夜雨聆风
夜雨聆风





TensorRT-LLM 0.5.0 源码之十
linear.py
def _gemm_plugin(input: Tensor,
mat2: Tensor,
transa: bool = False,
transb: bool = False,
use_fp8: bool = False) -> Tensor:
plg_creator = trt.get_plugin_registry().get_plugin_creator(
'Gemm', '1', TRT_LLM_PLUGIN_NAMESPACE)
assert plg_creator is not None
transa = 1 if transa else 0
transa = trt.PluginField("transa", np.array(transa, dtype=np.int32),
trt.PluginFieldType.INT32)
transb = 1 if transb else 0
transb = trt.PluginField("transb", np.array(transb, dtype=np.int32),
trt.PluginFieldType.INT32)
use_fp8 = 1 if use_fp8 else 0
use_fp8 = trt.PluginField("use_fp8", np.array(use_fp8, dtype=np.int32),
trt.PluginFieldType.INT32)
p_dtype = default_net().plugin_config.gemm_plugin
pf_type = trt.PluginField(
"type_id", np.array([int(str_dtype_to_trt(p_dtype))], np.int32),
trt.PluginFieldType.INT32)
pfc = trt.PluginFieldCollection([transa, transb, pf_type, use_fp8])
gemm_plug = plg_creator.create_plugin("gemm", pfc)
plug_inputs = [input.trt_tensor, mat2.trt_tensor]
layer = default_trtnet().add_plugin_v2(plug_inputs, gemm_plug)
return _create_tensor(layer.get_output(0), layer)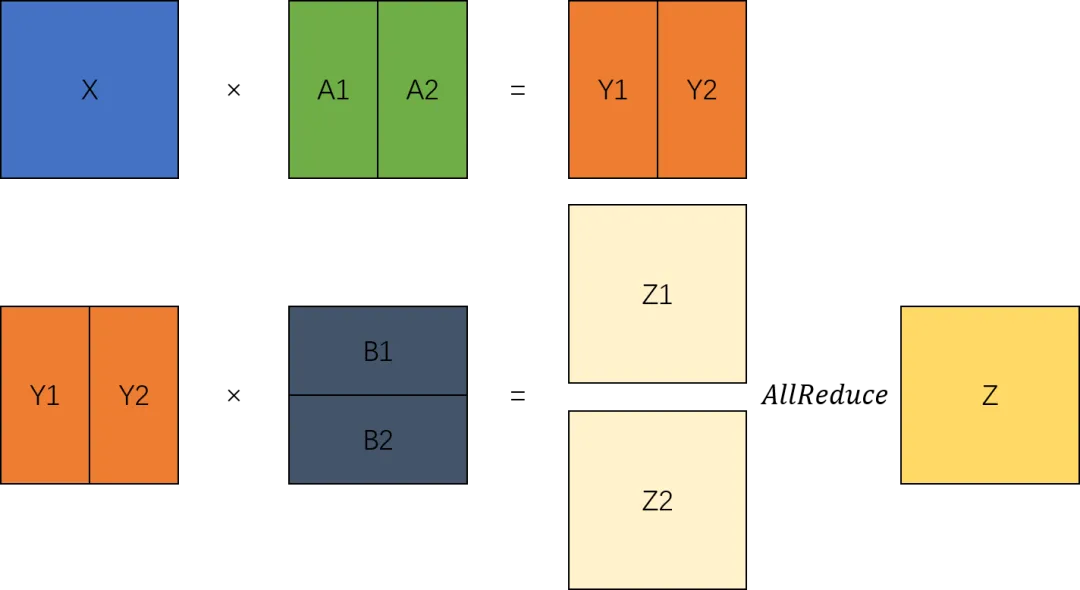
模型模块并行方案
Linear层作为切分主要的网络层,其核心是MatMul矩阵计算,因此矩阵切分计算也是模型并行最重要的一部分。
基础矩阵乘模块
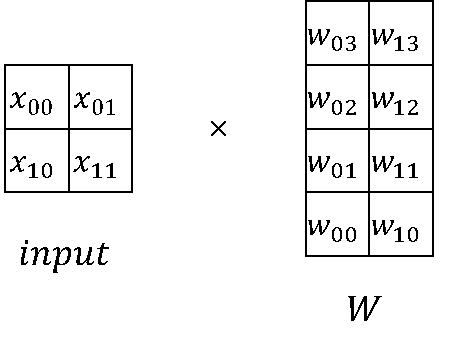
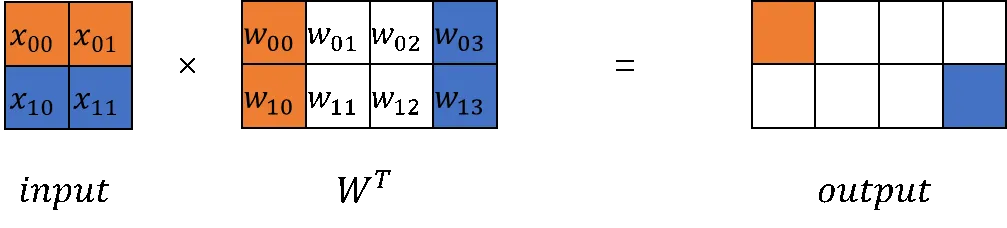
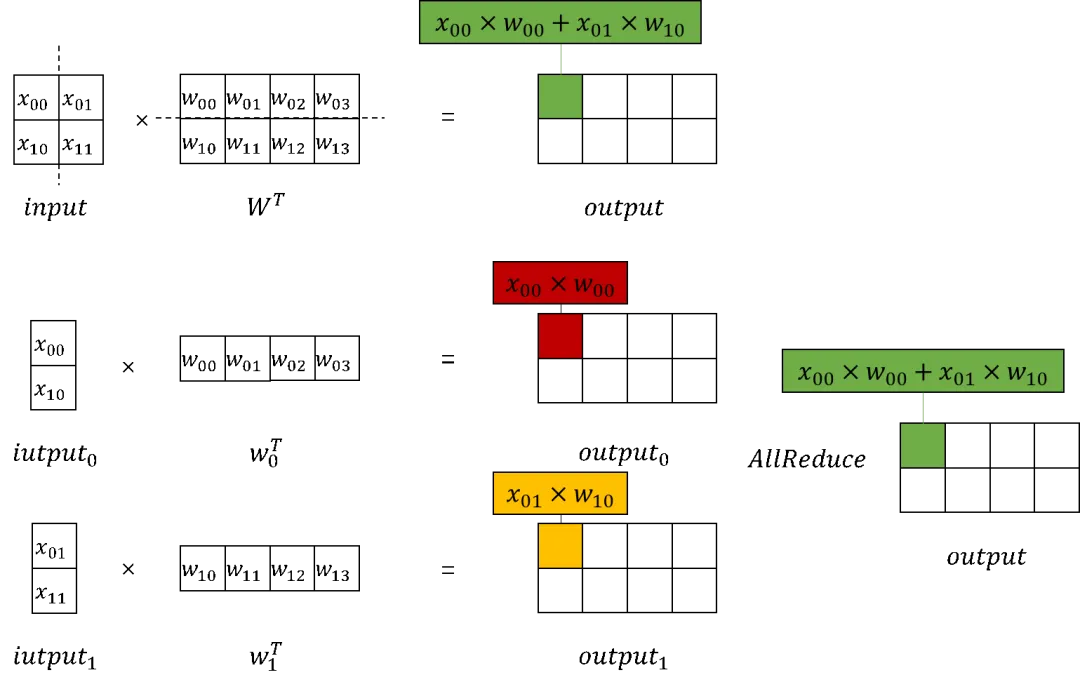
在大模型计算中,矩阵乘(MatMul)不管是在权重还是计算量上都占了相当大的比例。观察矩阵乘,其拥有列可切分性(Column-wise Parallelism)和行可切分性(Row-wise Parallelism)。
Column-wise Parallelism
