 夜雨聆风
夜雨聆风





【Python办公】提取 PDF 表格写进 Excel桌面工具
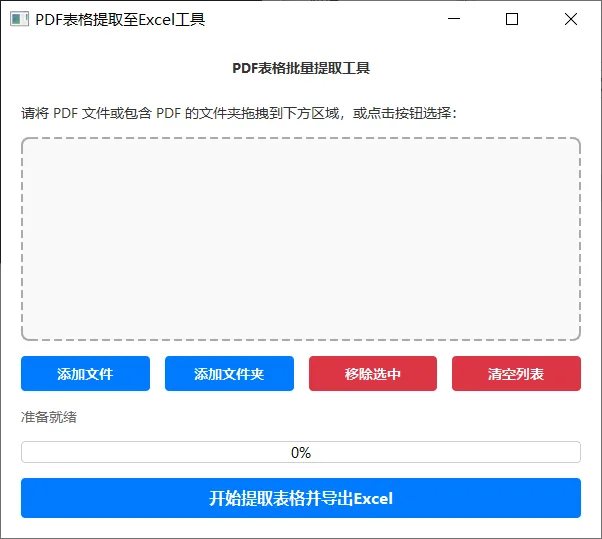
使用 PyQt5 和 pdfplumber 打造一款好用的“提取 PDF 表格写进 Excel”桌面工具
在日常的办公和数据处理过程中,我们经常会遇到需要将 PDF 文件里的数据表格提取出来,并放到 Excel 中进行二次分析的情况。虽然市面上有很多转换工具,但往往收费或者带有一些限制。作为一个程序员,为什么不自己动手丰衣足食呢?
今天,我们就来使用 Python,结合 PyQt5 构建美观的图形界面,搭配 pdfplumber 强大的 PDF 表格解析能力,亲手打造一款支持文件拖拽、批量处理的“PDF表格提取工具”。
欢迎大家关注此公众号,后台留言”python书籍”可免费获取【Python办公自动化高清PDF】电子书一本
此外小庄推荐一本适合于新手\小白入手一本 Python基础书籍,欢迎大家订阅
🛠️ 技术选型
-
1. 界面库:PyQt5
PyQt5 是 Python 中最强大的跨平台 GUI 框架之一,相比于 Tkinter,它的控件更加丰富,界面也更容易做得现代和美观,支持高度自定义样式(QSS)和复杂的事件处理(如拖放功能)。 -
2. PDF解析库:pdfplumber pdfplumber专门用于从 PDF 中提取文本和表格。相比于PyPDF2或pdfminer,pdfplumber在处理表格和页面布局方面有着极大的优势,能直接以二维数组形式返回提取到的表格,非常方便。 -
3. 数据处理与导出:pandas & openpyxl
使用pandas可以轻松把二维数组转换为 DataFrame,清理空行空列后,再利用openpyxl引擎写入 Excel 文件(.xlsx)中,支持将同一 PDF 中的不同表格存入不同 Sheet 页。
🎨 界面设计与实现
为了提升用户体验,我们的工具不仅要有普通的“添加文件”按钮,还必须支持直接拖拽 PDF 文件或包含 PDF 的文件夹。
1. 自定义支持拖拽的列表组件
在 PyQt5 中,想要实现拖拽接收,我们需要继承并重写组件(例如 QListWidget)的拖拽事件方法:dragEnterEvent、dragMoveEvent 和 dropEvent。
classDropListWidget(QListWidget):
files_dropped = pyqtSignal(list)
def__init__(self, parent=None):
super().__init__(parent)
self.setAcceptDrops(True) # 开启接收拖放
self.setSelectionMode(QAbstractItemView.ExtendedSelection)
# 简单美化:虚线边框和悬停选中效果
self.setStyleSheet('''
QListWidget { border: 2px dashed #aaa; border-radius: 8px; ... }
''')
defdropEvent(self, event):
if event.mimeData().hasUrls():
event.setDropAction(Qt.CopyAction)
event.accept()
links = []
for url in event.mimeData().urls():
if url.isLocalFile():
links.append(url.toLocalFile())
# 发送自定义信号,将获取到的文件路径列表传递出去
self.files_dropped.emit(links)2. 构建主界面与交互
主界面中包含了标题、操作提示、自定义的拖拽列表、操作按钮(添加、移除、清空),以及底部的进度条和执行按钮。我们通过 QSS 设置了按钮的蓝色主题,让其看起来像现代的 Web 风格按钮。
通过 os.walk,当用户拖入或者选择文件夹时,程序会自动递归查找并过滤出所有的 .pdf 文件并加入待处理集合中。
⚙️ 核心逻辑:PDF 表格提取与 Excel 写入
直接在主线程中处理 PDF 提取会导致界面卡死无响应。为了解决这个问题,我们需要借助 PyQt5 的 QThread 创建一个后台工作线程。
1. 多线程处理 WorkerThread
工作线程负责遍历用户选择的 PDF 列表,并通过自定义信号 pyqtSignal 实时向主线程发送进度更新和日志信息。
2. 提取并清洗数据
提取表格的核心逻辑非常简单,利用 pdfplumber 依次打开 PDF 页面并调用 extract_tables():
with pdfplumber.open(pdf_path) as pdf:
for page_num, page inenumerate(pdf.pages):
tables = page.extract_tables()
for table_idx, table inenumerate(tables):
cleaned_table = []
for row in table:
# 清洗数据,将 None 转为空字符串,并去除多余空格
cleaned_row = [str(cell).strip() if cell isnotNoneelse""for cell in row]
# 过滤掉全为空的无效行
ifany(cleaned_row):
cleaned_table.append(cleaned_row)
if cleaned_table:
# 使用 pandas DataFrame 进行组织
df = pd.DataFrame(cleaned_table[1:], columns=cleaned_table[0]) iflen(cleaned_table) > 1else pd.DataFrame(cleaned_table)
all_tables.append((f"Page_{page_num+1}_Table_{table_idx+1}", df))3. 导出为 Excel 多个 Sheet
当我们把一个 PDF 中的所有表格都提取为 DataFrame 后,就可以利用 pd.ExcelWriter 配合 openpyxl 引擎批量写入同一个 Excel 文件。不同表格分别放在不同的 Sheet 页,Sheet 的名称直接对应 PDF 的页码和表格序号。
if all_tables:
with pd.ExcelWriter(excel_path, engine='openpyxl') as writer:
for sheet_name, df in all_tables:
df.to_excel(writer, sheet_name=sheet_name[:31], index=False)🎯 总结
通过上述实现,我们不仅复习了 PyQt5 界面的开发(自定义控件、QSS 样式、信号与槽机制)、多线程 QThread 的无阻塞处理方式,还掌握了使用 pdfplumber 解析 PDF 以及用 pandas 生成复杂 Excel 文件的方法。
这个工具对于财务、人事或者需要经常和 PDF 报表打交道的打工人来说非常实用,你可以随时在本地批量提取数据,再也不用手动去复制粘贴了。希望这篇文章对你有所启发,赶快动手去试一试吧!