 夜雨聆风
夜雨聆风





OpenClaw Token 优化实战:省下来的钱够养三只龙虾
一、背景:Token消耗的滚雪球困局
三月份刚开始使用 OpenClaw 的时候,遇到的问题和大多数用户一样,Token消耗越来越高,像滚雪球一样停不下来。
一开始只是简单对话,每天花几块钱。但随着使用加深、Agent配置增多,对话上下文越来越多,每次请求都要把完整的对话历史重新发送一遍。到三月份中下旬,即便只是简单的日常使用,一天的Token消耗都能冲到二十多块。
从 DeepSeek 后台的消耗数据来看,三月份的峰值触目惊心。下面是峰值最高的四天数据:
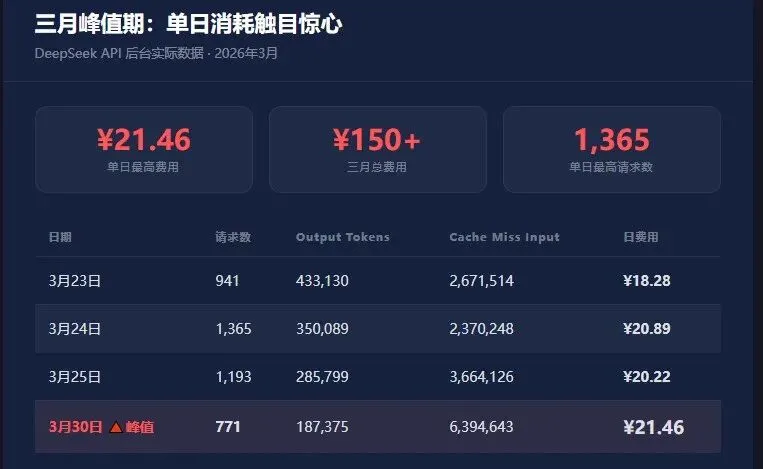
三月份整个月的总费用超过了150元,最高单日达到21.46元。虽然不是动辄上百,但对于个人使用和开发测试来说,这笔开销也足够让每次打开API后台时心里咯噔一下。
问题的根源其实很简单。OpenClaw 作为 Agent 框架,每轮对话都会携带完整的会话历史。你聊得越多,历史越长,要付的Token就越多。而且 Agent 模式下,一次任务要跑5到10个来回,每次都是满负荷发送。
好在那时候看到两篇知乎文章,给了我完整的优化方向。我对三台主机上的 OpenClaw 配置进行了系统性调优。
更新之后的成效非常显著,四月份的总费用不到三月份的一半,日均消耗从6到7元降到了3到4元。省下来的钱,够养三只小龙虾了。
二、四大核心优化配置
以下是我在三台设备上实际套用的配置方案。先说结论,再贴配置。
2.1 Compaction(会话压缩)
Compaction 是 OpenClaw 内置的会话压缩机制。它会将会话历史浓缩成摘要,存储到 JSONL 文件中,而不是每次都把原始对话全部塞给模型。
配置原理:Compaction 有多种模式可选。最初我使用的是 safeguard 模式,这个模式会将超长历史拆分成多个分块分别进行摘要,再合并成完整摘要。好处是能处理超长会话,避免单次摘要请求超出上下文限制,但代价是多次调用 LLM 生成摘要,Token 消耗更大,延迟也更高。
我的配置(三台主机统一):
"compaction": {"mode": "default","memoryFlush": {"enabled": true,"softThresholdTokens": 30000,"prompt": "将本次会话中的关键决策、代码变更、阻塞项提取到 memory/YYYY-MM-DD.md,如果没有值得保存的内容则输出 NO_FLUSH","systemPrompt": "只提取值得记住的内容,不要冗余信息。使用中文。"}}
效果:开启 Memory Flush 后,Agent 在压缩前会自动提取重要信息写到每日笔记中,无用的对话历史被压缩掉,但关键决策和代码变更不会丢。softThresholdTokens 设为 30000,针对128K上下文窗口来说是一个比较合理的触发阈值,约在窗口上限的23%开始准备,留够了余量。
