 夜雨聆风
夜雨聆风





Claude code 源码学习(二)
今天重点梳理 Context Engineering 相关的部分,深入剖析 Claude Code 的上下文构建与记忆管理机制。
2.1 输入消息构建与响应流向
在 Claude Code 中,单次查询由 QueryEngine 负责封装。它是外层的会话协调者,统筹系统提示词组装、用户输入处理、Transcript 持久化以及最终结果汇总。
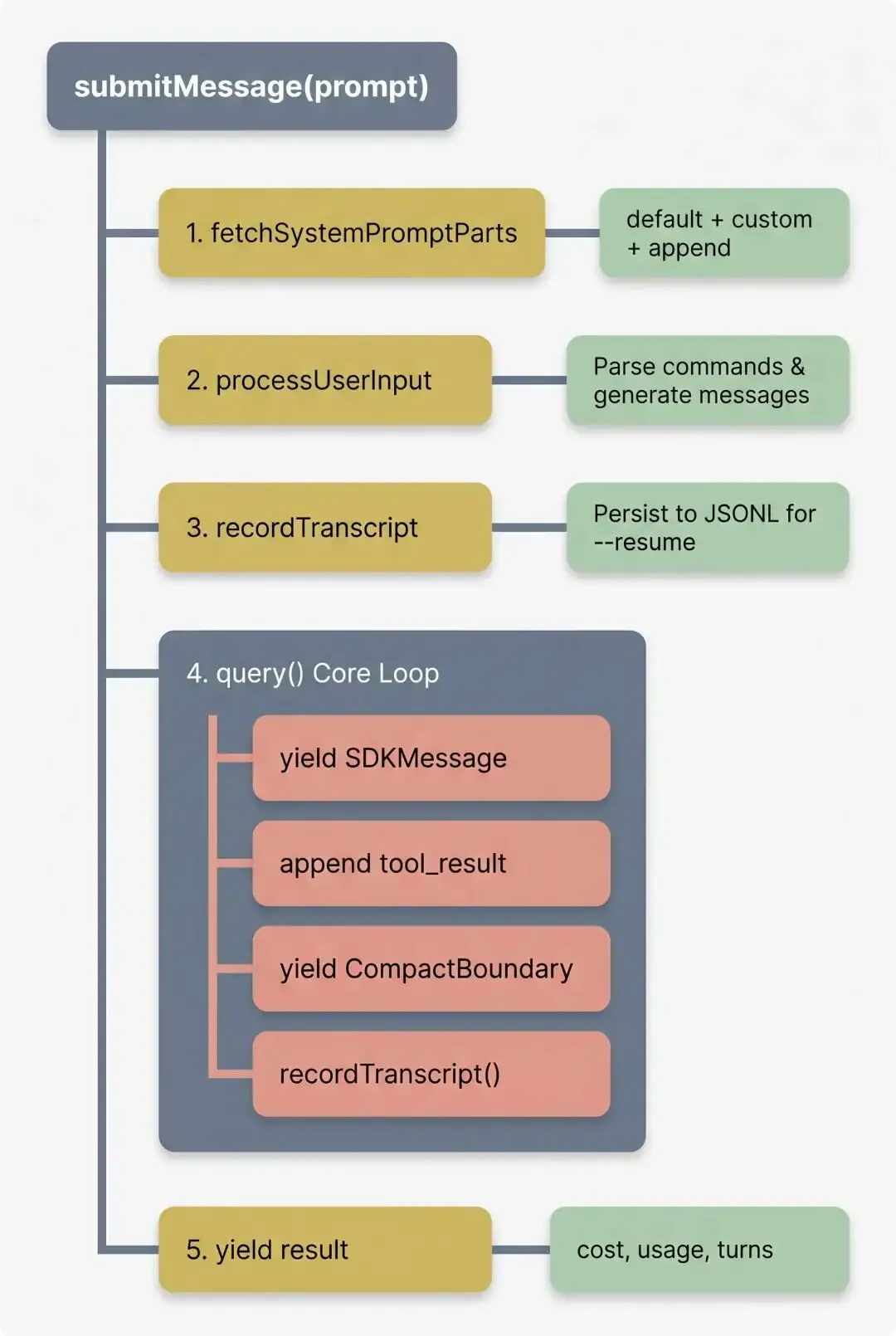
而实际执行查询循环(Query Loop)的则是 query.ts。一次 Claude API 调用组装的提示词可以分成三大块,分别是system、user 和 tool,上下文信息主要位于 user 段:

API 响应也具有不同的类型,各类型消息的最终流向如下:
响应 Block Yield 给调用方 进入下轮 Messages 持久化
───────────── ────────────── ───────────────── ────────
text ✓ AssistantMessage ✓ assistantMessages ✓ JSONL
thinking ✓ AssistantMessage ✓ assistantMessages ✓ JSONL
tool_use ✓ AssistantMessage ✓ assistantMessages ✓ JSONL
tool_result ✓ ToolResultMessage ✓ toolResults ✓ JSONL
compact_boundary ✓ SDKCompactBoundary ✓(替换历史) ✓ JSONL
tool_result:Claude API 并没有原生的 Tool 角色,因此tool_result被伪装成 User Message 传入。该消息的content包含结构化数据{ type: 'tool_result', tool_use_id, content },用于承载工具的输出。
compact_boundary:这是上下文压缩后插入的分水岭标记。后续的 API 调用仅携带该 Boundary 之后的消息。当QueryEngine处理到该标记时,会立即执行splice(0, boundaryIdx),释放之前所有历史消息的内存。
2.2 上下文窗口压缩
触发时机:系统在每轮 Query Loop 开始时进行检查,基于“有效上下文窗口(模型总窗口 – 输出预留)”设置了多档阈值:
有效上下文窗口
├── - 20,000 → Warning / Error 阈值(触发 UI 警告)
