 夜雨聆风
夜雨聆风





【AI前沿】过去 24 小时 AI 圈最值得看的,不是又多了几个新模型,而是两条战线一起打响了
过去 24 小时 AI 圈最值得看的,不是又多了几个新模型,而是两条战线一起打响了
过去 24 小时,AI 圈表面上看有三条更新:
-
Qwen 3.6-Max-Preview 发布 -
Kimi K 2.6 发布 -
Claude 在 Cowork 里上线 live artifacts
如果把它们分别当作资讯播报来看,当然都成立。
但放在一起看,真正值得写的不是“谁又发了什么”,而是更深一层的变化:「国产模型正在往 Claude Opus、Codex、GPT-5.4 的核心腹地逼近,而 Anthropic 仍然在把模型能力继续产品化,直接去撞 SaaS 和传统软件工作流。」
今天的大模型竞争,已经越来越不像聊天机器人比赛,而更像两条战线同时推进:
-
「模型层战线」:谁更能做 agentic coding,谁更能长时间执行任务,谁更能接住多文件工程、工具调用和复杂开发流程。 -
「产品层战线」:谁能把模型变成可直接使用的工作系统,吃掉原本由软件席位费支撑的价值层。
先看这张图,就能明白为什么这三条更新不能分开看:
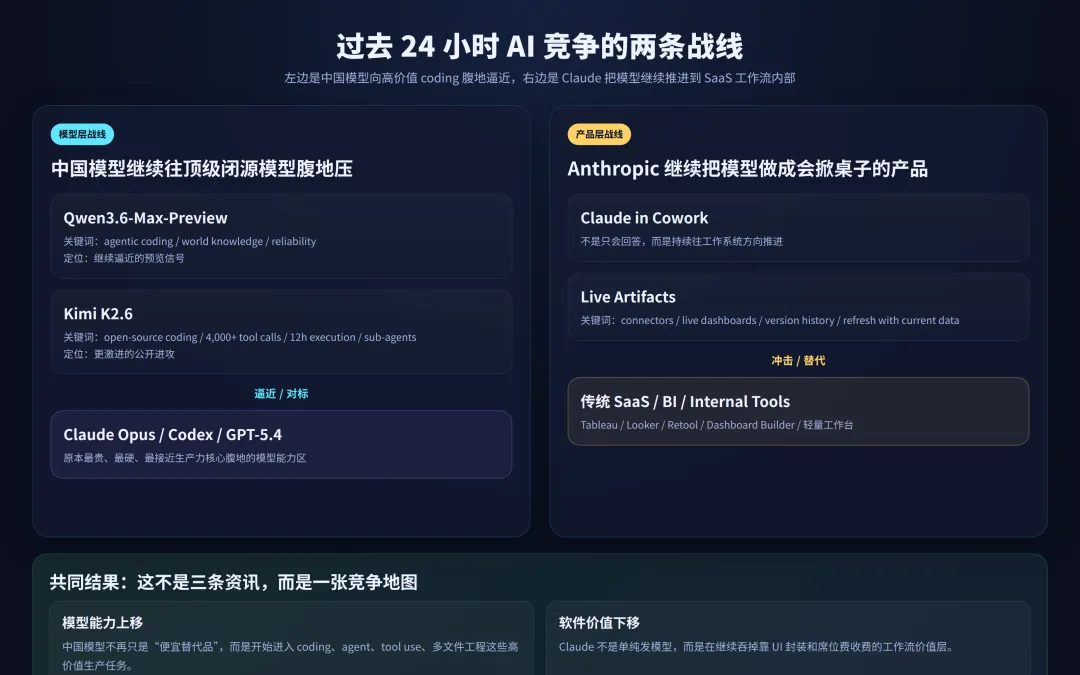
这三条更新,刚好把这两件事同时照亮了。
一、Qwen 3.6-Max-Preview:这不是普通升级,而是继续往 agentic coding 逼近
先看 Qwen 3.6-Max-Preview。
Tongyi Lab 官方帖里给出的关键词很直接:「agentic coding、stronger world knowledge、real-world reliability」。

这次最值得注意的,不是它有没有把自己说成万能模型,而是它把重心明确放在了「开发者工作流上」。
这很关键。因为今天高价值的大模型竞争,早就不是“谁回答更顺”这么简单,而是谁能在复杂任务里持续稳定地跑下去。
Tongyi Lab 还补了一张 benchmark 图。
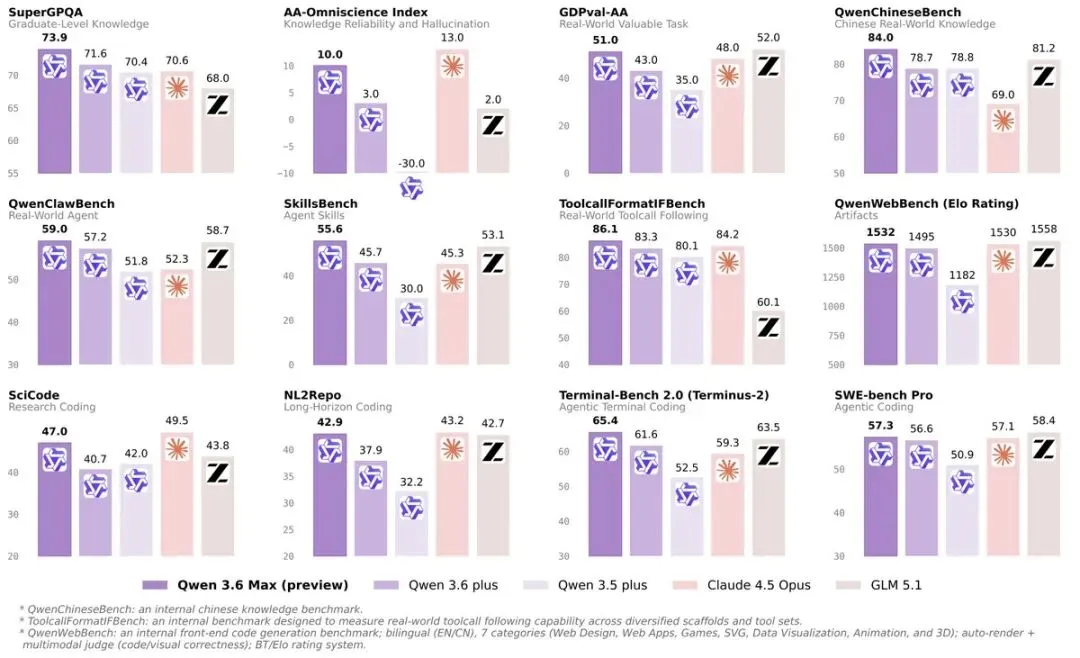
这张图当然有信息量,但 Qwen 这次真正传递出来的信号,不只是分数,而是姿态:「Qwen 现在盯着的,是高强度 coding 和 agent 任务,不是普通聊天榜单。」
不过,Qwen 这次也明确写了一个词:「Preview」。
这意味着它更像一个正在逼近的强信号,而不是已经完成市场验证的终局答案。
网上比较有价值的一条评论来自 @mylifcc:
❝
agentic coding gains look real, but the gap shows in multi-file, long-horizon tasks — ran a multi-agent harness in production for months, and model consistency under pressure mattered way more than raw benchmark numbers. max-preview might actually shift that
