 夜雨聆风
夜雨聆风





Celestial AI最新白皮书解析:光互连如何打破“内存墙”,重塑AI大模型训练与推理的未来
Celestial AI最新白皮书解析:光互连如何打破“内存墙”,重塑AI大模型训练与推理的未来
在生成式AI(GenAI)爆发的当下,大模型的参数规模正以指数级速度增长,从百亿到千亿,甚至向万亿进发。然而,硬件的发展却面临着“线性缩放”的瓶颈。传统的GPU加速器设计,受限于“硅海滩”(Silicon Beachfront)的物理极限,其计算与内存的比例是固定的,这成为了制约AI集群扩展的“阿喀琉斯之踵”。
今天,我们将深入解读Celestial AI发布的技术白皮书《Photonic Fabric Platform for AI Accelerators》,探讨一种名为Photonic Fabric™(光织物)的创新架构,是如何通过光互连技术打破这一瓶颈,为大模型训练和推理带来颠覆性性能提升的。
1. 现状与挑战:为什么我们需要“光”?
目前的数据中心主要依赖两种网络架构:Scale-up(单节点内扩展)和Scale-out(跨节点扩展)。
•Scale-up的困境:虽然单节点拥有高带宽和低延迟,但受限于物理封装,无法容纳动辄万亿参数的巨型模型。•Scale-out的痛点:虽然可以通过堆砌节点来扩容,但随之而来的是高昂的通信开销。无论是InfiniBand还是以太网,其能耗和延迟都随着节点增加而激增。
核心矛盾在于: 现有的电子互连技术(如NVLink、PCIe)在能效和带宽密度上已经接近物理极限,无法满足大模型训练中频繁的集体通信(Collective Operations)需求。
为此,Celestial AI提出了Photonic Fabric Appliance™ (PFA) —— 一种机架级的光互连存储与计算系统。
2. 核心架构:PFA如何工作?
PFA的核心理念是“内存与计算的解耦”。它不再将内存死死地绑在GPU旁边,而是通过光互连构建一个巨大的共享内存池。
2.1 硬件基石:光互连模块 (PFM) PFA的基本单元是Photonic Fabric Module™ (PFM)。它采用了一种独特的2.5D封装技术:
•有源光中介层(Active Photonic Interposer):使用了锗硅(GeSi)电吸收调制器(EAM),相比传统的微环谐振器,它具有极佳的热稳定性。•混合集成:将定制的ASIC芯片、两堆HBM3E内存集成在同一封装内。•优势:这种设计消除了数字信号处理(DSP)的开销,相比传统的长距离SerDes,功耗大幅降低。
