 夜雨聆风
夜雨聆风





【AI资讯】爱奇艺悄悄上架"AI艺人"遭明星集体打脸,肖像权争议背后的影视困局

🤖 AI 资讯日报
每日精选 · 投融资 · 政策 · 技术 · 产品 · 大厂 · 活动 · Paper
2026年4月21日 · 星期二
📌 今日重点摘要
-
亚马逊千亿美金押注 Anthropic — 十年1000亿美元算力长约+250亿美元投资
-
Sergey Brin 发内部动员令 — Google 全员追赶 Anthropic 编程 Agent
-
Kimi K2.6 万亿参数开源 — 代码能力对标 GPT-5.4,Agent 并行 300 个子智能体
-
Qwen3.6-Max 霸榜 HN 509分 — 阿里编码模型登顶今日最热 AI 帖
-
Deezer 每日 7.5 万首 AI 音乐涌入 — 占上传量 44%,85% 被认定欺诈
投融资
🔥 亚马逊与 Anthropic 深化合作:千亿美元十年长约 + 250亿美元投资
亚马逊宣布与 Anthropic 大幅深化战略合作,Anthropic 未来十年将向 AWS 采购超 1000 亿美元算力资源,亚马逊则在此前 80 亿美元基础上追加至多 250 亿美元投资(首批 50 亿立即到账,200 亿视里程碑逐步释放)。双方还将联手优化未来 Trainium 芯片,AWS 将为 Anthropic 提供合计 5GW 的多世代 Trainium 算力容量。这是目前 AI 领域规模最大的单笔战略合作之一,凸显大厂对算力锁定和 AI 基础设施投入的”军备竞赛”态势。
🔗 来源:IT之家
DeepSeek 开启首轮外部融资,估值超百亿美元
国产大模型黑马 DeepSeek 正式启动首轮外部融资,计划募资约 3 亿美元,投后估值超 100 亿美元。据悉,由于研发成本上升及核心人才竞争加剧,DeepSeek 需要资本注入以维持技术迭代速度。这标志着中国 AI 独角兽的融资门槛进一步提高,头部公司的资源虹吸效应愈发明显。
🔗 来源:AIbase
蚂蚁灵光 App 投入 1 亿元启动创作者激励计划
蚂蚁集团 AI 产品”灵光 App”宣布投入 1 亿元专项基金,启动”灵光闪应用创作者激励计划”。自 2025 年底上线以来,灵光 App 已累计产生超 3000 万个用户通过自然语言生成的闪应用,覆盖工具、游戏、社交等多维度,形成全球最大的”个人应用生态”。
🔗 来源:AIbase
政策与监管
🔥 NSA 被曝使用 Anthropic 的 Mythos 模型,无视供应链黑名单
据 Axios 报道,美国国家安全局(NSA)正在使用 Anthropic 受限的 Mythos 网络安全模型,尽管该模型此前因供应链风险被列入限制名单。The Verge 证实白宫也正在准备获取 Mythos 的访问权限。此事引发对军事和情报机构使用前沿 AI 模型边界的广泛讨论——尤其是 Mythos 据称发现了数千个主流操作系统的高危漏洞。
🔗 来源:The Verge | HN 433▲
德国法院裁定:用 AI 将版权照片二创成漫画未必构成侵权
德国杜塞尔多夫高等法院最新判决指出,AI 将他人版权照片转化为漫画风格图片不必然构成侵权。关键在于 AI 生成作品是否复制了原作的构图、视角、光线等受保护的”创造性元素”,而摄影主题本身不在版权保护范围内。法院同时强调,AI 作品需有人类”可识别的创造性决策”才可获得版权。此判决为欧洲 AI 创作领域提供了重要法律参考。
🔗 来源:IT之家
Bernie Sanders 联合工会呼吁 AI 劳动保护,称”数据中心建设应暂停”
