 夜雨聆风
夜雨聆风





大模型Agent并行化让AI助手真正快起来的秘诀
尴尬的是,这三分钟里,它可能只是在sequential(顺序)地做事情:先搜索,再总结,再搜索,再总结。
但如果我告诉你,这些步骤其实可以同时发生呢?
这就是今天要聊的主题——大模型Agent并行化。不是什么玄学,就是让AI真正快起来的干活。

AI助手”思考中…”时的等待场景
01
为什么你的AI助手总是那么慢
说个真实的场景。
上个月我让一个AI研究助手帮我分析某个技术主题。它的操作流程是这样的:
第一步,搜索来源A,等它搜完;
第二步,总结来源A,等它总结完;
第三步,搜索来源B,等它搜完;
第四步,总结来源B,等它总结完;
第五步,合成最终答案。
你猜猜用了多久?
⏱️ 四分半
我中途去倒了杯水,回来还没完事。
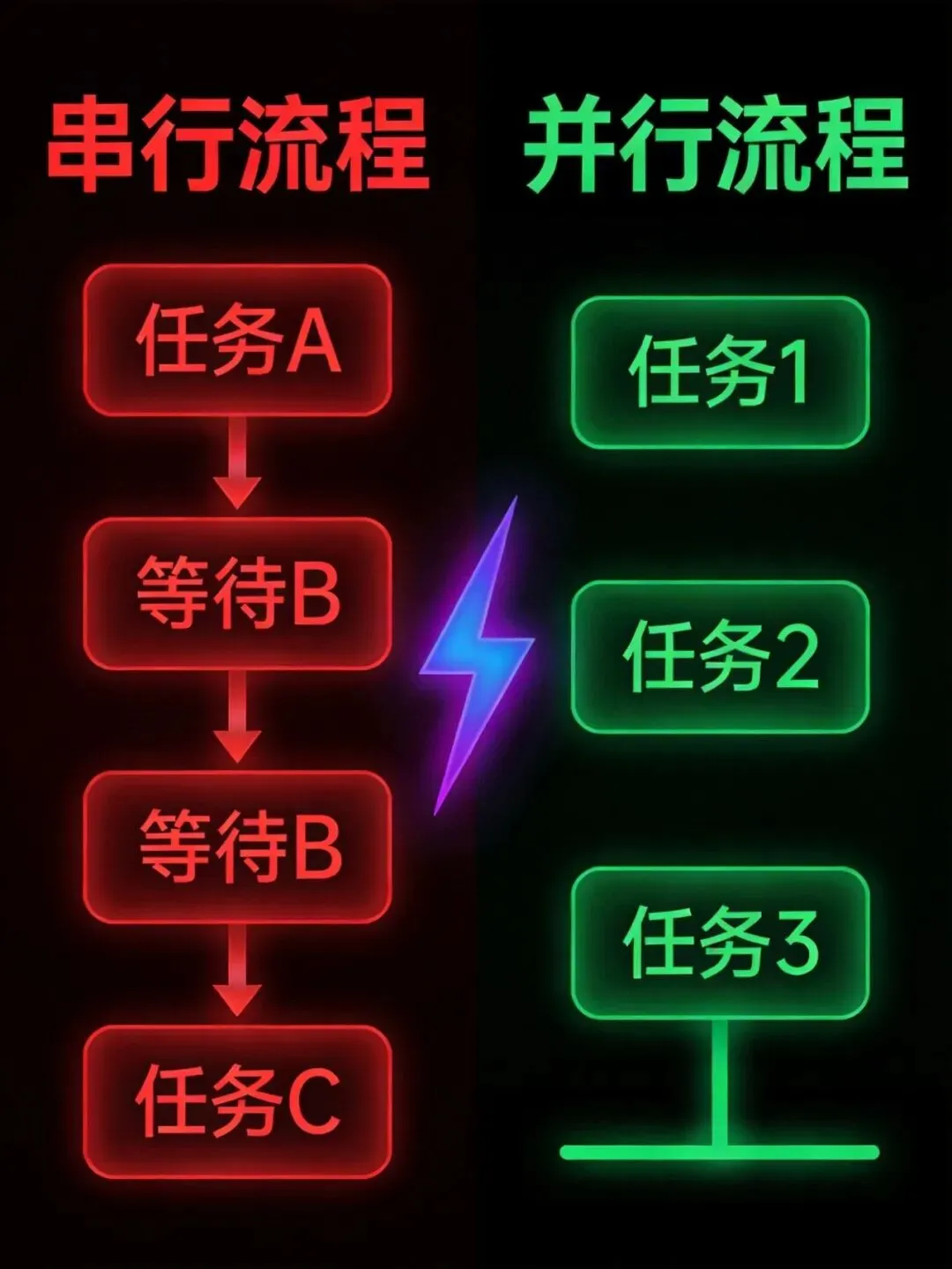
但如果用并行化的思路重写这个流程——
同时搜索来源A和来源B,两个搜索完成后再同时总结A和总结B,最后一步合成答案。
🚀 四分半变成一分半
这不是偷工减料,是真真切切的效率提升。
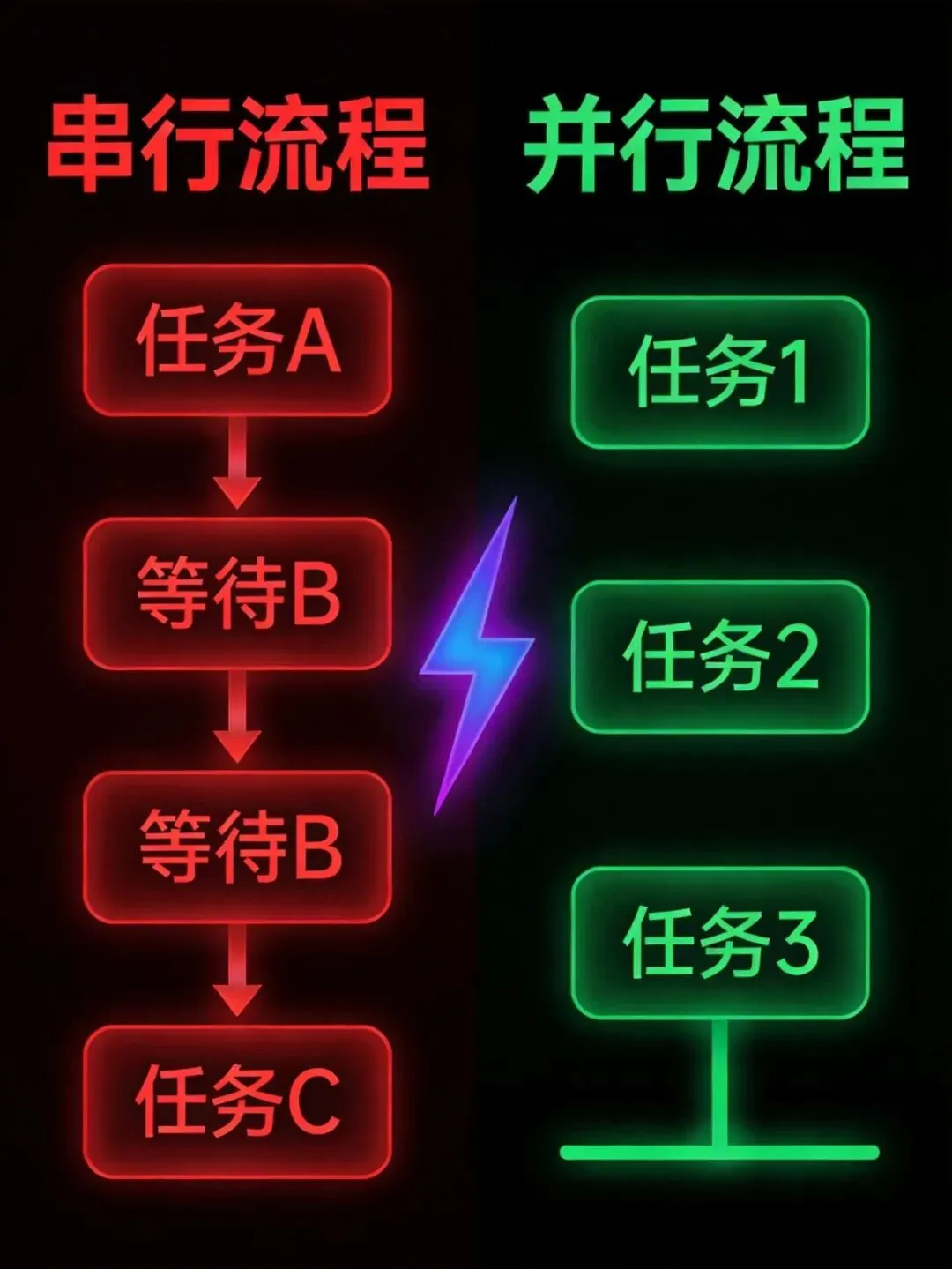
串行 vs 并行:效率对比一目了然
02
并行化是什么
用一句话解释:并行化就是让多个任务同时执行,而不是一个等一个。
在AI Agent的语境下,这包括:
-
多个LLM调用同时进行
