当前时间: 2026-04-12 20:58:55
更新时间: 2026-04-12
分类:软件教程
评论(0)
9830条记忆之后,我把AI助手系统重建了
从1月份开始折腾 openclaw 开始,我搭建了一套记忆+进化+做梦的完整系统,这套重建后的系统已经开源了。
https://github.com/Elo-Mario/openclaw-memory-system
如果你只想直接看方案,这套东西解决了什么问题,以及怎么开始用,可以直接去看开源地址。如果你更关心我是怎么一步步走到这里的,这篇文章就是那份完整的踩坑记录。
这是我花了三个月,从4年的Obsidian日记里提取了9830条记忆,喂进了 openclaw 的记忆系统。
不光是一开始的架构问题,是那段时间我才真正搞明白:记忆系统最大的问题,不是内容够不够,而是整理、读取,和后续的管理。
我在一月份刷X的时候就看到了Openclaw(当时还叫Moltbot)的宣传,当时它吹捧的:有长期记忆,能慢慢了解用户,还能持续做任务,像极了真正的 AI 牛马。
让每个人都能有自己专属的AI助理,有自己的 Javes —— 这个点就已经足够吸引人了。
大家真正缺的,从来不是一个更会说话的模型,缺的是一个能记住你、接住你判断方式、延续上次任务思路的系统。
我对这件事比一般人更敏感一点。在这之前,我已经有几年 Obsidian 积累:日记、项目、想法、长期变化的观察,其实一直都在(感谢过去几年折腾Obsidian的习惯,虽然不成功,但好歹踩坑不少)。问题不是”没有内容给 AI”,恰恰相反——我手里有一大堆能体现我性格、习惯、判断方式的东西,而是这些东西始终没有被真正用起来。
所以开始接触Openclaw的时候,期待值其实很明确:不是想让它回答更像人,是想看它能不能慢慢变成一个”越来越懂我”的系统,能帮我做一些工作上的事,让我能更好地“摸鱼”。
与Claude code相比,openclaw有着更多的定义文件:有 SOUL.md,可以定义 AI 的人格和语气;有 USER.md,可以定义你的画像、偏好、协作方式。通过这些文件去定义人格、语气、合作方式。
某种意义上,这已经是在试图解决”让 AI 更懂你”这件事了(现在的ChatGPT之类也有类似的设置)。但它有一个很大的问题:这套配置依赖于文件,只要不更新,就是写死的。
它能让系统更像你,但还不足以让系统真正长期理解你。
openclaw 需要你不断和AI对话,去提醒、纠正AI的信息,然后AI提取有用的内容,重新整合自己的记忆,动态更新AI的记忆,从而达到“越来越懂你”的程度——这就是所谓“养龙虾”说法的来源。
刚好我在 Obsidian 里有4年的日记积累,把这些都转移到openclaw里面去,是不是就省去了“养龙虾”的过程?
