 夜雨聆风
夜雨聆风





AI智能体,正在悄悄改写生命科学的研究分工
不是又多了几个好用工具,而是实验室里最耗时间、最割裂、最依赖人肉衔接的那一层,开始被接管了。
前几年,生命科学圈讨论 AI,更多是在谈模型:蛋白结构预测、分子生成、病理识别、单细胞分析、文献检索。大家默认的使用方式也很像“高级工具箱”——你提一个问题,它给一个答案;你给一份数据,它吐一个结果。
但事情正在发生变化。
现在进入实验室和研发团队视野的,不再只是“会回答”的模型,而是会拆任务、会调工具、会串流程、会回看结果、还会继续往前推进的 AI 智能体。它不只是在某个环节提速,而是在尝试接住研究流程中原本最容易断掉的部分:从找文献,到提假设;从设计分析,到写 protocol;从连接内部数据,到组织外部证据;再到把干实验和算实验拉进同一个闭环。
真正值得关注的,不是 AI 在生命科学里“更聪明了”,而是AI 开始从一个回答者,变成一个任务执行者;从一个局部插件,变成一个研究工作流的中间层。
这不是一个小升级。这是研究分工在改。
不是模型更强了,而是“科研工作流”第一次被认真重构
生命科学一直是一个特别容易被“流程摩擦”拖慢的领域。
一个课题从想法到结果,中间要跨过太多系统:PubMed、专利数据库、实验记录、组学结果、统计脚本、内部报告、供应链、CRO、LIMS、ELN、云端计算平台。很多时候,真正拖慢课题的,并不是某一个算法不够强,而是信息不在一处,工具不在一处,人也不在一处。
所以你会看到一个很现实的场景:博士后知道问题在哪,但没时间把所有文献重新梳一遍;生信同学能写流程,但不可能随时替每个 bench scientist 定制分析;PI 看到了方向,但很难在海量碎片信息里迅速形成一套可推进的判断;而企业研发团队最大的问题,往往不是不会做,而是每推进一步,都要在不同角色、不同系统、不同数据格式之间反复转译。
AI 智能体之所以在生命科学里突然变得值得关注,原因就在这里。
它不是简单把某项能力做强,而是瞄准了科研里最贵的那部分:上下文切换、跨系统搬运、任务衔接、证据组织、决策前整理。
换句话说,生命科学真正缺的,很多时候不是“一个更大的模型”,而是一个能把分散能力编排起来的执行层。
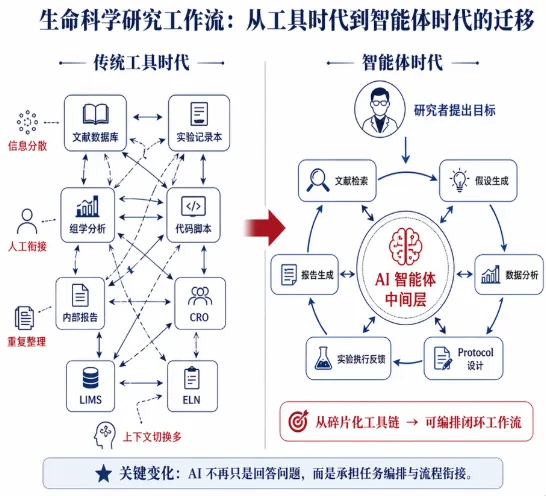
图 1:生命科学研究工作流的核心变化,不是模型替代某个工具,而是智能体开始承担流程编排与任务衔接。
先别急着问“谁最强”,要先看现在形成了哪几条路线
今天生命科学里的 AI 智能体,已经不是一个模糊概念。它大致正在沿着三条路线展开,而且这三条路线的成熟度、商业逻辑、科研含义,差别很大。
第一条路线:文献—假设—研究方案智能体
这是目前最容易率先成形的一条。
原因很简单:文献爆炸、知识碎片化、跨领域整合困难,本来就是当代生命科学最痛的底层问题之一。谁先把这一层做顺,谁就先碰到真实需求。
这一条路线里,最值得盯住的不是“谁会总结论文”,而是谁能把“找资料”这件事推进到“形成研究判断”。
很多人还没完全意识到,智能体和传统文献问答工具的本质区别,不在答案更长,而在它是否能围绕一个科研目标持续推进。它能不能自己拆解问题?能不能区分证据强弱?能不能沿着 citation 继续深挖?能不能把“有文章提过”与“这个方向值得做”分开?