2.2 Context Pruning(上下文修剪)
这是很多用户最容易忽视的配置。Pruning 和 Compaction 不同。Compaction 是永久性操作,把对话写成摘要。而 Pruning 是临时性操作,在每次请求构建时修剪内存中的上下文,对存储没有影响。
配置原理:mode: “cache-ttl” 表示基于时间的淘汰策略,超过 TTL 的消息会被修剪。ttl: “4h” 即4小时前的消息自动剪掉。keepLastAssistants: 3 表示始终保留最近3条 Assistant 回复。
我的配置(三台主机统一):
"contextPruning": {"mode": "cache-ttl","ttl": "4h","keepLastAssistants": 3}
效果:这个配置看起来不起眼,实际上省得非常狠。如果没有 Pruning,几小时前读取的大文件内容会一直原样留在上下文里,但那些内容对当前对话已经没有意义了。设置4小时TTL后,长期运行的会话不会无限膨胀,系统会自动裁剪那些过期的历史消息。
2.3 Subagent 并发控制
Subagent 是 OpenClaw 的一个核心特性,每个子任务独立维护自己的对话上下文窗口。但默认配置下,并发数过高会导致Token消耗暴增。
三台主机的差异化配置:
233(Windows 主开发机),maxConcurrent设为4,subagents.maxConcurrent设为8,因为它承担了主要的开发工作,需要更高的并行度。
214(Windows 笔记本),maxConcurrent设为4,subagents.maxConcurrent设为4,只做轻量任务,4个就够了。
247(Ubuntu 服务器),未显式设置,使用 OpenClaw 默认值。
效果:过高的并发数意味着同一时刻有更多的上下文窗口在消耗Token,合理限制后,并发消耗被控制在可承受范围内。
2.4 Heartbeat 配置(心跳优化)
Heartbeat 是 OpenClaw 的定时轮询机制。如果没有正确配置,Agent 每30分钟甚至更短时间就会自动唤醒一次,每次都会消耗Token。
三台主机的配置对比:
233主机,心跳完全关闭,直接通过配置 heartbeat 的 target 设为 none 来实现。
214笔记本,未配置 heartbeat,使用默认值。
247服务器,使用本地 Ollama 模型 qwen2.5:1.5b 来跑心跳,每30分钟一次。本地推理不消耗 API Token,是开源节流的好方案。
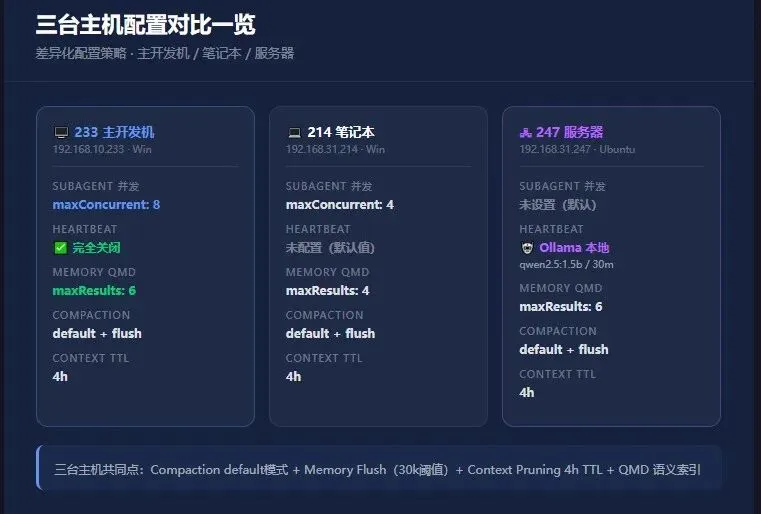
效果:233 主机直接关闭了 Heartbeat,彻底避免了因心跳轮询产生的Token消耗。247 服务器因为需要定时监控,使用本地小模型来跑 Heartbeat,一分钱不花。
