 夜雨聆风
夜雨聆风





企业知识库管理系统|把散落文档做成「可问、可搜、可管」的企业知识中台
一、项目背景及简介
很多团队不是缺文档,而是缺「统一入口 + 可控权限 + 好用检索」。文档在网盘、邮件、Wiki、IM 文件里各有一份时,新人问老人、老人翻收藏夹,成本高且难审计;一旦要做 AI 问答,没有规范化的语料与引用来源,又容易变成「模型随口编」。下面先对齐问题,再说明本系统如何收口。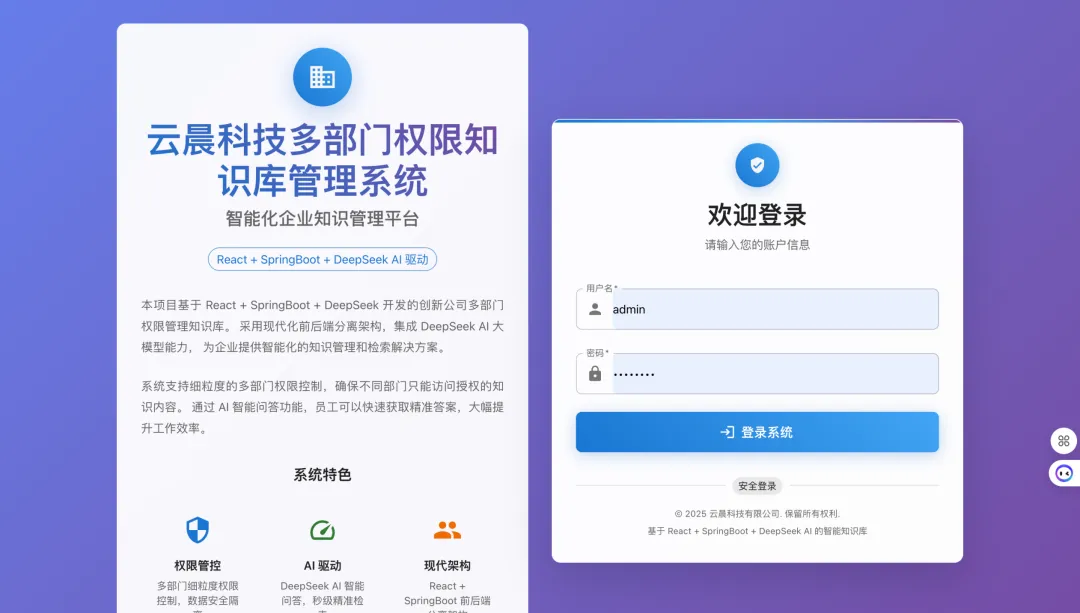
1.1 背景概述
企业里常见的是:资料越写越多,但沉淀不等于可检索、可复用。传统做法往往卡在几类典型矛盾上:
-
知识孤岛问题:各部门文档分散存储,缺乏统一管理平台 -
查找效率低下:员工需要花费大量时间在多个系统中查找所需信息 -
权限管理混乱:难以实现细粒度的部门级权限控制 -
知识传承困难:新员工难以快速获取历史经验和最佳实践 -
重复工作频发:相同问题被反复咨询,缺乏知识沉淀机制
1.2 项目简介
企业知识库管理系统是一个面向中大型企业的智能化知识管理解决方案。系统采用现代化的前后端分离架构,深度集成DeepSeek AI大语言模型,为企业提供文档管理、智能搜索、AI问答、权限控制等一站式知识服务。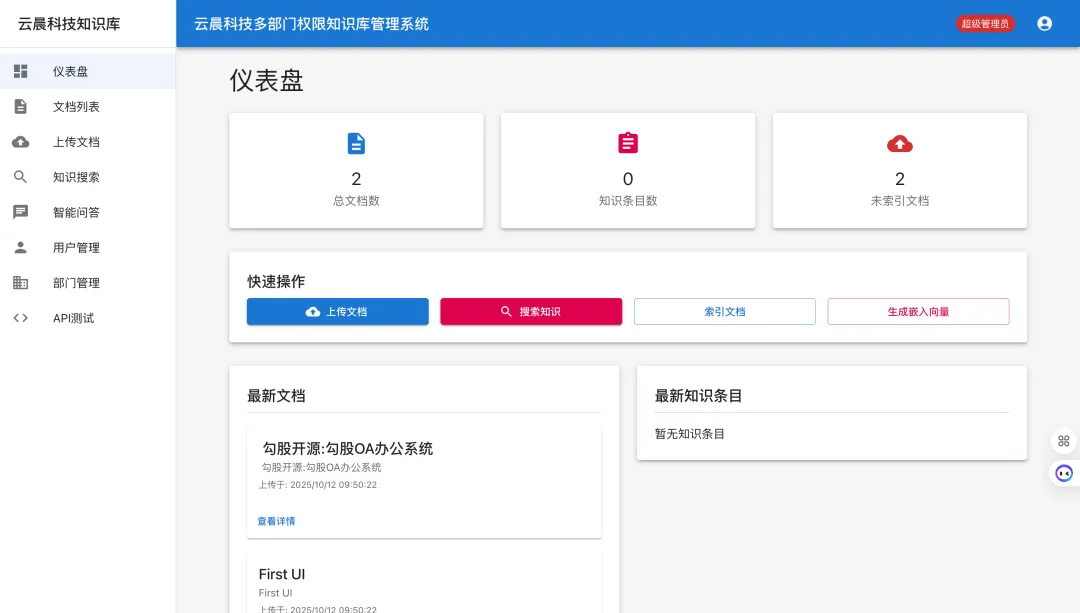
1.3 核心价值
-
智能化:AI驱动的语义搜索和智能问答,让知识查找从”搜索”变为”对话” -
安全性:多层级权限体系,确保敏感信息仅在授权范围内访问 -
易用性:直观的用户界面,零学习成本,开箱即用 -
可扩展性:模块化设计,支持企业定制化需求 -
成本效益:开源技术栈,降低企业IT成本
1.4 技术特点
系统基于Spring Boot 2.7 + React 18技术栈构建,采用JWT无状态认证、RESTful API设计、向量化语义搜索等先进技术,确保系统的安全性、性能和可维护性。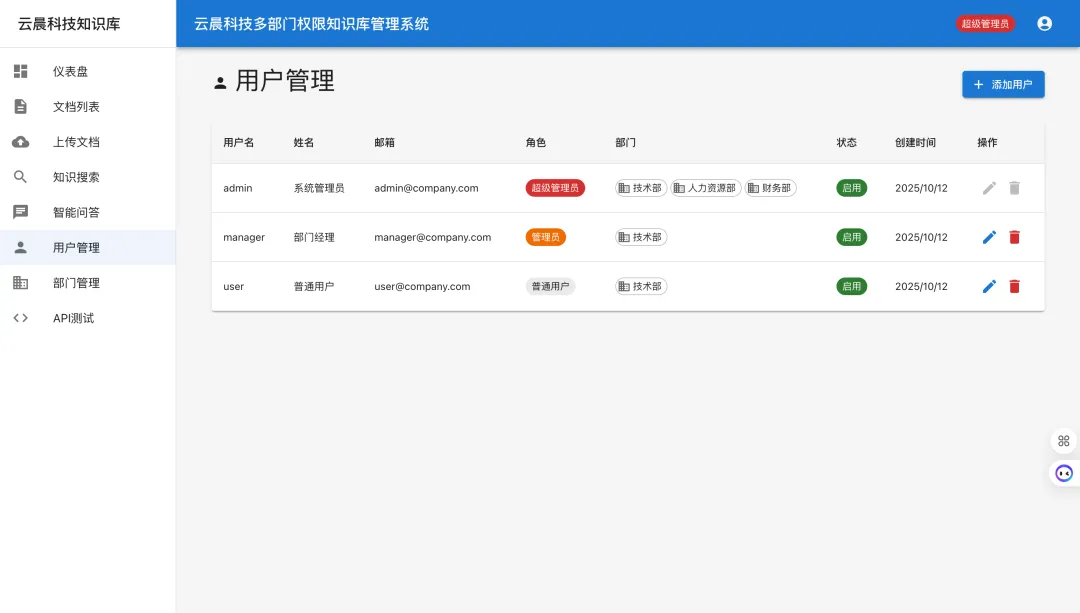
二、目标客户
2.1 主要客户群体
中大型企业
-
特征:拥有多个部门(5个以上),员工规模100+,知识资产丰富 -
需求:统一的知识管理平台,跨部门知识共享,权限精细化管理 -
典型行业:制造业、金融业、零售业、物流业等
技术型公司
-
特征:以技术为核心,需要管理大量技术文档、API文档、开发规范 -
需求:技术文档集中管理,代码规范传承,技术问题快速解答 -
典型行业:软件开发公司、互联网公司、IT服务公司
咨询服务公司
-
特征:项目经验丰富,需要沉淀和复用最佳实践 -
需求:项目案例库,行业知识库,方案模板管理 -
典型行业:管理咨询、财务咨询、法律咨询、工程咨询
教育培训机构
-
特征:教学资料丰富,课程内容需要统一管理 -
需求:教学资源库,课程资料管理,培训材料共享 -
典型行业:企业大学、培训机构、在线教育平台
政府机关及事业单位
-
特征:政策文件多,工作流程复杂,需要规范化管理 -
需求:政策法规库,工作流程文档,规章制度查询 -
典型行业:政府部门、事业单位、行业协会
医疗机构
-
特征:医疗知识专业性强,诊疗指南需要及时更新 -
需求:诊疗指南管理,病例库建设,医疗知识传承 -
典型行业:医院、诊所、医疗研究机构
2.2 适用场景
|
|
|
|
|---|---|---|
| 企业内部知识共享 |
|
|
