 夜雨聆风
夜雨聆风





ai4protein论文推荐 | 2026-04-25
今日相关 / Relevant Today
AI4Protein 前沿追踪
AI 深度解读
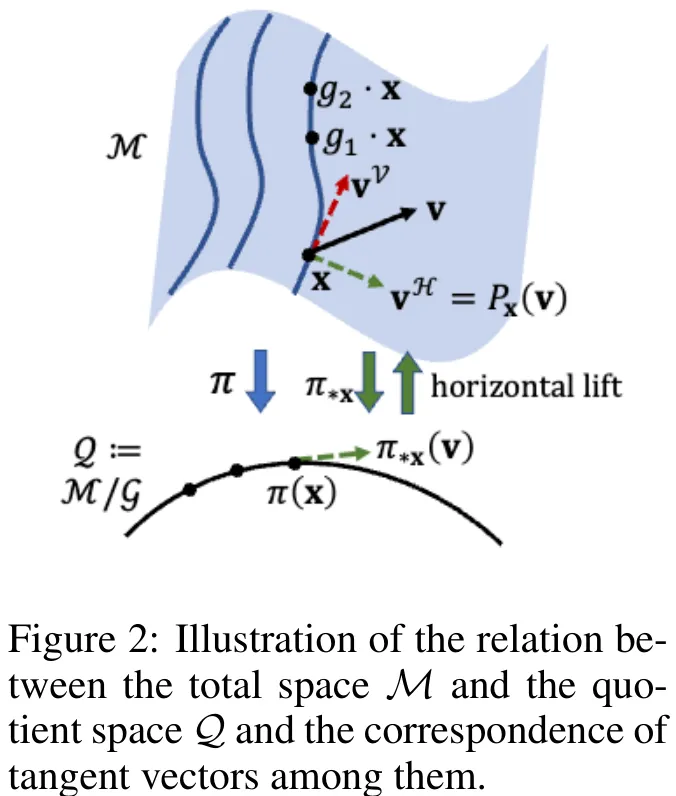
本文针对科学领域中普遍存在的对称性任务(如分子结构生成),提出了一种基于商空间(Quotient Manifold)的扩散模型。研究指出,传统扩散模型在欧氏空间中训练,难以直接处理具有内在对称性的数据分布。为此,文章构建了从欧氏空间到商空间的几何框架:首先定义流形与李群以形式化描述对称性,进而引入商空间概念,将等价类压缩为单点以反映系统的本质状态。核心方法是通过推导投影到商空间的扩散过程(SDE),利用投影向量场、商空间的平均曲率向量场以及商空间上的维纳过程,建立了描述系统演化本质的数学模型。该方法允许先在抽象的商空间上定义生成过程,再将其提升回总空间进行实际采样。在分子结构生成(R^3N/SE(3))的具体案例中,该模型证明了利用商空间构建扩散过程能有效降低训练难度,并提升了采样器的有效性,为处理具有对称性的科学数据生成提供了 principled(原则性)的解决方案。
中文摘要
基于扩散的生成模型已重塑生成式人工智能,并在科学领域催生了新能力,例如生成分子的三维结构。由于某些任务固有的问题结构,系统中常存在对称性,该对称性将可通过群作用相互转换的对象视为等价,因此目标分布本质上定义在相对于该群的商空间上。本文建立了一个适用于一般商空间的扩散建模形式化框架,并将其应用于遵循特殊欧几里得群 extSE(3) 对称性的分子结构生成任务。该框架降低了对学习群作用对应分量的需求,从而简化了相较于传统群等变扩散模型的训练难度;同时,其采样器能够保证恢复目标分布,而启发式对齐策略则缺乏适当的采样器。我们在小分子和蛋白质的结构生成任务上对理论进行了实证验证,结果表明,基于原则的商空间扩散模型提供了一个优于以往对称性处理方法的新框架。
Paper Key Illustration
原文
Quotient-Space Diffusion Models
Abstract: Diffusion-based generative models have reformed generative AI, and have enabled new capabilities in the science domain, for example, generating 3D structures of molecules. Due to the intrinsic problem structure of certain tasks, there is often a symmetry in the system, which identifies objects that can be converted by a group action as equivalent, hence the target distribution is essentially defined on the quotient space with respect to the group. In this work, we establish a formal framework for diffusion modeling on a general quotient space, and apply it to molecular structure generation which follows the special Euclidean group SE(3) symmetry. The framework reduces the necessity of learning the component corresponding to the group action, hence simplifies learning difficulty over conventional group-equivariant diffusion models, and the sampler guarantees recovering the target distribution, while heuristic alignment strategies lack proper samplers. The arguments are empirically validated on structure generation for small molecules and proteins, indicating that the principled quotient-space diffusion model provides a new framework that outperforms previous symmetry treatments.