2.5 模型选择和成本配置
一个值得注意的点,主模型的选择直接影响Token成本。
配置文件里只对 deepseek-reasoner 设置了具体成本,input为0.28,output为0.42。而 deepseek-chat 的成本全设为0,这个设置不影响实际计费,DeepSeek API 后台会按实际用量扣费。
补充一点背景:DeepSeek API 自身有 Prompt Caching 机制,这个是服务端的功能,跟 OpenClaw 本地配置无关。只要重复发送相同的上下文前缀,API 就会自动命中缓存,费用按缓存价计算而非全价。所以即使三月份还没配置 QMD 和 Compaction,从 CSV 数据看 Cache Hit 比率依然很高——以3月30日为例,Cache Hit 高达4052万个token,而 Cache Miss 只有639万个token。这部分节省是 DeepSeek 服务端自动完成的。
另外,DeepSeek 在4月24日发布了 V4 Flash 模型(deepseek-v4-flash),input价格更低。最后两天切换到 Flash 模型后,日均费用进一步降到1.63元,不过目前只有两天数据,后续效果还需要观察。
一个小提示:主模型没必要用 deepseek-reasoner,日常对话用 deepseek-chat 就够了。Reasoner 的推理过程本身也要消耗Token,而且对日常任务来说没太大必要。
2.6 Memory 后端:QMD
从配置可以看到,所有主机都统一配置了 QMD 作为 Memory 后端。QMD 通过向量索引和语义检索,只将最相关的记忆注入上下文,而不是一股脑地把所有记忆塞进去。
三台主机的QMD配置有差异:
233主开发机,maxResults设为6,maxSnippetChars设为1200,maxInjectedChars设为2000。配置最宽松,因为主开发机需要更多上下文。
214笔记本,maxResults设为4,maxSnippetChars设为800,maxInjectedChars设为1200。
247服务器,maxResults设为3,maxSnippetChars设为600,maxInjectedChars设为1000。maxSnippetChars最小,单条记忆注入最短,进一步节省Token。
关键在于,配置了 QMD 后,Agent 不再把整个 Memory 文件作为上下文发送,而是智能检索。这一步节省的Token非常可观。
三、优化前后数据对比
3.1 三月份(优化前)峰值期

可以看到,3月19日到25日是Token消耗最严重的时期,日均费用接近12元。3月26日到31日有所回落但仍然波动较大,真正的优化配置是从4月2日开始的。
3.2 四月份(优化后)稳步下降