| 技术文档管理 |
|
|
| 客服知识库 |
|
|
| 培训资料管理 |
|
|
| 政策法规查询 |
|
|
三、平台定位
3.1 产品定位
智能化企业知识管理平台 – 致力于成为企业知识资产管理的核心基础设施
核心定位
-
AI驱动的知识管理:不仅仅是文档存储,更是智能化的知识服务 -
企业级安全标准:满足中大型企业对数据安全和权限管理的严格要求 -
开箱即用:提供完整的解决方案,无需复杂配置即可投入使用
差异化优势
-
多部门权限管理:支持细粒度的部门级权限控制,确保数据安全隔离 -
AI智能问答:集成DeepSeek大语言模型,提供自然语言交互体验 -
语义搜索:基于向量相似度的智能检索,超越传统关键词搜索 -
零代码配置:管理员通过可视化界面完成所有配置,无需技术背景
价值主张
-
让知识资产活起来:从静态存储到动态服务,提升知识利用效率 -
降低知识获取成本:从平均15分钟缩短到2分钟的知识查找时间 -
促进知识传承:避免因人员流动造成的知识流失
四、平台技术与系统架构
4.1 整体架构
系统采用经典三层、前后端分离,可独立部署与扩展。逻辑拓扑(自左向右):
客户端 →(HTTPS)→ Nginx(可选) → React SPA → REST → Spring Boot(Security/JPA/业务) ↓ MySQL / 本地文件 / DeepSeek & Embeddings4.2 核心技术栈
前端技术栈
React 18 – 现代化前端框架
-
采用函数式组件和Hooks,代码简洁高效 -
支持服务端渲染(SSR),提升首屏加载速度 -
虚拟DOM机制,确保高性能渲染
TypeScript – 类型安全的JavaScript超集
-
编译时类型检查,减少运行时错误 -
提供完整的IDE智能提示和代码补全 -
增强代码可维护性和团队协作效率
Material-UI 5 – Google Material Design组件库
-
丰富的UI组件,快速构建现代化界面 -
响应式设计,适配各种屏幕尺寸 -
主题定制,支持企业品牌化
React Router 6 – 单页应用路由管理
-
声明式路由配置,代码清晰易维护 -
支持路由守卫,实现权限控制 -
懒加载路由,优化应用性能
Axios – HTTP客户端
-
拦截器机制,统一处理请求和响应 -
支持请求取消和超时控制 -
自动处理JSON数据转换
后端技术栈
Spring Boot 2.7 – 企业级Java框架
-
自动配置,减少样板代码 -
内嵌Tomcat,简化部署流程 -
丰富的Starter依赖,快速集成各种功能
Spring Security – 安全认证框架
-
基于JWT的无状态认证机制 -
支持方法级权限控制(@PreAuthorize) -
跨域资源共享(CORS)配置
Spring Data JPA – 数据持久化框架
-
自动生成SQL,减少手写代码 -
支持复杂查询和分页 -
事务管理,确保数据一致性
Apache Tika – 文档解析库
-
支持50+种文档格式(PDF、Word、Excel、PPT等) -
自动提取文档元数据和文本内容 -
处理各种编码和字符集
OkHttp – HTTP客户端
-
用于调用DeepSeek API和OpenAI API -
连接池管理,提升性能 -
支持超时和重试机制
数据库技术
MySQL 8.0 – 生产环境关系型数据库