├── - 13,000 → Autocompact 阈值(触发自动压缩)
└── - 3,000 → Blocking Limit(硬阻断,拒绝发起 API 调用)
注意:Autocompact 若连续失败 3 次将停止重试,以防止无效的 API 调用堆积。
自动压缩的产出结构:
[compact_boundary] + [摘要消息] +[messagesToKeep] + [attachments] + [hookResults]
摘要生成机制:摘要由 Fork 出的独立 Agent(使用 Haiku 模型)生成。该 Agent 与主对话共享 Prompt Cache 前缀,从而大幅降低 Cache Miss 的成本。
此外,系统提供了 PreCompact Hook,允许在压缩执行前注入自定义指令来干预摘要内容。
2.3 记忆检索:为什么不用 RAG?
Claude Code 的记忆检索并没有使用 RAG(检索增强生成),而是通过小模型执行 Side-query。Side-query 的系统提示词节选如下:
You are selecting memories that will be useful to Claude Code as it processes a user's query.
You will be given the user's query and a list of available memory files with their filenames and descriptions.
Return a list of filenames for the memories that will clearly be useful to Claude Code...
(up to 5). Only include memories that you are certain will be helpful...
- If you are unsure... do not include it.
- If there are no clearly useful memories... return an empty list.
- If a list of recently-used tools is provided, do not select usage reference or API documentation for those tools — DO still select memories containing warnings, gotchas, or known issues.
