 夜雨聆风
夜雨聆风





更强更快更聪明!OpenAI 全新 GPT-5.5,从零重训重磅登场

点击蓝字 关注我们
从GPT-4时代走到GPT-5,再到如今的GPT-5.5,AI的发展远远超出了普通用户的想象,基本平均每6周就发布一个新版本。

OpenAI 将 GPT-5.5 定位为
一个真正“能干活”的模型,
而不仅仅是一个回答问题的聊天机器人。
GPT-5.5被官方定位为“迄今最强的自主编程模型”。
它能更快地理解你的目标,擅长编写和调试代码、在线搜索、分析数据、创建文档和电子表格,
并且能够在多个工具之间来回切换,直到完成任务。
在Codex环境中,它已经能承担从实现、重构到调试、测试、验证的全流程工程工作,
甚至能判断为什么某功能失败、修复该落在哪里、以及代码库中还有哪些地方会受影响。
官方给了一些案例:
-
太空任务应用程序
-
地震追踪器
-
地牢游戏
-
3D游戏
在GPT-5.4时代,100万Token的上下文窗口更多是“名义上支持”,
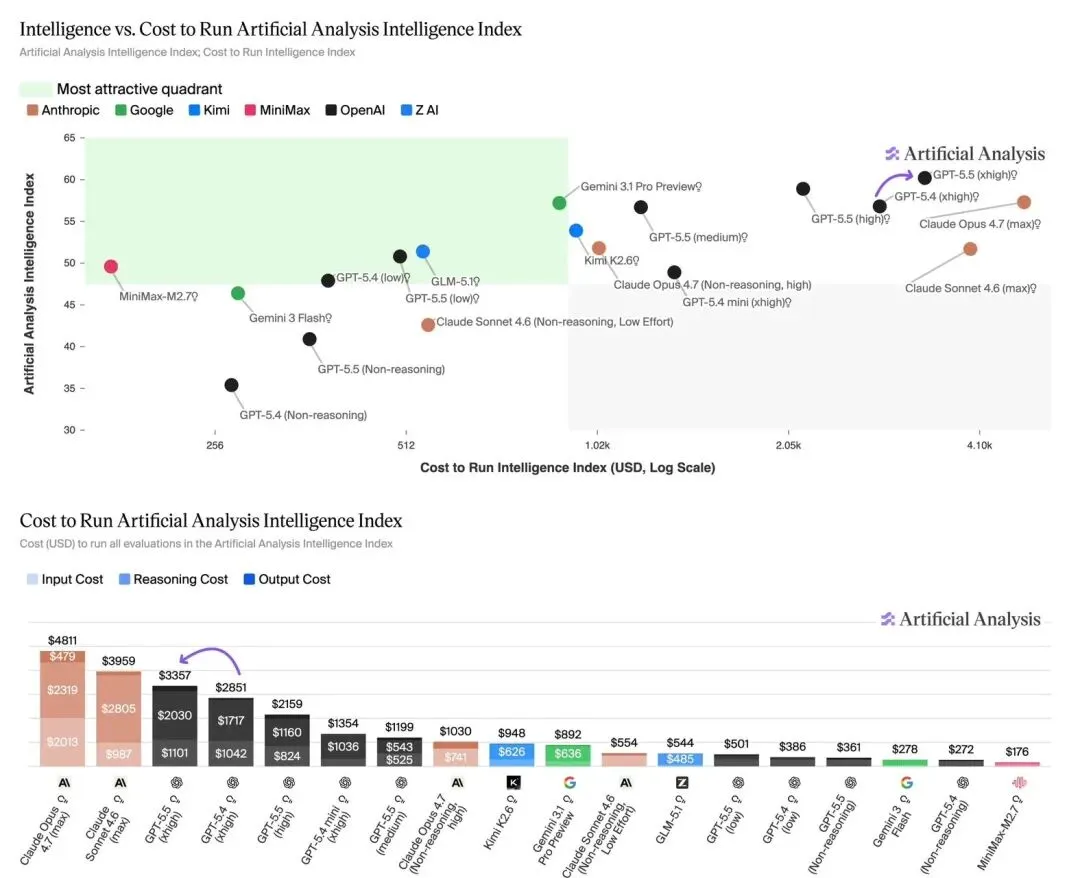
但GPT-5.5通过重训架构,将同等测试得分大幅提升至45.4%,首次让100万Token的上下文从“理论可用”变成了“实质可用”。

尽管API的单词元标价从GPT-5.4的$2.50/$15(每百万Token输入/输出)翻倍至$5/$30,
但官方强调GPT-5.5完成相同任务所需Token数量大幅减少,约40%。
综合下来,用户的实际任务成本净增仅约20%,而且已经比Claude Opus 4.7便宜了约30%;
GPT-5.5在真实服务中保持了与GPT-5.4相当的每Token延迟,同时实现了更高的智能水平。简单说就是:活干得多了,饭吃得少了。
GPT-5.5能在更少的任务指令下完成更多工作,面对模糊问题时能自主判断下一步该做什么。
过去由于模型推理能力有限,你需要告诉它第一步做什么、第二步做什么。
但在GPT-5.5面前,这些多余描述反而会束缚模型,你只需要给出目标产出和基本约束,让模型自己找最优路径。
OpenAI官方表示,GPT-5.5搭载了公司有史以来最强大的安全防护机制。
