 夜雨聆风
夜雨聆风





Claude Code 源码解析(二):对话循环——Agent 的心脏如何跳动
AI应用实录 · Claude Code 源码拆解 · 第二章
一个被打破的假设
传统的程序调用模型是确定性的:函数接收输入,执行计算,返回输出,然后终止。调用者知道函数什么时候结束,也知道它只会返回一次。
LLM Agent 打破了这个假设。
当用户向 Claude Code 发出一条指令,没有人知道它需要几轮 API 调用、几次工具执行、多少次中间决策才能完成任务。更关键的是,用户需要实时看到每一步的进展——文字在流出,工具在执行,文件在变更。整个过程是持续的、有中间状态的、随时可被打断的。
面对这种需求,传统函数调用模型完全无能为力。Claude Code 的解答是一个异步生成器驱动的无限循环。
这个架构选择不是偶然的,也不只是技术偏好。它是对 Agent 运行时特征的精确回应——理解了这个选择,就理解了 Claude Code 最核心的设计哲学。
为什么是 AsyncGenerator
面对”流式输出 + 可中断 + 状态持续”这三个需求,工程师通常会考察以下方案:
回调函数:事件总线或观察者模式,为每种事件类型注册独立的处理函数。问题是代码会散落在各处,随着事件类型增多形成”回调地狱”,更无法在事件之间维护关联的状态。
Promise 链:Promise 本质上是”一次性”的——它只能 resolve 一次,无法表达持续的事件流。强行用 Promise 实现流式输出,通常会退化为回调或事件监听器。
EventEmitter:接近需求,但引入了两个隐患:事件名是字符串,类型系统无法检查;监听器未被移除时会造成内存泄漏——在 Agent 这种复杂、长生命周期的场景里,这些隐患足以导致生产事故。
AsyncGenerator(async function*):JavaScript 原生支持,零额外依赖。yield 表达”产出一个中间值并等待”,for await...of 表达”持续消费直到结束”,.return() 表达”从外部取消”。这三个能力完整覆盖了 Agent 对话循环的全部需求。
这不是”都能用,AsyncGenerator 稍微更好”的选择——这是”其他方案都有硬性短板,AsyncGenerator 是刚刚好的答案”的选择。

▲ AsyncGenerator 三层设计优势
函数签名里的三层设计决策
Claude Code 对话主循环的类型签名,值得逐字解读:
TYPESCRIPT
async function* query( params: QueryParams ):AsyncGenerator<StreamEvent | RequestStartEvent| Message | TombstoneMessage| ToolUseSummaryMessage, Terminal >
Yield 类型:五种事件的联合体
生成器向外产出五种事件类型:
•RequestStartEvent:每次 API 请求发起前的通知,UI 据此显示”正在思考”
•StreamEvent:来自 API 的原始流式 token,透传给 UI 实时渲染
•Message:结构化的消息对象(用户消息、助手消息、系统通知等)
•TombstoneMessage:标记某条消息需要被 UI 撤销——发生在模型降级时
•ToolUseSummaryMessage:工具调用批次完成后的摘要,用于折叠展示