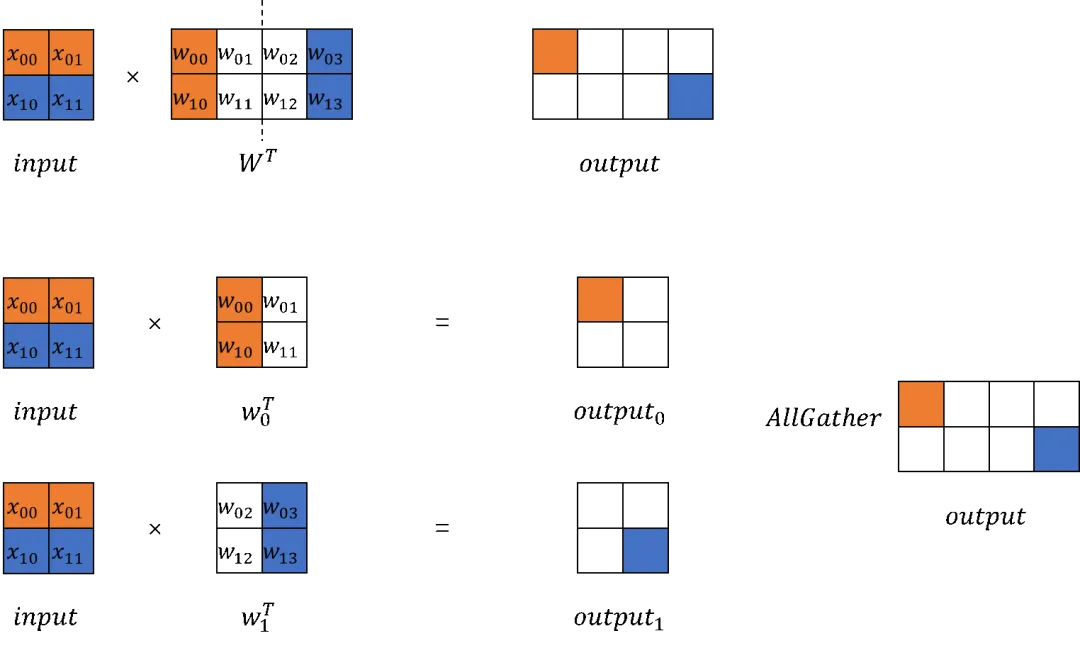
Row-wise Parallelism
ColumnLinaer
class Linear(Module):
def __init__(self,
in_features,
out_features,
bias=True,
dtype=None,
tp_group=None,
tp_size=1,
gather_output=True,
share_weight=None):
super().__init__()
self.in_features = in_features
self.out_features = out_features // tp_size
self.dtype = dtype
if not share_weight:
self.weight = Parameter(shape=(self.out_features, self.in_features),
dtype=dtype)
else:
self.weight = share_weight
self.tp_size = tp_size
self.tp_group = tp_group
self.gather_output = gather_output
if bias:
self.bias = Parameter(shape=(self.out_features, ), dtype=dtype)
else:
self.register_parameter('bias', None)
def multiply_gather(self, x, weight, gemm_plugin, use_fp8=False):
if gemm_plugin:
x = _gemm_plugin(x, weight, transb=True, use_fp8=use_fp8)
else:
x = matmul(x, weight, transb=True)
if self.bias is not None:
if x.dtype != self.bias.value.dtype:
x = cast(x, self.bias.value.dtype)
x = x + self.bias.value
if self.gather_output and self.tp_size > 1 and self.tp_group is not None:
# 1. [dim0, local_dim] -> [dim0 * tp_size, local_dim]
x = allgather(x, self.tp_group)
# 2. [dim0 * tp_size, local_dim] -> [dim0, local_dim * tp_size]
# 2.1 split
split_size = shape(x, dim=0) / self.tp_size
ndim = x.ndim()
starts = [constant(int32_array([0])) for _ in range(ndim)]
sizes = [shape(x, dim=d) for d in range(ndim)]
sizes[0] = split_size
sections = []
for i in range(self.tp_size):
starts[0] = split_size * i
sections.append(slice(x, concat(starts), concat(sizes)))