-
支持JSON数据类型,存储向量数据 -
全文索引,支持中文分词 -
事务ACID特性,确保数据一致性
H2 Database – 开发环境内存数据库
-
零配置,快速启动 -
支持SQL标准,便于开发测试 -
可导出为SQL脚本,方便迁移
AI集成技术
DeepSeek API – 大语言模型服务
-
提供智能问答能力 -
支持多轮对话和上下文理解 -
可配置的模型参数(temperature、max_tokens等)
OpenAI Embeddings API – 文本向量化服务
-
将文档内容转换为高维向量 -
支持余弦相似度计算 -
实现语义级别的相似度搜索
向量相似度搜索 – 语义搜索核心
-
基于余弦相似度算法 -
支持大规模向量检索 -
可扩展为向量数据库(如Milvus、Pinecone)
4.3 系统架构设计
分层架构
系统采用经典的分层架构,各层职责清晰:
-
表现层(Presentation Layer)
-
React前端应用,负责用户交互 -
路由管理、状态管理、UI渲染 -
业务逻辑层(Business Layer)
-
Spring Boot服务层,处理业务逻辑 -
文档处理、AI服务、权限验证 -
数据访问层(Data Access Layer)
-
Spring Data JPA,封装数据库操作 -
实体映射、查询优化、事务管理 -
数据持久层(Persistence Layer)
-
MySQL数据库,存储结构化数据 -
文件系统,存储文档文件
安全架构
请求路径:JWT 过滤器 → AuthenticationManager → @PreAuthorize → 部门过滤(PermissionUtil 等)→ 业务。实现见 backend 下 Security 配置与各 Controller。
数据流架构
-
文档: 上传 → Tika 抽取 → 分块 →(可选)Embeddings → 持久化 KnowledgeEntry。 -
问答: 问句嵌入 → EmbeddingService相似度取片段 →ChatService组 prompt → DeepSeek → 落库会话。细节见DocumentController、ChatService、EmbeddingService。
4.4 关键技术实现
JWT 签发/校验、余弦相似度、按部门过滤文档等均在仓库 backend/src/main/java/com/company/knowledgebase/ 中实现(如 Security/JWT 工具类、EmbeddingService、DocumentService 等),此处不再展开大段源码。若需对照阅读,可直接在 IDE 中全文搜索 generateToken、calculateCosineSimilarity、department。
五、平台核心业务功能
5.1 用户权限管理
多角色体系
系统支持三种用户角色,每种角色具有不同的权限范围:
超级管理员(SUPER_ADMIN)
-
拥有系统所有权限 -
可以访问所有部门的文档 -
可以管理所有用户和部门 -
可以配置系统参数
管理员(ADMIN)
-
可以管理本部门的用户和文档 -
可以上传、编辑、删除本部门文档 -
可以查看本部门的统计数据
普通用户(USER)
-
只能查看本部门授权的文档 -
可以使用AI问答功能(仅限本部门范围) -
可以搜索和浏览文档
