 夜雨聆风
夜雨聆风





4月23日AI观察:代理进入治理时代
如果只看 4 月 23 日这一天 X 上的 AI 讨论,很容易被表面的热闹带偏:一边是 Qwen3.6-27B、Kimi K2.6 这样的模型更新继续刷榜,另一边是 Claude、OpenAI、Google、Microsoft 各自围绕 Agent 放出新说法、新产品和新叙事。可真正值得盯住的,不是哪家模型又多了几个点,而是行业判断正在明显收敛: Agent 不再只是“能不能做出来”的问题,而是“怎么接入系统、怎么管起来、出了事谁负责”的问题。
这也是为什么同一天里,Google 一边在讲长时运行 Agent 的设计模式,一边又把讨论重点从“如何构建 Agent”推到“如何管理成千上万个 Agent”;Microsoft 在讲每个 Agent 都需要自己的“计算机”;Anthropic 的 Managed Agents 被拿来和企业自建基础设施做对比;Greg Brockman 又把软件开发的下一阶段描述成“代理管理平台”。几条线放在一起看,方向已经很清楚了:2026 年的竞争,不只是模型能力竞赛,更是 Agent 基础设施、治理能力和工作流交付能力的竞赛。
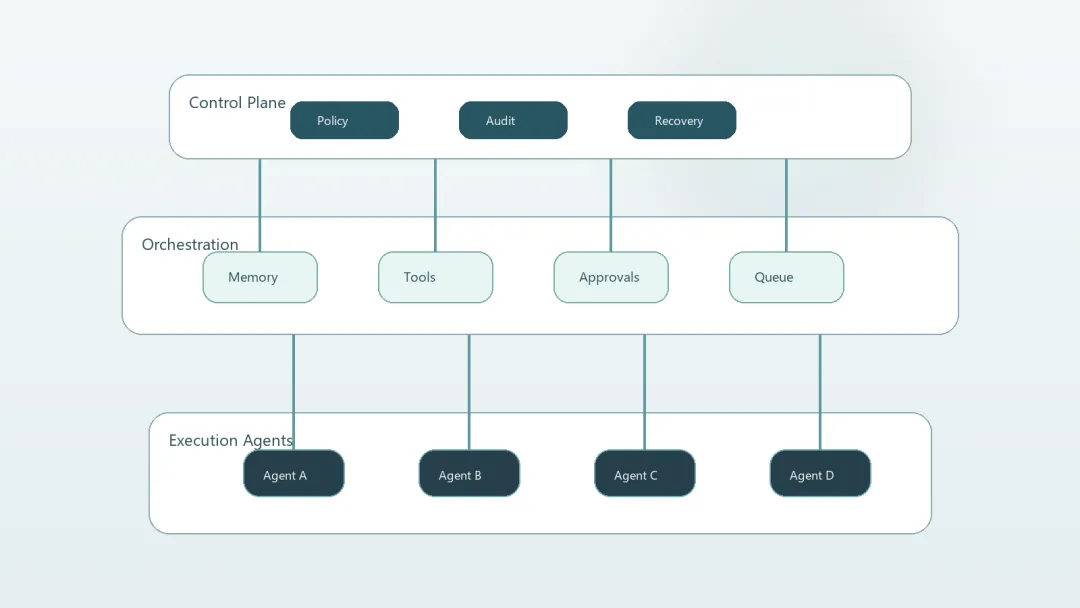
昨天最强的一条主线,是 Agent 平台化已经从概念走向企业级组织问题。Google Cloud 给出的 5 种长时运行 Agent 设计模式,其实已经不是在教人怎么写一个 demo,而是在回答真正上线之后会遇到的麻烦:任务做到一半如何断点恢复,审批链怎么嵌进去,记忆如何分层,后台事件怎么持续处理,多 Agent 怎么编排协作。换句话说,行业开始默认 Agent 会长期运行、会跨系统工作、会接触真实业务。
同样的信号,也出现在 Google 关于 Gemini Enterprise Agent Platform 的表述里。讨论焦点不再是“让模型更聪明一点”,而是 Build、Scale、Govern、Optimize 这套完整框架。平台方已经意识到,只给企业一个会回答问题的模型没有意义,企业真正需要的是一套能建、能管、能审、能控的系统。