在整个安全与准备框架下对模型进行了评估,动用了内外部红队测试人员,并针对高级网络安全和生物能力进行了专项测试,在发布前收集了近200家信任的早期合作伙伴的真实用例反馈。
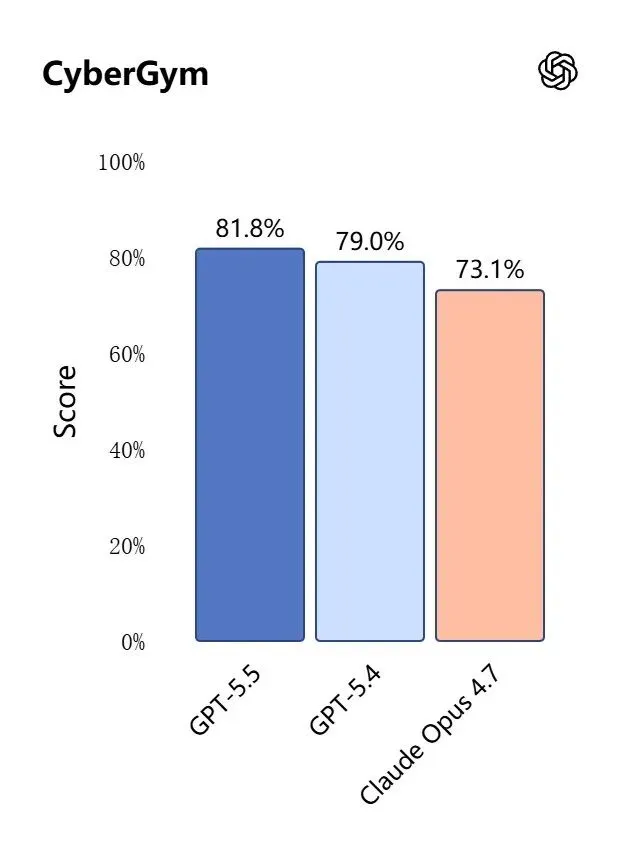
在CyberGym网络安全测试中,GPT-5.5以81.8%领先Claude Opus 4.7的73.1%。
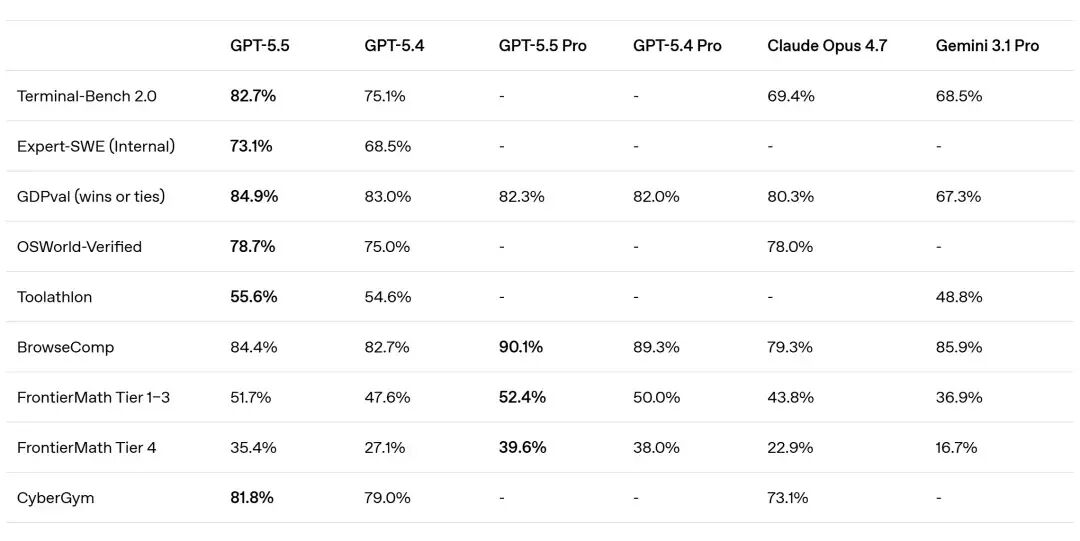
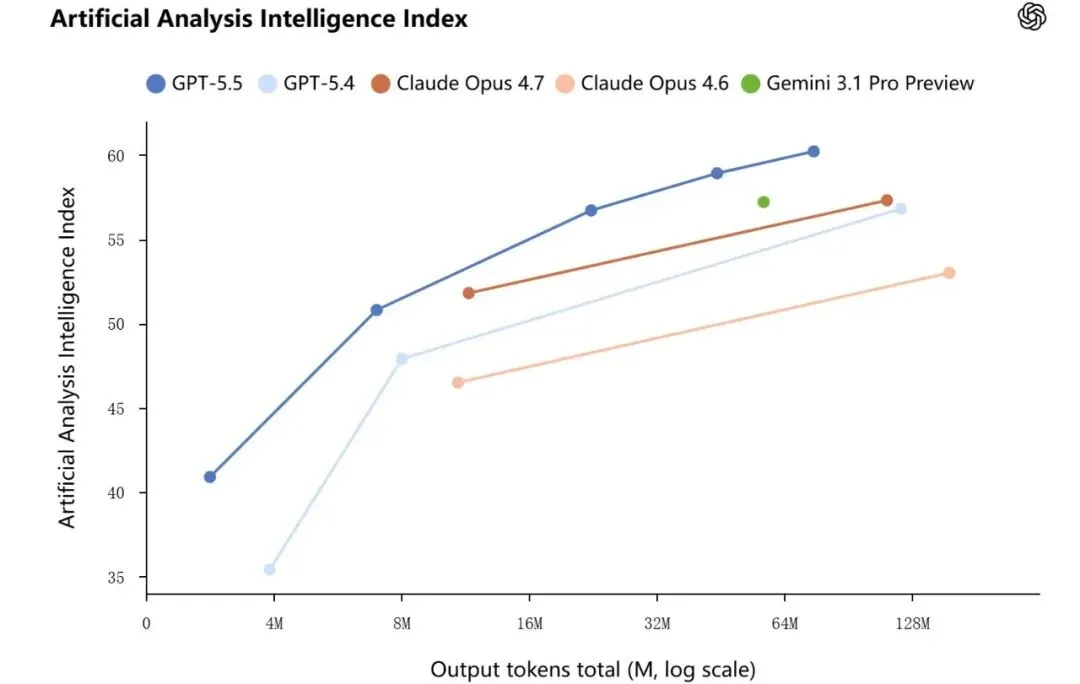
最直观,最有说服力的还是在数据中的表现,GPT-5.5在多项权威基准测试中都表现出色,官方博客列出了核心基准对比:
-
Terminal-Bench 2.0(终端自主任务):GPT-5.5得分82.7%,显著高于Claude Opus 4.7的69.4%和Gemini 3.1 Pro的68.5%。
-
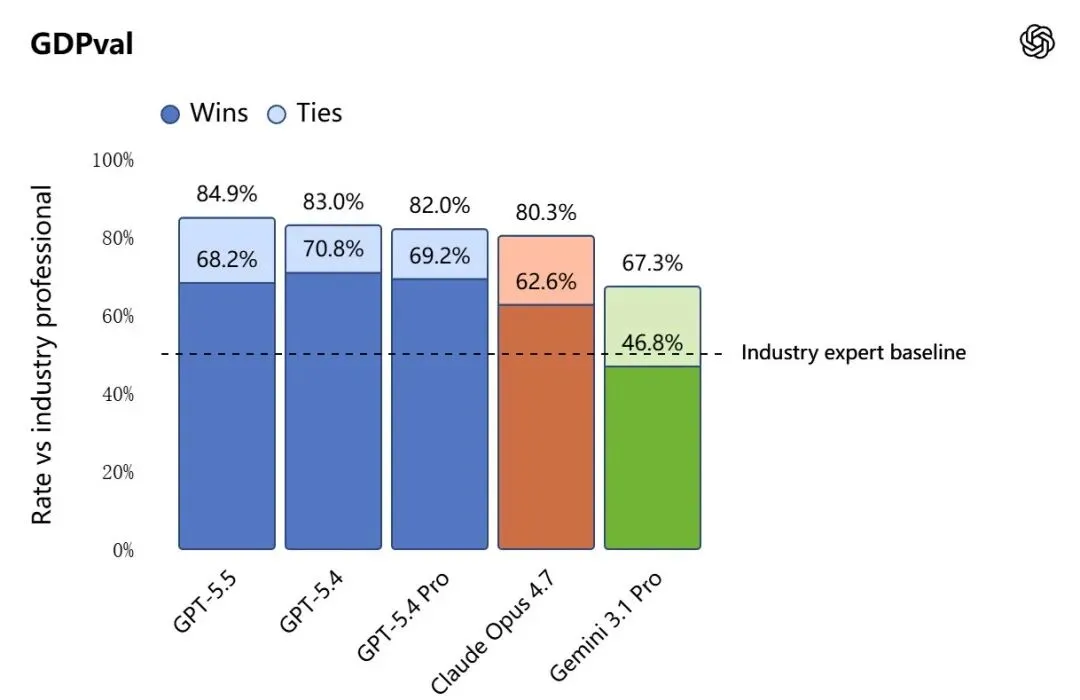