用联合类型而非多个独立通道的原因:时序一致性。UI 看到的事件顺序必须与实际发生顺序完全一致。如果通过不同通道传递不同类型的事件,就无法保证这一点。
Return 类型:Terminal
生成器最终返回一个终止原因对象,而非 void。这启用了”yield 过程、return 结论”的编程模式——消费者在 for await...of 循环结束后,可以立即拿到对话的终止原因,无需额外的状态变量。
参数设计:结构化对象而非散列参数
所有入参封装在一个 QueryParams 对象中。这不只是代码风格问题——它允许参数按需提供,使得测试时注入最小化的参数集成为可能,也使得未来增加新参数时不破坏调用方。
五种事件的含义
对话循环产出的五种事件,构成了 Agent 对外通信的完整语言:
|
|
|
|
|---|---|---|
RequestStartEvent |
|
|
StreamEvent |
|
|
Message |
|
|
TombstoneMessage |
|
|
ToolUseSummaryMessage |
|
|
TombstoneMessage 的存在揭示了一个工程现实:当主模型过载触发降级时,已产出的流式内容(包含该模型专属的 thinking 签名块)必须被撤销,切换到备用模型重新生成。如果没有这种”撤销消息”的机制,UI 会显示来自不同模型的混合输出——这是 Claude Code 在容错设计上的精细之处。
对话循环内部是一个 while (true) 无限循环。每次迭代代表一次完整的”API 调用 + 工具执行”回合(Turn)。Turn 的生命周期分为五个阶段:
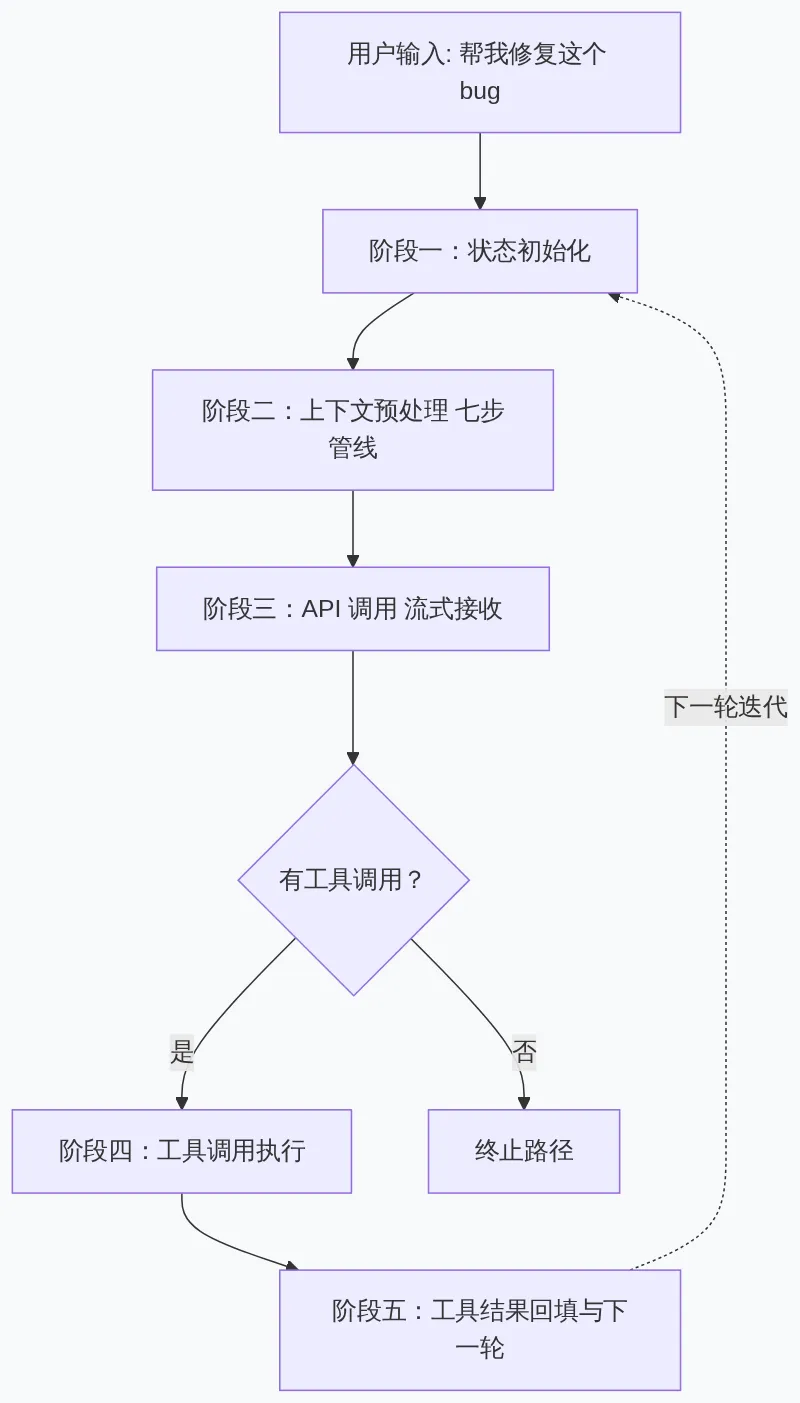
▲ Turn 完整生命周期
阶段一:状态初始化 阶段二:上下文预处理(七步管线) 阶段三:API 调用(流式接收) 阶段四:工具执行(按需) 阶段五:结果回填 → 下一轮 ↑________________________|
阶段一:状态初始化
每次迭代的开始,函数从状态对象中一次性解构出当前迭代所需的全部字段,并在结束时构造一个全新的状态对象写回。
这是一个微妙但重要的约定:状态在”读入”和”写出”之间有明确的分界线。 迭代过程中不存在”部分更新”——只有”读取旧状态”和”写入新状态”两个时刻。这消除了并发修改导致的不一致问题,也使得每次迭代的输入状态是确定性快照。
阶段二:七步预处理管线
在发起 API 调用之前,循环执行七步预处理。这七步构成了 Claude Code 上下文管理的核心:
① 工具结果预算:工具执行的返回值可能极大(如读取一个巨型日志文件)。这一步对超限的工具结果进行截断或持久化到磁盘,确保消息总量不超过上下文窗口。类比计算机的虚拟内存机制——当物理内存(上下文窗口)放不下,把部分数据”换出”到磁盘,保留摘要引用。
② Snip 压缩:对历史消息中过长的内容进行直接截断。这是最轻量但也最”粗暴”的压缩方式——信息会损失,但速度快、无需 API 调用。通常用于处理已被工具结果预算截断后仍然过长的历史记录。
③ Microcompact:利用 API 的缓存编辑能力,在不破坏整体 Prompt Cache 的前提下删除特定历史工具调用的详细结果。Microcompact 的关键约束是”缓存友好”——它尽量复用 API 侧已缓存的 token,避免因压缩操作导致缓存全面失效、反而增加成本。