-
多个工具调用并行触发 -
多个子Agent协同工作
你以前可能见过这种场景——AI在调用一个API,等返回,然后再调下一个,再等。这种串行模式在处理独立任务时简直是对时间的犯罪。
并行化核心:多个任务同时执行
💡 关键洞察:并行化的核心思想是识别工作流中不依赖其他部分输出的环节,将它们并行执行。这在处理具有延迟的外部服务时尤其有效——你可以同时发出多个请求,而不是老老实实排队。
03
什么场景必须用并行化收集
这是最经典的使用场景。
一个完整的公司调研,传统的做法是:
1. 搜索新闻文章(等)
2. 获取股票数据(等)
3. 监控社交媒体(等)
4. 查询公司数据库(等)
每个任务之间没有依赖关系,但你却让它们排着队一个个来。
用并行化重构后,四个任务同时触发,最后汇总结果。
这就是为什么有些AI研究工具能在几十秒内给你一份完整的行业分析报告——人家不是比你聪明,是比你快。
多来源信息并行收集
场景二:多维度数据处理
客户反馈分析,听起来是个简单任务对吧?
但如果你要做:
-
🔹 情感分析(用户是褒是贬) -
🔹 关键词提取(用户在聊什么) -
🔹 反馈分类(功能/服务/价格) -
🔹 紧急问题识别(哪些需要立即处理)
这四个任务完全独立,完全可以并行。
⏱️ 串行 20秒 → 🚀 并行 5秒
多维度数据并行处理
场景三:多API调用
旅行规划Agent。
用户说:”帮我规划一个东京七日游。”
它需要:
