 夜雨聆风
夜雨聆风





OpenAI发布第一个生命科学大模型:GPT-Rosalind!这个名字来自生物学史上最大的遗憾之一
背景
从靶点发现到拿到 FDA 批准,平均要走 10 到 15 年,耗资 26 亿美元,约 90% 的临床试验以失败告终。这不完全是因为科学难,也因为研究流程本身太过繁重:海量文献、各自为政的数据库、不断更新的假说……每向前一步,研究者都得在信息的泥泞里跋涉。
AI 已在这个领域试水多年,AlphaFold 预测蛋白质结构,大语言模型被用于文献综述与序列解读。但多数用法是临时拼凑的——通用模型加几条提示词,总差那么一口气。2026年4月17日,OpenAI 发布 GPT-Rosalind,宣称这是专门为生命科学研究工作流而建的第一个前沿推理模型。
那个带着遗憾的名字
罗莎琳德·富兰克林(Rosalind Franklin)是英国晶体学家与 X 射线衍射专家。1952年,她拍摄的”51号照片”精确揭示了 DNA 分子的螺旋结构,Watson 和 Crick 在未经她同意的情况下看到了这张照片,并据此建立了 DNA 双螺旋模型。1962年,Watson、Crick 和 Wilkins 获得诺贝尔奖;富兰克林则在1958年因卵巢癌去世,年仅37岁,从未获得应有的承认。
这是一个带着致敬也带着遗憾的名字——一个研究者,用一生的严谨换来了她所在时代无法给予的认可;一个模型,试图用算力接过她未竟的事业。只是,X 和 Reddit 上立刻有人指出了讽刺:用一个研究成果被封锁的科学家命名,却把这个模型锁起来只给特定机构用——名字里的遗憾,在现实里重演了一遍。
为科研而生
GPT-Rosalind 不是在通用大模型上贴生物标签,而是专门针对生命科学研究工作流进行了优化训练。目标很具体:跨文献与数据库的多跳推理、从基因序列解读到功能预测、设计分子克隆方案、根据现有数据生成下一步假说——这些任务都要求模型不只懂背景知识,还能在多个步骤之间保持连贯的科学推理。
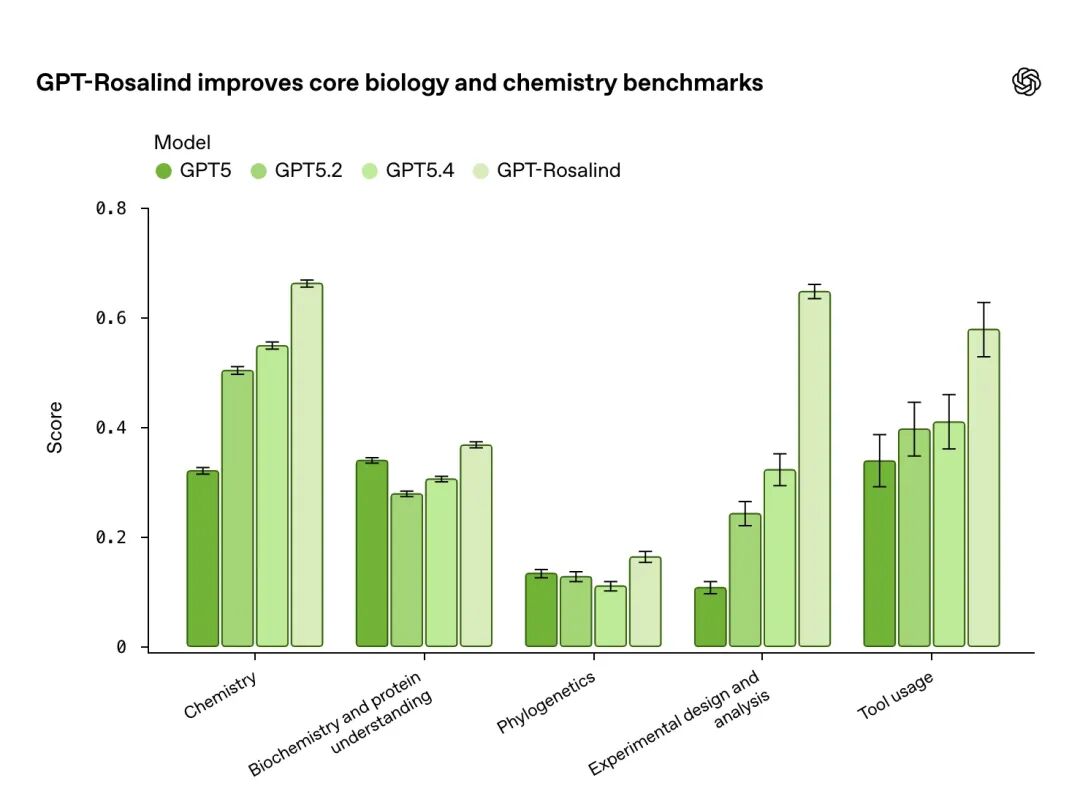
关于训练细节官方未公布,但从评测结果可以推断大概经历了三个层面的打磨。领域语料的专项训练:化学反应机制、蛋白质突变效应、基因组注释这类内容在通用互联网语料里占比极低,需要在专业文献和数据库条目上做深度预训练或微调。工具使用的专项优化:GPT-Rosalind 在多步骤工具调用上明显优于 GPT-5.4,说明它被专门训练了”何时用哪个工具、如何把多步输出拼成连贯推理链”的能力。任务对齐:文献综述与实验设计是截然不同的任务,针对不同科研任务类型的对齐训练,大概是它在基准测试上拉开差距的核心原因。