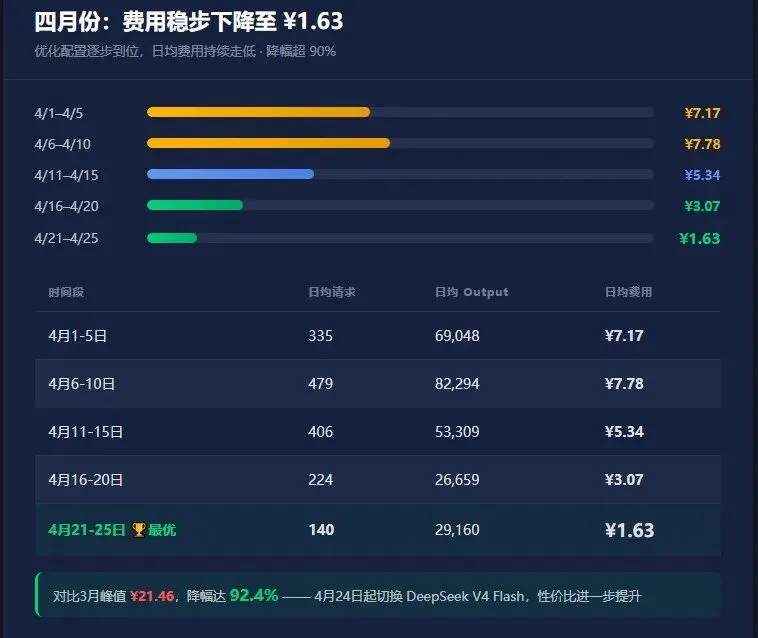
从4月16日起,日均费用已经降到3元左右。4月21日到25日更进一步降到1.63元。对比3月最高峰的20多元每天,下降了超过92%。而且4月24日开始切换到 DeepSeek V4 Flash 模型,每次请求的价格更低,性价比进一步提升。
3.3 Git 提交记录里的优化轨迹
从 Git 提交记录可以看出优化的实施时间线:
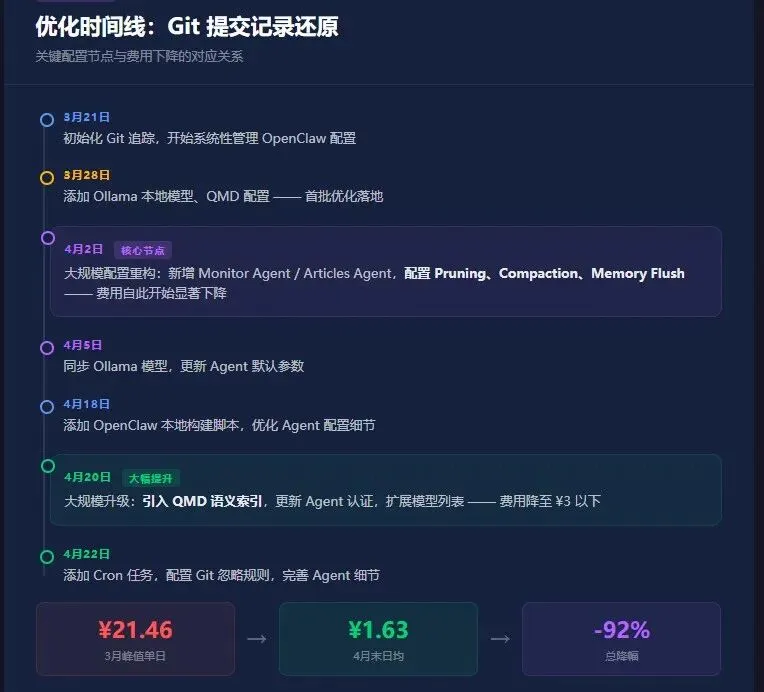
关键的配置节点在4月2日到4月5日之间。这段时期 Compaction、Context Pruning、Memory Flush 被完整配置到位,对应着CSV数据中4月2日后消耗骤降的趋势。
四、总结
经过近一个月的配置调优,三个主机的 OpenClaw 消耗从单日最高21.46元降到了日均3元以下,降幅超过80%。
对于三台主机的综合配置方案,总结了几个关键经验:
第一,Compaction 加 Memory Flush 是核心,必须配合使用,否则压缩会丢失重要信息。
第二,Context Pruning 的 TTL 设为4小时最合适,既能保留当天工作上下文,又不会让历史无限膨胀。
第三,Subagent 并发数按需配置,主开发机开到8,轻量设备维持在4。
第四,Heartbeat 要么关掉,要么用本地模型。不需要定时轮询的设备直接关闭,需要监控的用 Ollama 免费模型。
第五,QMD 注入限制是隐形省Token大户,通过限定 maxResults 和 maxSnippetChars,让 Agent 只携带真正需要的历史记忆。
现在的消耗水平,一天一杯蜜雪冰城都不到。省下来的钱够养三只龙虾了,虽然是小龙虾。
补充说明一下实际使用场景。三台主机的两个月运行下来,主要覆盖了四类工作:
内容分析与创作:公众号文章风格分析、批量文章分类整理、写作技巧提炼、文章撰写与排版、PDF 文档转换等。
日常自动化运维:工作区文件整理归档、Git 版本管理、系统健康检查、监控日报等。
如果你也在用 OpenClaw 做类似的事情——搭建 Agent 平台、用 AI 辅助写文章、跑自动化任务,同样会遇到 Token 消耗过高的问题,上面的配置方案都能帮上忙。
如果你也在用 OpenClaw 并且觉得Token消耗太快,照着上面这些配置走一遍,应该能省下不少。
参考与致谢:
本文的优化方案主要参考了以下两篇知乎文章,它们给了我完整的优化方向和思路,特此感谢:
[OpenClaw小龙虾如何系统性节省Token,有没有可落地的方案?](https://www.zhihu.com/question/2011944622507700619)
[OpenClaw Token 优化实战:从配置到习惯,全面降低上下文消耗](https://zhuanlan.zhihu.com/p/2013012710317642934)