Microsoft Foundry 的托管代理预览,和 Anthropic 的 Claude Managed Agents,其实也站在同一个方向上。它们卖的不是某个单一模型的分数,而是沙箱、持久状态、身份、恢复能力、治理接口这些“脏活累活”。这类能力过去通常需要团队自己搭,周期长、坑也多。现在厂商都在争着把这部分收走,本质上是在争夺 Agent 时代的基础设施层。
这对企业的意义很直接:接下来采购 AI,不再只是选模型,而是要选一整套运行与控制体系。谁能把权限边界、任务恢复、审计记录和多 Agent 协作做扎实,谁就更接近真正可落地的企业级产品。只会聊天、不会治理的 Agent,很快会被视为半成品。
开源模型继续冲,真正的变化是“高能力”开始下沉
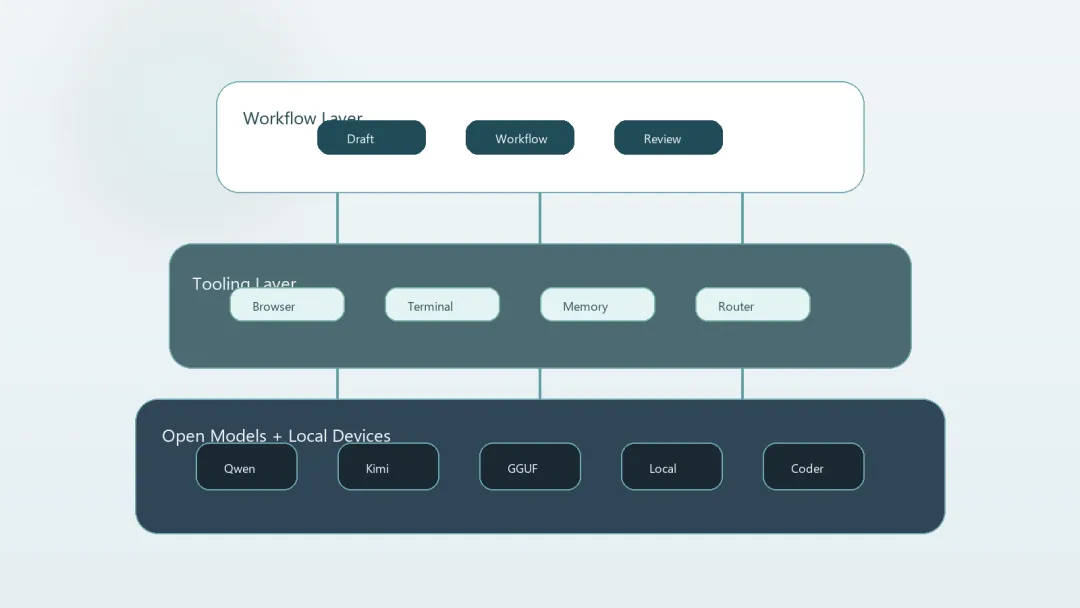
如果说平台层在变厚,那么模型层最值得注意的变化,是高能力模型正在更快地下沉。Qwen3.6-27B 这类更新之所以有分量,不是因为又多了一个名字,而是因为它继续强化一个趋势:更小的参数规模,开始逼近甚至超过更大的前代模型,在编码、多模态理解和实际可部署性之间做出更现实的平衡。再叠加 Unsloth 对本地运行门槛的继续下压,开源模型的意义就不只是“可替代”,而是“可进入普通开发者机器”。
Kimi K2.6 的讨论也有类似味道。过去很多开源模型发布,更多是社区狂欢;现在不一样,大家看的是它能不能进工具链、能不能接浏览和执行、能不能支撑更长链路的编码任务。模型仍然重要,但判断标准已经从“会不会答”变成“能不能干活”。
同一时间,围绕 Claude Opus 4.7、Genspark Build、OpenClaude 0.4 的讨论,也指向了另一层变化:前沿模型不再只拼推理深度,而是在拼产品承载形式。有人在做从想法到网站原型的端到端生成,有人在做多模型统一工作流,有人在强调更稳定的长链路编码体验。也就是说,模型层的竞争正在迅速产品化,最后比的不只是智力上限,而是被什么样的界面、工具和工作流包起来。
基础设施叙事正在抬头:每个 Agent 都需要“自己的机器”
Satya Nadella 那句“每个 Agent 都需要自己的计算机”,之所以能引发传播,不只是口号讲得漂亮,而是它很准确地点出了下一阶段的资源形态。Agent 一旦从问答走向执行,就不可能只占用一次性的上下文窗口。它需要状态、文件、权限、身份、网络边界,最好还要能恢复、能追踪、能独立运行。换句话说,它更像一个带治理边界的计算单元,而不是一个被临时召唤的回答器。