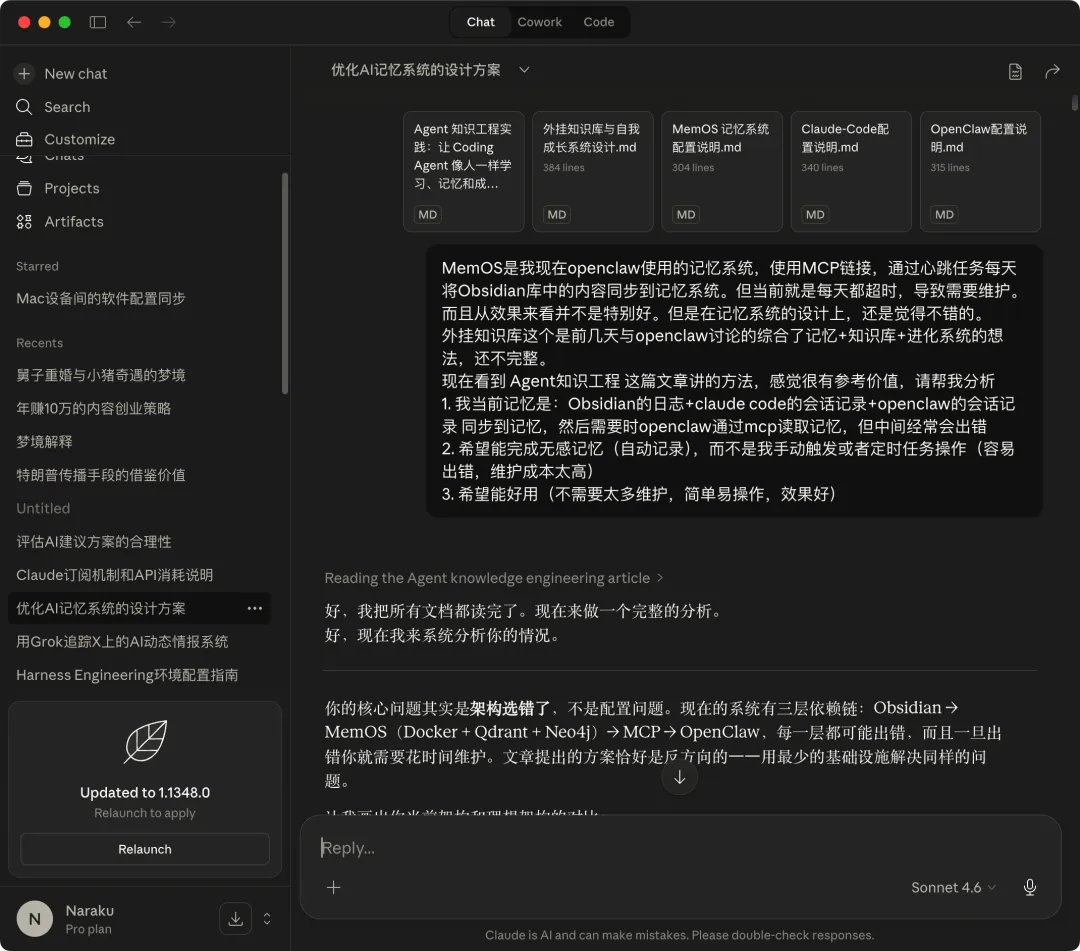
当时openclaw还很简陋,于是我开始把Obsidian日记喂进了MemOS系统里。
——因为 MemOS 看起来正好能补上我最在意的那块:不只是提取关键词,而是提取性格、行为、习惯、思考方式、做事偏好,再接到 OpenClaw 上,让它不只是”知道我是谁”,而是能在后续任务里真正利用这种理解。
从本地1200+日记里提取性格、行为这些信息,最后的数据是到了 9830 条。如果这样都还不够好,那问题不是数据太少,可能是AI模型的问题了(反正不可能是人的问题)。
因为不懂技术,MemOS 搭建与链接是这个系统里花时间最多的一段。
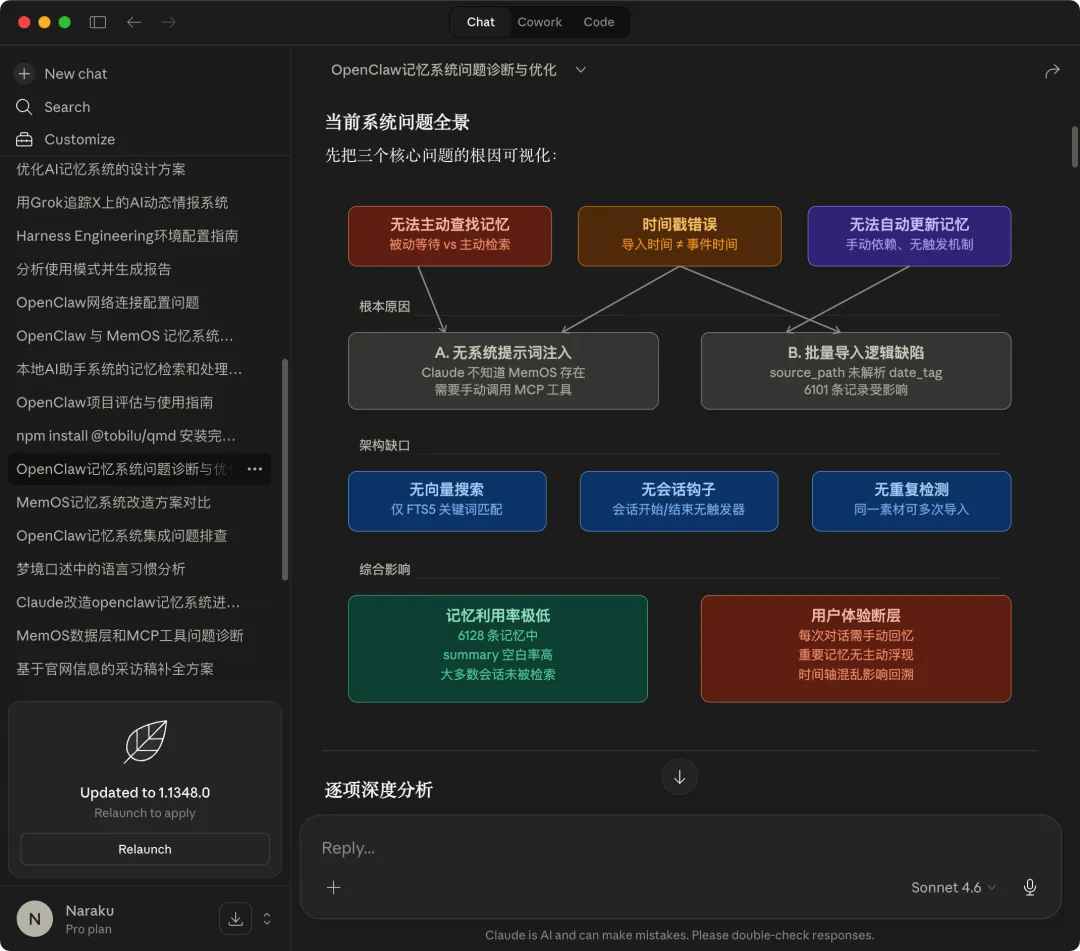
装环境只是开始。后面还有数据库、MCP、worker、同步脚本、查询方式、导入逻辑、时间戳、分类、去重、日记处理。
-