与之对比的是另一种思路:主流大模型加上 skills。这正是 OpenAI 同期开源的 Life Sciences Research Plugin 所走的路——不特调模型,直接给通用模型装上工具接口。门槛低、灵活性强。两种路线并不对立,更像是同一个系统的两个层次:开源工具层面向普通研究者,专项模型层面向高要求的企业科研环境。
编者注:其实我感觉通用基模加上技能拓展的思路更有生命力。另外,生命科学领域的数据类型有可能并不适合完全在GPT架构下直接训练,极高的维度、大量的噪音和稀疏的标签,会让模型训练非常困难,能够提升的科研任务类型可能也有限,但工作流提效和推理优化应该是没问题的。
评测成绩
OpenAI 公布了 GPT-Rosalind 在几个基准测试上的表现。
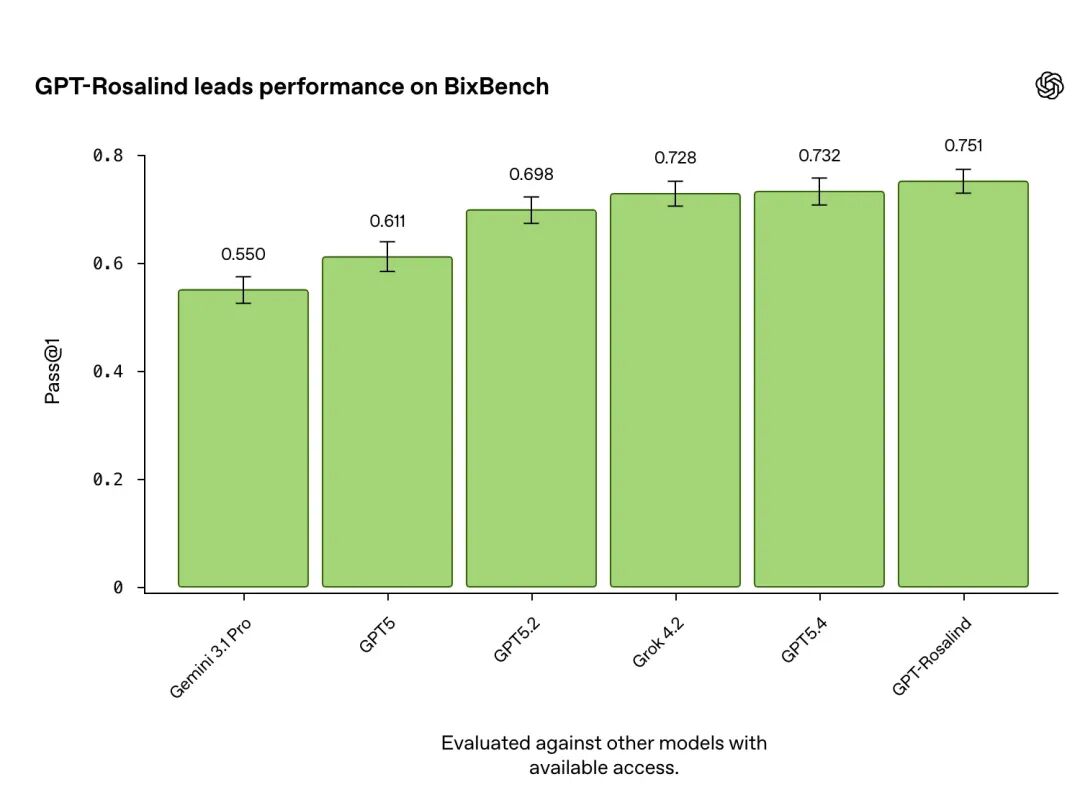
BixBench 是一个专门围绕真实世界生物信息学任务设计的基准,测的是模型在数据分析、序列处理、基因组工作流上的能力。GPT-Rosalind 在已公布评分的模型中取得了领先成绩。
LABBench2 覆盖更广泛的科研任务,包括文献检索、数据库访问、序列操作和实验方案设计。GPT-Rosalind 在11项任务中的6项超过了 GPT-5.4,其中提升最显著的是 CloningQA——这是一项要求端到端设计 DNA 与酶试剂的分子克隆协议的任务,直接对应实验室的真实操作。
最有意思的是与 Dyno Therapeutics(一家专注 AI 设计基因疗法的公司)的合作评测:用未发表、未污染的 RNA 序列设计了两项任务,参照系是57位人类 AI-bio 领域专家的历史成绩。GPT-Rosalind 在序列功能预测上最优10次提交排在第95百分位以上,序列生成排在约第84百分位。第95百分位意味着在这项特定任务上超越了几乎所有人类专家——不是用年,而是用分钟完成的。这不等于”AI 能治愈癌症”,但在某些边界清晰的科研子任务上,AI 超越人类专家集体表现这件事,已经可以被量化地证明了。
开源的那50个科研技能
GPT-Rosalind 对多数人来说需要资格审查才能用,但 OpenAI 同期在 GitHub 上开源了 Life Sciences Research Plugin,任何人都可以拿来用。
这是一个模块化工具集合,目前包含 50 余个科研技能,设计思路是让模型先理解研究问题、规范化实体(基因、蛋白质、疾病、变体等),再路由到正确的数据库完成查询,各技能既可单独使用也可组合成多步推理链。