链接:https://arxiv.org/pdf/2604.21809
AI 深度解读
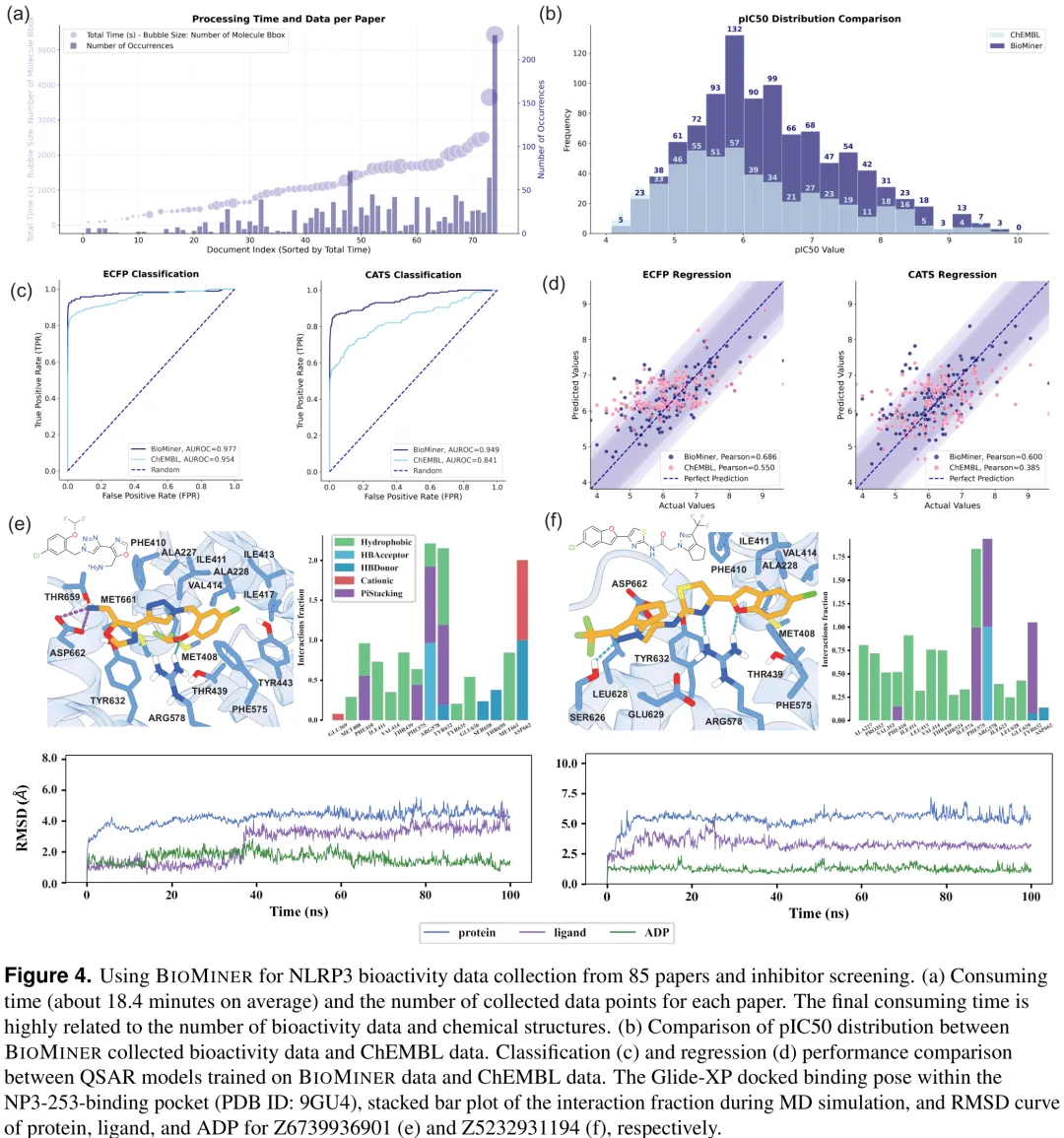
针对蛋白质 – 配体生物活性数据提取任务,研究提出了一种名为 BIOMINER 的多模态智能体框架,旨在解决自动化提取中语义推理与化学结构构建(特别是复杂的 Markush 结构)两大核心挑战。该框架摒弃了端到端预测的脆弱性,采用解耦策略将任务分解为文档解析、生物活性测量解释、化学结构解析及跨模态整合四个阶段。其中,化学结构解析引入了基于化学结构感知的视觉语义推理(CSG-VSR)机制:首先利用检测工具从图表中提取化学描绘并生成 SMILES;随后由大语言模型进行增强的视觉语义推理,识别核心骨架与 R 基团定义;最后通过确定性工具将骨架与基团组合生成完整的化学结构。为评估该框架,研究构建了 BIOVISTA 基准数据集,包含来自 500 篇论文的 16,457 条生物活性数据和 8,735 个结构。实验结果表明,BIOMINER 在复杂结构处理上表现优异,能够有效提取包括 Markush 在内的多样化化学结构,并展示了在药物设计等真实场景中的实用价值。
中文摘要
摘要:文献中发表的蛋白质 – 配体生物活性数据对药物发现至关重要,但人工整理难以跟上文献的快速增长。自动化生物活性提取仍具挑战性,因为它不仅需要解读分布在文本、表格和图中的生化语义,还需重构化学精确的配体结构(例如马库什结构)。为解决这一瓶颈,我们提出了 BioMiner,这是一种多模态提取框架,明确将生物活性语义解读与配体结构构建分离。在 BioMiner 中,生物活性语义通过直接推理得出,而化学结构则通过一种基于化学结构的视觉语义推理范式进行解析:多模态大语言模型在基于化学的视觉表示上操作以推断结构间关系,而精确的分子构建则委托给领域化学工具。为了严格的评估和方法开发,我们进一步建立了 BioVista,这是一个包含从 500 篇文献中整理的 16,457 条生物活性条目的综合基准。BioMiner 验证了其提取能力并提供了定量基准,在生物活性三元组上实现了 0.32 的 F1 分数。BioMiner 的实用价值通过三项应用得到证实:(1)从 11,683 篇论文中提取 82,262 条数据以构建预训练数据库,使下游模型性能提升 3.9%;(2)实现人机协同工作流,使高质量 NLRP3 生物活性数据数量翻倍,帮助 28 个 QSAR 模型提升 38.6%,并鉴定出 16 个具有新颖骨架的候选化合物;(3)加速蛋白质 – 配体复合物生物活性注释,在 PoseBusters 数据集上相比人工工作流速度提升 5.59 倍,准确率提升 5.75%。
Paper Key Illustration
原文
BioMiner: A Multi-modal System for Automated Mining of Protein-Ligand Bioactivity Data from Literature
Abstract: Protein-ligand bioactivity data published in the literature are essential for drug discovery, yet manual curation struggles to keep pace with rapidly growing literature. Automated bioactivity extraction remains challenging because it requires not only interpreting biochemical semantics distributed across text, tables, and figures, but also reconstructing chemically exact ligand structures (e.g., Markush structures). To address this bottleneck, we introduce BioMiner, a multi-modal extraction framework that explicitly separates bioactivity semantic interpretation from ligand structure construction. Within BioMiner, bioactivity semantics are inferred through direct reasoning, while