日记更新的问题:我每天都在Obsidian里写日记 ,每次对话也有新的输出。谁来读这些内容?谁来判断哪些是偏好、哪些是知识沉淀、哪些是流水账、哪些值得长期保留?没有这套机制,记忆库就会慢慢过期。
-
还有导入时的数据和时间问题,想让它不要只是堆素材(导入时间冲突导致所有的时间都是同一天),而是真的形成对”我这个人”的理解。
-
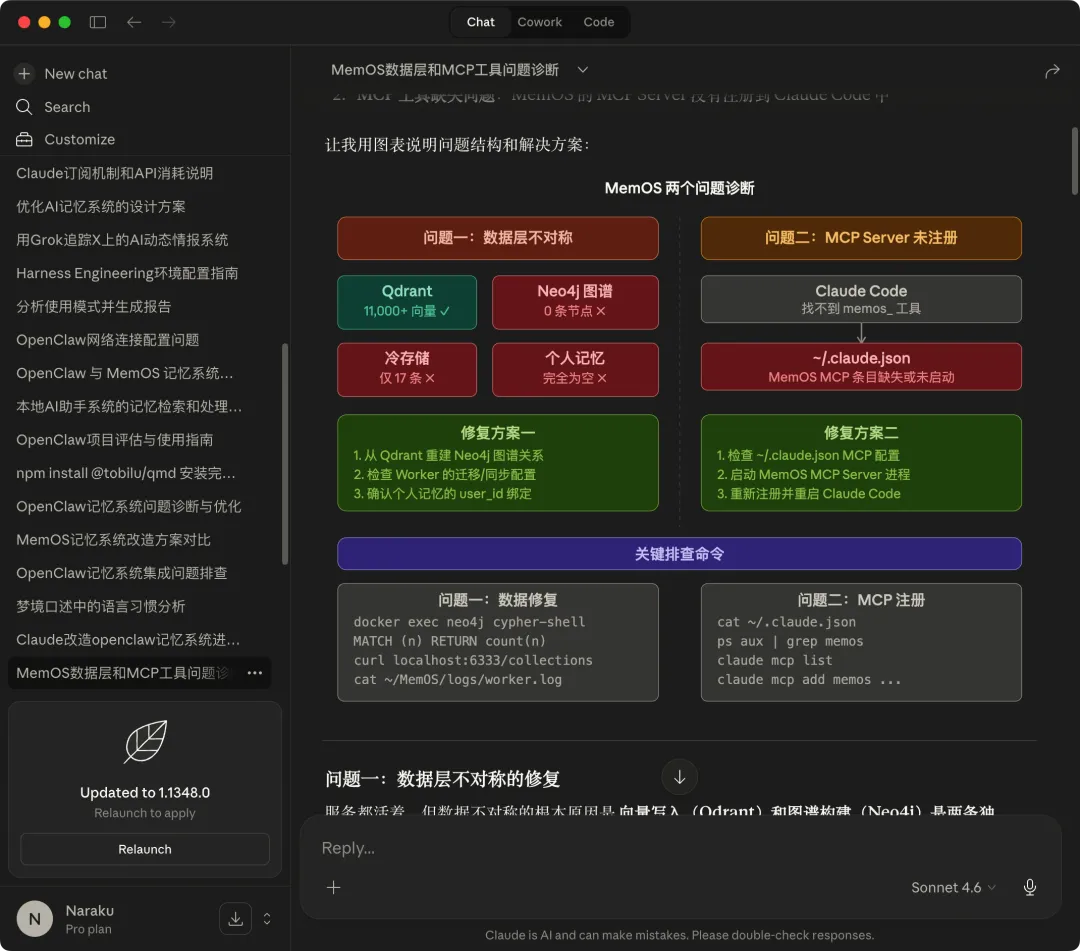
MCP的记忆查询问题:MemOS 的记忆查询要通过 MCP Server 进行,但 MCP Server 没有常驻机制,每次开新会话都要手动检查有没有在跑。有时候服务跑起来了,但进程没了,重启后还得重新导入配置。
最典型的一次:Qdrant 那边已经有 11,000 多条向量,Neo4j 一条没有。两个数据库根本没在同步,语义搜索和图谱查询走的是两套互不相干的数据。
那几条我还在修 MemOS 的查询问题。刚好X上开始铺天盖地宣传 Claude Code 源码泄露——”51 万行源码被人扒出来了”,各种截图和分析一窝蜂地出来。
