 夜雨聆风
夜雨聆风





阿里AI工程师面试题–说一下RadixAttention
这个系列会通俗易懂的拆解跟LLM相关的核心问题和原理,适合求职者也适合小白从0️⃣理解大模型,所以以问问题的形式来说,每篇一个问题。
昨天爆肝写了Chunked Prefill,搞太晚了,今天写的有点吃力了,写完这篇,后面缓两天。今天继续拆解SGLang中叫RadixAttention的东西。
刚开始我寻思了一下,这不就是个KV缓存的前缀匹配吗,没什么好写的。然后我仔细看了代码,看到了那个基数树的节点分裂逻辑,有点牛逼。这个设计比我想象的精巧得多。我先说背景,大模型推理的时候,有一个非常耗资源的中间结果,叫KV缓存。你可以把它理解为模型的记忆。每个token经过Transformer计算后,都会产生一组Key和Value向量,存起来供后续的Attention计算使用。问题在于,这个KV缓存太大了,一个token在Llama 70B模型上大概要占1MB多的显存。你想想看,如果你有两个请求,prompt前面有90%是相同的内容,比如都是同一份长文档,只有最后的问题不一样。如果每个请求都从头算一遍KV缓存,那前面90%的KV是重复计算的,纯纯浪费算力和显存。所以直觉上的做法是,把已经算过的KV缓存存起来,新请求来了先看看有没有可以复用的前缀。但直觉归直觉,怎么实现是一个很讲究的事。SGLang用的是基数树,英文叫Radix Tree。这玩意跟字典树Trie是亲戚,但有一个关键区别,它不是每个字符一个节点,而是把连续没有分叉的路径压缩成一个节点。这样做的好处是,共享前缀越长,树的深度越浅,查找越快。
例子来了。先上图,又爆肝了
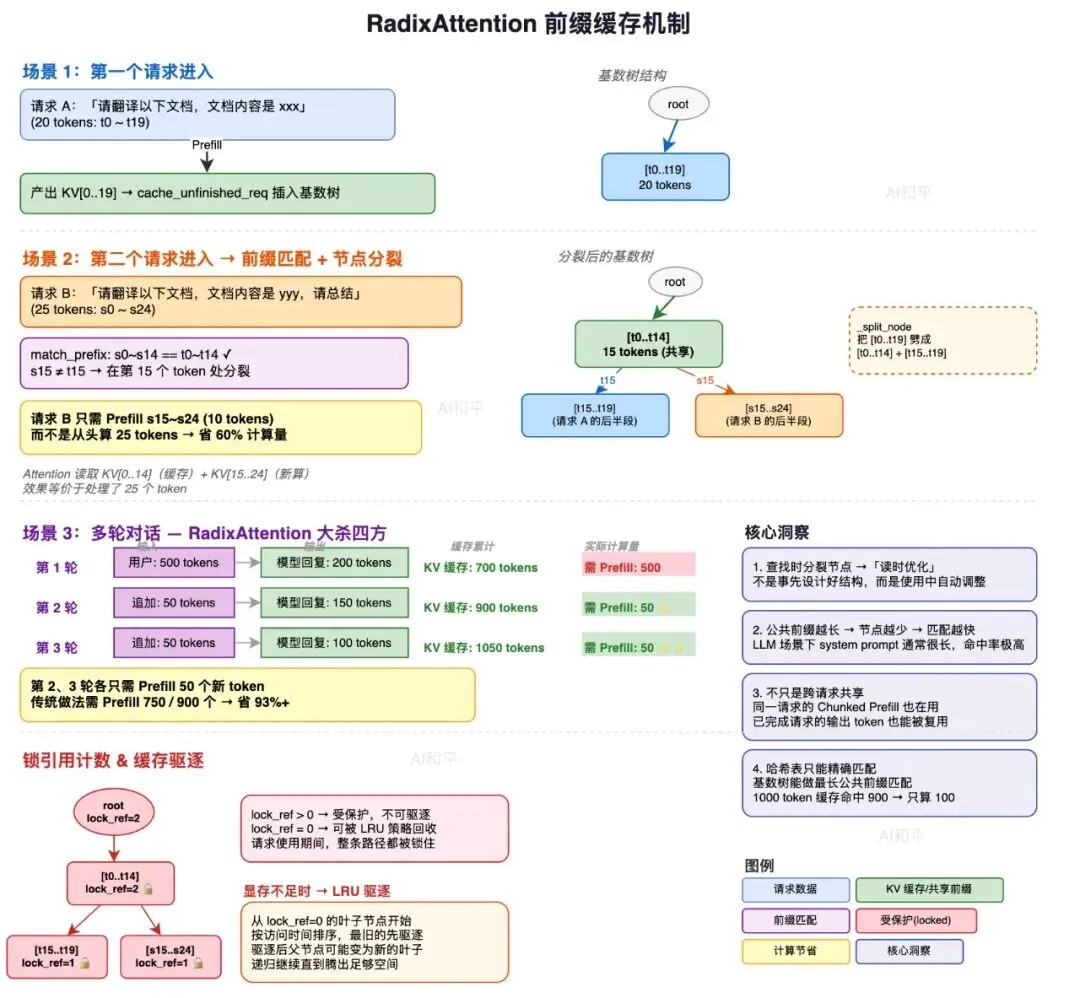
假设第一个请求进来,prompt是“请翻译以下文档,文档内容是xxx“,这段话被分词后假设变成了20个token,记作t0到t19。GPU跑完prefill,产生了20个token的KV缓存。然后cache_unfinished_req被调用,这20个token的KV索引就被插入基数树。树的结构很简单,根节点下面挂着一个节点,这个节点的key是[t0, t1, …, t19],value是这20个token对应的KV缓存在显存池中的位置索引。
现在第二个请求来了,prompt是“请翻译以下文档,文档内容是yyy,请总结“。这段话假设是25个token,记作s0到s24。调度器在init_next_round_input里调用match_prefix,在基数树里找最长公共前缀。match_prefix的查找逻辑是这样的,从根节点开始,用key的前几个token去匹配子节点的key。如果子节点的key被完全匹配上了,就沿着这条路径继续往下走。如果匹配到某个位置发现分叉了,就把这个节点劈开。在这个例子里,s0到s19和t0到t19进行比较。假设前15个token完全相同,s15开始不一样了,那查找到第15个位置时发现key不匹配了。牛逼的地方就在于,基数树不是简单地返回匹配了15个token,完事。它会执行一个_split_node操作,把原来的节点[t0, t1, …, t19]从第15个位置劈成两半。上半部分变成一个新节点[t0, t1, …, t14],下半部分是原来节点的后半段[t15, …, t19],作为新节点的子节点。劈完之后,树的结构变成了,根节点下面挂着节点[t0, …, t14],这个节点有两个子节点,一个是[t15, …, t19](来自第一个请求),另一个会在后续插入时创建,是[s15, …, s24](来自第二个请求的新部分)。
