OpenClaw(龙虾)的兴起,如何影响AI底层技基础设施?
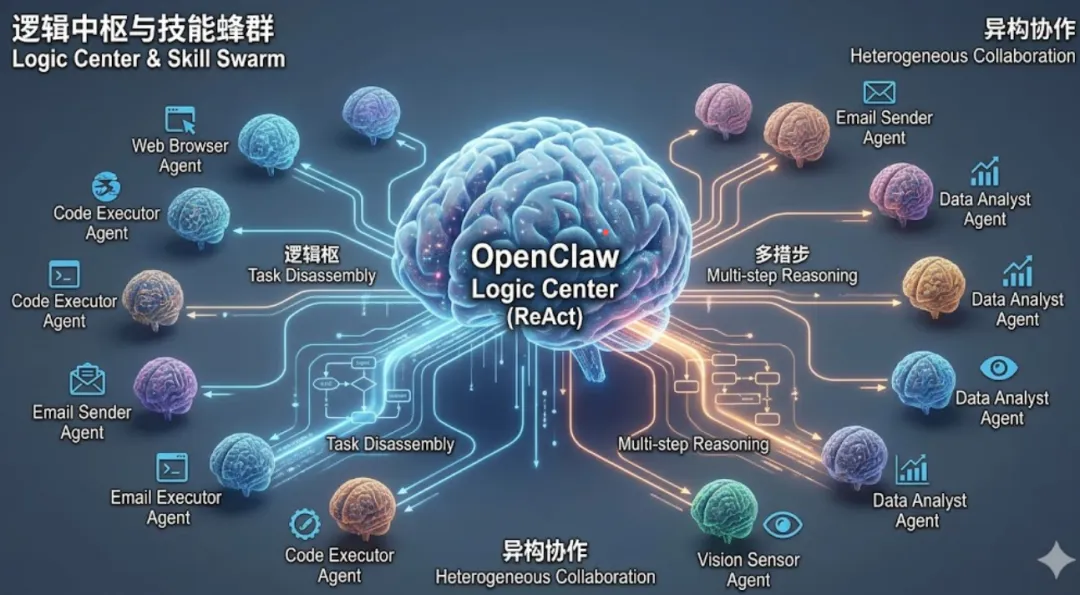
2025年底至2026年初,由奥地利开发者 Peter Steinberger 主导的开源智能体框架 OpenClaw(社区昵称“龙虾”)迅速席卷全球AI圈。与ChatGPT等传统“你问我答”的被动式对话大模型不同,OpenClaw 是一个真正拥有“手脚”的自主智能体(Autonomous Agent) ——它能够接管系统权限,自主跨应用执行各类任务,从收发邮件、云端创建服务器到自主部署新代码,均可独立完成,且能在后台实现7×24小时不间断运行。 这种从“被动对话”到“主动执行” 、从“单次交互”到“持续在线” 的范式跃迁,标志着人工智能正式迈入“智能体即服务(Agent as a Service)”的全新阶段。这一转变不仅是软件应用层的革新,更对底层AI基础设施发起了一场极其严苛的压力测试。 以下,我将从AI模型、算力芯片、存储、网络 这几个核心维度,解析 OpenClaw 的兴起,对AI基础设施提出的全新需求。 一、 AI模型:从“语言生成器”向“逻辑中枢与技能蜂群”演进 OpenClaw这类自主智能体,核心需求已从“把话说得漂亮”转向“把事办得明白”。这对底层AI模型的架构设计与核心能力,提出了三个维度的质变要求: 强化System 2(慢思考)与逻辑推理能力 :传统语言模型侧重基于概率的“快思考”(核心是预测下一个词),而OpenClaw中的模型需依托ReAct(推理与行动)框架,完成复杂任务的拆解与执行。当用户下达“分析上个月的财务数据并生成报告发给全组”的指令时,模型必须具备严密的规划能力、纠错能力与工具调用(Tool/API Calling)准确率。这意味着模型训练阶段,需注入更多包含逻辑链路、代码执行与环境反馈的高质量数据,夯实推理与行动的核心能力。支持超长上下文与“大海捞针”般的检索精度 :“龙虾”的持续运行特性,使其不断积累用户交互记录、系统日志与网页浏览内容——一个连续运行一周的OpenClaw智能体,其上下文长度可轻松突破百万甚至千万Token。这就要求基础模型不仅能“承载”海量上下文,更能在庞杂记忆中精准提取关键信息,确保执行复杂任务时不遗漏前置条件、不出现“遗忘”问题。走向异构化的“模型蜂群(Model Swarm)” :一个高效运行的OpenClaw,并非依赖单一巨无霸模型,而是一套协同工作的模型组合。这就要求基础设施需同时支持三类模型:负责意图识别与任务分发的高速路由模型(Router)、承担复杂决策的大型推理模型(Brain),以及大量部署在边缘或端侧、专精于视觉识别、代码格式化等特定场景的微型技能模型(Skills)。这种多模型协同调度的架构,进一步提升了对模型轻量化、专精化的要求。二、 算力芯片:告别“脉冲式负载”,迎接“全天候、异构化与高隔离” ChatGPT时代,算力负载呈现“脉冲式”特征——用户提问时算力飙升,阅读回复时则处于闲置状态。而随着“养龙虾”成为趋势,大量OpenClaw在后台全天候自主运行,甚至出现AWS案例中“龙虾自主衍生新龙虾”的场景,这使得算力芯片的需求发生了根本性扭转: 从追求“首字延迟(TTFT)”转向“全局吞吐量” :人机对话场景中,人类对首字延迟极其敏感;但对于后台自主运行的OpenClaw,机器与机器(M2M)的异步交互,更看重单位时间内可处理的Token总量。因此,算力芯片的架构设计需进一步扩大SRAM容量,优化批处理(Batching)效率,以支撑海量智能体并发运行时的巨大吞吐需求。极端的能效比(TOPS/Watt)成为生死线 :当个人、企业普遍拥有多个甚至数十个7×24小时在线的“数字员工”时,算力中心的耗电量将呈指数级增长。传统通用GPU功耗过高,难以适配这一场景,而针对Agent推理深度定制的ASIC(专用集成电路)或LPU(语言处理单元)将迎来爆发。这类芯片剥离了不必要的图形渲染模块,专为大规模Transformer矩阵运算和向量检索优化,以最低功耗维持“龙虾”的持续运行。硬件级安全隔离(TEE)成为标配 :2026年初,国家信息安全漏洞库(CNNVD)通报显示,OpenClaw这类拥有极高系统权限的智能体,频繁暴露出严重安全漏洞——一旦被攻击,黑客可直接接管整个系统。这就要求未来的算力芯片,必须内建更强大的机密计算(Confidential Computing) 能力,通过硬件级可信执行环境(TEE),对每个智能体的运行内存和指令进行严格的物理沙箱隔离,防范“毒龙虾”越权窃取底层算力网络的敏感数据。