-
✈️ 查询航班价格 -
🏨 查询酒店可用性 -
🎯 查询当地活动 -
🍜 查询餐厅推荐
每个API响应时间2-3秒。
串行执行:8-12秒 → 并行执行:2-3秒
用户体验差距有多大?你自己品。

旅行规划:航班、酒店、活动、餐厅并行查询
场景四:内容生成的多组件
营销邮件创建,听起来是一件事,实际上是多个独立任务:
-
📝 生成邮件主题 -
📄 起草正文内容 -
🖼️ 查找相关图片 -
🎯 创建行动号召按钮文本
这四个任务完全可以并行,最后组装成完整邮件。
场景五:并发验证
用户注册时的多维度验证:
-
📧 邮箱格式校验 -
📱 手机号码校验 -
📍 地址信息数据库匹配 -
⚠️ 不当内容检测
四个检查同时跑,用户体验就是”秒过”。
04
怎么实现并行化
说到实现了。这个部分有点硬,但看懂了你就是半个专家。现方式
在LangChain的世界里,并行执行靠LangChain表达式语言(LCEL)实现。
核心方法很简单——把多个可运行组件放在字典或列表结构里。LCEL运行时碰到这种结构,会自动并发执行里面的任务。
# 伪代码示例chain = {"source_a": search_tool | summarize,"source_b": search_tool | summarize,"source_c": search_tool | summarize, }| synthesize
三个source的搜索和总结同时跑,最后才到synthesize合并。