按研究方向大致分为六族:人类遗传学与变异证据(OpenTargets、GWAS Catalog、ClinVar、gnomAD、FinnGen、UK Biobank 等15个来源);表达与功能基因组学(Human Protein Atlas、CellxGene、ENCODE、RNAcentral);蛋白质结构与通路(AlphaFold、RCSB PDB、UniProt、STRING、Reactome);化学与药理学(ChEMBL、PubChem、BindingDB、PharmGKB、HMDB);临床与癌症证据(ClinicalTrials.gov、cBioPortal、CIViC);文献与公共数据集(NCBI 全家桶、BioRxiv/MedRxiv、PRIDE、ProteomeXchange)。此外还有一个 research-router-skill 作为默认入口,负责理解任务、规范化实体,并选择最小可行的技能集合协调返回。
这些技能能覆盖的场景,比想象的要广。
-
• 想调研某个基因是否与某种疾病相关,它可以帮你横跨 GWAS、eQTL、PheWAS 三条证据链,整合 FinnGen 和 UK Biobank 的人群数据,最后给出一份综合背景报告——以前这件事可能要分散在十几个网站手工拼凑,现在几句话可以触发自动完成。 -
• 想在写论文前系统综述某个靶点的药物研发进展,它可以帮你同时查 PubMed 文献、ChEMBL 活性数据、ClinicalTrials 的临床试验状态,并归纳出目前到了哪个阶段、主要竞争者是谁、现有分子有什么局限。 -
• 想从一个蛋白质的序列出发了解它的功能、结构、互作伙伴、相关通路,AlphaFold + PDB + STRING + Reactome 的联动可以在一次对话里完成。这类”跨库多跳”的查询,正是人工操作最耗时也最容易遗漏的部分。
这个插件不依赖 GPT-Rosalind,配合任何主流模型都能跑。如果你现在就想在生命科学研究中用上 AI,并不需要等待资格审批——调用 GPT-5.4 加上这套技能,已经可以覆盖很多日常研究辅助需求。
预告: 麦伴科研(maltsci.com)正在筹备 Rosalind 特别版科研智能体,作为第一个云端智能体”生医数据专家”之后的第二款Agent产品。面向广大科研工作者,无需资格审批、无需本地配置,打开浏览器就能用上一线主流大模型 + 这50个开源科研技能的完整组合。预计效果优于原生 GPT-5.4,能达到满血 GPT-Rosalind + skills 约90%的水准。如果你不想排队等 OpenAI 的资格审查,欢迎关注我们上线通知。
围观者争议四起