④ Context Collapse(上下文折叠):将连续的工具调用结果折叠为紧凑的摘要视图。本质上是一种”读时投影”——折叠视图在每次发送前实时计算,原始消息仍然保存在完整历史中。这意味着折叠是无损的:需要精确历史时可以还原,发送给 API 时用压缩版本。
⑤ 系统提示组装:将基础系统提示与动态上下文(当前工作目录、用户配置、活跃的 CLAUDE.md 内容等)合并为完整的系统提示。这一步的设计直接影响缓存命中率——如果组装顺序不稳定,每次生成的 Prompt 字节内容不同,API 侧缓存将失效。 Claude Code 对系统提示的组装顺序有严格约束,根本原因在此。
⑥ Autocompact(自动全量压缩):当上下文超过阈值时,调用 LLM 生成对话历史的摘要,用摘要替换原始历史消息。这是四种压缩手段中最”重”的一个,也是最后的防线——前五步都是在不调用额外 API 的情况下减少 token,Autocompact 是真正意义上的”语义压缩”。
⑦ Token 阻断检查:如果 token 数超过硬性限制,直接返回错误,不发起 API 调用。这是快速失败机制——与其发送一个注定被 API 以 400 错误拒绝的请求,不如在本地就阻止它,给用户明确的错误提示。
七步管线遵循一个核心原则:从轻量到重量排列,每一步都优先使用最小代价的方案。 这不只是性能考量——每一步压缩都意味着一定程度的信息损失,应当尽量推迟最”激进”的手段的使用。
阈值计算也有一处精心设计:
TYPESCRIPT
export function getEffectiveContextWindowSize(model: string): number {const reservedTokensForSummary =Math.min(getMaxOutputTokensForModel(model), 20_000) // 基于 p99.99 数据(17,387 tokens)let contextWindow = getContextWindowForModel(model, getSdkBetas())const override = process.env.CLAUDE_CODE_AUTO_COMPACT_WINDOWif (override) contextWindow = Math.min(contextWindow, parseInt(override))return contextWindow - reservedTokensForSummary}
20_000 这个常数不是拍脑袋决定的——它来自生产环境的 p99.99 监控数据,即实际摘要生成消耗的 token 上限。这种”用数据锚定常量”的做法是大型系统工程的典型实践。
阶段三:API 调用(流式接收)
预处理完成后,循环向 API 发起流式请求,传入系统提示、消息历史和工具定义,然后用 for await...of 逐个处理流式事件:
–文本 token:立即 yield 给上层 UI,实现”字出现即显示”
–工具调用块:收集起来,待响应流完成后执行(或在启用流式工具执行时立即开始)
–模型降级信号:生成 TombstoneMessage,清空已收集的消息,切换到备用模型重试
这一阶段还处理一个边界情况:模型可能在同一个响应中同时输出文本和工具调用。例如”我需要查看你的配置文件”(文本)+ FileRead(path='package.json')(工具调用)。循环需要同时处理这两部分——既 yield 文本事件让 UI 渲染,又收集工具调用块为后续执行做准备。