如果只是平时刷到,我可能也就看看热闹。只是那时候我正卡在记忆这条线上,在吃瓜的同时,也是随大流,看看这个源码里有没有值得学习的东西。
-
-
-
-
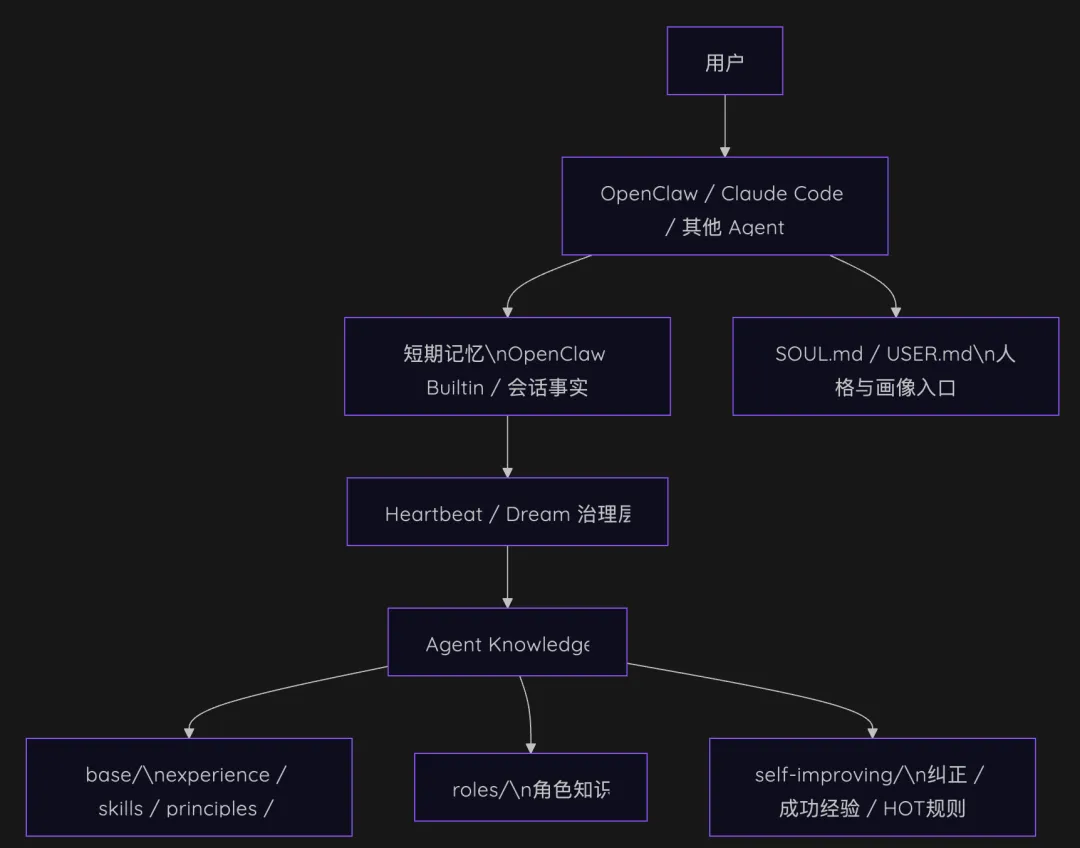
记忆、规则、工作流这些东西,是怎么被放到同一个框架里理解的
我原本以为记忆是仓库式的,内容越多AI才会越懂我;结果Claude的分析才是真相:记忆不是越多约好,是“有效的治理”才是最好。
也就是从这个阶段开始,我开始把几个东西放到一起看:规则怎么生效,偏好怎么留存,成功经验怎么写下来,错误怎么沉淀,会话结束以后哪些内容应该进入长期层。
这也是我后来为什么会专门去写资产地图、重建计划、配置手册和设计稿——我已经不只是在想”给 OpenClaw 接一个外挂记忆”,而是在重建一套长期助手的底层治理方式。
真正把这个判断彻底坐实的,是后来看到 Karpathy 的 LLM Wiki 方案。
