 夜雨聆风
夜雨聆风





work_mem:AI 帮你算,你别乱猜
导读
这是《AI 助力 PostgreSQL 优化 20 讲》第 6 讲,内存与 I/O 调优小系列(06-08 讲)的第一篇。 上一讲讲完索引设计,这一讲进内存调优。work_mem 是最容易被误解的 PostgreSQL 参数之一——设大了 OOM,设小了查询慢,两头都是坑。本讲解释它是什么、陷阱在哪、以及如何用 AI 辅助算出合理值。适合有 PostgreSQL 使用经验的研发和 DBA。
开篇:work_mem=2MB,怎么还是 OOM 了
生产事故记录(来源:mydbanotebook.org):
某集群把 work_mem 设成了 2MB。不是 512MB,是 2MB。然后在高峰期触发了 OOM killer,内存消耗峰值逼近 2TB。
复盘结果:一条 SELECT 语句调用了 PL/pgSQL 函数,函数里做了 COPY,再 JOIN 另一张大表。执行器内存快照显示:
•ExecutorState 上下文:235MB(40 个内存块)
•HashTableContext:340MB(47 个内存块)
•单个 backend 总消耗:557MB
work_mem=2MB,单个 backend 却用了 557MB——参数根本没拦住。原因下面解释。
work_mem 是什么:逐字读懂它
先看官方定义里最关键的一句话:
“a complex query might perform several sort and hash operations at the same time, with each operation generally being allowed to use as much memory as this value specifies”
拆开看:
•per-operation:每个 Sort / Hash 操作各自独立分配,互不干涉
•at the same time:同一查询的多个操作可以同时占用内存
•this value:每个操作的上限是 work_mem,不是所有操作共享一个池
所以 work_mem 不是”数据库的内存配额”,是”每个操作节点的最高许可证”。
理解这个之后,乘法炸弹就很清晰了:
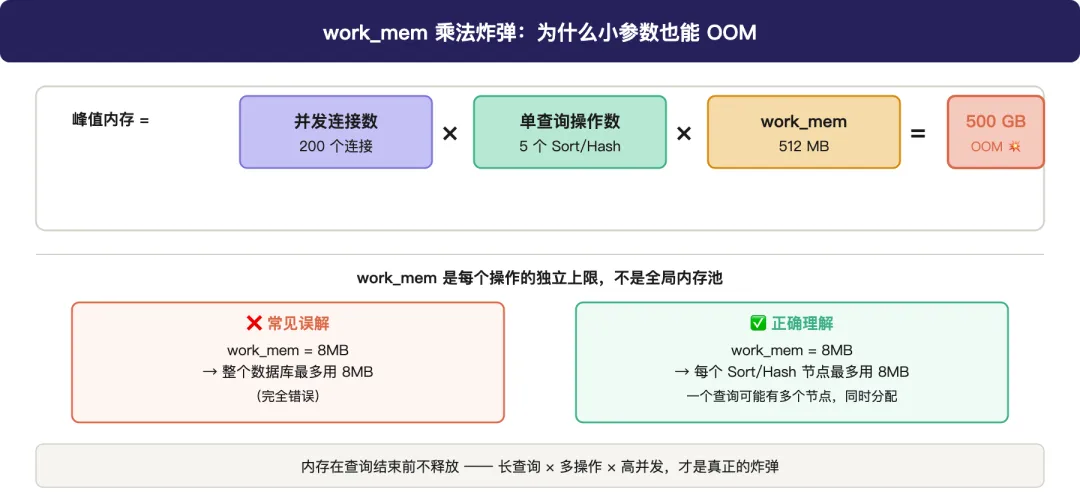
200 个并发连接,每个查询有 5 个 Sort/Hash 节点,work_mem=512MB,理论峰值 = 500GB。没有服务器能顶住这个。
陷阱:内存什么时候释放
回到开头那个案例。work_mem=2MB,为什么还是用了 557MB?