三、 存储:智能体的“数字海马体”,重塑IO模式与数据存储层级 传统AI训练存储的核心场景是“海量数据、持续读取(Read-Heavy)”,而OpenClaw彻底颠覆了这一现状,将存储基础设施推向“高并发读写、复杂数据结构”的深水区。 构建多级并发的记忆系统(Multi-Tier Memory) :OpenClaw需通过复杂记忆机制模拟人类行为,这就要求存储基础设施提供层次分明的数据库支持:从“重读轻写”转向“高频混合读写(50/50)” :OpenClaw执行多步任务时,需频繁进行“状态保存(Checkpointing)”与日志写入。例如,它在AWS上开通EC2实例时,每执行一步都会向本地或云端存储写入运行状态,一旦任务中断,可从断点快速恢复。这种高频、小文件的随机写操作(Write IOPS),对存储集群的元数据管理节点和底层存储介质,提出了极高的抗压要求。零信任架构下的细粒度数据管控 :鉴于“龙虾”能够自主读取本地文件和企业知识库,存储层必须具备基于属性的访问控制(ABAC)与数据访问实时审计溯源能力,确保智能体仅能访问其被授权的“数据孤岛”,防范企业核心机密被过度抓取、外泄。四、 网络:打破内存墙,承载巨量上下文 Scale-up指提升单一计算节点(如一台搭载8张GPU的服务器)的极限性能,而OpenClaw面临的核心挑战,是AI领域长期存在的“内存墙(Memory Wall)”。 极度渴求HBM(高带宽内存)容量 :智能体的长文本推理严重依赖KV Cache(键值缓存),在数百万Token的上下文中,随着生成长度增加,KV Cache的体积会呈线性甚至非线性膨胀。若单张算力芯片的HBM容量不足(如低于144GB或288GB),模型就不得不频繁将数据换页(Swapping)至主机内存甚至硬盘,导致推理速度断崖式下跌。因此,单芯片的内存密度与封装技术(如3D堆叠)必须实现大幅突破。单节点内的超高速互联互通 :当单个智能体任务过于庞大,单张芯片的内存无法容纳时,需在一个节点内的多张GPU之间进行“张量并行(Tensor Parallelism)”或“序列并行(Sequence Parallelism)”。这就要求芯片之间的总线带宽(如NVLink或下一代PCIe技术),需具备T级别/秒以上的传输速率。Scale-up的终极目标,是让服务器内的8张甚至32张GPU在逻辑上融合为一颗拥有海量显存的“超级芯片”,支撑复杂Agent的全局规划与推理。Scale-out指通过网络将成百上千个计算节点连接成庞大集群,在OpenClaw的大规模部署场景(尤其是云端或大型企业内部)中,Scale-out架构的设计重点发生了全新转变。 面向“解耦推理(Disaggregated Inference)”的网络重构 :为最大化算力利用率,现代AI基础设施正逐步将模型的“Prefill(预填充,即读取长上下文)”与“Decode(解码,即生成动作指令)”拆解至不同集群。由于OpenClaw拥有极长的历史记忆,Prefill阶段会产生海量KV Cache,这些动辄数十GB的缓存数据,必须在微秒级时间内通过数据中心网络,从Prefill集群传输至Decode集群,这就要求Scale-out网络具备极高带宽与无损传输特性。爆炸式增长的东西向流量(East-West Traffic) :未来的OpenClaw并非单兵作战,更多是由成百上千个“小龙虾”组成的多智能体系统(Multi-Agent System),它们之间会通过API频繁完成通信、状态同步与任务交接。这种大规模机器间协同,使得数据中心内部的“东西向流量”呈指数级上升,对网络架构的承载能力提出全新挑战。总结 “龙虾”OpenClaw的爆红绝非偶然,其背后是AI技术栈重心的彻底转移。如果说大模型时代的基建重点是“暴力美学式的训练算力” ,那么智能体时代的基建核心,便是“高并发、高可用、高安全的推理与运行环境” 。 从具备强逻辑规划的模型架构 ,到追求极致能效与隔离的算力芯片 ;从支撑多模态状态高频读写的多级存储 ,到为容纳超长上下文而持续打破内存墙的Scale-up纵向扩展 ,再到支撑多智能体蜂群低延迟协同的Scale-out横向网络体系 ,这五个维度正经历一场深度协同进化。 这场变革不仅将催生新一代基础设施巨头,更将彻底改变企业部署、消费计算资源的方式。
 夜雨聆风
夜雨聆风