GDPval(跨44类职业知识工作):GPT-5.5以84.9% 超过GPT-5.4的83.0%和Claude Opus 4.7的80.3%。该测试覆盖金融建模、法律分析、运营规划等44种真实职业场景。
-
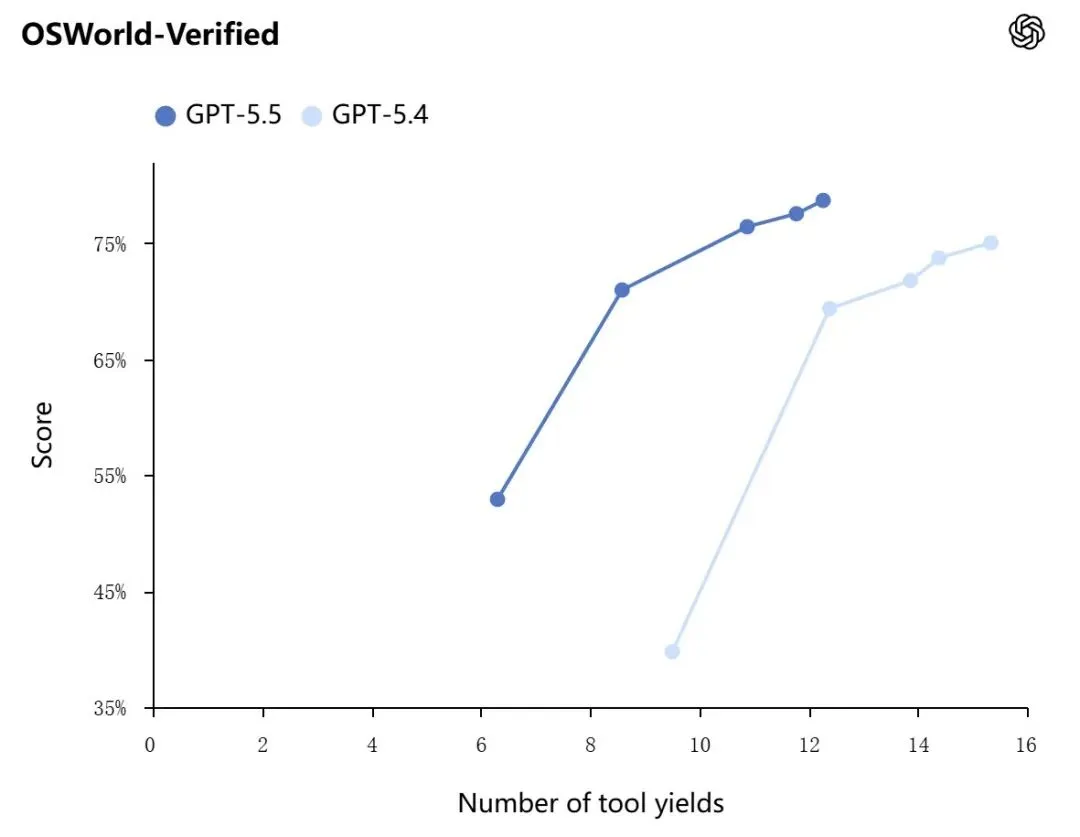
OSWorld-Verified(自主操作电脑):GPT-5.5得分78.7%,与Claude Opus 4.7的78.0%基本持平。
-
BrowseComp(浏览与信息综合):GPT-5.5得分84.4%,GPT-5.5 Pro版更高达90.1%,大幅领先Claude Opus 4.7的79.3%。
-
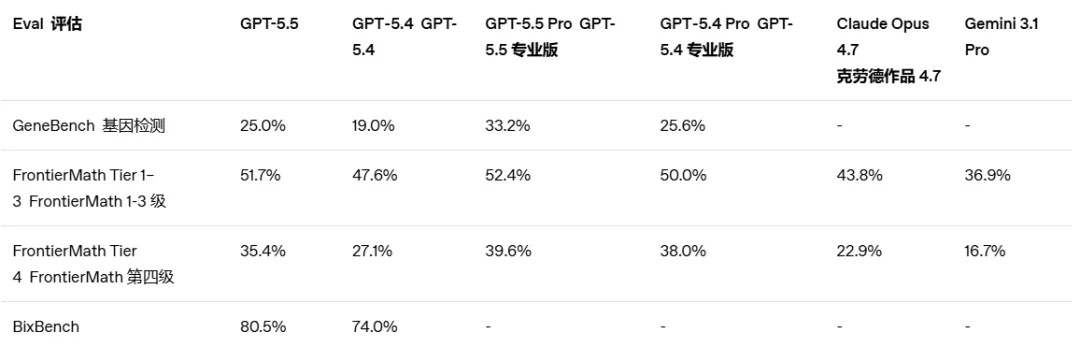
FrontierMath Tier 1–3(前沿数学):GPT-5.5得分51.7%,GPT-5.5 Pro版达到52.4%,而Claude Opus 4.7仅为43.8%。
-
FrontierMath Tier 4(最前沿数学难题):GPT-5.5得分35.4% vs Claude Opus 4.7的22.9%,差距进一步拉大。
最让人震惊的是,GPT-5.5还参与了自身推理基础设施的优化。
它帮助OpenAI基础设施团队分析了数周的生产流量数据,并重写了负载均衡的启发式算法,最终让Token生成速度提升了超过20%。
GPT-5.5 Pro的内测用户普遍反馈,它不像一次性答题引擎,而更像一个研究伙伴:能反复审读稿件、压力测试技术论点、提出分析方案,并同时处理代码、笔记和PDF上下文。
目前,GPT-5.5已在ChatGPT和编程助手Codex中全面上线,所有Plus、Pro、Business和Enterprise付费用户都可以直接体验。
API接口方面,GPT-5.5和GPT-5.5 Pro已于4月24日正式向全球开发者开放,定价为每百万Token输入$5、输出$30,批量处理和弹性定价可享受半价优惠。
https://openai.com/index/introducing-gpt-5-5/


