夜雨聆风
夜雨聆风





TensorRT-LLM 0.5.0 源码之十一
mlp.py
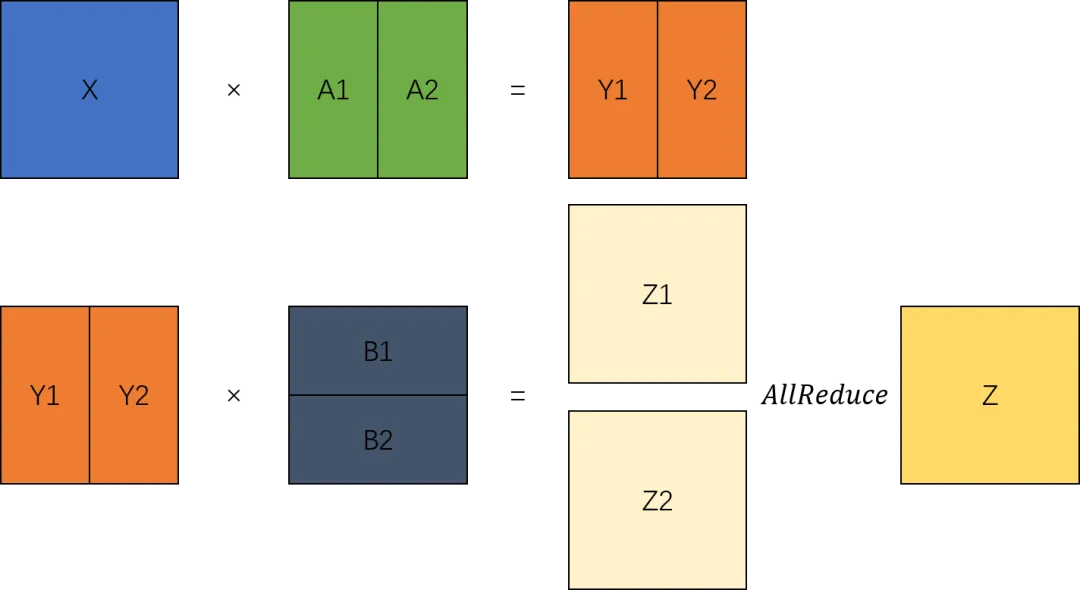
MLP
class MLP(Module):
def __init__(self,
hidden_size,
ffn_hidden_size,
hidden_act,
bias=True,
dtype=None,
tp_group=None,
tp_size=1,
quant_mode=QuantMode(0),
instance_id: int = 0):
super().__init__()
if hidden_act not in ACT2FN:
raise ValueError(
'unsupported activation function: {}'.format(hidden_act))
fc_output_size = 2 * ffn_hidden_size if hidden_act == 'swiglu' else ffn_hidden_size
self.use_fp8_qdq = quant_mode.has_fp8_qdq()
# qdq = Quant Dequant
if self.use_fp8_qdq:
self.fc = FP8Linear(hidden_size,
fc_output_size,
bias=bias,
dtype=dtype,
tp_group=tp_group,
tp_size=tp_size,
gather_output=False)
self.proj = FP8RowLinear(ffn_hidden_size,
hidden_size,
bias=bias,
dtype=dtype,
tp_group=tp_group,
tp_size=tp_size,
instance_id=instance_id)
else:
self.fc = ColumnLinear(hidden_size,
fc_output_size,
bias=bias,
dtype=dtype,
tp_group=tp_group,
tp_size=tp_size,
gather_output=False)
self.proj = RowLinear(ffn_hidden_size,
hidden_size,
bias=bias,
dtype=dtype,
tp_group=tp_group,
tp_size=tp_size,
instance_id=instance_id)
self.hidden_act = hidden_act
self.dtype = dtype
def forward(self, hidden_states, workspace=None):
inter = self.fc(hidden_states)
inter = ACT2FN[self.hidden_act](inter)
output = self.proj(inter, workspace)
return output
GatedMLP
class GatedMLP(MLP):
def __init__(self,
hidden_size,
ffn_hidden_size,
hidden_act,
bias=True,
dtype=None,
tp_group=None,
tp_size=1,
quant_mode=QuantMode(0),
instance_id: int = 0):
self.use_fp8_qdq = quant_mode.has_fp8_qdq()
super().__init__(hidden_size,
ffn_hidden_size,
hidden_act,
bias=bias,
dtype=dtype,
tp_group=tp_group,
tp_size=tp_size,
quant_mode=quant_mode,
instance_id=instance_id)
if self.use_fp8_qdq:
self.gate = FP8Linear(hidden_size,
ffn_hidden_size,
bias=bias,
dtype=dtype,
tp_group=tp_group,
tp_size=tp_size,
gather_output=False)
else:
self.gate = ColumnLinear(hidden_size,
ffn_hidden_size,
bias=bias,
dtype=dtype,
tp_group=tp_group,
tp_size=tp_size,
gather_output=False)
def forward(self, hidden_states, workspace=None):
inter = self.fc(hidden_states)
inter = ACT2FN[self.hidden_act](inter)
gate = self.gate(hidden_states)
output = self.proj(inter * gate, workspace)
return output参考文献
-
• https://github.com/NVIDIA/TensorRT-LLM/blob/v0.5.0/tensorrt_llm/layers/mlp.py