chemical structures are resolved via a chemical-structure-grounded visual semantic reasoning paradigm, in which multi-modal large language models operate on chemically grounded visual representations to infer inter-structure relationships, and exact molecular construction is delegated to domain chemistry tools. For rigorous evaluation and method development, we further establish BioVista, a comprehensive benchmark comprising 16,457 bioactivity entries curated from 500 publications. BioMiner validates its extraction ability and provides a quantitative baseline, achieving an F1 score of 0.32 for bioactivity triplets. BioMiner’s practical utility is demonstrated via three applications: (1) extracting 82,262 data from 11,683 papers to build a pre-training database that improves downstream models performance by 3.9%; (2) enabling a human-in-the-loop workflow that doubles the number of high-quality NLRP3 bioactivity data, helping 38.6% improvement over 28 QSAR models and identification of 16 hit candidates with novel scaffolds; and (3) accelerating protein-ligand complex bioactivity annotation, achieving a 5.59-fold speed increase and 5.75% accuracy improvement over manual workflows in PoseBusters dataset.
链接:https://arxiv.org/pdf/2604.21508
今日热门 / Popular Today
ArXiv 高热度精选
AI 深度解读
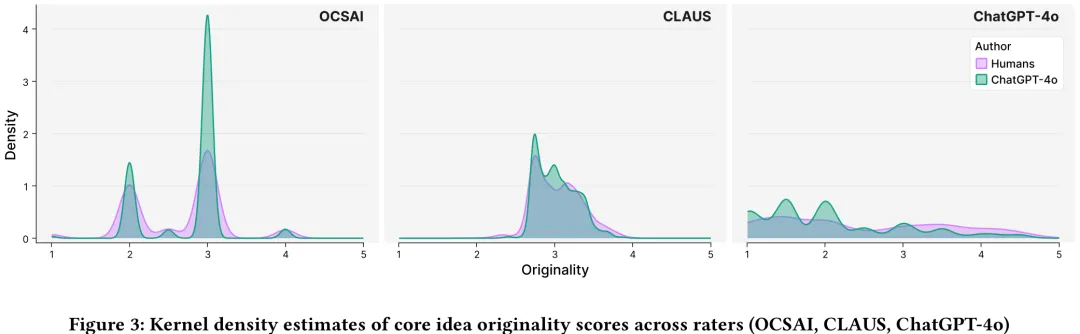
本研究旨在系统评估自动化工具(OCSAI、CLAUS 及 ChatGPT-4o)在衡量人类与大型语言模型(LLM)生成的替代用途(AUT)创意时的有效性。研究基于 Domanti 等人收集的数据库,其中包含 81 名人类参与者及由 ChatGPT-4o 生成的响应,并获得了专家人类评分者的原始性评分。研究首先分析了完整响应的原始性评分,随后参照前人研究,通过仅提取核心创意(如“便携式禅意花园”)来控制并消除“阐述偏差”(即因回答冗长而导致的评分虚高)。结果显示,在未控制阐述长度时,OCSAI 倾向于给机器生成的回答打更高分;但在控制阐述长度后,这种优势显著减弱。然而,即便在仅评估核心创意时,OCSAI 仍持续高估机器生成内容的原始性,而 ChatGPT-4o 和 CLAUS 的表现则与人类评分者存在不同程度的对齐差异。该研究揭示了当前自动化工具在评估 LLM 生成内容时存在的系统性偏差,特别是 OCSAI 对机器生成文本的偏好,并指出了现有研究在跨系统比较方面的不足,为后续优化自动化创意评估模型提供了实证依据。
中文摘要