为什么要劈?因为这样后续再有请求来,如果也是以「请翻译以下文档」开头,就不需要从头到尾线性扫描了。基数树会直接定位到[t0, …, t14]这个公共节点,然后只对剩余部分做匹配。公共前缀越长,匹配越快,而且这种劈开的操作是增量式的,每次只劈一次,树的形态随着请求的增多自动优化。这个设计太骚了。说真的,我一开始以为前缀缓存就是搞个哈希表,key是token序列,value是KV索引。后来发现哈希表的问题在于,它只能做精确匹配,不能做最长公共前缀匹配。你有一个1000 token的缓存,新请求的前900个token和它一样,哈希表只能告诉你「没命中」,因为key不一样。但基数树可以告诉你「命中了900个,只有最后100个需要重新算」。这个差距不是一点半点。
说到这个,还有一个细节特别有意思。基数树的节点有一个lock_ref字段,叫锁引用计数。当一个请求正在使用某个节点的KV缓存时,从那个节点到根节点路径上所有节点的lock_ref都会加1。这意味着这些节点的KV缓存是被保护的,不会被驱逐。只有lock_ref为0的叶子节点才会被列入驱逐候选。如果一个请求正在decode阶段,它的KV缓存突然被驱逐了,那模型生成出来的就是乱码。锁引用计数机制保证了正在使用的KV缓存绝对安全,同时允许没人在用的旧缓存被自动回收。驱逐策略也是可配置的,SGLang支持LRU、LFU、FIFO这些策略。默认用的是LRU,也就是最近最少使用的先被驱逐。显存不够的时候,调度器从叶子节点开始,按优先级堆排序,把最不重要的KV缓存释放掉。
看完这些代码之后,我对前缀缓存这四个字的认知完全变了。之前我觉得前缀缓存就是一个优化手段,用空间换时间。现在我觉得它更像是一种记忆管理。模型的KV缓存就是它的记忆,基数树就是这个记忆的索引结构。请求来的时候查记忆,有的直接用,没有的算完存起来。请求走的时候释放记忆,但不能释放别人还在用的。显存紧张的时候淘汰最不重要的记忆,跟人类大脑的遗忘机制异曲同工。这不是我硬升华,人类的记忆也不是什么都记,而是把常用的、重要的记住,不常用的逐渐遗忘。基数树的LRU驱逐策略干的就是这件事。而且人类的记忆也是有关联结构的,提到昨天晚饭会连带想起那家餐厅,基数树里共享前缀的节点也是这种关联结构,一条路径被访问,同一条路径上的所有节点都更新了访问时间。
还有一个让我觉得特别优雅的地方,是基数树跟Chunked Prefill的配合。一个长请求被拆成多个chunk做prefill,每个chunk做完之后cache_unfinished_req把当前进度的KV缓存插入基数树。下一个chunk开始前init_next_round_input做前缀匹配,自动找到上一次插入的缓存位置。整个过程不需要任何额外的协调逻辑,基数树本身就是协调者。
RadixAttention就是这样,用一个基数树管理KV缓存的生命周期,插入、查找、分裂、驱逐,每个操作都是O(k)的复杂度,k是key的长度。没有任何花活,但组合起来就能解决前缀共享、自动分裂、安全驱逐这三个看似互相矛盾的需求。
终于写完了,你读到这儿就给个关注吧~