原因在 PostgreSQL 的内存管理机制:所有 Sort/Hash 操作分配的内存,都挂在同一个 ExecutorState 内存上下文下。这个上下文在整个查询结束前不释放。
PostgreSQL 采用”上下文整体释放”的设计——释放速度快,但代价是粒度粗。查询一直跑,内存一直占。如果查询本身出了问题(死循环、超大结果集、函数嵌套),内存会一直累积到 OOM。
这就是为什么 statement_timeout 是 work_mem 的配套安全阀。没有超时保护,一条失控的查询可以把服务器内存耗尽,跟 work_mem 设多少无关。
两种 Spill:Sort 和 Hash Join
数据超出 work_mem 限制时,PostgreSQL 不会报错,而是把数据写到临时文件继续处理——这就是 spill to disk。
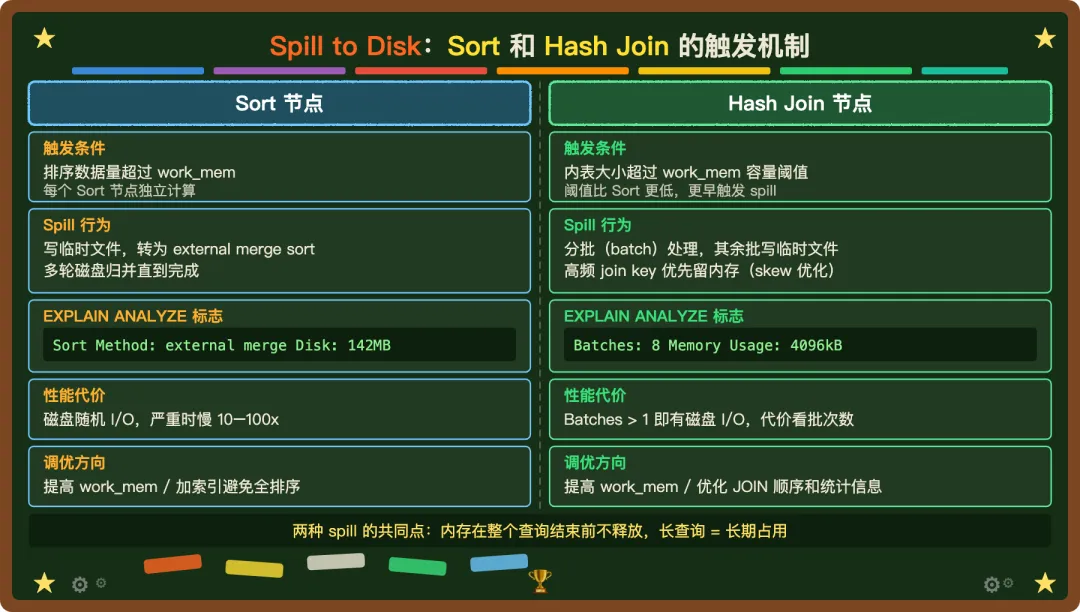
Sort 节点的 spill:排序数据超出 work_mem 时,进入 external merge sort。EXPLAIN ANALYZE 里看到 Sort Method: external merge Disk: 142MB 就是在 spill。
Hash Join 的 spill:触发阈值比 Sort 更早,内表超过一定比例后就开始分批。每批处理一部分数据,剩余写临时文件。Batches: 8 代表分了 8 批,说明在磁盘上走了 7 次 I/O。高频 join key 会优先留在内存(skew 优化),能减少部分磁盘读写,但代替不了足够的 work_mem。
Spill 的代价是磁盘 I/O,不是查询失败,所以很容易被忽视。等到业务反馈”查询变慢了”,临时文件可能已经堆了几十 GB。
发现问题:三个工具
工具一:EXPLAIN (ANALYZE, BUFFERS)
最直接。看两个关键字段:
●●●EXPLAIN (ANALYZE, BUFFERS)SELECT ...;
•Sort 节点:找 Sort Method,external merge Disk: XXX = 在 spill
•Hash 节点:找 Batches,大于 1 = 在 spill
工具二:log_temp_files
●●●-- postgresql.conflog_temp_files = 0 -- 记录所有临时文件(0 = 全部记录,单位 kB)
开启后,每次有临时文件产生,日志里会记录大小。统计高峰期每小时产生多少临时文件、最大的有多大——这是衡量当前 work_mem 够不够的最直接数据。
工具三:pg_log_backend_memory_contexts()(PG14+)
●●●-- 找到目标进程的 PIDSELECT pid, query FROM pg_stat_activity WHERE state = 'active';-- 把该 backend 的内存上下文树写到日志SELECT pg_log_backend_memory_contexts(pid);
日志里会出现类似这样的信息:
●●●ExecutorState: 235 MB in 40 blocksHashTableContext: 340 MB in 47 blocks