阶段四:工具执行
当响应流结束后,循环检查是否有待执行的工具调用。如果有,进入工具执行阶段。
工具执行本身也是一个异步生成器——每执行完一个工具,立即 yield 结果消息。这个设计体现了重要的工程原则:“结果收集”和”结果传递”是解耦的同一操作。 工具结果既被收集到数组中(用于下一轮 API 调用),也被 yield 给 UI(用于实时展示),两件事通过同一个 yield 同时完成。
工具执行的并发策略将在第三章详细分析,这里只需要理解:并发安全的工具(如文件读取)可以并行执行,非并发安全的工具(如 Bash 命令)必须串行。
阶段五:结果回填与下一轮
工具执行完成后,循环执行附件注入,然后将完整的消息历史(原始消息 + 助手消息 + 工具结果)打包为新的状态对象,通过 continue 回到 while (true) 的顶部。
附件注入是一个容易被忽视的关键步骤。 假设在工具执行期间,用户修改了 CLAUDE.md 文件——如果不在这一步注入变更通知,下一轮 API 调用中模型将基于过时的配置做出决策。附件注入保证了每一轮循环开始时,模型拥有最新的环境状态。
对话循环不会永远运转。终止发生在以下十种情况:
|
|
|
|
|---|---|---|
completed |
|
|
aborted_streaming |
|
|
aborted_tools |
|
|
max_turns |
|
|
blocking_limit |
|
|
prompt_too_long |
|
|
model_error |
|
|
stop_hook_prevented |
|
|
hook_stopped |
|
|
image_error |
|
|
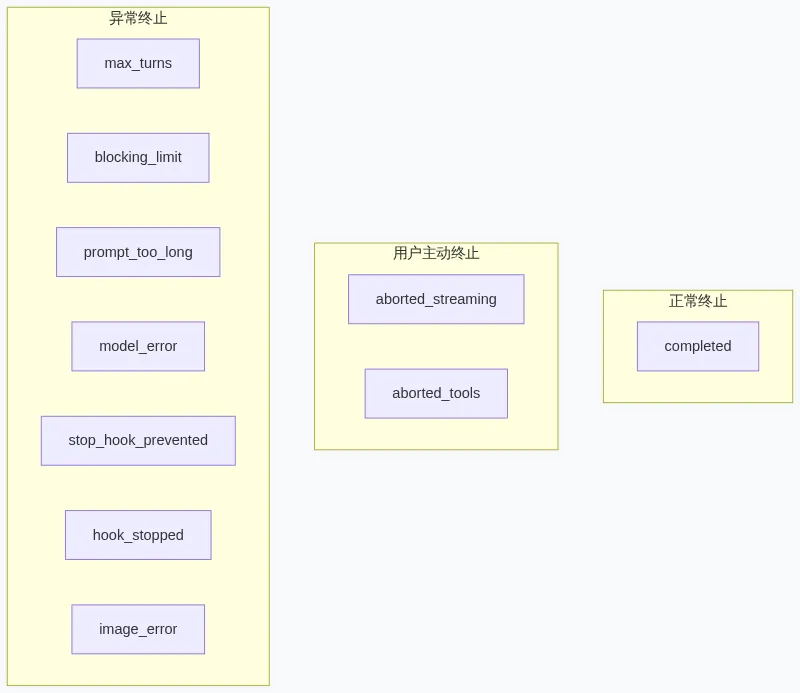
▲ 十种终止原因分类
十种终止原因的精细划分不是过度设计。在调试 Agent 行为时,准确的终止原因是定位问题的第一线索。 如果所有错误都返回一个笼统的”error”,开发者将无从判断是 API 超时、上下文溢出还是用户中断导致了问题——而这三种情况的处理方式完全不同。细粒度的终止类型是可观测性(Observability)的基础。
并非所有异常都直接终止——对话循环定义了七条 Continue 路径,在特定条件下恢复循环而非中止:
next_turn(正常继续):工具执行完成后的标准路径。消息列表扩展,turn 计数递增,进入下一轮。这是最常见的路径。
max_output_tokens_escalate(输出截断 → 先提升限制):模型输出被截断时(stop_reason === 'max_output_tokens'),首先尝试提升输出 token 上限(从默认的 8K 升级到 64K),以同一组输入重新发起请求。这比”从中断处继续”更优雅——给模型更大的输出空间,让它一次性完成,避免语义断裂。
max_output_tokens_recovery(输出截断 → 注入恢复消息):提升限制后仍然截断,或无法提升时,注入恢复消息让模型从中断处继续:
Output token limit hit. Resume directly — no apology, no recap. Pick up mid-thought if that is where the cut happened.