如果沿着这个标准看,几个代表性系统已经非常清楚地在分层了。
Google 的 AI co-scientist,代表的是“多智能体协作式假设生成”。它不是把大模型包成一个聊天界面,而是把生成、反思、排序、进化、元审查等角色拆开,去逼近科学问题中最关键的一步:提出更有新意、同时又能落地验证的假设。这个方向的重要性不在于“像不像科学家”,而在于它开始正面碰触生命科学研究里最昂贵、最难标准化的工作——问题形成。
FutureHouse 则更激进。它的 Crow、Falcon、Owl、Phoenix 分别对应一般文献问答、深度综述、查“有没有人做过”、以及化学实验规划等不同任务,背后的思路不是通用模型一把抓,而是把科研拆成功能明确的专门代理,再进行组合。后来它把这些代理进一步串起来,做成 Robin 这样的多代理科研流程,试图把文献、候选提出、数据分析和实验迭代贯穿起来。
OpenAI 新近推出的 GPT-Rosalind,也很能说明当下风向。它不是单纯说“模型更懂生物”,而是明确把重点放在 evidence synthesis、hypothesis generation、experimental planning,以及对科学数据库和工具的调用上。这说明一个很明显的变化:生命科学不再只是大模型的应用场景,而正在变成需要专门工作流设计的垂直前沿。
这条路线已经很重要,但也最容易被误读。
它的真正价值,不是“替你读完 300 篇文献”,而是帮你把本来散落在不同论文、不同数据库、不同实验经验里的信息,组织成可以继续推进的研究上下文。也就是说,它更像一个研究前端加速器,而不是一个已经成熟的“自动发现引擎”。
第二条路线:嵌入研发系统的工作流智能体
这条路线更现实,也更容易先落地。
因为生命科学企业和机构真正愿意付钱的,很多时候不是“一个看起来很聪明的科研伙伴”,而是一个能减少手工搬运、减少信息断层、减少反复沟通的系统级助手。
Benchling 就很典型。它推进的不是浪漫化的“AI 科学家”,而是把 Agents 直接塞进研发基础设施里:让智能体去读实验记录、读附件、连内部数据、连外部资料、给出可追溯引用,然后生成分析、草稿、结构化记录和研究报告。这个方向为什么重要?因为它抓住了企业研发最真实的痛点——不是没有知识,而是知识在系统里,但团队调不出来;数据在库里,但决策串不起来。
AWS 刚推出的 Amazon Bio Discovery,则把这个思路又往前推了一步。它强调的是 lab-in-the-loop:计算设计、模型选择、工作流构建、湿实验验证和结果回流,不再靠人工在不同系统之间传球,而是尽量在同一个应用层里形成闭环。这个信号非常重要,因为它意味着云厂商也开始判断:生命科学下一阶段真正有价值的,不只是模型本身,而是把模型嵌进可反复执行、可协作、可验证的研发管线里。
这条路线的本质,不是让 AI 去“发明科学”。而是先让 AI 去消灭研发组织里最贵的摩擦成本。
别小看这件事。很多技术革命,一开始都不是靠“最惊艳的能力”改变行业,而是先靠“最稳定地省时间、省错误、省沟通”渗透进去。
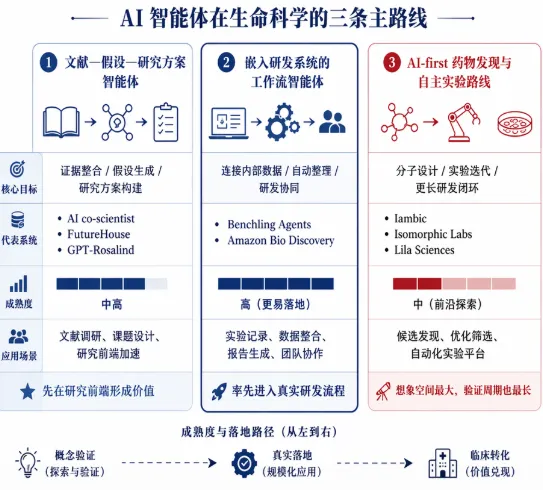