部门权限管理
系统支持用户与多个部门关联(user_departments 等多对多表,详见 database/init.sql)。
权限控制逻辑:
-
用户只能访问其所属部门的文档 -
超级管理员可以访问所有部门 -
文档上传时自动关联到指定部门 -
搜索和AI问答结果自动按权限过滤
JWT认证机制
系统采用JWT(JSON Web Token)实现无状态认证:
认证流程:
-
用户登录,提交用户名和密码 -
后端验证用户凭证 -
生成JWT Token,包含用户信息和权限 -
前端存储Token,后续请求携带Token -
后端验证Token有效性,提取用户信息
Token特点:
-
无状态:服务器不需要存储Session -
安全:使用HS512算法签名,防止篡改 -
可扩展:支持分布式部署 -
过期控制:Token设置有效期,自动过期
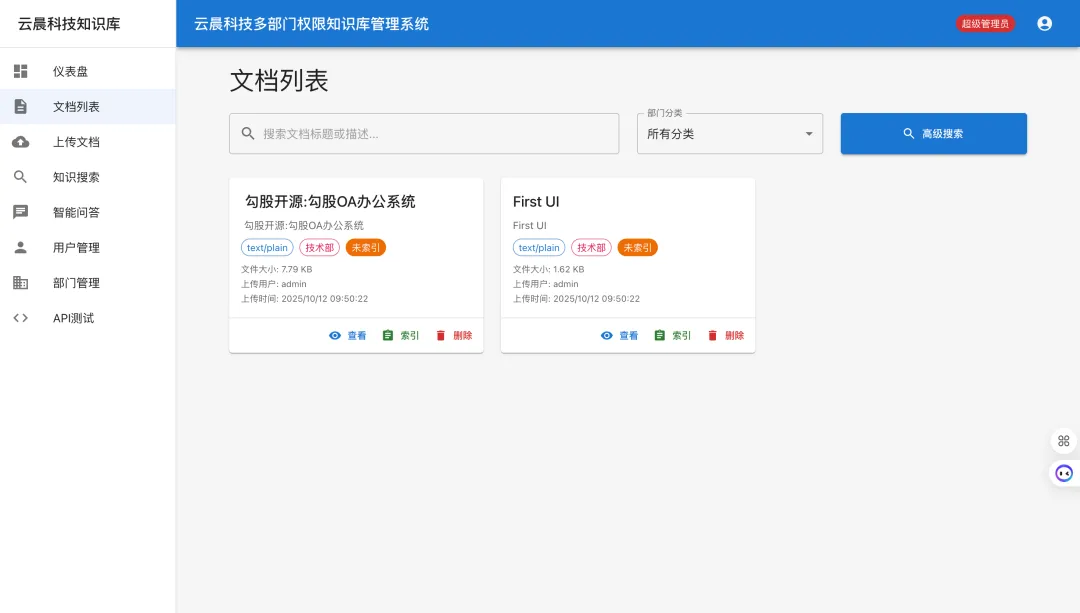
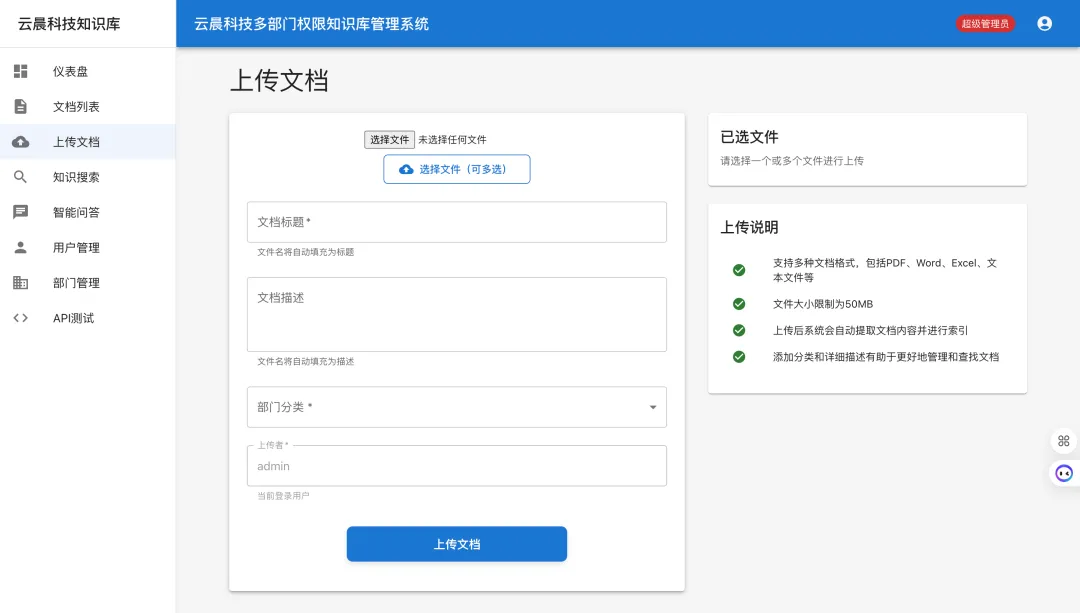
5.2 文档管理
文档上传
系统支持多种文档格式的上传和管理:
支持的格式:
-
办公文档:PDF、Word (.doc, .docx)、Excel (.xls, .xlsx)、PowerPoint (.ppt, .pptx) -
文本文件:TXT、Markdown、HTML、XML、JSON -
图片文件:JPG、PNG、GIF(OCR提取文字) -
其他格式:CSV、RTF等
上传流程:DocumentController 接收 multipart,校验 → Tika 抽取 → 落库 → 生成 KnowledgeEntry 与向量(见 DocumentService 等实现)。
文档解析:
-
使用Apache Tika自动识别文档类型 -
提取文档文本内容和元数据 -
处理各种编码和字符集 -
支持OCR识别图片中的文字
文档分类与组织
分类体系:
-
按部门分类:每个文档必须关联到一个部门 -
按类别分类:支持自定义类别(如:技术文档、政策文件、培训材料等) -
按时间分类:自动记录上传时间和更新时间 -
按上传者分类:记录文档上传者信息
文档索引:
-
文档上传后自动创建知识条目(KnowledgeEntry) -
将长文档分割为多个条目,便于检索 -
为每个条目生成向量嵌入(Embedding) -
建立全文索引,支持关键词搜索
批量操作
系统支持文档的批量管理:
-
批量上传:一次选择多个文件上传 -
批量删除:选择多个文档进行删除 -
批量索引:为未索引的文档批量生成向量 -
批量导出:导出文档列表和元数据
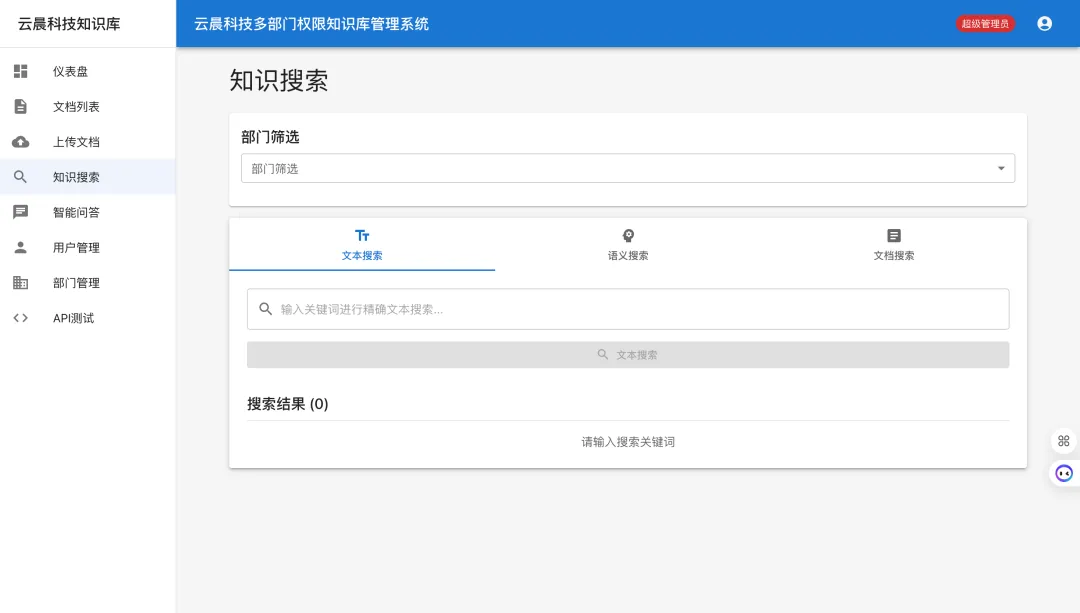
5.3 智能搜索
关键词搜索
传统的全文检索功能,支持:
-
全文索引:对文档内容建立全文索引 -
关键词匹配:支持多关键词组合搜索 -
模糊匹配:支持部分匹配和通配符 -
结果排序:按相关度、时间等排序
搜索实现: 关键词类查询走 JPA Repository,结果集经部门过滤;具体方法见 DocumentController / DocumentService。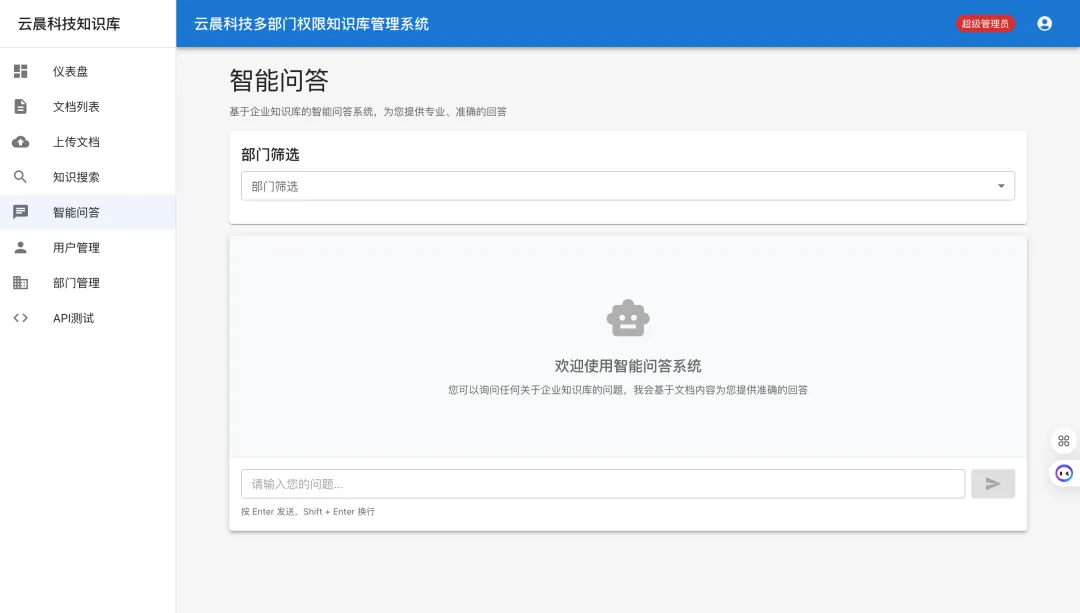
语义搜索
基于AI向量技术的智能搜索:
工作原理:
-
将查询文本转换为向量(使用OpenAI Embeddings API) -
