参数:
-
• AUTOCOMPACT_BUFFER_TOKENS = 13000——这个数字是从多少次 OOM 里调出来的? -
• MAX_CONSECUTIVE_AUTOCOMPACT_FAILURES = 3——三次这个阈值,是基于多少 session 的 API 成本数据? -
• per-skill token cap、session memory 12000 tokens 上限——每个数字背后都是一次真实的失控案例
架构可以复制,调参需要时间和教训。
对大多数团队来说,从 Claude Code 泄露源码里真正能带走的,是这几条工程判断:
-
1. Query Loop 是 Agent 的心跳,不是 wrapper:维护跨轮状态,才能处理长任务 -
2. Prompt 是控制面,不是人设:分层、有优先级、连接 memory 和 runtime -
3. 上下文是工作内存,不是垃圾桶:分层治理,compact 目标是重建工作语义 -
4. 工具是受管执行接口:权限先于能力,高风险工具单独对待 -
5. 错误是主路径:设计恢复策略,分层不重锤,加熔断防死循环 -
6. 验证必须独立:不能让实现者自证,verification 是单独的 Agent 角色
Claude Code 值得研究的,不是它用了多强的模型,而是它用了多扎实的工程。
💡 延伸思考
-
1. 你现在的 AI Agent 出现 prompt too long时怎么处理?是直接截断历史还是有分层恢复策略?如果你上线了 compact 机制,compact 之后有没有重新注入 plan / tools / memory 等工作语义? -
2. 权限系统里的 ask状态——”系统不应该替用户决定”——在你的场景里,哪些操作应该触发这个路径?你现在是用静态规则白名单处理的,还是有 critic 模式?
觉得有收获?请 点赞、转发、 和 关注 ,让更多工程师看到这篇文章~