2.2 系统规格:海量内存与超高带宽 一个标准的PFA机柜包含16个PFM模块,其规格令人震撼:
| 关键指标 | 规格参数 |
| 共享内存容量 | 高达 32 TB (DDR5) |
| 内存带宽 | 全HBM3E带宽 (HBM作为DDR5的缓存) |
| 交换带宽 | 115 Tbps 全对全数字交换 |
| 连接能力 | 支持16个XPU(GPU/TPU等)全对全连接 |
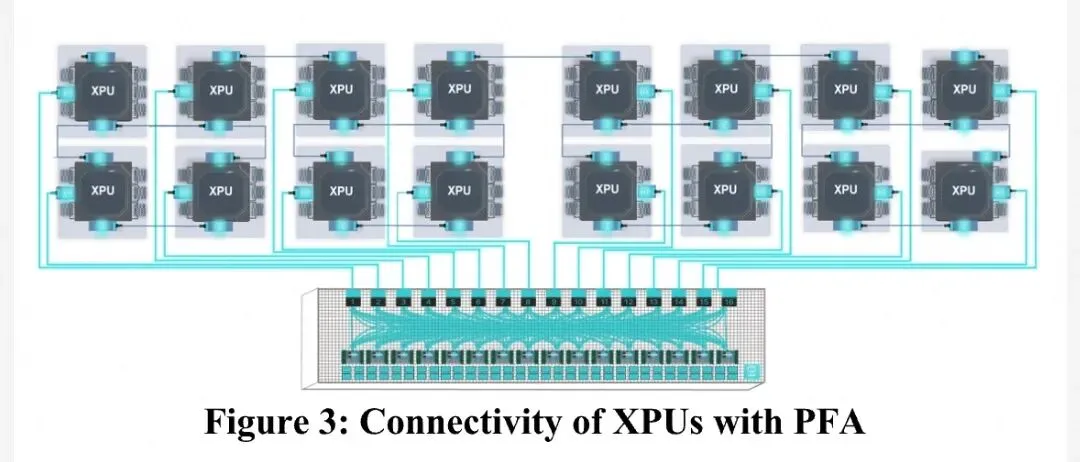
技术亮点:PFA让每个连接的XPU都能以HBM级别的带宽访问这32TB的共享内存。这意味着,原本受限于单卡显存大小(如H100的80GB)的模型,现在可以轻松加载千亿甚至万亿参数,而无需复杂的模型并行切分。
3. 实测数据:性能与能效的双重飞跃
为了验证PFA的效果,Celestial AI开发了一款名为CelestiSim的轻量级分析模拟器。该模拟器基于NVIDIA H100/H200的实际微基准测试数据进行了校准,能够准确预测Transformer模型在不同架构下的表现。
3.1 大模型推理:吞吐提升7倍 在LLM推理场景下,PFA展现了惊人的扩展能力。
•4050亿参数模型:相比传统的DGX H100集群,PFA实现了 3.66倍 的吞吐量提升和 1.40倍 的延迟降低。•1万亿参数模型:性能提升更为显著,吞吐量提升达到 7.04倍,延迟降低 1.41倍。
原因分析: 推理过程中的“解码(Decode)”阶段是典型的“内存受限(Memory-bound)”操作。PFA提供的巨大内存池和高带宽,消除了传统架构中因张量并行(Tensor Parallelism)带来的通信开销和冗余内存访问。
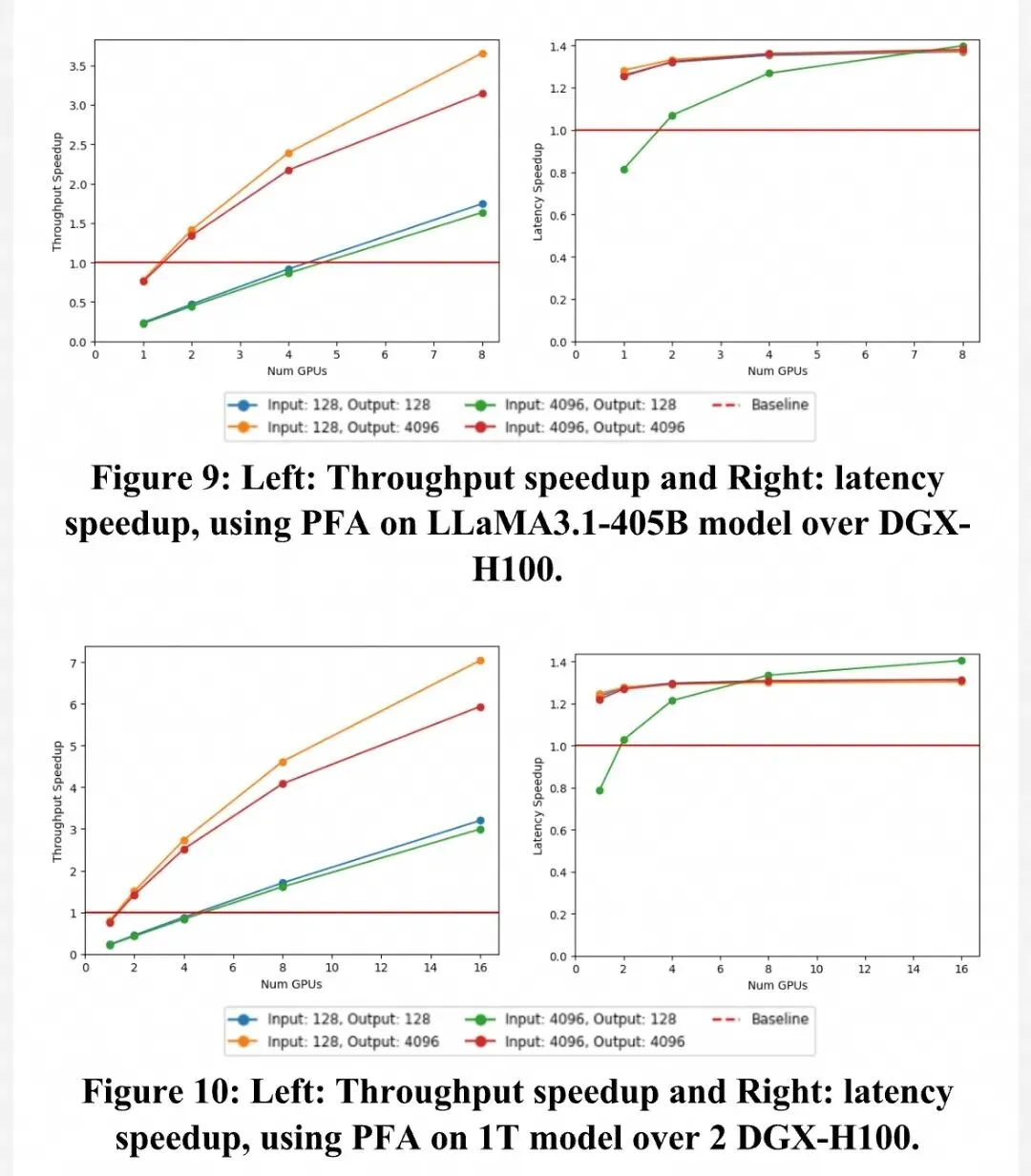
1T参数模型推理性能对比图
3.2 大模型训练:能耗降低90% 在预训练(Pre-training)场景中,通信是最大的能耗来源。
•能效对比:相比传统的以太网Clos拓扑结构,PFA在通信相关的功耗上降低了 60% – 90%。•并行策略优化:在张量并行(TP)和流水线并行(PP)场景下,PFA均能实现约80%的能效节省。
3.3 推荐系统:DLRM性能提升22倍 对于拥有超大Embedding表的推荐系统(如DLRM模型),PFA同样表现出色。模拟结果显示,相比NVLink连接的GPU集群,PFA能带来 22.8倍 的性能提升。
4. 深度解析:为什么PFA能消除瓶颈?