计算查询向量与文档向量的余弦相似度 -
返回相似度最高的文档片段 -
支持语义理解,不局限于关键词匹配
优势:
-
语义理解:理解查询意图,而非简单匹配 -
同义词识别:自动识别同义词和相关概念 -
上下文感知:考虑查询的上下文含义 -
多语言支持:支持中英文混合搜索
实现要点: 问句嵌入后与候选 KnowledgeEntry 向量做余弦排序,见 EmbeddingService;大规模场景建议迁向量库。
部门筛选
搜索功能支持按部门筛选:
-
权限自动过滤:普通用户只能搜索本部门文档 -
多部门选择:管理员可以选择多个部门进行搜索 -
全部部门:超级管理员可以搜索所有部门
5.4 AI智能问答
对话式交互
系统提供类似ChatGPT的对话式问答体验:
核心功能:
-
自然语言提问:用户可以用自然语言提问 -
上下文理解:支持多轮对话,理解上下文 -
答案来源标注:显示答案引用的文档来源 -
会话管理:保存对话历史,支持会话恢复
问答流程: 检索片段 → 组装 system/user 消息 → OkHttp POST DeepSeek /chat/completions → 解析 choices[0].message.content → 持久化消息。完整实现见 **ChatService**。
实现机制
系统提示与 API 调用: 由 ChatService 内私有方法完成(拼接知识片段、构造 JSON 请求体、带 Authorization: Bearer)。此处不贴长代码。
权限控制
AI问答功能同样遵循部门权限控制:
-
普通用户:只能基于本部门文档进行问答 -
管理员:可以选择本部门或下属部门 -
超级管理员:可以选择任意部门或全部部门
权限过滤实现: 在 EmbeddingService / ChatService 调用链上对部门 ID 取交集后再截断 Top-K,详见源码中带 User / departmentIds 参数的方法。
5.5 系统管理
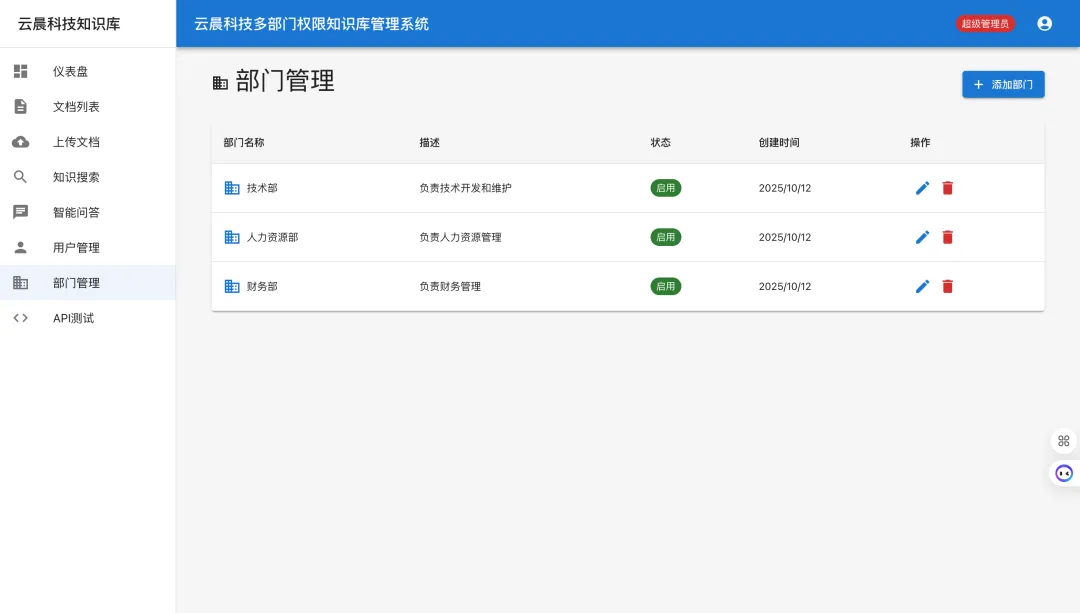
部门管理
系统提供完整的部门管理功能:
功能特性:
-
部门创建:创建新部门,设置部门名称和描述 -
部门编辑:修改部门信息 -
启用/禁用:可以临时禁用部门,禁用后该部门文档不可访问 -
部门列表:查看所有部门及其状态
数据模型: 见 database/init.sql 中 departments 等表定义。
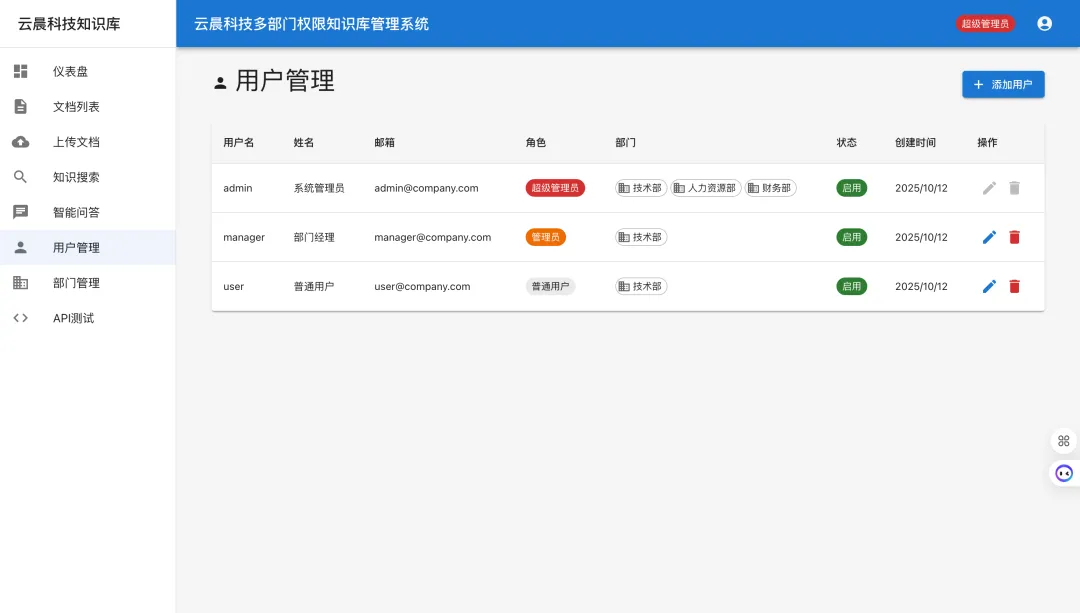
用户管理
用户操作:
-
创建用户:设置用户名、密码、角色、部门 -
编辑用户:修改用户信息,调整部门和角色 -
删除用户:删除用户(级联删除关联数据) -
启用/禁用:临时禁用用户账号 -
密码重置:管理员可以重置用户密码
用户表结构: 见 database/init.sql(users 表,role 枚举等)。
权限配置
用户部门关联:
-
一个用户可以属于多个部门 -
用户可以访问所有所属部门的文档 -
支持动态调整用户的部门归属
配置界面:
-
可视化选择用户和部门 -
批量分配部门权限 -
查看用户的部门权限列表
系统监控
统计信息:
-
文档统计:总文档数、已索引文档数、按部门分类统计 -
用户统计:总用户数、活跃用户数、按角色分类统计 -
部门统计:部门数量、每个部门的文档数和用户数 -