美国参议员 Bernie Sanders 与多个工会领袖联合发声,推动 AI 技术演进中的就业保护立法。Sanders 已提出暂停数据中心建设的法案,并警告如果不加管控,”十年内制造业就业的概念将不复存在”。该活动反映了美国社会对 AI 大规模取代人类工作的深层焦虑。
🔗 来源:The Verge
技术动态
🔥 月之暗面发布并开源 Kimi K2.6:万亿参数 MoE 模型,代码能力对标 GPT-5.4
月之暗面发布其最强模型 Kimi K2.6 并全面开源,1T 参数、32B 激活参数、384 个专家,支持 256K 上下文和原生多模态。在 HLE(人类终极考试)、SWE-Bench Pro(软件工程基准)和 DeepSearchQA 等测试中,K2.6 表现持平或优于 GPT-5.4、Claude Opus 4.6 和 Gemini 3.1 Pro。实测能连续编码 13 小时、执行 4000+ 次工具调用;Agent 集群支持 300 个子 Agent 并行处理。同步发布 Kimi Vendor Verifier(KVV)工具,帮助开发者验证第三方推理服务的精度。

🔗 来源:IT之家 / Kimi Blog | HN 142▲
🔥 阿里发布 Qwen3.6-Max-Preview,强化 Agent 编程能力
阿里通义千问发布 Qwen3.6-Max-Preview 预览版,在 Agent 编程、世界知识和指令遵循方面实现显著提升,AIME 2026 #15 和 Code Arena 排名均有亮眼表现。HN 热度高达 509 分,是今日 AI 相关最火帖。社区评论认为这是中国开源/半开源实验室在编码和 Agent 模型领域竞争力持续上升的标志。
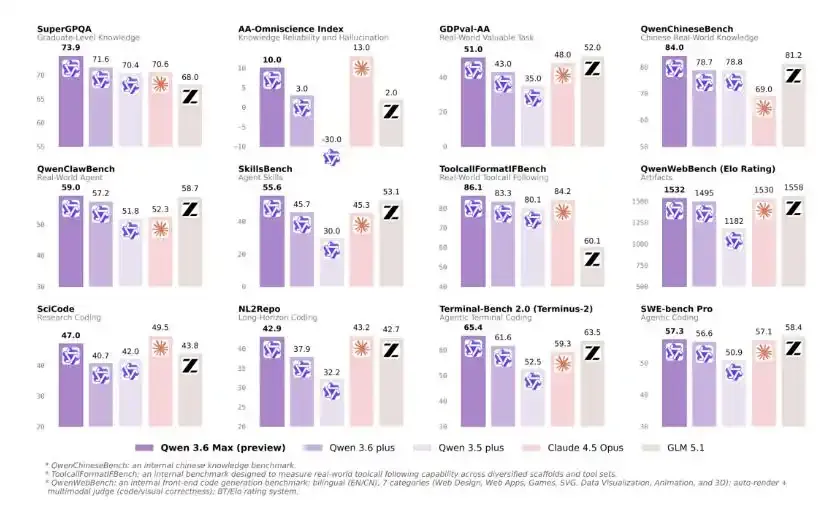
🔗 来源:HN 509▲ / AI News
LuceBox:RTX 3090 上 Qwen3.5-27B 推理达 207 tok/s
开源项目 LuceBox 发布两个针对特定消费级硬件手动优化的推理引擎:Megakernel(单次 CUDA dispatch 跑完 24 层 Qwen3.5-0.8B)和 DFlash+DDTree(基于 GGUF 的推测解码),在 RTX 3090 上实现 Qwen3.5-27B 的 207 tok/s 推理速度,比自回归方式快 5.46 倍,比 SGLang AWQ 快 2.8 倍,且支持 24GB 显存内的 128K 上下文。项目强调”本地 AI 应是默认选择,而非特权”。
🔗 来源:GitHub | HN 150▲
产品发布
OpenAI Codex 推出 Chronicle 功能:屏幕录制构建上下文记忆库
OpenAI 为 Codex 应用推出 Chronicle 功能,可在后台录制用户屏幕并由智能体整理为 Markdown 摘要保存在本地,后续任务无需用户重复说明项目上下文。录制文件 6 小时后自动删除。目前以预览版向 macOS ChatGPT Pro 用户开放(欧盟、英国除外)。OpenAI 提醒该功能会快速消耗调用额度、存在提示词注入风险,且记忆内容在本地未加密存储。
🔗 来源:IT之家
谷歌发布 A2UI 0.9:为 AI 智能体订立生成式 UI 设计标准
谷歌推出 A2UI 0.9 标准,允许 AI 智能体构建和调用用户界面元素。提供共享 Web 核心库、官方 React 渲染器,并支持 Flutter、Lit、Angular 等框架。全新 Agent SDK 支持通过 Python 安装,未来还将推出 Go 和 Kotlin 版本。目前已支持 AG2、A2A 1.0 等集成方案,为智能体时代的 UI 层提供标准化基础设施。