摘要:自动系统越来越多地用于评估创造性任务中回答的原创性。它们为解决人类评估的关键局限性(成本、疲劳和主观性)提供了一种潜在的解决方案,但已有初步证据表明存在自我偏好偏差。因此,自动系统往往更倾向于偏好与其自身风格更为接近的结果,而非人类风格。本文研究了大型语言模型(LLMs)在发散思维任务中评估回答原创性时与人类评分者的一致性。我们分析了由高创造力和低创造力人类以及 ChatGPT-4o 生成的 4,813 个替代用途任务(Alternate Uses Task)的回答。人类评分者为两名经过密集培训的大学生。机器评分者包括两个基于替代用途任务回答及相应人类评分(OCSAI 和 CLAUS)进行微调的专业系统,以及接受与人类评分者相同指令的 ChatGPT-4o。研究结果证实了 LLM 中存在自我偏好偏差。自动系统倾向于优先选择人工生成的回答。然而,当分析中对观点展开程度进行控制时,这种自我偏好偏差便消失了。我们通过强调创造力评估研究的未来方向,讨论了这些发现对理论和方法论的影响。
Paper Key Illustration
原文
The Effect of Idea Elaboration on the Automatic Assessment of Idea Originality
Abstract: Automatic systems are increasingly used to assess the originality of responses in creative tasks. They offer a potential solution to key limitations of human assessment (cost, fatigue, and subjectivity), but there is preliminary evidence of a self-preference bias. Accordingly, automatic systems tend to prefer outcomes that are more closely related to their style, rather than to the human one. In this paper, we investigated how Large Language Models (LLMs) align with human raters in assessing the originality of responses in a divergent thinking task. We analysed 4,813 responses to the Alternate Uses Task produced by higher and lower creative humans and ChatGPT-4o. Human raters were two university students who underwent intensive training. Machine raters were two specialised systems fine-tuned on AUT responses and corresponding human ratings (OCSAI and CLAUS) and ChatGPT-4o, which was prompted with the same instructions as human raters. Results confirmed the presence of a self-preference bias in LLMs. Automatic systems tended to privilege artificial responses. However, this self-preference bias disappeared when the analyses controlled for the idea elaboration. We discuss theoretical and methodological implications of these findings by highlighting future directions for research on creativity assessment.
链接:https://arxiv.org/pdf/2604.20569
AI 深度解读
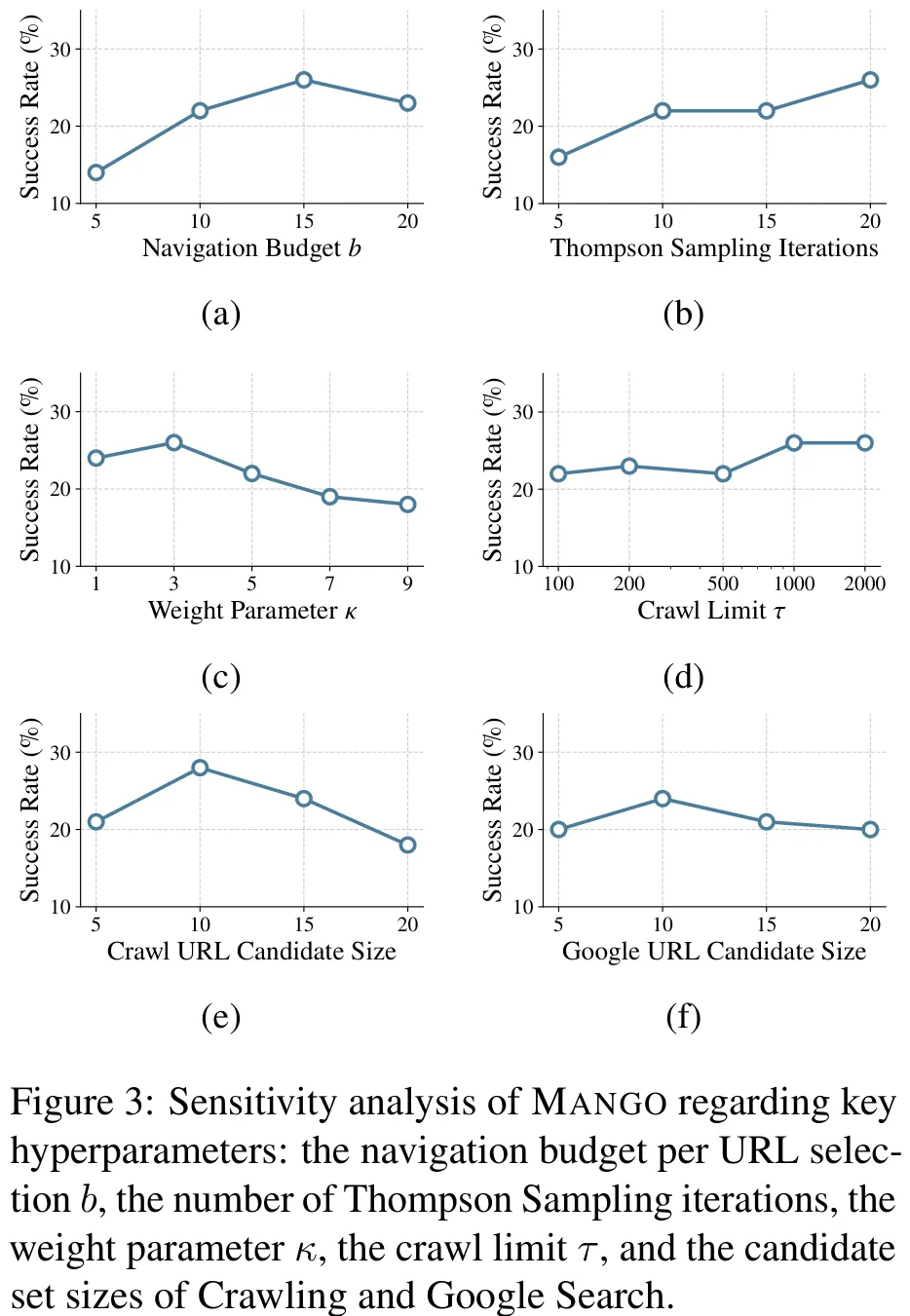