图 2:当前生命科学 AI 智能体最值得关注的,不是单点产品,而是三条正在成形的技术与产业路线。
第三条路线:AI-first 药物发现与“更长闭环”的智能体系统
如果说前两条路线主要在解决“想法”和“流程”的问题,那么第三条路线真正想做的,是把 AI 推进到药物发现、分子设计、实验迭代,甚至更长的研发闭环里。
这条路线最性感,也最容易被高估。
Iambic、Isomorphic Labs、Lila Sciences 这类玩家的共同点,是都不满足于做一个单点模型。它们更想做的是模型 + 数据 + 自动化实验 + 组织化执行的复合系统。
Iambic 这一路线,代表的是更偏工程化、平台化的 AI-first 药物设计。它不是只强调一个结构预测模型多强,而是把蛋白-配体复合物预测、项目可行性判断、高通量实验回流和候选推进串在一起。它与 Takeda 的合作之所以值得看,不只是金额大,而是说明药企开始愿意把 AI 不仅当成外围辅助,而是当成更靠近候选发现与筛选核心环节的能力层。
Isomorphic Labs 的代表意义则不同。它背后连接的是 AlphaFold 之后更大的野心:从“理解分子结构”走向“重塑药物设计引擎”。这条路线说明,生命科学 AI 的竞争,正在从单模型突破,转向系统级药物设计平台。但它同样提醒人们另一面:从漂亮的计算结果走到真正进临床,中间有极长的真实世界摩擦。临床时间表的延后,本身就是对行业最好的降温器。
Lila Sciences 更进一步,几乎是在押注“科学工厂”这一叙事:让 AI 不是只用已有数据学习,而是主动生成假设、调度实验、产出新数据、再反哺模型。这个方向非常前沿,也很有想象力,但现阶段更适合被理解为正在快速融资和搭架构的长期路线,而不是已经被大规模验证的成熟范式。
所以,这条路线最值得读者记住的判断不是“AI 已经会自己发明新药了”,而是:
药物研发中的 AI 智能体,正在从“帮助看数据”走向“参与决定下一轮该做什么”,但离真正稳定、可复制、可监管地接管长周期研发,还差得很远。
真正的分水岭:不是会不会写答案,而是能不能承担“下一步”
很多文章一谈 AI 智能体,就容易把重点放在演示画面上:能连续调用工具。能自己写计划。能根据反馈再改。能做 multi-agent debate。
这些当然重要,但它们还不是生命科学里真正的分水岭。
真正的分水岭是:它能不能在一个高噪声、高不确定、强依赖证据质量的科研环境里,持续承担“下一步该怎么做”的责任。
这件事一旦成立,研究方式就会变。因为生命科学最贵的,不是得到一个答案,而是判断下一步。
下一步做哪组对照?下一步补哪类文献?下一步换哪个候选分子?下一步做 RNA-seq 还是先做功能验证?下一步是补机制,还是先拿到可发表结果?
人类科研人员强,不只是因为会操作,而是因为能在不完美信息下做推进判断。智能体之所以重要,也不是因为它会“回答”,而是因为它开始逼近这个层面。
但必须说清楚,今天大多数系统还没到这一步。
BixBench 这类面向计算生物学真实任务的基准已经很直白地告诉我们:即使是前沿模型,面对多步骤、生物数据驱动、需要解释细节的开放任务,表现仍然不高。LABBench2 进一步说明,一旦把任务拉近真实科研场景,难度会明显上升。这意味着什么?