X 上主要是兴奋。Kevin Weil 说”超级兴奋”,围观者充斥感叹号和”快给我访问权限”。有人算账:全球药物发现市场 2030 年预计超 1200 亿美元,单个药物从发现到批准平均耗资 26 亿;如果能在最早期发现环节显著提升成功率,撬动的价值不可估量。还有人说:本质上是给研究者配了一个读过所有相关论文、了解所有数据库的合作者,这个复利效应很难高估。
Reddit 则更复杂。r/singularity 第一条高赞评论直接点名:” 用一个研究成果被盗用封锁的女科学家命名,然后把这个模型锁起来——这是一种选择。” 有人补刀:”OpenAI,如果你不想开源,就改个名字。”
关于突破潜力,Reddit 更有分寸。有人写得颇有逻辑:生物学的瓶颈不是智力,是实验——细胞需要时间生长,动物模型是糟糕的疾病代理,生物系统不是设计出来的,天然对理解充满敌意。结论是:在通用机器人普及和实验室自动化成本大幅下降之前,AI 攻克疾病的大突破还要等。反驳的人则祭出开尔文勋爵1895年的名言——”比空气重的飞行器不可能存在”——然后说:等着瞧。
还有关于安全的担忧:生物模型越来越强,de novo 病原体设计的门槛就越来越低,这正是 OpenAI 实施”可信访问”机制的真实原因之一。这些声音勾勒出 GPT-Rosalind 所处的真实张力:兴奋与谨慎、开放与管控、命名的致敬与现实的门槛。
结语
GPT-Rosalind 的意义,不只在于它在某几项基准测试上赢了,更在于它代表的方向:专项训练、深度工具集成与领域对齐,为生命科学打造一个真正够用的 AI 合作者。AlphaFold 重塑了结构生物学,现在 OpenAI 试图覆盖整条研究流程——从文献综述到假说生成再到实验设计,一路打通 (BTW,也是我们麦伴科研的愿景)。
当然,生物学里有太多东西是模型学不到的。每次实验失败的原因,往往既不在文献里也不在数据库里,而在那个每天泡在实验室里修仪器的博士生的直觉经验里。最可能的近期图景是:AI 不是取代实验,而是减少做错误实验的概率——每一个假说被更严格地验证,每一次实验前有更好的方案设计,这些叠加起来,才产生真正的复利。
Rosalind Franklin 用一生证明了严谨的数据能战胜时代的偏见,只是她没能亲眼看到。今天用她名字命名的模型,能否让更多研究者在有生之年等到那个答案——我们还不知道。
参考资料
-
• Introducing GPT-Rosalind for life sciences research | OpenAI -
• Life Sciences Research Plugin | GitHub -
• Reddit r/singularity 讨论 -
• Kevin Weil on X