该研究提出了一种名为 MANGO 的智能体框架,旨在解决网页导航任务中探索效率与资源预算受限的矛盾问题。研究针对 WebVoyager 和 WebWalkerQA 两个基准数据集,构建了包含 Thompson Sampling 选择器、Web 导航执行器及反思评估器的三阶段架构。其中,Thompson Sampling 利用 Beta 分布动态调整 URL 选择概率,反思器则根据导航轨迹判断任务完成度或路径价值,通过奖励机制更新策略分布,并在预算耗尽或遇到死胡同时自动标记无效 URL。实验结果显示,MANGO 在多种大语言模型(包括 GPT-5-mini 及 Qwen3 系列)的支持下,成功率显著优于 AgentOccam 和 WebWalker 等现有最先进方法,特别是在多源信息整合及深层探索任务中表现突出,证明了其通过反思机制优化探索策略的有效性。
中文摘要
摘要:现有的网络代理通常从根 URL 开始探索,这对于具有深层层次结构的复杂网站而言效率低下。由于缺乏对网站结构的整体视图,代理经常陷入导航陷阱、探索无关分支,或在有限的预算内无法到达目标信息。我们提出了 Mango,一种利用网站结构动态确定最佳起始点的多智能体网络导航方法。我们将 URL 选择建模为多臂老虎机问题,并采用 Thompson 采样算法自适应地在候选 URL 之间分配导航预算。此外,我们引入了一个情节记忆组件以存储导航历史,使代理能够从先前的尝试中学习。在 WebVoyager 上的实验表明,Mango 在使用 GPT-5-mini 时取得了 63.6% 的成功率,优于最佳基线 7.3%。此外,在 WebWalkerQA 上,Mango 达到了 52.5% 的成功率,超越最佳基线 26.8%。我们还通过使用开源和闭源模型作为骨干,展示了 Mango 的泛化能力。我们的数据和代码已开源,可在 https://github.com/VichyTong/Mango 获取。
Paper Key Illustration
原文
Mango: Multi-Agent Web Navigation via Global-View Optimization
Abstract: Existing web agents typically initiate exploration from the root URL, which is inefficient for complex websites with deep hierarchical structures. Without a global view of the website’s structure, agents frequently fall into navigation traps, explore irrelevant branches, or fail to reach target information within a limited budget. We propose Mango, a multi-agent web navigation method that leverages the website structure to dynamically determine optimal starting points. We formulate URL selection as a multi-armed bandit problem and employ Thompson Sampling to adaptively allocate the navigation budget across candidate URLs. Furthermore, we introduce an episodic memory component to store navigation history, enabling the agent to learn from previous attempts. Experiments on WebVoyager demonstrate that Mango achieves a success rate of 63.6% when using GPT-5-mini, outperforming the best baseline by 7.3%. Furthermore, on WebWalkerQA, Mango attains a 52.5% success rate, surpassing the best baseline by 26.8%. We also demonstrate the generalizability of Mango using both open-source and closed-source models as backbones. Our data and code are open-source and available at https://github.com/VichyTong/Mango.