为避免解析失败,返回格式被严格限制为 JSON Schema({ selected_memories: string[] })。同时通过 alreadySurfaced 机制去重,确保已注入过的文件不占用 5 个召回名额。
放弃 RAG 而采用小模型的工程考量
-
分发成本(轻量化):Claude Code 是本地 CLI 工具。引入向量数据库(如 Chroma、Faiss)会带来额外的二进制依赖、索引文件管理和跨平台兼容问题,对命令行工具而言过于沉重。 -
数据量未达 RAG 门槛:个人使用场景下,记忆文件通常只有几十条。RAG 的核心优势在于海量语料库中的近似搜索。而在小数据量下,将所有 Description 组装后发给小模型做全量比对,Token 消耗极低且速度足够,无需建立倒排或向量索引。 -
跨语义的意图理解:RAG 的向量匹配本质是统计相似度,难以判断“某条记忆对当前任务是否有用”。例如“用户偏好简洁回复”这条记忆与具体 Query 的向量相似度极低,但实际上对所有任务都有效。LLM 能精准捕捉这种跨语义的“有用性”。 -
动态规则过滤:提示词中明确要求“如果模型正在使用某工具,则过滤该工具的 API 文档”。这属于逻辑推理而非文本检索,向量数据库无法表达此类动态规则。 -
零冷启动与无状态:RAG 每次写入新记忆都需要更新索引。小模型方案则是纯无状态的,记忆文件可随时增删,下次 Query 直接扫描文件目录即可,维护成本为零。
核心结论:RAG 解决的是“大规模语料的检索效率”问题,而 Claude Code 面临的是“少量条目的意图判断”问题。在这里,一次走 Prompt Cache 的小模型 API 调用,比 RAG 更准、更轻、更灵活。
2.4 记忆管理 (Memory)
消费机制
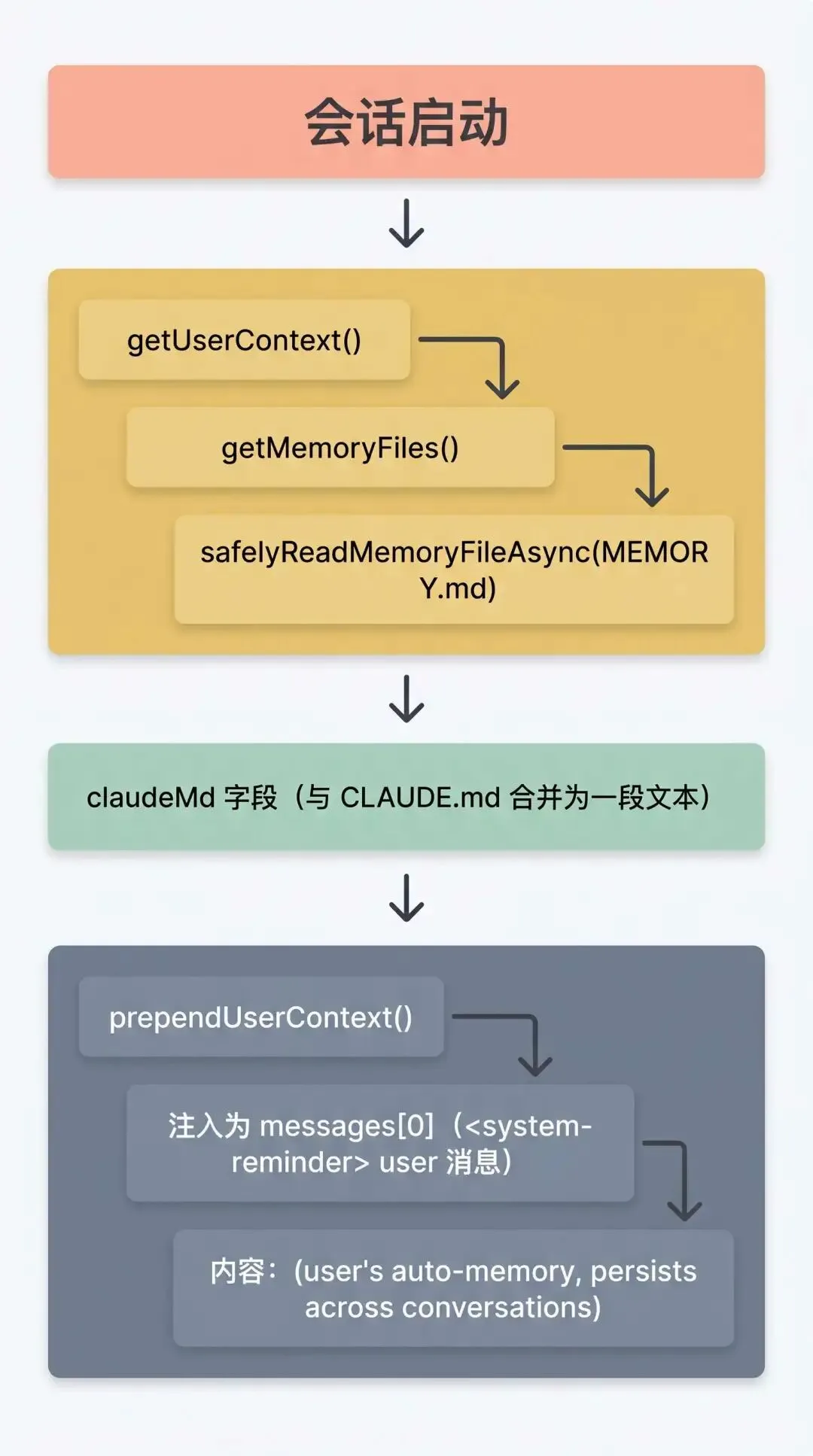