这是最细粒度的内存分析工具。遇到内存异常,先用这个定位是哪个操作在吃内存,再决定怎么调。
给 AI 算合理值
知道了乘法炸弹的结构,计算合理值的逻辑就清楚了:
全局保守值 = 安全内存上限 ÷ (峰值连接数 × 单查询最大操作数)
这个计算 AI 能做,但你必须给够上下文。
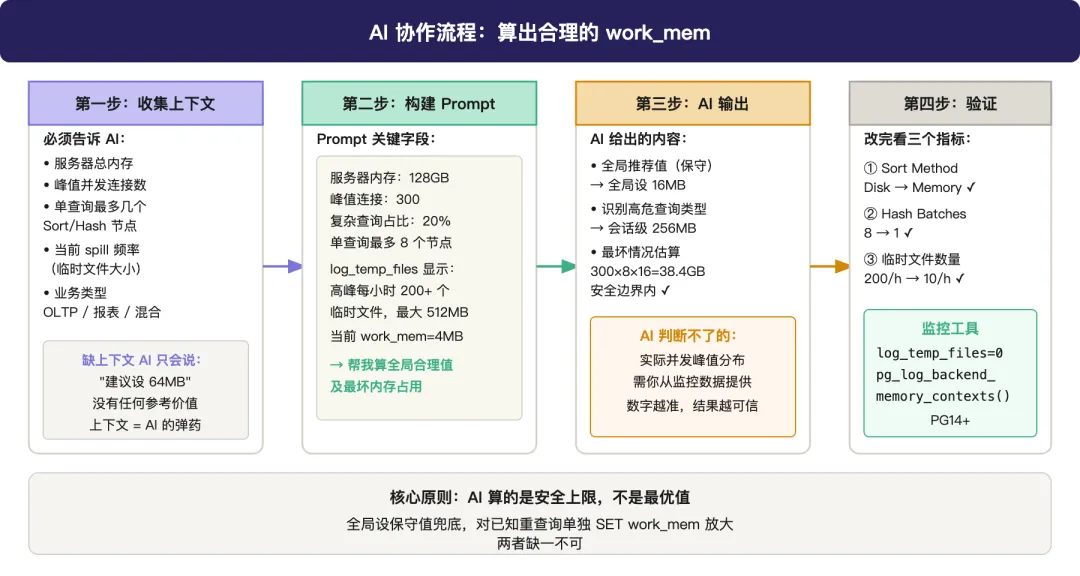
Prompt 模板:
●●●我的 PostgreSQL 集群配置如下:- 服务器内存:128GB,PG 可用内存约 80GB- 峰值并发连接:300(其中约 20% 是复杂查询)- 分析过几条典型慢查询,最多的有 8 个 Sort/Hash 节点- log_temp_files 显示高峰每小时约 200 个临时文件,最大单个 512MB- 当前 work_mem=4MB请帮我:1. 计算合理的全局 work_mem 值2. 估算调整后的最坏情况内存占用3. 建议哪类查询需要单独 SET work_mem 提高,以及建议值
AI 会给你:全局推荐值(通常 8-32MB 区间)、最坏情况内存占用验算、需要单独处理的重查询类型。
AI 判断不了的:实际并发峰值分布。300 个连接里同时跑复杂查询的实际比例,只有你的监控数据说了算。上下文里给的数字越准,AI 的推荐越有参考价值。
两种用法的组合
全局:设保守值
●●●-- postgresql.confwork_mem = 16MB -- 全局保守,防乘法炸弹statement_timeout = '30s' -- 配套安全阀,防失控查询log_temp_files = 0 -- 持续监控 spill
会话级:对重查询放大
对于已知的报表查询、数据导出任务,在会话内临时提高:
●●●SET work_mem = '256MB';-- 执行重查询RESET work_mem;
这种用法适合能控制会话生命周期的场景(后台任务、脚本、专用连接)。连接池复用的短连接不适合这种方式,容易出现设置泄漏。
验证:改完怎么确认有效
改了 work_mem 之后,三个指标确认效果:
|
|
|
|
|---|---|---|
|
|
external merge Disk |
quicksort Memory |
|
|
Batches: 8 |
Batches: 1 |
|
|
|
|
如果 Sort Method 还是 Disk,说明数据量超出了新的 work_mem 上限,要么继续调大(先评估乘法),要么从查询层面优化(加索引、减少排序字段)。
一个结论收尾:
内存调优最常见的错误是把它当成参数问题。mydbanotebook.org 的作者说得对:没有任何硬件能抗住一条失控的查询。 work_mem 控制的是正常查询的内存使用,控制不了失控的查询。真正的安全线是 statement_timeout + 监控 + 定期 EXPLAIN 分析,这三件事做到位,参数才有意义。
下一讲:shared_buffers 与缓存命中——另一个经常被设错的内存参数,以及用 pg_buffercache 看清楚内存里到底缓存了什么。
本文由人类 DBA + AI 协作完成。观点和案例是人的,查文档和码字是 AI 的。所有踩过的坑——那是人的专属贡献,AI 没有生产权限。