Google Cloud 同天还在讲 Virgo Network 这种大规模 AI 数据中心网络架构,表面看是硬核基础设施新闻,和普通用户距离很远;但如果把它和长时 Agent、托管 Agent、企业平台这条线放在一起看,逻辑就接上了。行业上游在重写算力与网络结构,下游在重写应用和工作流结构,中间夹层就是 Agent 这一代产品的运行环境。
这意味着 2026 年往后,AI 产品的差异会越来越多地体现在系统设计,而不是单点模型。为什么有的 Agent 只能做演示,有的能跑进生产;为什么有的平台只能给你一个聊天框,有的平台却能接审批、接数据、接任务队列、接权限系统。答案都不在口号里,而在基础设施层。
安全与政策不再是边角料,而是主战场的一部分
昨天另一条不能忽视的线,是安全与政策开始正面进入 AI 主叙事。围绕 Anthropic Mythos 的争议,无论具体细节后续如何发展,都已经暴露出一个非常现实的问题:能力越强的模型,风险不只在“会不会胡说”,更在“能不能被错误的人接触、在错误的场景里被调动”。这不是传统内容安全问题,而是供应链、访问控制、能力边界和责任划分的问题。
与此同时,关于前沿 AI 实验室与美国联邦政府关系变化的讨论也在升温。这里最值得警惕的一点,不是新闻性的会面本身,而是一个更长期的趋势:头部模型公司越来越像基础设施承包方与战略资源方,而不只是普通软件公司。到了这个阶段,政策、合规、安全和商业部署不可能分开谈。
这会直接改变创业公司和产品团队的判断方式。以前做 AI 产品,很多人默认先把效果做出来,安全和治理以后再补;现在这个顺序已经开始失效。只要产品涉及多 Agent、真实执行链路、企业数据或高价值场景,治理和安全不是后补模块,而是第一天就要写进架构里的东西。
最后要看的,不是下一个爆款模型,而是谁先把 Agent 做成系统
把 4 月 23 日这一天的信号收拢起来,会发现行业判断已经比表面热闹更明确。模型还会继续更新,开源阵营还会继续追赶,产品形态还会持续变化,但真正决定下一阶段胜负的,是谁能把 Agent 做成一套稳定系统:有状态、有边界、有恢复能力、有审计能力,也能真正接入工作流。
所以,比起继续沉迷“哪个模型更强”这种单点问题,更值得问的是另外三个问题:你的 Agent 是否有明确的权限和责任边界;它出了错之后能否被复盘和修正;它到底是在生成答案,还是在交付结果。谁先把这三件事做实,谁就更接近下一波 AI 产品的核心位置。