 夜雨聆风
夜雨聆风





【Nature】当 AI 不再只是工具,而是你的“虚拟同事”:解读 Nature 2025 虚拟实验室的产业真相
当 AI 不再只是工具,而是你的“虚拟同事”:解读 Nature 2025 虚拟实验室的产业真相
最近,Nature 2025 年发表的一篇关于“虚拟 AI 实验室设计新型 SARS-CoV-2 纳米抗体”的论文在圈子里炸开了锅。很多人第一反应是盯着那些漂亮的实验数据看,但作为一名在产业界摸爬滚打多年的人,我看到的却是另一番景象:这不仅仅是 AI 在生物设计上的又一次胜利,更是一次研发组织范式的根本性转移。
简单来说,我们正在从”AI 辅助人类”迈向“人机协同研发”。今天,我想抛开那些晦涩的学术术语,从技术转化和落地的角度,和大家聊聊这篇论文背后真正的产业价值,以及我们距离真正的“无人实验室”还有多远。
一、直击痛点:我们到底在为什么买单?
在生物医药行业,尤其是抗体工程领域,老板们最头疼的从来不是“有没有技术”,而是“成本”和“速度”。这篇论文的研究动机,恰恰精准地打中了工业界的三个死穴:
首先是跨学科协作的“天价”成本。做一个完整的抗体项目,你得凑齐免疫学家、计算生物学家、机器学习专家。这不仅仅贵,更难的是沟通。生物学家听不懂代码架构,CS 专家搞不懂蛋白折叠,这种“语言壁垒”消耗了大量时间。虚拟实验室的聪明之处在于,它用 AI 代理(Agents)模拟了这些角色。对于中小企业来说,这意味着你不需要养一支昂贵的多学科团队,就能启动复杂的项目,门槛被实实在在地降低了。
其次是与病毒赛跑的时间窗口。大家都记得 SARS-CoV-2 的变异速度,从 JN.1 到 KP.3,病毒不等人。传统的抗体开发流程太慢,往往“药出来了,病毒变了”。这项研究展示了一种极速流程——几天内就能构建完计算流程。在大流行病应对或快速迭代靶点时,这种速度就是生命线。
最后是研发流程的“非标”难题。工业界太缺乏将“科学直觉”转化为“标准代码”的工具了。以前每个新项目都要重新搭管道,现在虚拟实验室展示了 AI 自主构建工作流(Workflow)的能力。这意味着,研发 SOP 不再是死板的硬编码,而是可以动态生成的。
二、核心突破:不仅是预测,更是“编排”
如果只盯着纳米抗体设计,那就看浅了。这篇论文真正性感的的地方,在于它的多智能体协作架构(Multi-Agent Orchestration)。
想象一下,系统不再是一个只会回答问题的聊天机器人,而是一个虚拟的课题组。里面有 PI(主研人)负责统筹,有科学家负责执行,还有批评家负责挑刺。这种“基于角色的提示工程”具有极强的可迁移性。今天你能用它设计抗体,明天就能让它去搞小分子药物,甚至做材料筛选。你只需要把角色换成“合成化学家”或“安全评估员”,底层逻辑是通用的。
更妙的是它的会议机制。通过模拟“团队头脑风暴”和“个人任务执行”,它复现了真实实验室的管理流程。这种结构化的交互协议,保证了 AI 输出的逻辑是可追溯的,而不是随机生成的幻觉。同时,它能自主决定调用 ESM、AlphaFold 或 Rosetta 等工具,并自己写代码把它们串起来。AI 在这里扮演的是“集成者”的角色,这意味着你不需要重新训练模型,只要更新工具库,它就能适配现有的软件栈。
三、算一笔账:效率与成本的真实账本
抛开概念,我们来看看实打实的数据。结合论文图表,有几个数字非常值得玩味:
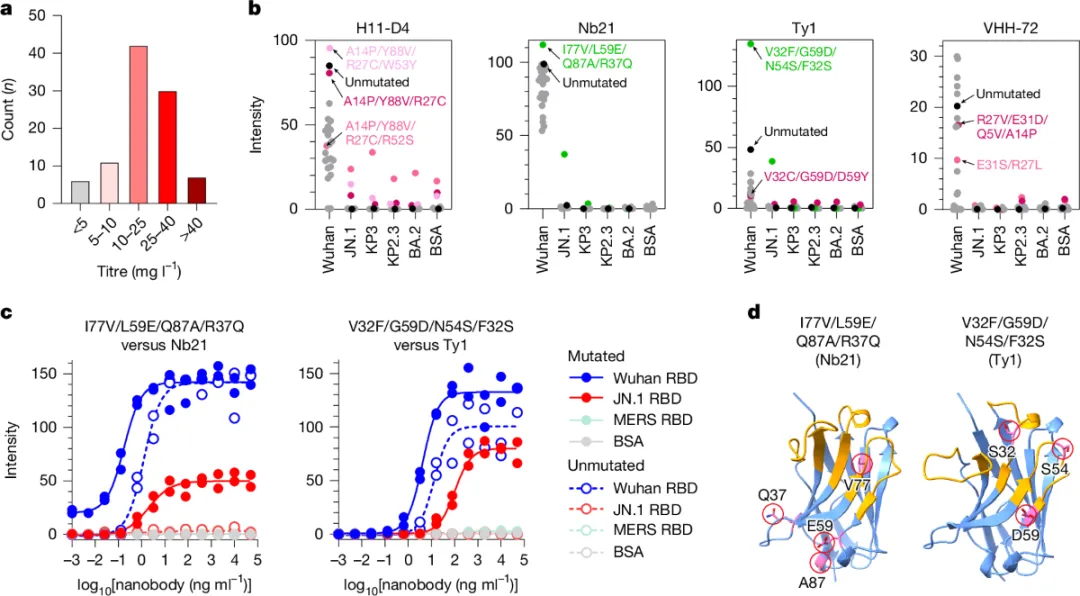