使用统计:AI问答次数、搜索次数、上传次数
日志管理:
-
操作日志记录 -
错误日志追踪 -
性能监控日志
六、平台独特优势
6.1 技术优势
现代化架构设计
前后端分离架构
-
前端和后端完全解耦,可以独立开发和部署 -
支持多前端(Web、移动App、小程序)共用同一后端API -
便于团队协作,前端和后端可以并行开发
微服务友好
-
RESTful API设计,易于拆分为微服务 -
无状态服务,支持水平扩展 -
服务间通过HTTP通信,松耦合设计
技术栈先进
-
采用最新的稳定版本技术 -
TypeScript提供类型安全 -
Spring Boot提供企业级特性
AI深度集成
DeepSeek大语言模型
-
集成DeepSeek API,提供强大的自然语言理解能力 -
支持多轮对话和上下文理解 -
可配置的模型参数,适应不同场景
向量化语义搜索
-
基于OpenAI Embeddings的向量化技术 -
余弦相似度算法,实现语义级别的搜索 -
支持大规模向量检索(可扩展为向量数据库)
智能文档处理
-
自动文档解析和内容提取 -
智能分块,优化检索效果 -
自动生成向量嵌入
类型安全与代码质量
TypeScript类型系统
-
编译时类型检查,减少运行时错误 -
完整的IDE支持,提升开发效率 -
代码可读性和可维护性更高
Spring Boot企业级特性
-
自动配置,减少样板代码 -
统一异常处理 -
完善的日志系统
6.2 安全优势
多层权限体系
用户角色权限
-
三级角色体系:超级管理员、管理员、普通用户 -
基于角色的访问控制(RBAC) -
方法级权限注解(@PreAuthorize)
部门级权限控制
-
用户与部门多对多关联 -
文档自动关联部门 -
搜索和问答结果自动按权限过滤
数据隔离
-
部门间数据严格隔离 -
普通用户无法访问其他部门文档 -
超级管理员可以跨部门访问
安全认证机制
JWT无状态认证
-
无需服务器存储Session -
Token包含用户信息和权限 -
支持分布式部署和负载均衡
密码安全
-
BCrypt加密存储密码 -
密码强度验证 -
支持密码重置功能
API安全
-
CORS跨域配置 -
CSRF防护 -
SQL注入防护(JPA自动处理)
安全最佳实践
密码 BCrypt、JWT HS512 与 @PreAuthorize 等在 SecurityConfig / 各 Controller 中落地;生产请轮换强 jwt.secret 并配合 HTTPS。
6.3 性能优势
快速响应
前端优化
-
单页应用(SPA),无需整页刷新 -
代码分割和懒加载 -
静态资源CDN加速
后端优化
-
API响应时间优化 -
数据库查询优化 -
连接池管理
缓存机制
-
多级缓存策略 -
文档内容缓存 -
搜索结果缓存
批量处理
文档批量操作
-
批量上传支持 -
批量索引处理 -
批量删除操作
向量生成优化
-
异步处理向量生成 -
批量API调用 -
失败重试机制
可扩展性
水平扩展
-
无状态服务,支持多实例部署 -
负载均衡支持 -
数据库读写分离(可扩展)
垂直扩展
-
支持增加服务器资源 -
数据库性能优化 -
缓存层扩展
七、平台安装使用
7.1 环境要求
开发环境
必需软件:
-
Java: JDK 8 或更高版本(推荐JDK 11+) -
Node.js: 16.x 或更高版本(推荐LTS版本) -