意味着“看起来会做研究”和“真的能在研究里稳定工作”,中间还有一整段距离。
所以今天更准确的表述,不是“AI 科学家来了”,而是:
生命科学已经进入 AI 智能体试图接手科研流程的阶段,但它最先接手的,仍然是高价值的辅助决策层,而不是最终拍板层。
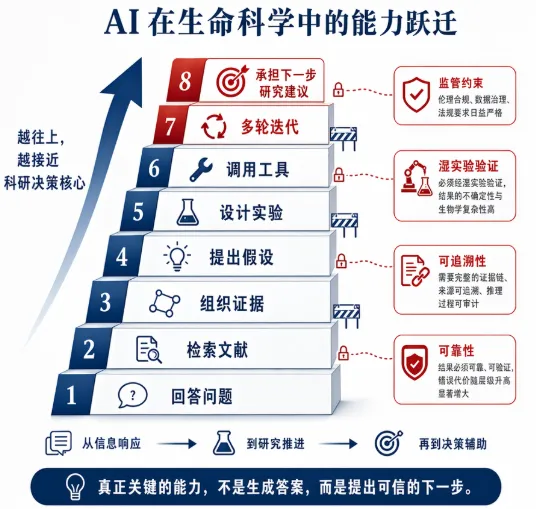
图 3:生命科学里真正重要的能力,不是生成一段像样的话,而是在高不确定环境中提出可信的“下一步”。
对生命科学科研人来说,这意味着什么
对科研个体来说,最先发生变化的,不会是“你被替代”。而是你原本靠时间硬扛的那些工作,开始被重新分配。
以前,一个人做课题,常常要在几个角色之间来回切换:半天在找文献,半天在改代码;一会儿在想机制,一会儿在补图;刚看完数据库,又去整理组会汇报;刚想推进实验,又被历史记录、试剂信息、分析流程卡住。
AI 智能体真正会改变的,就是这种切换成本。
对研究生,它会先成为研究助推器:把文献梳理、候选比较、方案草拟、分析框架搭建这些“起步慢”的环节拉快。对博士后和青年 PI,它会逐渐变成研究编排器:帮助你把课题前端判断、跨模态证据整合、多人协作推进做得更系统。对企业研发团队,它更像组织效率层:让计算、生物、药化、转化、项目管理之间的信息摩擦下降。
但这也意味着,科研人的核心能力会被重新定义。
以后真正拉开差距的,也许不再只是“谁会做某个分析”,而是:
谁更会提问题。谁更会定义目标。谁更会判断证据质量。谁更会设计人机协作的工作流。谁更知道哪些环节必须亲自盯,哪些环节可以交给智能体先跑。
换句话说,未来生命科学里稀缺的,不只是实验能力和算法能力,还包括调度智能体完成研究任务的能力。
现在最现实的瓶颈,不在“智商”,而在四个更难的问题
第一,可靠性。生命科学不是互联网问答。一个错误的通路解释、一个被误读的阴性结果、一个看似合理却缺乏边界条件的实验建议,代价都很高。智能体输出如果不能被追溯、被验证、被约束,它再强也只能停在演示层。
第二,数据边界。公开文献是一回事,企业内部数据、患者数据、药物项目数据又是另一回事。真正高价值的生命科学智能体,一定会越来越深入私有数据和机构流程。但一旦深入,安全、权限、合规、审计就立刻变成核心问题。
第三,湿实验闭环。很多智能体现在擅长的是“想”和“写”,但生命科学最终要面对的是“做”。只要实验执行、结果回流、失败处理、批次差异、现实噪声还大量依赖人,所谓“自动科学家”就很难真正闭环。
第四,评价体系。现在行业最缺的,不是更响亮的 demo,而是更接近真实科研工作的评估方法。如果评价仍然停留在回答题目、复述知识、写得像不像,那么大家会高估很多系统的真实能力。
所以,今天讨论 AI 智能体在生命科学的应用,最怕两种极端。
一种是过度浪漫化,仿佛实验室马上就要无人化。另一种是轻视它,把它当成“不过就是高级搜索”。
两种都不对。
更准确的判断是:它还远没有成熟到重写全部科研,但已经成熟到足以重写一部分研究分工。
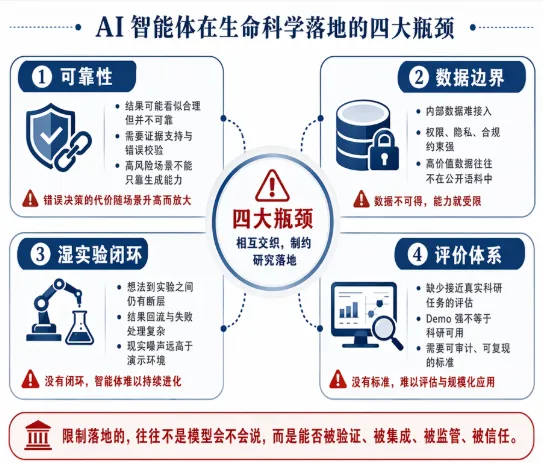
图 4:真正限制生命科学 AI 智能体落地的,往往不是模型会不会说,而是能否被验证、被集成、被监管、被信任。
最后真正该记住的一句话
如果一定要把这篇文章压缩成一个判断,我会写成这句:
AI 智能体在生命科学里的意义,不是再造一个“会聊天的科学家”,而是在重建科研流程中最关键、也最昂贵的连接层。
它把文献、数据、工具、实验、报告、协作,重新接成一个可推进的系统。它最先改变的,也不是某个单点技术指标,而是研究怎样被组织、怎样被加速、怎样被决策。