MEMORY.md 作为记忆的索引文件,在会话启动时通过 getUserContext() 读入内存。该函数被 memoize 处理,单次会话仅执行一次。
其内容会被合并进 claudeMd 字段,并通过 prependUserContext() 使用 <system-reminder> 标签包装,注入到 messages[0] 中,伴随每次 API 调用下发。索引行的标准格式为:- [Title](file.md) — one-line hook。
读取正文:主 Agent 读到感兴趣的索引条目后,会主动发起 Read 工具调用获取文件正文。
此外,代码中还有一条实验性路径:findRelevantMemories() 会在每轮开始前用 Sonnet 模型筛选相关文件,并直接以 Attachment 形式注入,免去模型主动 Read 的步骤(目前受 Feature Gate 控制,未全量开放)。
<system-reminder>用于标记伪造的 user message,表明这并非用户的原始输入,可以用于模型区分和程序处理时的过滤。
维护机制
系统没有为记忆设计自动过期或 TTL 机制,而是完全依赖提示词引导模型主动进行生命周期管理,共分四层防御:
-
写入时合并:当检测到用户纠正或确认时,模型应更新已有记忆,而非新建条目。 -
时效性警示:提示词明确告知模型,记忆仅代表过去某个时间点的状态。若回忆内容与当前观察冲突,必须信任当前观察,并主动更新或删除过期记忆。 -
使用前验证:对于涉及文件、函数、Flag 的记忆,模型在使用前必须验证其当前真实性(“The memory says X exists” is not the same as “X exists now”)。 -
绝对时间标记:写入 project类型记忆时,强制要求将相对日期(如“下周四”)转换为绝对日期(如“2026-04-19”),赋予记忆时间戳语义,辅助后续的时效性判断。
写入机制