❞
这条评论比单纯夸 benchmark 有价值得多。因为它点出了真正的生产问题:「多文件、长时执行、高压条件下的一致性」,往往比单次 benchmark 分数更重要。
另一条来自 @sebuzdugan 的保留意见也值得写进去:
❝
preview is nice but without clear benchmarks against gpt 4 o this means little
❞
这话虽然有点硬,但意思没错:如果缺少更直观的对比口径,外界很难直接判断它离 Opus、Codex、GPT-5.4 还有多远。
所以,Qwen 3.6-Max-Preview 给我的判断不是“已经赢了”,而是:「阿里已经把火力更明确地压到高强度 coding 和 agent 工作流上了。」
它不再只是一个中文世界里很强的通用模型,而是在主动往全球最贵、最硬的那块生产力区域里挤。
二、Kimi K 2.6:比起“逼近”,它更像一次公开进攻
如果说 Qwen 更像一个继续逼近的信号,那 Kimi K 2.6 的气势要更猛一些。
Kimi 官方发布几乎没有绕弯,直接把自己放进 「Advancing Open-Source Coding」 这个框架里。

它给出的叙事也很完整:
-
长时 coding,4,000+ tool calls,连续执行 12 小时以上 -
motion-rich frontend -
300 个并行 sub-agents -
proactive agents -
研究预览阶段的 Claw Groups
这已经不是单点能力升级了,而是在把“编码模型”往完整的 agent runtime 推。
这里最危险的地方在于,Kimi 不只是说自己代码能力更强,而是在强调:「长期执行、工具链编排、前端生成、多 agent 协作」,它都要往前拿。
这意味着它抢的已经不是单个模型的位置,而是在碰整套 coding product stack。
外部讨论也很能说明这点。
比如 Unsloth AI 很快就表示,他们在做 Kimi-K 2.6 Dynamic GGUF,好让更多人本地运行:
❝
We’re working on Kimi-K 2.6 Dynamic GGUFs so folks can run it locally…
❞
这类反馈很关键。因为只有当社区觉得一个模型「值得部署、值得适配、值得进生产环境」时,第一反应才会是去做本地化和量化。
另一类讨论,则直接把它拉进和顶级闭源模型的对比里。@tonbistudio 的说法很激进:
❝
Impressive model! I tested it out in Hermes Agent with 2 challenging tasks, and it really lived up to the SOTA label (even beating Opus 4.7 easily in one showdown).