🔗 来源:IT之家
中兴路由器首款 Co-Claw 功能公测:路由器的”龙虾”来了
中兴智慧家庭在问天 BE7200 Pro+ 路由器上推出 Co-Claw 功能公测——这是首款嵌入路由器的 OpenClaw 类 AI 智能体。支持通过微信对话查询/修改 WiFi 配置、查看网络状态、设置家长控制、优化 Wi-Fi 环境等。首批名额限 99 位,需添加”中兴小智”微信好友。
🔗 来源:IT之家
大厂动态
🔥 Sergey Brin 内部备忘录:Google 必须追赶 Anthropic 的 AI 编程 Agent
据 The Information 报道,Google 联合创始人 Sergey Brin 向 DeepMind 员工发出内部备忘录,称”每一位 Gemini 工程师都必须被强制使用内部 Agent 完成复杂多步骤任务”。Brin 认为 Anthropic 的工具在 AI 编程竞赛中处于领先地位,追赶它们是迈向 AI 自我进化的关键一步。这一罕见表态显示 Google 内部对 Agent 竞赛的紧迫感。
🔗 来源:The Verge
Atlassian 默认开启数据收集用于训练 AI,引发用户反弹
Atlassian 被曝默认开启用户数据收集以训练 AI 功能,未经用户显式同意。消息在 HN 引发强烈讨论(476 分、111 评论),用户批评此举违反数据隐私原则,尤其对企业客户而言,Jira/Confluence 中包含大量敏感项目信息。
🔗 来源:HN 476▲
OpenAI 广告合作伙伴开始售卖基于”提示词相关性”的 ChatGPT 广告位
据 Adweek 独家报道,DSP 平台 StackAdapt 正悄悄向广告主推介 ChatGPT 内的广告投放测试,CPM 低至 15 美元。泄露的内部文档将其定位为捕获用户在 ChatGPT 中进行产品研究和对比时的”发现层”广告。这标志着 OpenAI 正式启动商业化广告体系探索。
🔗 来源:Adweek | HN 119▲
活动与行业
🔥 Deezer:每日上传歌曲中 44% 为 AI 生成,日均 7.5 万首
法国流媒体平台 Deezer 公布惊人数据:AI 生成曲目现已占每日新上传量的 44%,日均接近 7.5 万首、月超 200 万首。但 AI 音乐仅占总播放量的 1-3%,且其中 85% 被检测为欺诈流量并取消了收益分成。Deezer 已停止存储 AI 曲目的高清版本。与此同时,上周一首 AI 生成歌曲登顶了美英法加等多国 iTunes 榜首——AI 音乐从”边缘现象”走向了行业性议题。
🔗 来源:TechCrunch | HN 269▲
爱奇艺发布”AI 艺人库”后遭多位明星打脸否认授权
爱奇艺在世界大会上宣布包括张若昀、王楚然、于和伟在内的 100+ 艺人入驻”AI 艺人库”,随后多位艺人通过微博公开否认签署过任何 AI 相关授权。爱奇艺随后回应称”入驻仅代表有接洽 AI 影视项目的意愿”,但这一事件暴露了 AI 影视创作中肖像权与知情同意的灰色地带。

🔗 来源:IT之家
荣耀机器人”闪电”打破人类半马世界纪录,包揽前三
荣耀自研人形机器人”闪电”在 2026 北京亦庄人形机器人半程马拉松中以 50 分 26 秒夺冠,超越人类男子半马世界纪录,并包揽赛事前三名。据研发工程师透露,机器人仅研发半年。这一成绩展示了国内具身智能在自主导航、抗摔、地形适应等方面的工程化突破。
🔗 来源:IT之家