链接:https://arxiv.org/pdf/2604.18779
AI 深度解读
本文构建了一套基于粗糙集理论的模型图谱,旨在系统梳理粗糙集范式的理论扩展与应用路线,而非单纯开发单一算法。研究首先从经典 Pawlak 粗糙集出发,利用等价关系定义下、上近似以刻画概念的不确定性,并通过医疗分诊案例展示了其在处理信息缺失时的边界区域含义。在此基础上,文章将粗糙集理论进行了多维度的广义扩展:在粒度机制上,涵盖了基于相似度的容差关系、基于距离的邻域关系以及允许重叠的覆盖关系,以适应连续属性或噪声数据;在语义表示上,从经典的二值逻辑延伸至模糊集、直觉模糊集、 neutrosophic 集及 plithogenic 集,以分别处理模糊性、犹豫度及矛盾性;在输出形式上,除了传统的近似区域,还重点探讨了属性约简、规则归纳及排序决策等应用方向。此外,针对动态流数据,提出了增量更新机制。该研究通过建立“粒度 – 语义 – 输出”的三维选择指南,为不同数据条件(如严格分类、噪声容忍、重叠分组、不确定性建模及动态环境)下的粗糙集模型选型提供了系统的理论依据与实践指引,明确了各类模型在特征选择、可解释性规则挖掘及风险排序等场景中的适用性。
中文摘要
摘要:粗糙集理论通过不可分辨性诱导的下近似集和上近似集,或更一般地通过数据表中的粒化关系来对不确定性进行建模。这一视角捕捉了由观测分辨率有限所导致的模糊性,并支持关于哪些内容可以确定无疑地判定、哪些内容仅可能成立的集合论推理。本书旨在作为模型地图,而非深入探讨单一算法流程,而是系统综述粗糙集的主要范式及其扩展路径。具体而言,代表性变体按照(i)底层粒化机制(如基于等价关系、容忍关系、覆盖关系、邻域关系以及概率近似)和(ii)附加于数据与关系的不确定性语义(如经典、模糊、直觉模糊、中性及Plithogenic设置)进行组织。本书还阐释了每种选择如何改变近似的形式以及对边界区域的解释。全书辅以小型示例,以阐明建模意图以及在分类与决策支持中的典型应用场景。最后,需特别说明本书的范围:由于本书的主要目的是提供模型地图,摘要与引言不应引导读者预期特征约简与规则归纳为主要目标。尽管这些主题在粗糙集文献中居于核心地位,但本书将其主要视为激励性应用及进入更广泛研究领域的入口。本书的根本宗旨在于以系统且连贯的方式综述并定位粗糙集模型及其扩展。

Paper Key Illustration
原文
Handbook of Rough Set Extensions and Uncertainty Models
Abstract: Rough set theory models uncertainty by approximating target concepts through lower and upper sets induced by indiscernibility, or more generally, by granulation relations in data tables. This perspective captures vagueness caused by limited observational resolution and supports set-theoretic reasoning about what can be determined with certainty and what remains only possible. This book is written as a map of models. Rather than developing a single algorithmic pipeline in depth, it provides a systematic survey of the main rough set paradigms and their extension routes. More specifically, representative variants are organized according to (i) the underlying granulation mechanism, such as equivalence-based, tolerance-based, covering-based, neighborhood-based, and probabilistic approximations, and (ii) the uncertainty semantics attached to data and relations, such as crisp, fuzzy, intuitionistic fuzzy, neutrosophic, and plithogenic settings. The book also explains how each choice changes the form of approximations and the interpretation of boundary regions. Throughout the book, small illustrative examples are used to clarify modeling intent and typical use cases in classification and decision support. Finally, an important clarification of scope should be noted. Since the main purpose of this book is to provide a map of models, the Abstract and Introduction should not lead readers to expect that feature reduction and rule induction are primary objectives. Although these topics are central in the rough set literature, they are treated here mainly as motivating applications and as entry points to the broader research landscape. The principal aim of the book is to survey and position rough set models and their extensions in a systematic and coherent manner.