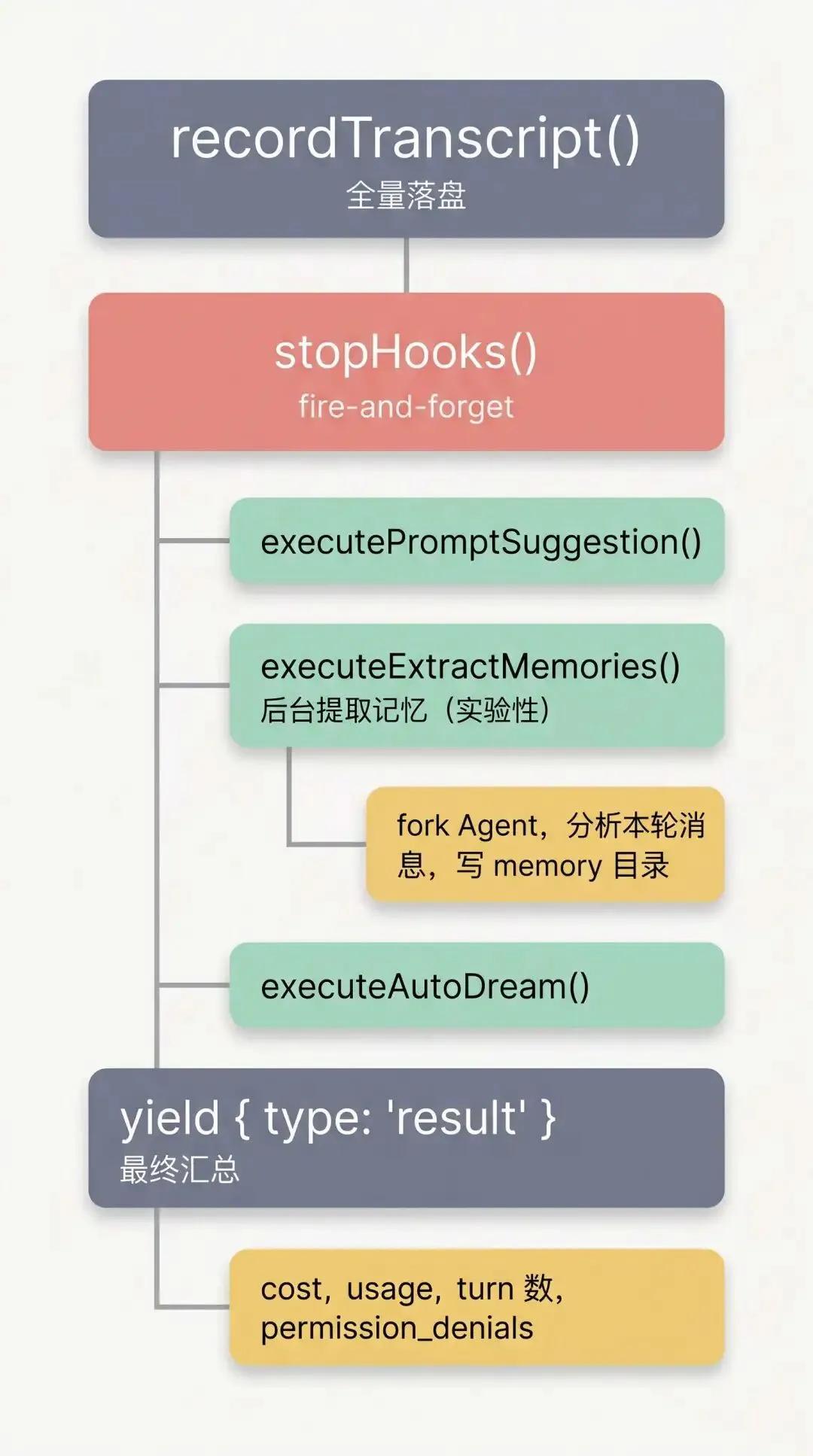
记忆写入分为“主 Agent 主动写入”和“后台 Agent 异步提取”两条路径:
|
|
|
|
|---|---|---|
| 触发时机 |
|
|
| 触发主体 |
|
|
| 用户可见性 |
|
|
坑与警告:路径 B 目前处于灰度实验阶段,受编译期
feature('EXTRACT_MEMORIES')和 GrowthBook 实验开关tengu_passport_quail双重控制。这两条路径互斥:若主 Agent 本轮已写入记忆,后台 Agent 将跳过提取以防重复。
两条路径共用相同的记忆分类标准(memoryTypes.ts)。主 Agent 的系统提示词常驻记忆维护模块,为每种类型定义了 <when_to_save>:
-
user:学到用户的角色、偏好、职责、知识。 -
feedback:用户纠正了做法,或确认了某个非显而易见的做法有效(提示词强调 “confirmations are quieter — watch for them”)。 -
project:了解到谁在做什么、为什么做、截止时间。 -
reference:了解到外部系统中资源的位置(如 Linear、Slack)。
总结
回顾全文,Claude Code 的上下文管理机制可以清晰地划分为两个层次:
-
当前会话级别:聚焦短期记忆。通过多档阈值监控、 compact_boundary截断以及自动摘要,精细控制单次对话的窗口长度,防止 Token 溢出。 -
跨会话级别:聚焦长期记忆。摒弃了厚重的 RAG 架构,完全依靠小模型的意图检索和提示词引导,实现历史经验的无状态读写与淘汰。
无论是短期的会话维护,还是长期的记忆调度,这两个层次最终都由 QueryEngine 作为核心枢纽统一驱动。整体架构没有堆砌复杂的外部组件,而是将大模型原生的推理和缓存能力用到了极致。