❞
这还不能直接上升成行业结论,但它至少说明了一件事:「市场已经开始认真把国产模型放进“能不能打 Opus”这个问题里了。」
还有一层更明显的情绪,是“更开放的高能力模型正在冲击原来的高价闭源格局”。比如 @JackColbySEO 这句虽然带点夸张,但很抓市场情绪:
❝
OpenAI and Anthropic watching Chinese labs open source everything they charge $200/month for
❞
这类情绪化表达,不足以当结论,但能说明今天海外用户对国产模型的第一感受,已经逐渐变成了:「高能力 + 更开放 + 价格压力」。
Kimi 这边还有一个很适合放进正文的实战素材:它已经迅速被接进 agent 框架里跑实测了。
这种素材比单纯 benchmark 更有说服力,因为它说明 Kimi 的传播已经不只是“看分数”,而是进入“拿去跑真实 agent 框架”的阶段。
再看另一条高互动回复,@SahilPanhotra 直接发了一张图,配文是:
❝
waiting for composer 3 by cursor now
❞

这张图本身不是技术论据,但它很适合说明 Kimi K 2.6 在外部产品生态里引发的情绪联想:当一个开源 coding 模型突然把前端、agent、长时执行都抬上来时,大家会自然去联想到 Cursor、Composer、Codex 这类现有产品的压力。
三、但说国产模型已经全面平替 Opus、Codex、GPT-5.4,还是太早
说到这里,很容易顺手写成一句爽文式结论:国产产模型已经全面崛起,可以直接平替 Claude Opus、Codex、GPT-5.4。
我不认同这么写。
至少从这 24 小时拿到的材料看,这个判断还是太满了。
更准确的说法是:「在 coding、frontend、tool use、agent workflow 的一些关键任务上,替代已经开始发生,但“全面平替”还没有发生。」
原因很简单。
第一,Qwen 3.6-Max-Preview 自己就写了 preview,它不是最终稳定版。
第二,即便 Kimi K 2.6 的反馈很强,市场也不是一边倒。比如 @XCSme 就明确表示,它只是比 Kimi 2.5 好一点,但依然不如 GLM 5。这说明即便在国产模型内部,竞争也还在快速拉扯。
第三,闭源顶级模型真正难替代的,不只是 benchmark 顶点,而是「长时稳定性、复杂项目一致性、边界条件下的容错,以及和产品层整合后的整体体验」。
也就是说,今天更负责的判断不是“替代已经完成”,而是:
「国产模型已经进入高价值替代区间,正在把原本属于 Claude / Codex / GPT-5.4 的部分任务,实打实切下来。」
这已经够重了,不需要靠夸张来抬高结论。
四、Claude live artifacts:Anthropic 依然最擅长把模型能力变成“行业冲击”
如果说 Qwen 和 Kimi 代表的是模型层的进攻,那 Claude 这次 live artifacts 更像产品层的精准打击。