最多重试 3 次。第 3 次截断后放弃并 surface 错误。
reactive_compact_retry(响应式压缩恢复):上下文过长,预处理管线未能将其压缩到限制以内,触发一次紧急的响应式全量压缩,然后重试。这是压缩管线的”紧急刹车”。
collapse_drain_retry(折叠溢出恢复):上下文折叠后仍然溢出的恢复路径,优先于响应式压缩执行,因为折叠保留更细粒度的上下文(丢失信息更少)。两条路径的优先级排序体现了”最小信息损失”原则。
stop_hook_blocking(Stop hook 错误反馈):Stop hook 脚本返回阻塞错误时,将错误信息注入消息列表,让模型有机会调整策略后继续。这展示了 Agent 系统设计的一个关键理念:错误不一定是终止条件,也可以是反馈信号。 模型收到 hook 的错误后,可能会调整操作路径并找到合法方案。
token_budget_continuation(Token 预算提醒):Token 预算接近耗尽时,注入提醒消息告知模型注意剩余预算,而非直接截断。类比手机流量套餐的余量预警——提醒而非立即断网。
七条 Continue 路径共享一个设计约定:每次 continue 都构造全新的状态对象,并通过 transition 字段记录本次 continue 的原因。 这使得后续迭代可以识别”我是怎么来到这里的”,从而避免走入相同的恢复路径形成循环。
QueryDeps:四个测试关键点
对话主循环的依赖注入设计,是 Claude Code 工程质量的缩影:
TYPESCRIPT
export type QueryDeps = { callModel: typeof queryModelWithStreaming // LLM API 调用microcompact: typeof microcompactMessages // 轻量压缩autocompact: typeof autoCompactIfNeeded // 自动压缩uuid: () => string // ID 生成}
这四个依赖不是随机选取的——它们恰好是对话循环中所有”与外部世界交互”的边界点。将它们抽象为接口后,循环内部变成了纯逻辑:给定相同的输入状态和依赖实现,行为完全可预测。
生产环境使用真实的依赖实现;测试环境传入自定义的 stub。
代码注释里有一段坦诚的说明——在 6-8 个测试文件中反复用 spyOn 做 mock 之后,开发者决定将常用依赖抽取为可注入参数,一举消除了所有测试文件中的重复样板代码。
好的工程设计往往来自对重复痛苦的系统性消除。
不可变状态 × 函数式闭包
对话循环采用 async function* 而非 class,这个选择同样有深层考量:
状态隔离:每次调用对话函数都创建全新的闭包,所有可变状态都是函数局部变量。不存在跨调用的状态泄漏风险。对比 class 方案:多个并发对话可能意外共享实例属性,在多用户场景下造成状态污染。
背压语义:yield 暂停执行直到消费者请求下一个值。消费者处理速度跟不上时,生成器自动等待,不会堆积内存。这对处理 npm install 这类产生大量输出的工具至关重要。
确定性取消:调用 .return() 触发生成器的 finally 块,清理逻辑是确定性的。结合资源管理声明,Ctrl+C 不只能停止对话循环,还能保证所有正在执行的工具被正确取消。
对话循环的完整状态机,可以用以下结构表达:
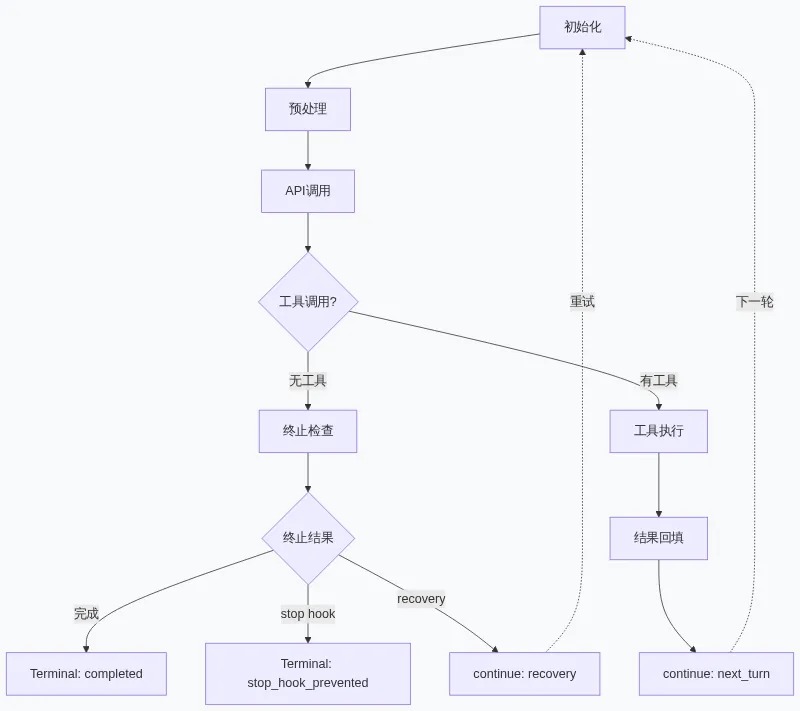