这就是LangChain的魔法——声明式地定义并行,运行时自动调度。

LangChain LCEL 并行任务语法
LangGraph的实现方式
LangGraph通过图结构来实现并行。
它的思路是:定义多个节点,每个节点从单一状态转换执行。当多个节点都满足执行条件时,它们可以并行运行。
简单说就是:你在图里画好节点关系,LangGraph帮你算好哪些可以同时跑。
LangGraph 图结构并行执行
05
并行化的坑,你得知道
讲了这么多好处,也得说说问题。
⚠️ 坑一:任务并非总是独立的
并行化只适用于真正独立的任务。如果任务B依赖任务A的输出,那不好意思,B必须等A跑完。强行并行会导致数据错误或者逻辑混乱。写之前先问自己:这两个任务有没有依赖关系?
⚠️ 坑二:资源消耗是真实的
并行跑4个任务,理论上是快了,但也意味着你同时占用了4倍的计算资源。在生产环境里,这可能意味着更高的成本和更大的系统压力。不是所有场景都适合疯狂并行,要根据实际负载来决策。
⚠️ 坑三:错误处理变复杂了
串行任务,一个错了就停。并行任务,一个错了,另外几个可能还在跑。你的错误处理逻辑得设计得更健壮——谁先错、错几个要停、结果怎么回滚,这些都得想清楚。
⚠️ 坑四:结果顺序不确定
并行执行的任务,完成顺序是不确定的。你需要考虑:结果组装时怎么办?有些任务快有些任务慢,最终输出怎么保证一致性?通常的解法是:给每个任务分配ID,最后按ID组装结果,而不是按完成顺序。