链接:https://arxiv.org/pdf/2604.19794
AI 深度解读
本文针对下一点兴趣(POI)推荐任务,提出了一种名为 CaST-POI 的候选条件化时空排序模型。研究指出,传统方法往往采用‘候选无关’的架构,即使用单一固定的用户表示来同时评估所有候选 POI,这忽略了历史访问与不同候选地点之间存在的细微时空偏好差异。为此,论文构建了候选条件化的注意力机制,将候选 POI 作为查询(Query),历史轨迹作为键(Key)和值(Value),通过交叉注意力机制动态地从同一历史轨迹中检索与特定候选相关的偏好证据。该方法引入了候选相对的时间间隔(Δ𝑡𝑖)和空间距离(Δ𝑑𝑖(𝑐))作为偏置项,使得模型能够根据候选地点的不同,对历史访问赋予差异化的注意力权重。这种设计突破了传统架构的局限,能够更精细地建模人类移动行为中的时空偏好,从而提升推荐准确性。
中文摘要
摘要:下一兴趣点(POI)推荐在位置服务中通过预测用户未来的移动模式发挥着至关重要的作用。现有方法通常基于历史轨迹计算单一的用户表示,并以此对所有候选 POI 进行统一评分。然而,这种与候选对象无关的范式忽视了历史访问的相关性本质上取决于所评估的候选对象这一事实。本文提出了 CaST-POI,一种用于下一 POI 推荐的候选条件时空模型。我们的核心洞察在于,在评估不同候选 POI 时,相同的用户历史应被赋予不同的解释。CaST-POI 采用候选条件序列读取器,利用候选对象作为查询,动态地关注用户历史。此外,我们引入了候选相对时空偏差,以捕捉基于历史访问与每个候选 POI 之间关系的细粒度移动模式。在三个基准数据集上的广泛实验表明,CaST-POI consistently 优于最先进的方法,在多个评估指标上取得了显著提升,尤其在候选池较大的情况下优势尤为明显。代码可在 https://github.com/YuZhenyuLindy/CaST-POI.git 获取。
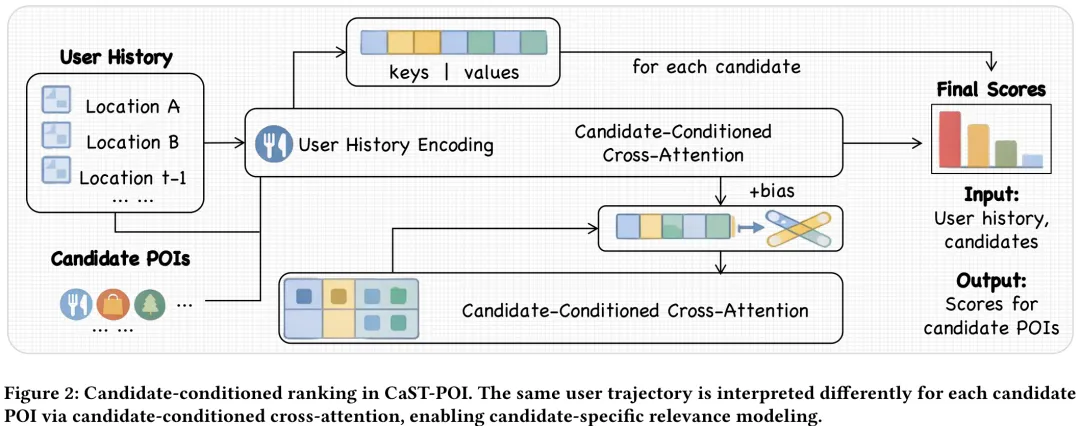
Paper Key Illustration
原文
CaST-POI: Candidate-Conditioned Spatiotemporal Modeling for Next POI Recommendation
Abstract: Next Point-of-Interest (POI) recommendation plays a crucial role in location-based services by predicting users’ future mobility patterns. Existing methods typically compute a single user representation from historical trajectories and use it to score all candidate POIs uniformly. However, this candidate-agnostic paradigm overlooks that the relevance of historical visits inherently depends on which candidate is being evaluated. In this paper, we propose CaST-POI, a candidate-conditioned spatiotemporal model for next POI recommendation. Our key insight is that the same user history should be interpreted differently when evaluating different candidate POIs. CaST-POI employs a candidate-conditioned sequence reader that uses candidates as queries to dynamically attend to user history. In addition, we introduce candidate-relative temporal and spatial biases to capture fine-grained mobility patterns based on the relationships between historical visits and each candidate POI. Extensive experiments on three benchmark datasets demonstrate that CaST-POI consistently outperforms state-of-the-art methods, yielding substantial improvements across multiple evaluation metrics, with particularly strong advantages under large candidate pools. Code is available at https://github.com/YuZhenyuLindy/CaST-POI.git.