▲ 状态转换决策逻辑
State(当前迭代状态) ↓ 预处理 ↓ API 调用 ↓ 工具执行 ↓ [Terminal] ← 十种终止路径中的任意一种 或 [Continue] → 新 State(七条 Continue 路径之一) 包含:transition 字段(记录本次 continue 的原因)
State 类型的定义:
TYPESCRIPT
type State = { messages: Message[] // 完整消息历史toolUseContext: ToolUseContext // 工具执行上下文autoCompactTracking: AutoCompactTrackingState | undefinedmaxOutputTokensRecoveryCount: number // 截断恢复计数(上限 3)hasAttemptedReactiveCompact: boolean // 是否已尝试响应式压缩turnCount: number // 当前 turn 计数transition: Continue | undefined // 上一次 continue 的原因pendingToolUseSummary: Promise<...> // 异步摘要生成stopHookActive: boolean | undefined}
transition 字段的存在是状态机设计的精华。它将”上一次如何来到这里”编码进了状态,使得循环在每次迭代时都能做出上下文感知的决策——例如,当 transition.reason === 'max_output_tokens_recovery' 时,循环知道自己正在恢复一次截断,不应该再次走 escalate 路径。
这是在可变循环中应用函数式设计理念的典型案例:状态携带历史,转换是纯函数,副作用通过 yield 显式暴露。
AsyncGenerator 是 Agent 循环的最佳载体:yield 提供流式输出,yield* 提供子生成器委托,.return() 提供确定性取消。这三个能力完整覆盖了 Agent 对话循环的全部需求。选择 AsyncGenerator 不是”也可以用其他方案”的折中,而是”其他方案都有明确短板”的最优选择。
预处理管线是上下文管理的骨架:七步管线从轻量到重量排列,确保 Agent 在无限对话中始终保持在 token 预算内。关键原则:信息损失应当延迟到最后,最重的手段(Autocompact)最后触发。
状态不可变,转换可追踪:每次 continue 都构造新的 State,transition 字段记录每一次跳转的原因。这是函数式设计在命令式循环中的优雅折中——可追踪性不需要以可变性为代价。
终止原因是可观测性的基础:十种精细的终止原因不是过度设计,而是生产环境可调试性的前提。错误的终止处理比错误的正常流程更危险,因为它可能导致资源泄漏或状态不一致。
依赖注入是测试可维护性的保证:QueryDeps 的四个字段覆盖了循环的全部外部交互边界,使得状态转换逻辑可以在不访问真实 API 的情况下得到完整验证。
第三章将深入工具系统——对话循环的”执行层”。如果说对话循环是 Agent 的心脏,工具系统就是它的四肢。理解了工具系统如何管理并发、如何做权限判断、如何处理流式执行,才能完整理解 Claude Code 从”能说话”到”能做事”的全部工程细节。
AI应用实录|用大白话拆解 AI 应用,让普通人也能上手。