Claude 官方的说法很克制:在 Cowork 里,Claude 现在可以构建 live artifacts,做出连接 app 和文件的 dashboard、tracker,并且随时打开都能用当前数据刷新。
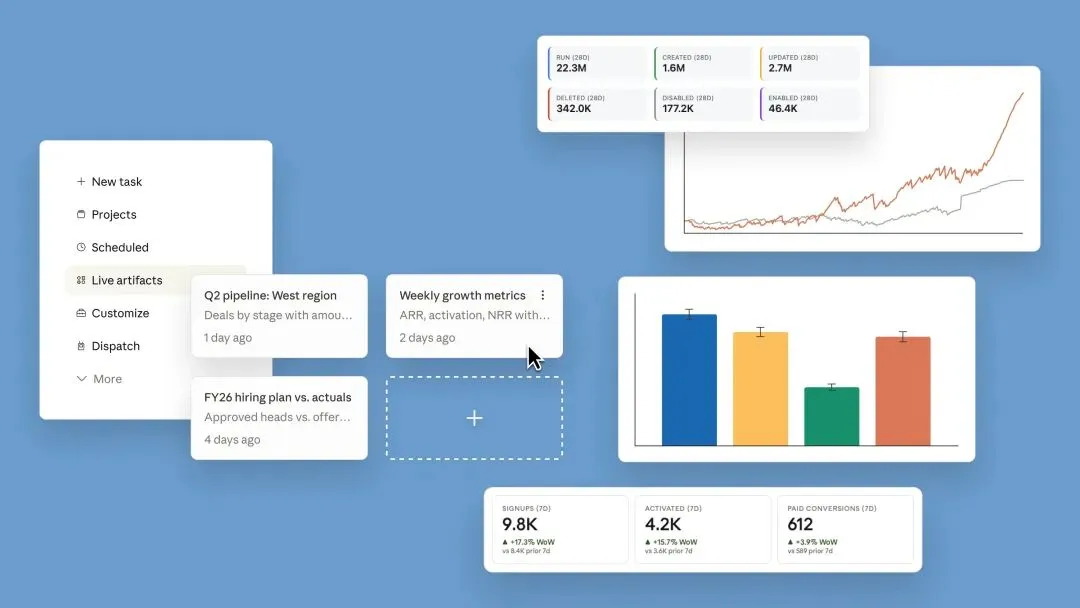
官方随后还补了一条串文,说这些东西会保存在新的 Live Artifacts tab 里,并且带 version history。
这几个词连起来,意思就完全不一样了。
它不是一次性生成个 demo,也不是帮你画个静态 dashboard,而是在把 artifacts 变成一种「可连接数据、可持续刷新、可回溯版本的活对象」。
这一步会直接打到哪里?
就是 BI、internal tools、dashboard builder、轻量工作台这一类长期靠“把复杂数据工作包装成一个可视化工具”来卖席位费的软件。
网上几条更像从业者判断的评论,比情绪化 meme 更值得留。
比如 @iamsubha44 的这条:
❝
Claude’s new live artifacts in Cowork finally solve the ‘build once, then manually update forever’ problem. Connected to your actual data sources and versioned over time – this is how you make AI-built tools that actually stick around and stay useful.
❞
这条评论很准。Claude 这次真正解决的问题,不是“会不会生成”,而是「生成出来的东西能不能继续活着、持续更新、被反复使用。」
@AiwithZoaina 也点到了另一个关键点:
❝
Live Artifacts that connect to actual data sources and persist with version history is exactly what was missing. Would love to see deeper team sharing/multiplayer support next…
❞
这条评论很适合用来平衡文章。因为它一方面承认这次更新很强,另一方面也指出它还没完全吃掉团队协作层。
还有 @travasites 这条,也很像真正会用这类产品的人写出来的判断:
❝
Real time dashboards without manual refresh or custom ETL is a huge workflow win. Does it support custom data sources via API, or only pre connected apps?
❞
这不是喊“某行业死了”,而是在追问一个非常实际的问题:「连接器边界在哪里,开放度够不够,能不能接更复杂的真实系统。」
这类问题,才是真正决定它能吃掉多少 SaaS 价值的地方。
五、能否冲击行业?