通过分析LLaMA-70B的推理过程,我们可以看到PFA解决的两个核心问题:
1.
消除张量并行(TP)开销: 在传统架构中,为了将大模型塞进有限的显存,必须使用TP将模型切分到多个GPU上。这导致了频繁的All-Reduce通信。PFA的大内存容量允许模型在更少的节点上运行,甚至单节点运行,从而直接砍掉了这部分通信延迟。
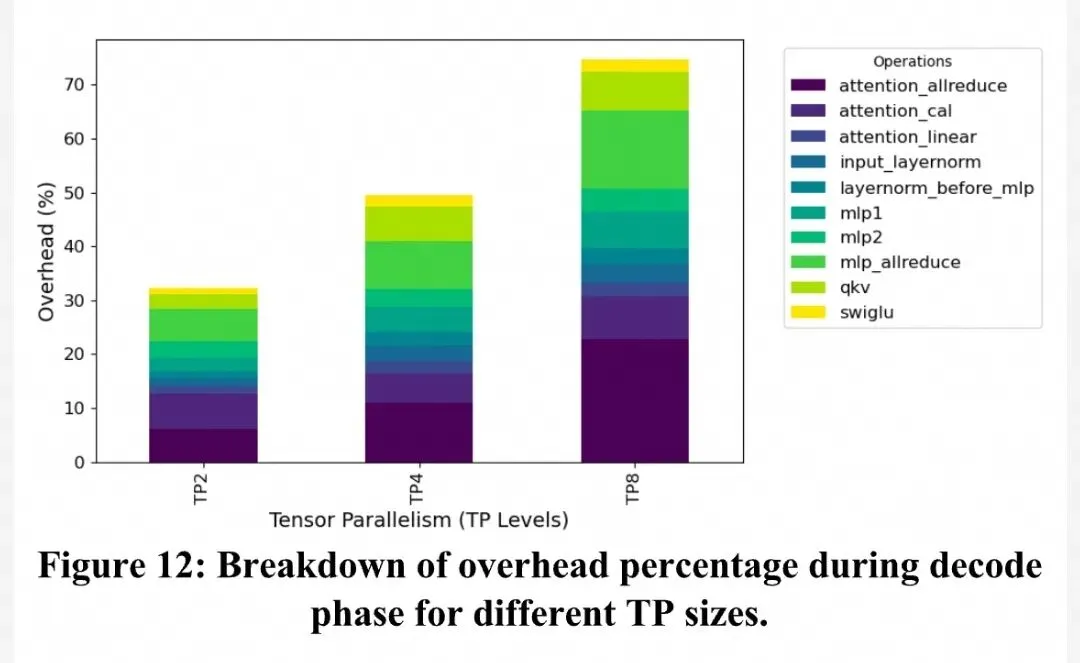
不同TP规模下的开销分析
2.
解决KV Cache瓶颈: 在长文本生成(Decode阶段)时,Key-Value Cache的大小随序列长度线性增长,迅速耗尽HBM显存。PFA利用HBM作为缓存,DDR5作为底层存储,以HBM级别的带宽访问海量参数,完美解决了这一“内存墙”问题。
5. 结语
Celestial AI的Photonic Fabric平台不仅仅是一个更快的交换机,它代表了一种全新的AI系统设计理念:通过光互连实现内存与计算的解耦。
虽然目前的数据主要基于模拟器(CelestiSim),但其揭示的趋势是明确的:随着模型规模的不断扩大,电子互连的能耗和带宽瓶颈将愈发严重。光互连技术(PFA)通过提供近乎无限的带宽密度和极低的每比特能耗,为下一代万亿参数级别的AI大模型提供了一条可行的演进路径。
对于AI硬件工程师和架构师而言,关注光互连技术的落地,将是未来几年保持技术领先的关键。
注:本文数据及图表均基于Celestial AI白皮书《Photonic Fabric Platform for AI Accelerators》精简整理而得。