大佬言论
Sergey Brin(Google 联合创始人)
“每一位 Gemini 工程师都必须被强制使用内部 Agent 完成复杂多步骤任务”——Anthropic 的工具正引领 AI 编程竞赛,追赶它们是通向 AI 自我进化的关键路径。
🔗 来源:The Verge / The Information
Bernie Sanders(美国参议员)
“如果不及管控,十年内’制造业就业的概念将不复存在’。”向科技寡头喊话”滚蛋”,推动数据中心建设暂停法案。
🔗 来源:The Verge
Deezer CEO Alexis Lanternier
面对每日 7.5 万首 AI 音乐涌入平台的现实,呼吁全行业共同采取措施,保护艺术家权益并提升透明度。Deezer 的技术和主动措施已证明”将 AI 相关欺诈和收益稀释降到最低是可能的”。
🔗 来源:TechCrunch
GitHub 热门项目
-
Megakernel — 单次 CUDA dispatch 跑完 Qwen3.5-0.8B 全部 24 层,RTX 3090 上 1.87 tok/J,能效比匹配 Apple 最新芯片
-
DFlash+DDTree — 首个 GGUF 移植的推测解码引擎,RTX 3090 上 Qwen3.5-27B 达 207 tok/s,24GB 显存内支持 128K 上下文
-
项目理念:本地 AI 应该是默认选择而非特权
🔗 来源:GitHub
-
因第三方推理服务在参数设置、量化误差等环节常引入偏差导致基准得分虚高或虚低,KVV 提供 6 项关键基准测试(OCRBench、MMMU Pro、AIME2025、K2VV ToolCall 等)
-
帮助开发者验证推理提供商的精度,已与 vLLM/SGLang/KTransformers 社区合作修复上游问题
🔗 来源:GitHub
-
在 1MHz 的 Commodore 64 上运行真正的 Transformer 模型。作为对 Transformer 架构极限压缩的技术探索,在 HN 收获 56 分热度
🔗 来源:GitHub
每日 Paper 精选
🧠 ASMR-Bench:审计 ML 研究中的蓄意破坏行为
🔗 论文链接:arXiv:2604.16286
🔬 核心创新
-
构建了 9 个 ML 研究代码库的”破坏变体”,修改超参数、训练数据或评估代码,使实验结果产生质的偏差,但保留论文描述的高层方法论不变
-
同时评测前沿 LLM 和 LLM 辅助的人类审计者的检测能力
-
最佳表现为 Gemini 3.1 Pro 的 AUROC 0.77 和 42% 的 top-1 修复率——说明即使最强模型也难以可靠检测精心伪装的代码篡改
-
还测试了 LLM 作为红队攻击者的效果:LLM 生成的破坏弱于人工,但仍能骗过同等能力的 LLM 审计者
🌈 通俗解读
想象你是一个代码审查员,有人在科研代码里偷偷改了几个数字让实验看起来成功了——这个基准测试就是专门衡量”你(或 AI)能不能抓住这种学术造假”的。目前连最强 AI 也只有不到一半的检出率。
❓ 为什么值得关注
随着 AI 越来越多地自主执行科学研究,如何防止不对齐的 AI 系统在研究中植入微妙的误导性缺陷成为关键安全问题。这个基准为 AI 安全治理领域的”可审计性”研究提供了重要基础设施。
👆 觉得有用?点赞 + 在看 支持一下 👆
每天更新,陪你追踪 AI 最前沿 🚀
想看更多精彩内容?
扫描下方二维码加入群聊

@本文为AI洞察局原创内容
未经授权, 禁止转载
进群、转载或商务合作联系后台
— 完 —