# 2.2 concat
x = concat(sections, dim=1)
return x
def forward(self, x):
return self.multiply_gather(x, self.weight.value,
default_net().plugin_config.gemm_plugin)
ColumnLinear = LinearRowLinear
class RowLinear(Module):
def __init__(self,
in_features,
out_features,
bias=True,
dtype=None,
tp_group=None,
tp_size=1,
instance_id: int = 0):
super().__init__()
self.in_features = in_features // tp_size
self.out_features = out_features
self.dtype = dtype
self.weight = Parameter(shape=(self.out_features, self.in_features),
dtype=dtype)
if bias:
self.bias = Parameter(shape=(self.out_features, ), dtype=dtype)
else:
self.register_parameter('bias', None)
self.tp_group = tp_group
self.tp_size = tp_size
self.instance_id = instance_id
def multiply_reduce(self,
x,
weight,
gemm_plugin,
use_fp8=False,
workspace=None):
if gemm_plugin:
x = _gemm_plugin(x, weight, transb=True, use_fp8=use_fp8)
else:
x = matmul(x, weight, transb=True)
if self.tp_size > 1 and self.tp_group is not None:
x = allreduce(x, self.tp_group, workspace, self.instance_id)
if self.bias is not None:
if x.dtype != self.bias.value.dtype:
x = cast(x, self.bias.value.dtype)
x = x + self.bias.value
return x
def forward(self, x, workspace=None):
return self.multiply_reduce(x,
self.weight.value,
default_net().plugin_config.gemm_plugin,
workspace=workspace)参考文献
-
• https://github.com/NVIDIA/TensorRT-LLM/blob/v0.5.0/tensorrt_llm/layers/linear.py -
• https://www.mindspore.cn/tutorials/zh-CN/r2.7.1/model_infer/ms_infer/ms_infer_parallel_infer.html