链接:https://arxiv.org/pdf/2604.20845
AI 深度解读
AtomicRAG 针对传统检索增强生成中知识碎片化与语义漂移问题,提出了一种基于‘原子 – 实体图’(Atom-Entity Graph, AEG)的架构。该方法首先将文档解析为上下文完整、非指代的‘知识原子’,并聚合实体构建异构图。图结构包含三种边:连接原子与提及实体的‘包含边’、基于共现关系类型数量构建的‘相关边’、以及基于向量相似度连接的‘同义边’。在检索阶段,系统通过原子级问题分解将复杂查询拆解为子问题,利用个人化 PageRank 在 AEG 上进行无标签的信号传播,实现多跳证据的软性关联。最终通过‘原子筛’过滤与合并检索到的原子,生成基于事实的紧凑上下文以支持答案生成。该研究证明了原子化表示与图传播机制能显著提升检索的鲁棒性与效率,有效解决了多跳推理中的证据组织难题。
中文摘要
摘要:近期的 GraphRAG 方法将图结构融入文本索引与检索中,利用知识图谱三元组连接文本片段,从而提升了检索覆盖率和精度。然而,我们观察到,将文本片段 rigidly(刚性)地作为知识表示的基本单位,会将多个原子事实捆绑在一起,限制了支持多样化检索场景所需的灵活性与适应性。此外,基于三元组的实体链接对关系抽取错误较为敏感,可能导致推理路径缺失或错误,最终损害检索准确性。为解决这些问题,我们提出了原子实体图(Atom-Entity Graph),这是一种更为精确可靠的知识表示与索引架构。在我们的方法中,知识以“知识原子”的形式存储,即独立、自包含的事实信息单元,而非粗糙的文本片段。这使得知识元素能够灵活重组且互不干扰,从而实现与多样化查询视角的无缝对齐。实体间的边仅表示关系是否存在。通过结合个性化 PageRank 与基于相关性的过滤,我们保持了准确的实体连接并提升了推理的可靠性。理论分析与在五个公开基准上的实验表明,所提出的 AtomicRAG 算法在检索准确性和推理鲁棒性方面均优于强大的 RAG 基线方法。代码:https://github.com/7HHHHH/AtomicRAG。
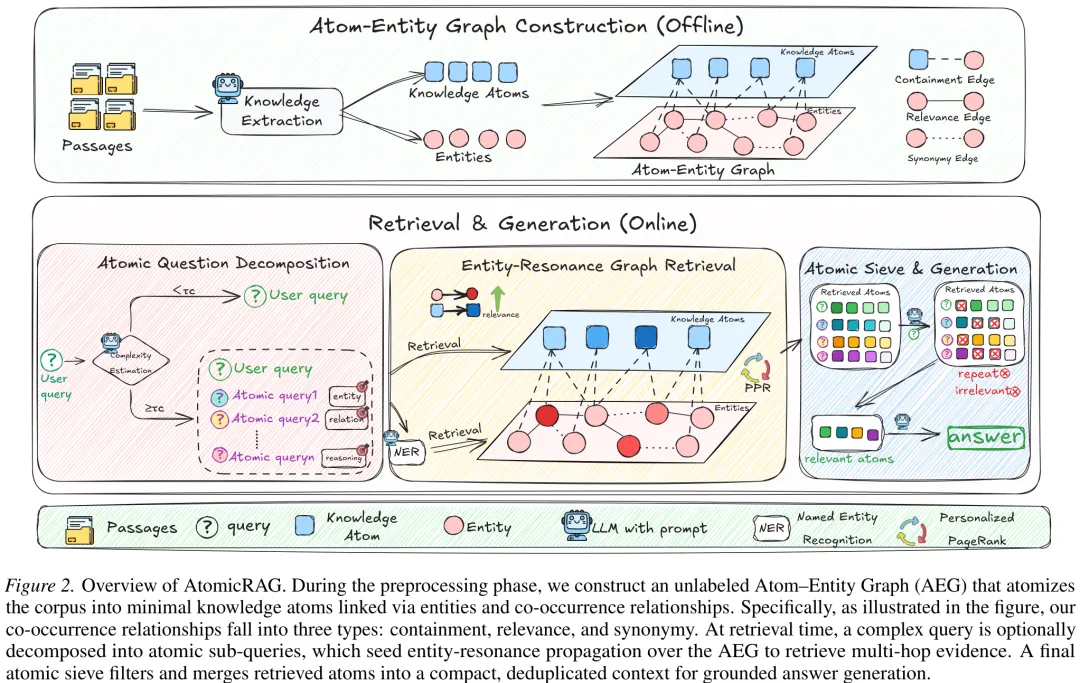
Paper Key Illustration
原文
AtomicRAG: Atom-Entity Graphs for Retrieval-Augmented Generation
Abstract: Recent GraphRAG methods integrate graph structures into text indexing and retrieval, using knowledge graph triples to connect text chunks, thereby improving retrieval coverage and precision. However, we observe that treating text chunks as the basic unit of knowledge representation rigidly groups multiple atomic facts together, limiting the flexibility and adaptability needed to support diverse retrieval scenarios. Additionally, triple-based entity linking is sensitive to relation-extraction errors, which can lead to missing or incorrect reasoning paths and ultimately hurt retrieval accuracy. To address these issues, we propose the Atom-Entity Graph, a more precise and reliable architecture for knowledge representation and indexing. In our approach, knowledge is stored as knowledge atoms, namely individual, self-contained units of factual information, rather than coarse-grained text chunks. This allows knowledge elements to be flexibly reassembled without mutual interference, thereby enabling seamless alignment with diverse query perspectives. Edges between entities simply indicate whether a relationship exists. By combining personalized PageRank with relevance-based filtering, we maintain accurate entity connections and improve the reliability of reasoning. Theoretical analysis and experiments on five public benchmarks show that the proposed AtomicRAG algorithm outperforms strong RAG baselines in retrieval accuracy and reasoning robustness. Code: https://github.com/7HHHHH/AtomicRAG.
链接:https://arxiv.org/pdf/2604.20844
Subscribe to arXiv’s Daily Preprint Notifications