Maven: 3.6+ 用于Java项目构建 -
MySQL: 8.0+ 用于生产环境数据库 -
Git: 用于版本控制
开发工具(推荐):
-
IDE: IntelliJ IDEA 或 Eclipse(Java开发) -
IDE: Visual Studio Code 或 WebStorm(前端开发) -
数据库工具: MySQL Workbench 或 Navicat
生产环境
服务器要求:
-
操作系统: Linux (Ubuntu 20.04+ / CentOS 7+) -
CPU: 2核心以上 -
内存: 4GB以上(推荐8GB+) -
磁盘: 50GB以上(根据文档数量调整) -
网络: 稳定的互联网连接(用于调用AI API)
软件要求:
-
Java运行环境: JRE 8+ -
Nginx: 1.18+ 用于反向代理 -
MySQL: 8.0+ 数据库服务器 -
SSL证书: 用于HTTPS(推荐Let’s Encrypt免费证书)
7.2 快速安装(命令合并)
git clone <仓库URL> && cd company-knowledge-devlopmysql -u root -p -e "CREATE DATABASE knowledgebase CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;"mysql -u root -p knowledgebase < database/init.sqlcd backend && cp -n src/main/resources/application-prod.properties.example src/main/resources/application-prod.properties 2>/dev/null; true# 编辑 application-local.properties 或 application-prod.propertiesmvn spring-boot:run # 或 mvn -q -DskipTests package && java -jar target/*.jar --spring.profiles.active=prodcd ../frontend && npm install && npm start# 生产:npm run build,API 基址见 src/services/api.prod.ts / REACT_APP_API_URL关键配置(节选,完整见 backend/src/main/resources/application*.properties):
spring.datasource.url=jdbc:mysql://localhost:3306/knowledgebasespring.datasource.username=...spring.datasource.password=...jwt.secret=请替换为 openssl rand -base64 48 级别长度deepseek.api.key=${DEEPSEEK_API_KEY:}embeddings.api.key=${OPENAI_API_KEY:}embeddings.enabled=trueserver.port=13085Nginx 要点: 静态 location /knowledgeWeb/ 指向 frontend/build/,API location /knowledgeWeb/api/proxy_pass 到后端 http://127.0.0.1:13085/api/;HTTPS 自行补证书。完整样例已删节,按现网路径改即可。