1. 湿实验成功率惊人: 在计算设计的 92 个候选分子中,超过 90% 在大肠杆菌中成功可溶性表达。行内人都知道,de novo 设计的蛋白表达成功率通常不到 50%。这说明 AI 设计的序列在生物物理层面非常“靠谱”。
2. 命中率(Hit Rate)高: 在 92 个候选物里,发现了 2 个关键突变体,不仅保留了原始结合力,还增强了对最新变异株的结合。考虑到这仅经过 4 轮迭代,这个开发价值是巨大的。
3. 成本被压缩了数量级: 构建完整计算流程,人类专家可能要几周,虚拟实验室只要几天。更夸张的是,LLM 交互的 Token 成本只要10-20 美元。虽然没算算力成本,但决策层的智力成本确实被打下来了。
4. 人力杠杆效应: 人类研究人员仅输入了总文本量的 1.3%(约 1596 词),却驱动了 12 万词的 AI 生成内容。这意味着,一个科学家现在可以管理相当于整个团队产出的工作量。
四、冷思考:从 Paper 到 Product 的鸿沟
当然,作为从业者,我们必须保持清醒。学术成果亮眼,不代表工业化产品就能马上落地。从实验室走向生产线,中间还隔着几座大山:
第一,幻觉与安全风险。 论文里也承认,AI 生成的代码需要人工调试。在工业界,一段错误代码可能意味着昂贵的算力浪费,甚至实验事故。我们需要构建沙箱环境来自动验证代码。此外,LLM 的知识是有截止日期的(比如可能不知道 AlphaFold 3),工业应用必须结合RAG(检索增强生成),实时连接最新文献,防止 AI“一本正经地胡说八道”。
第二,湿实验闭环还没打通。 目前还是”AI 设计 -> 人类实验验证”的半自动模式。真正的产业落地,必须与自动化实验室(Cloud Lab/Robotics)打通,实现“设计 – 合成 – 测试 – 学习”的全自动闭环。只要蛋白表达和检测还需要人动手,速度瓶颈就依然存在。
第三,知识产权与合规的灰色地带。 由 AI 代理主导设计的抗体,专利算谁的?FDA 或 EMA 对于 AI 完全参与设计的分子,会不会有额外的验证要求?数据的可追溯性必须满足 GLP/GMP 规范,而 LLM 的随机性(Temperature 设置)与此天然冲突。这些都是法务和注册部门未来要头疼的问题。
五、给产业界的务实建议
基于以上分析,如果你是一家生物医药企业或研发机构,我的建议是:保持乐观,但步子要稳。
1.定位为”Copilot”而非”Autopilot”:短期内别想着完全取代科学家。把虚拟实验室当作高级辅助工具,用于加速早期靶点验证和方案预演。人类专家必须保留“最终决策权”,特别是在关键节点进行核实。
2.构建私有知识库:利用论文中的多智能体架构,但底层模型最好经过企业私有数据微调,或结合内部实验数据构建 RAG 系统。这既解决了通用模型知识滞后问题,又能保护核心 IP 不泄露。
3.先挑“软柿子”捏:最适合落地的场景是抗体人源化、亲和力成熟、稳定性优化等迭代型任务,而不是完全从零开始的 de novo 设计。这些场景容错率高,能快速看到 ROI。
4.基建要跟上:为了最大化虚拟实验室的潜力,你得同步投资高通量筛选平台和液体处理机器人。只有当湿实验速度跟上 AI 设计速度时,这项技术的价值才能彻底释放。
写在最后
这篇论文标志着 AI for Science 从“工具辅助”迈向了“流程自主”的关键一步。虽然距离完全自主的“无人实验室”还有工程距离,但它展示的多智能体协作范式,已经具备了极高的产业转化价值。
对于行业而言,最大的机会不在于等待一个完美的 AI,而在于谁能更快地将这种“虚拟同事”整合进现有的研发流中,在降低门槛和加速发现之间,找到属于自己的平衡点。