这次更新对 BI 行业的冲击可以说得更具体。
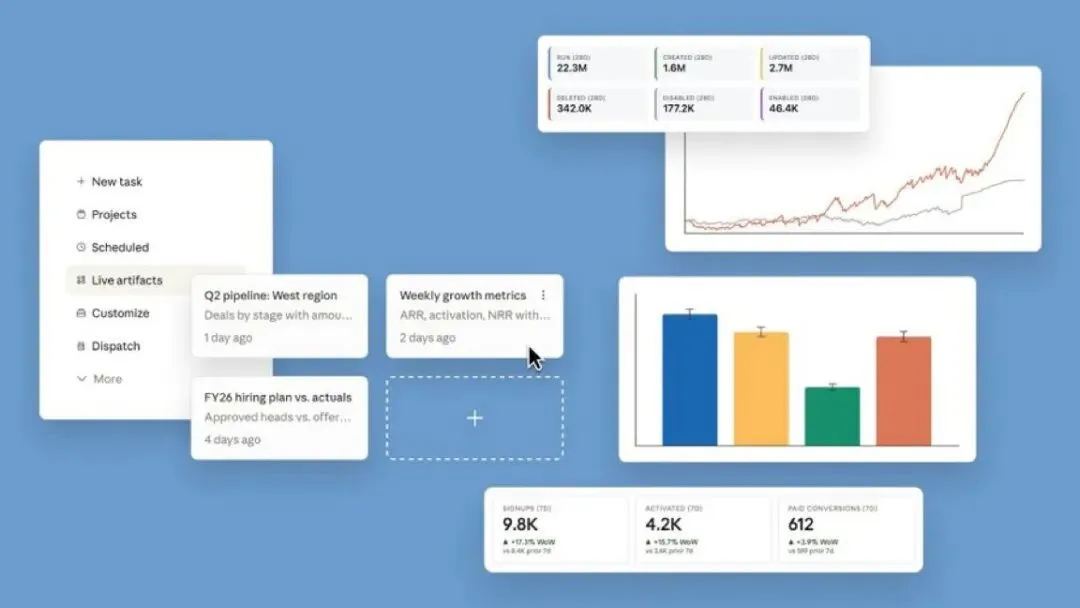
有网友判断:「过去十年大量 SaaS 的生意,本质上是在卖“把复杂工作包成一个好看的 UI,然后按席位收费”。而现在,prompt 加 connector,已经开始吃掉中间那层 UI 封装价值。」
这句话我基本同意。
但也要修一下力度。
不是 BI 行业明天就没了,也不是 Tableau、Looker、Retool 立刻归零。数据治理、指标口径、权限管理、合规、跨团队协同,这些真正难的层面,Claude 这次并没有一键解决。
但说它没有冲击,也是假话。
它先吃掉的,很可能就是那批“为了做一个常用 dashboard 或 tracker,不得不搭一堆中间工具和手工流程”的工作。
也就是过去最容易被 SaaS 席位费收割的那一段。
六、网上的情绪已经说明,大家怕的不是单个功能,而是 Anthropic 继续按行业掀桌子
Claude 这条下面的评论区里,专业判断和 meme 已经混在一起了。
有人说 Tableau 和 Power BI 现在成了昂贵但没必要的选项。有人说,如果你的工作就是不停更新 dashboard,可能该去学 prompting 了。还有人直接说,又一个 startup category 要没了。
还有一张更典型的情绪图,把 Claude 直接理解成“正在往完整 AI startup starter agent 发展”:

这些图本身不是硬证据,但它们很适合证明舆论温度。
大家怕的不是 Claude 又多了一个小功能,而是 「Anthropic 总能把模型能力做成一个看起来会直接吞掉现有软件品类的东西。」
这和国产模型的冲击方式不完全一样。
国产模型这边,市场更在乎的是:能力是不是已经足够强,价格是不是更低,生态是不是更开放。
Anthropic 这边,市场更在乎的是:你这次又打到了哪个行业的核心工作流。
七、这 24 小时真正的主线,是“模型能力上移”和“软件价值下移”同时发生
如果把这篇文章压成一句判断,我会写成这样:
「国产模型正在把顶级模型的能力门槛往下打,Claude 则在把传统软件的价值边界往下拆。」
前者会让 Opus、Codex、GPT-5.4 这类高价能力越来越难维持神圣感。后者会让一批依赖 UI 封装和席位费的软件,越来越难证明自己还有多少不可替代性。
所以,今天真正值得注意的不是“又有三个新功能了”,而是两条更深的变化:
-
「第一,国产模型已经进入 coding 主战场,不再是外围变量,而是正面选手。」 -
「第二,大模型应用层的竞争,已经越来越像对 SaaS 垂直品类的逐层拆解。」
写在最后
回到最开始那个问题。
国产产模型崛起了吗?
我的答案是,已经不是“会不会崛起”的问题,而是:「它们已经开始在部分高价值任务上正面替代顶级闭源模型,只是还没到全面接管的阶段。」
能不能平替 Claude Opus、Codex、GPT-5.4?
如果你问的是全部能力、全部场景、全部体验,答案还是不能轻易说“能”。
但如果你问的是 coding、agent workflow、前端生成、多工具协作这些越来越贵的生产任务,那答案已经开始变成:「很多地方,能了,而且会越来越能。」
而 Claude 这边,问题甚至不是“它强不强”,而是它几乎每隔几天都会给传统软件行业补一刀。
过去 24 小时,真正值得警惕的不是某一个模型参数更高了。
而是两件事已经同时发生:
-
一边是国产模型开始把最贵的能力做得更开放。 -
另一边是 Anthropic 继续把模型做成能掀行业桌子的产品。
这才是今天 AI 圈真正的新鲜事。
「更多 AI 前沿技术与设计灵感,欢迎关注「设计小站」公众号(ID:sjxz00),一起探索科技与设计的融合创新。」