7.3 详细配置说明
-
数据库:连接池、时区、 utf8mb4、慢查询与索引优化见database/init.sql及 DBA 规范;按需对documents.department_id等加索引。 -
AI:无 Key 时可设 embeddings.enabled=false走关键词能力;DeepSeek 超时在ChatService所用 OkHttp 中已放宽,仍建议网关侧限流。 -
安全: jwt.secret勿入库仓;全站 HTTPS。
7.4 Docker(可选)
仓库含 backend/Dockerfile;Compose 需自建。典型流程:mvn package 后 docker build -t kb-backend ./backend,数据库与卷按环境变量注入,勿把真实密码写入 YAML 提交。
7.5 运维管理
# 状态 / 日志 / 备份(按需选用)systemctl status nginx mysql; tail -n200 backend/logs/*.logmysqldump -u USER -p knowledgebase | gzip > backup_$(date +%F).sql.gz排障: 端口占用、java -version、JDBC URL、CORS、deepseek.api.key / 出网策略。
八、应用场景及使用案例说明
咨询公司项目知识库
客户背景:
-
公司规模:某管理咨询公司,员工80+,其中咨询顾问50+ -
业务特点:项目制工作,每个项目都有独特的解决方案 -
痛点问题: -
项目经验难以沉淀和复用 -
行业知识分散,查找困难 -
客户方案缺乏标准化模板 -
新顾问需要大量时间学习历史项目经验
解决方案实施:
1. 项目案例库建设
-
按行业分类:金融行业案例、制造业案例、零售业案例 -
按业务类型分类:战略咨询、运营优化、数字化转型 -
按项目阶段分类:项目启动、需求分析、方案设计、实施交付
知识条目示例: 以「行业 / 业务类型 / 周期 / 挑战 / 方案 / 效果」等字段结构化写入文档,便于检索与问答拼接。
2. 最佳实践沉淀
-
将成功项目的经验总结为最佳实践 -
将失败项目的教训总结为注意事项 -
形成可复用的知识模板
3. AI智能推荐
-
顾问输入新项目需求:”为某制造企业设计数字化转型方案” -
AI自动推荐相似的历史项目案例 -
提供可参考的解决方案框架
使用场景(示意): 输入新项目画像,系统按向量相似度列出历史案例标题与要点,顾问再人工裁剪进标书。
实施效果:
-
✅ 项目准备时间缩短50%:从平均2周缩短到1周 -
✅ 方案质量一致性提升:基于历史经验的方案更可靠 -
✅ 顾问工作效率提升35%:减少重复性方案设计工作 -
✅ 客户满意度提升:方案更贴合实际,实施成功率更高
🚀 快速开始
https://www.qdzjkf.com/knowledgeWeb/超级管理账号: admin 密码:admin123管理员账号:manager 密码: admin123普通账号:user 密码: user123

软件接单交流群:
