 夜雨聆风
夜雨聆风





【统计分析软件SPSS】54、个案加权
链接:https://pan.baidu.com/s/15r0rLWkJlcecUvBPKZo_MQ?pwd=mnsj提取码:mnsj
由于微信公众号已发布文章的内容及排版顺序无法二次编辑,为了方便大家后续查阅、检索,同时便于我对内容进行补充更新与完善,我会将所有已发布的推文,在个人网站上以结构化文档的形式重新整理、归档。欢迎前往查看:
https://www.mizhushare.com/docs/
在SPSS的默认逻辑里,数据文件中的每一行代表一个独立的观测对象(例如一名受访者)。然而在实际研究中,出于数据存储效率或隐私保护的考虑,我们获取的往往是经过汇总的频数数据。
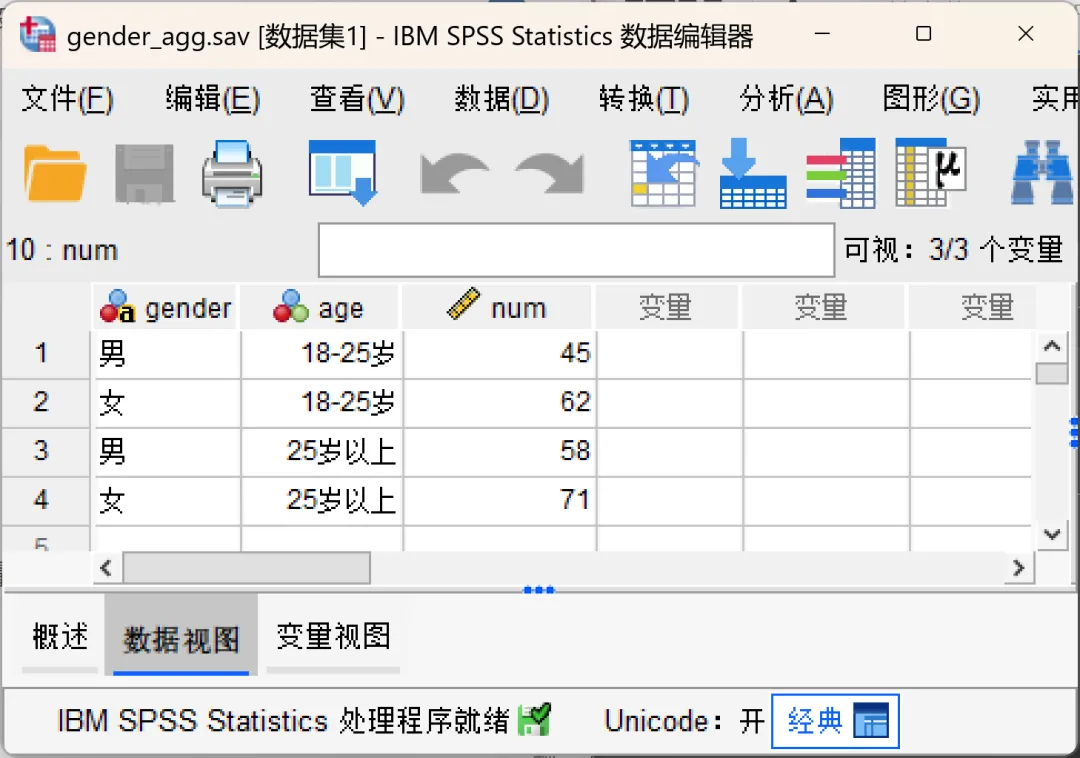
假设现有一份简单的性别统计汇总表:
|
|
|
|
|
|
|
|
|
若直接将上述两行数据导入SPSS进行分析,软件会默认样本总量仅为 2(即1名男性和1名女性),这将导致统计结果严重失真。
此时,必须使用【个案加权】功能告知SPSS每一行数据所代表的实际频数。启用加权后,SPSS在进行所有统计分析时,会将总样本量修正为350人,从而确保计算结果的准确性。
简而言之,个案加权就是赋予每行数据一个权重值(通常为频数),指示SPSS在计算时将该行数据视为N个独立的个案进行处理,而非单一的观测值。
需要注意的是,加权状态具有持续性。一旦开启个案加权,该设置将一直生效并随数据文件保存,直到用户手动关闭加权功能或指定新的权重变量为止。因此,在完成相关分析后,请务必检查并适时取消加权,以免影响后续其他分析任务的准确性。

示例数据集是4行汇总数据,每行代表一组人群,人数(num变量)是该组实际样本量,未加权时,SPSS会把这4行当成4个独立个案,总样本量显示为4,完全失真;加权后,总样本量会自动计算为45+62+58+71=236,贴合真实调研样本。
-
个案加权:
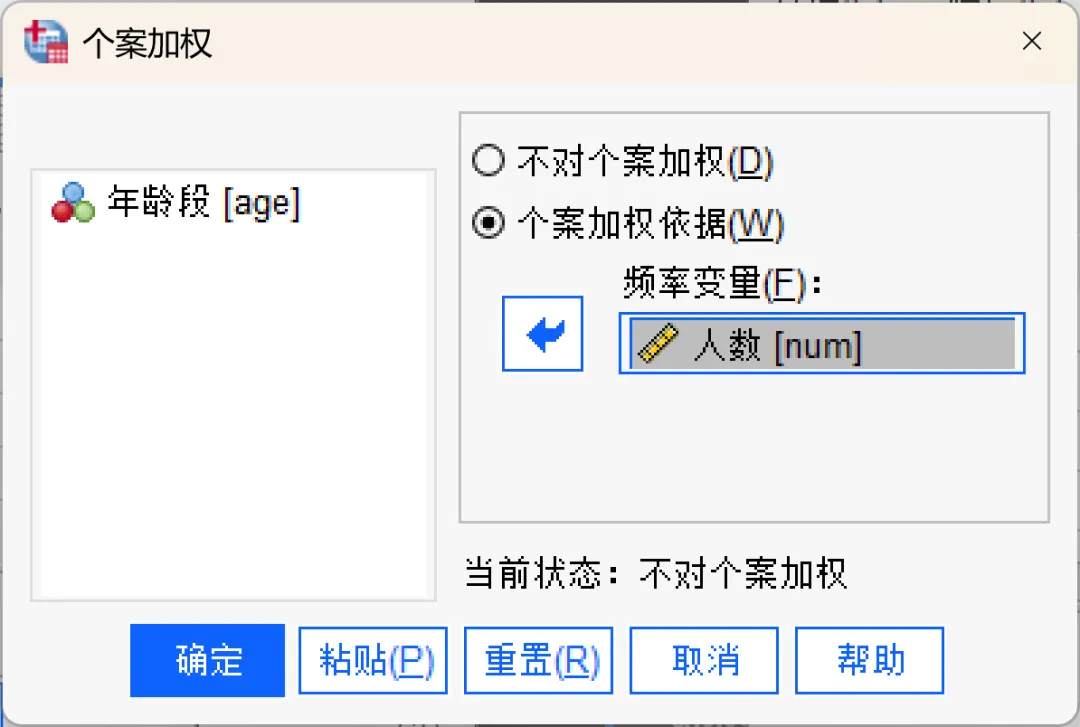
点击顶部菜单栏的【数据→个案加权】,在打开的对话框中进行相应设置。
-
频率变量:频率变量的数值将用作个案权重。例如,频率变量数值为3的个案在加权后的数据文件中将代表三个个案。
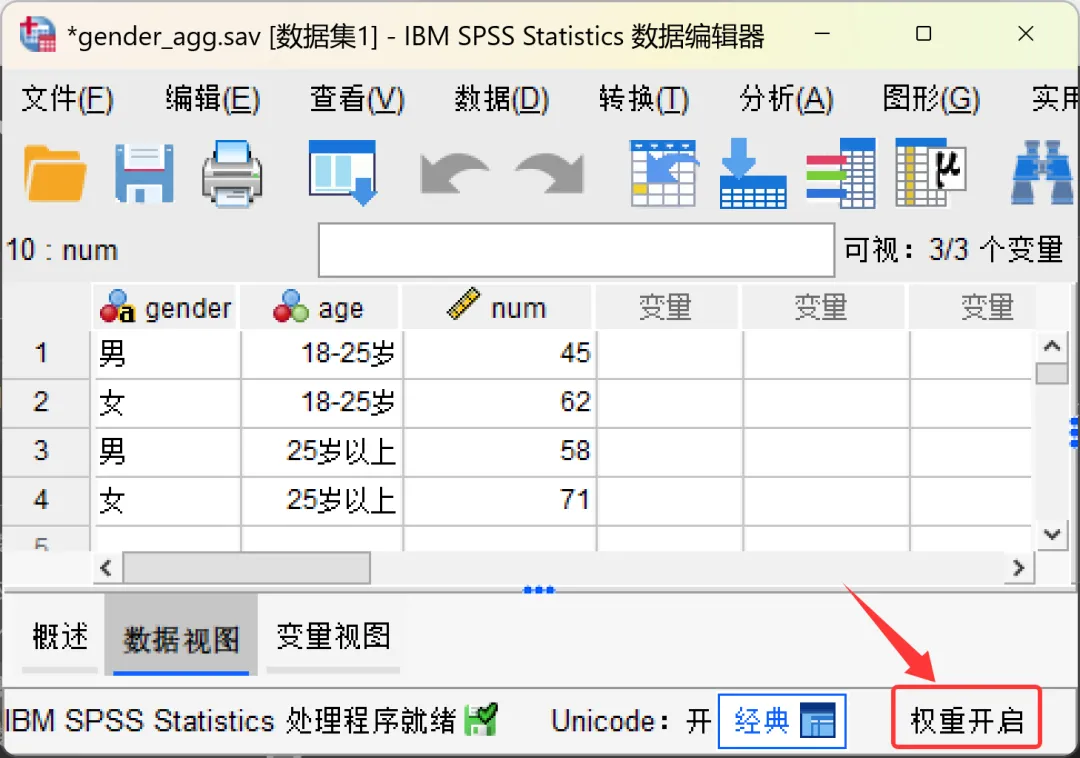
设置完成后,回到SPSS数据视图,数据编辑器窗口的右下角会显示「权重开启」字样,这就代表加权功能已生效,后续所有分析都会自动按权重计算。
-
验证加权效果:
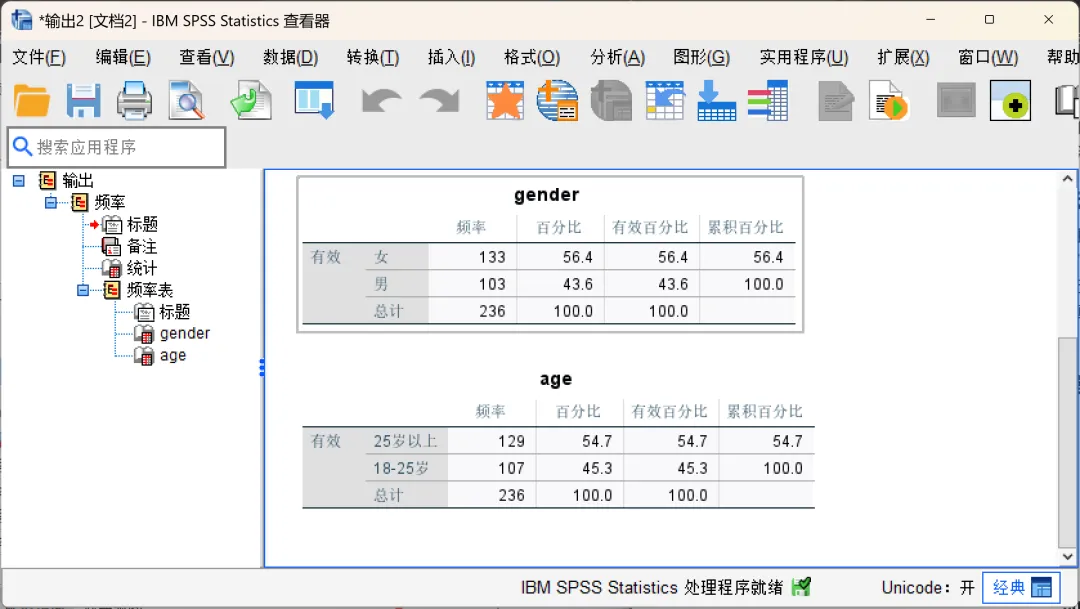
完成个案加权设置后,即可进行后续的统计分析。本次将以频率分析操作为例验证加权是否生效。
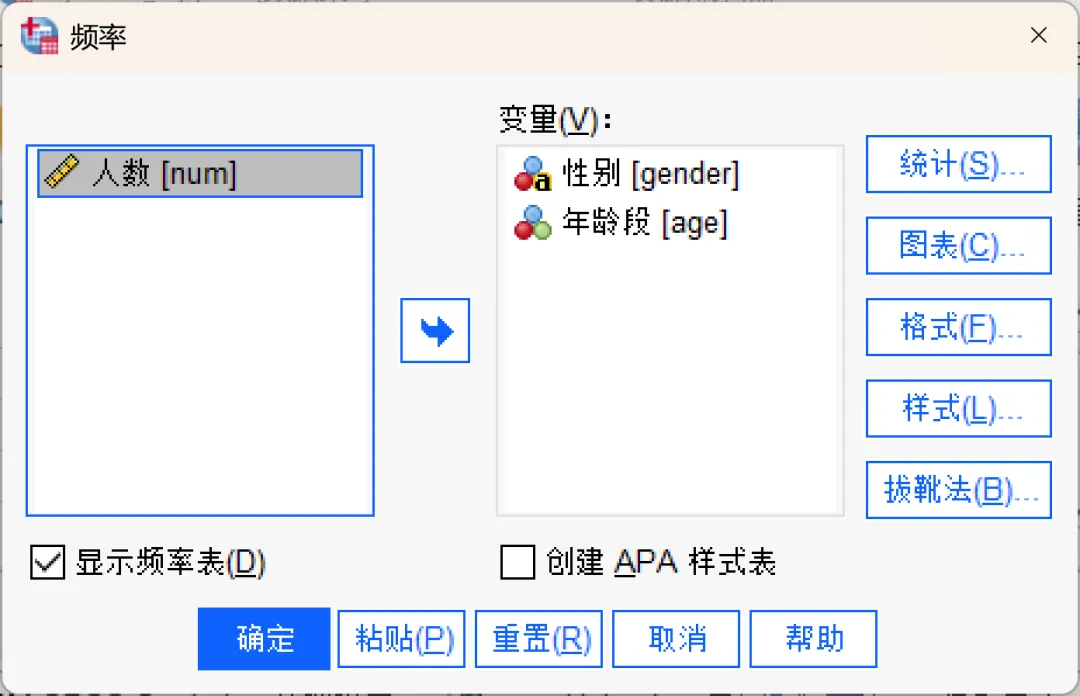
点击顶部菜单栏的【分析→描述统计→频率】,在弹出的对话框中,将「gender、age」变量移入「变量」框,点击确定生成输出结果。
SPSS会输出两个变量的频率结果,频率表中显示的样本总数应与加权后的总频数一致(即235人),说明加权设置正确。
需要注意是,在完成特定的分析后,如果需要进行其他类型的不加权分析,记得取消加权!