Andrej Karpathy 是前特斯拉 AI 总监,也是早期参与 GPT 研究的人。他在 GitHub 上开了一个 Gist,写了自己怎么用 AI 维护一个持久化的知识库——不是传统的 RAG 检索,而是让 AI 把知识编译成可持续更新的 Markdown 文件。
问题是:高价值信息有没有被持续整理、持续更新、持续写回。如果没有,记忆再多,也很可能只是堆在那里。每次你问问题,系统还是临时去抓一点材料拼一下。真正重要的经验、判断、方法和长期有效的结论,仍然会散在各种聊天和日志里消失掉。
好答案不应该消失在对话里。高价值内容应该进入知识库。系统的重点不是一遍遍检索,而是持续维护一个能被调用、能被更新、能被交叉引用的长期结构。
刚好openclaw的新版也借鉴了Claude code源码的经验,上了做梦系统,再结合进化插件,我就重新调整了openclaw的记忆和进化系统:
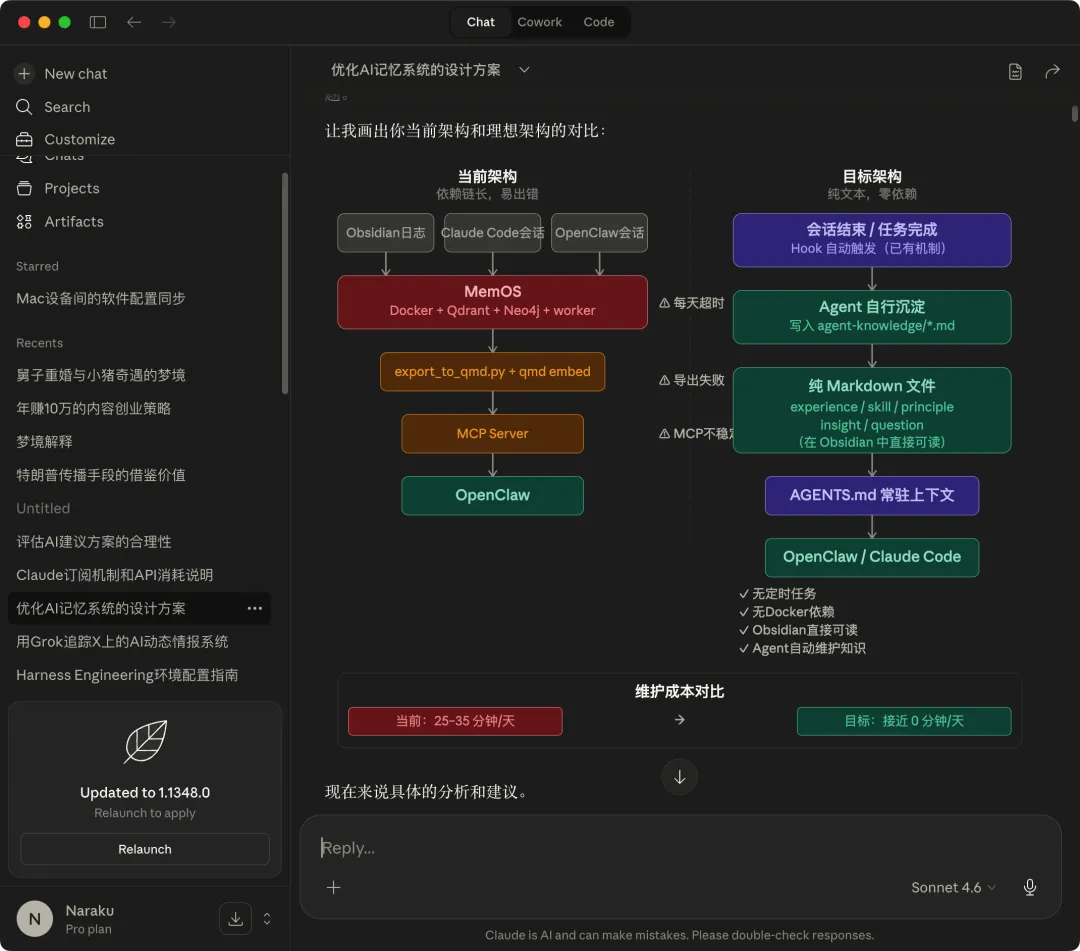
截图里的维护成本对比是真实数字:之前 25 到 35 分钟每天,现在接近 0。
没有向量库,没有 Docker,没有 MCP Server 要维护。
全是纯文本文件,Claude Code 和 OpenClaw 直接读。
如果你也有下面这些问题,那这套系统可能会对你有帮助:
-
你已经有自己的日志、笔记、资料库,但 AI 始终用不好。
那你需要的,往往不是”更大的记忆”,而是一套更稳的治理结构。
这也是我最后决定把它开源的原因。不是因为它已经完美,而是因为它终于从”概念很好”走到了”我愿意长期用下去”。
把 SOUL.md 和 USER.md 认真填一遍,再建一个 self-improving/ 目录,把 AI 纠正过你的地方开始记下来。治理从第一条记录开始。剩下的结构,等你真正需要的时候再加。
https://github.com/Elo-Mario/openclaw-memory-system
如果你也在折腾长期助手、个人知识库、AI 记忆系统,欢迎拿去试。如果你也踩过类似的坑,也欢迎回来交流。
 夜雨聆风
夜雨聆风