所以,真正值得关注的,不是 AI 智能体会不会替代生命科学家。而是未来几年里,谁能最早学会把智能体嵌进自己的研究工作流,谁就更可能在同样的时间里,推进更多问题,完成更多闭环,做出更高密度的科研判断。
生命科学的下一轮竞争,未必先发生在“谁有更大的模型”。更可能先发生在:谁先拥有了更强的智能体化研究组织能力。
参考资料
-
Google Research. Accelerating scientific breakthroughs with an AI co-scientist. 2025. -
Gottweis J, et al. Towards an AI co-scientist. arXiv, 2025. -
FutureHouse. FutureHouse Platform: Superintelligent AI Agents for Scientific Discovery. 2025. -
FutureHouse. Demonstrating end-to-end scientific discovery with Robin: a multi-agent system. 2025. -
FutureHouse. Announcing BixBench: A Benchmark to Evaluate AI Agents on Bioinformatics Tasks. 2025. -
Mitchener L, et al. BixBench: a Comprehensive Benchmark for LLM-based Agents in Computational Biology. arXiv, 2025. -
Laurent JM, et al. LABBench2: An Improved Benchmark for AI Systems Performing Biology Research. arXiv, 2026. -
Benchling. AI Capabilities: AI, Purpose-built for Every Stage of R&D. 2026. -
Benchling Help Center. Search, analyze, and answer complex questions about your data with the Deep Research agent. 2026. -
OpenAI. Introducing GPT-Rosalind for life sciences research. 2026. -
AWS for Industries. Introducing Amazon Bio Discovery. 2026. -
Iambic Therapeutics. Iambic Announces Collaboration with Takeda to Advance AI-Driven Design of Small Molecules. 2026. -
Reuters. Google-backed Isomorphic Labs delays clinical trial timeline. 2026. -
Isomorphic Labs. News. 2026. -
Lila Sciences. Scientific Superintelligence to solve humankind’s greatest challenges. 2026.