06
什么情况下不该用并行化
说了这么多,你应该已经理解了——并行化是工具,不是银弹。
不该用并行化的场景:
❌ 任务之间有强依赖。后一个任务必须等前一个结果?乖乖串行。
❌ 任务太简单。开个并行调度的开销可能比任务本身还贵,得不偿失。
❌ 资源严重受限。内存不够、并发数有上限,这种时候强行并行反而拖慢整体。
❌ 需要强一致性。某些场景下必须保证执行顺序,那就老老实实串行。
07
怎么判断该不该用并行化
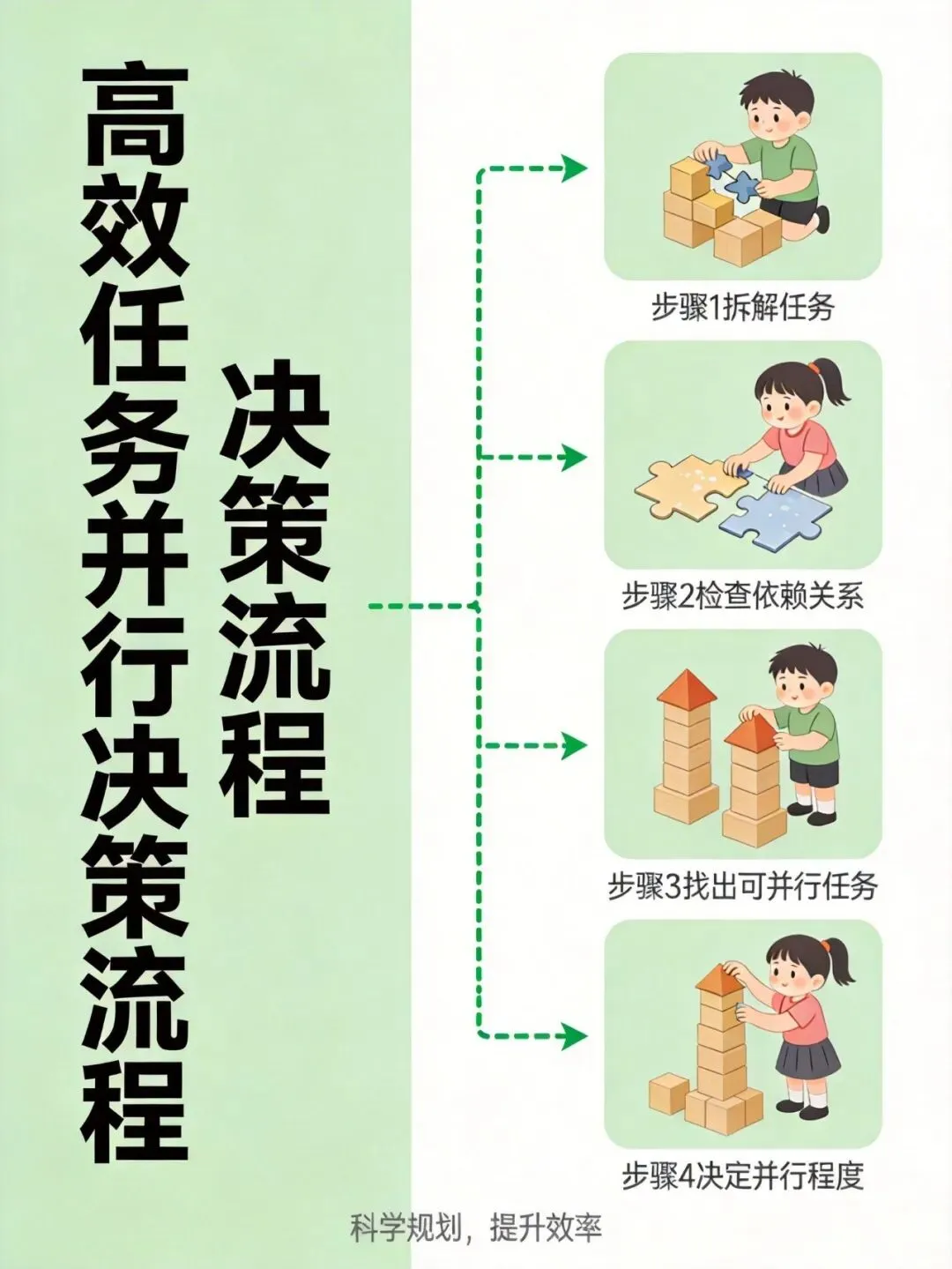
给你一个简单的判断流程:
1 拆解 — 拆解你的AI工作流,把每个步骤单独列出来。
2 检查 — 对每个步骤问——”这个任务的输入,是不是依赖其他步骤的输出?”
3 找出 — 如果答案是”不依赖”,恭喜,这个任务可以被并行化。
4 决定 — 根据实际资源情况和响应时间要求,决定并行程度。
就这么简单 ✨
08
写在最后
并行化不是什么新技术,但在大模型Agent时代变得格外重要。
因为LLM的推理本身就慢(几秒到几十秒不等),如果你还让它串行做事情,那用户体验就是灾难。
把并行化用起来,你会发现AI助手从”慢吞吞的老大爷”变成”雷厉风行的执行力”。
关键是记住一个原则:让所有独立的任务同时跑起来,只在必须串行的地方串行。
这就是效率的本质。
如果觉得有帮助,随手点个赞