 夜雨聆风
夜雨聆风





炸裂!4月AI大模型神仙打架,GPT-5.5 vs DeepSeek-V4终极对决!
兄弟们,四月份的AI圈简直杀疯了!
Llama 4、GPT-6、Claude Opus 4.7、Kimi K2.6、Qwen3.6、文心5.0、混元Hy3、GPT-5.5、DeepSeek-V4…整整9天,顶级模型轮番炸场!
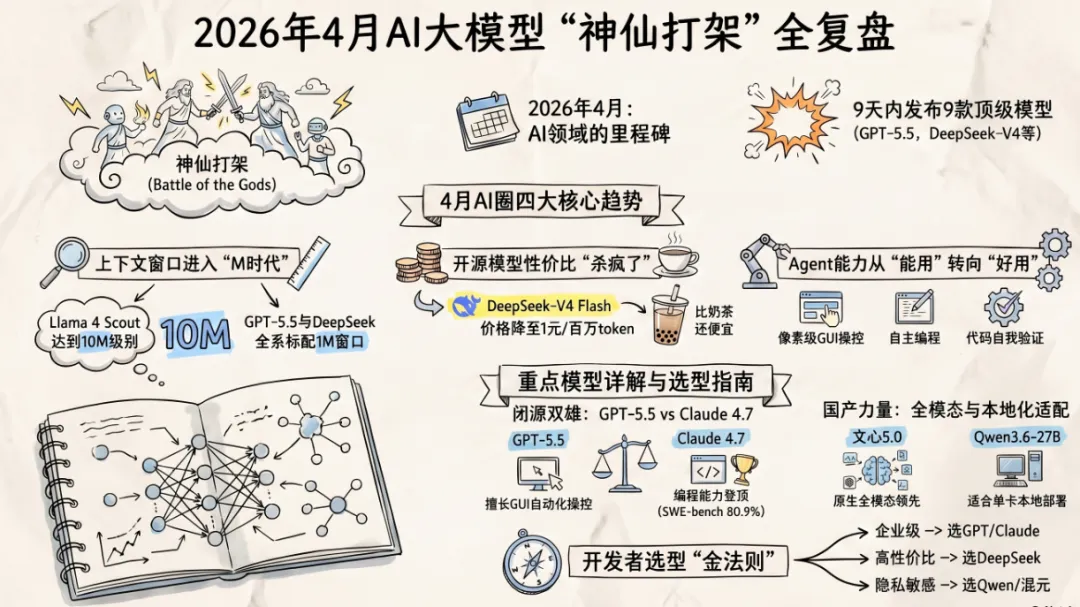
🔥 核心看点:本月的四大趋势
1️⃣上下文窗口军备竞赛
-
Llama 4 Scout:10M token(1000万)
-
GPT-5.5:1M token(100万)
-
DeepSeek-V4:1M token(全系标配)
-
腾讯混元Hy3:256K
2️⃣开源 vs 闭源:攻守易势
闭源阵营:GPT-6、Claude Opus 4.7、文心5.0、GPT-5.5
开源阵营:Llama 4、Kimi K2.6、Qwen3.6-27B、混元Hy3、DeepSeek-V4
3️⃣国产模型集体爆发 🇨🇳
-
Kimi K2.6:长程Agent能力拿下多个SOTA
-
Qwen3.6-Max:国产旗舰,智能体编程领先
-
文心5.0:LMArena全球第二、中国第一
-
混元Hy3:快慢思考融合,Agent能力大幅提升
-
DeepSeek-V4:开源第一,价格屠夫
4️⃣Agent能力全面爆发 🤖
-
GPT-5.5:自主编程 + 计算机操控(像素级GUI)
-
DeepSeek-V4:Agent能力开源第一
-
Claude Opus 4.7:自我验证能力登顶
-
混元Hy3:Agent能力大幅提升
📌 重点模型详解
🏆 GPT-5.5:OpenAI的王炸
4月24日发布
为什么值得关注?
-
成本暴降35倍:之前用GPT-4写代码肉疼?现在GPT-5.5直接降到$5/百万token,一杯奶茶钱能处理50万字代码。
-
自主编程+像素级GUI操控:这意味着AI不仅能写代码,还能帮你操控电脑——点按钮、填表格、截图分析,一条龙服务。
-
深度推理:面向真实工作的智能,不是玩具,是生产力工具。
🔥 DeepSeek-V4:开源的极致性价比
4月24日发布
为什么值得关注?
-
价格屠夫:Flash版本1元/百万token,这价格比奶茶还便宜,比很多免费模型还便宜。
-
技术突破:DSA2稀疏注意力,FLOPs降低73%,KV缓存降低90%——又省显存又省算力。
-
国产硬件适配:华为昇腾、寒武纪原生支持,国产替代不再是梦。
-
开源第一Agent能力:不再是”只能聊天”的开源模型,是真正能干活的Agent。
🎯 Claude Opus 4.7:编程能力登顶
4月17日发布
为什么值得关注?
-
编程能力天花板:SWE-bench 80.9%,意味着Claude Opus 4.7写的代码,10个bug能给你修掉8个。
-
自我验证:写完代码自动检查,连code review的活都帮你干了。
-
闭源旗舰:对于不追求开源、只追求效果的团队,这是目前编程能力的首选。
🇨🇳 Kimi K2.6:国产Agent黑马
4月20日发布
为什么值得关注?
-
长程Agent能力突出:深度检索F1分数92.5%,处理长文档、多轮对话的能力出色。
-
MoE架构:256K上下文下依然保持高效,不是傻大黑粗。
-
国产开源:终于有国产模型在Agent能力上和国外顶级模型掰手腕了。
🌟 Qwen3.6-27B:本地部署的Agent神器
4月20日发布
为什么值得关注?
-
27B参数,本地跑得动:不是所有人都能用云端API,27B意味着一块好显卡就能跑。
-
Agent编程集成:内置OpenClaw、Claude Code生态,本地开发也能用上顶级Agent能力。
-
国产之光:阿里出品,中文理解+编程能力的组合拳。
📊 文心5.0:国产旗舰的崛起
4月21日发布
为什么值得关注?
-
原生全模态:从训练源头就是多模态融合,不是后来拼凑的。
-
全球第二的排名:LMArena榜单中国第一,这个成绩值得骄傲。
-
2万亿参数但省算力:激活参数比<3%,意味着实际运行时不会太吃硬件。
📊 关键参数对比表
| 模型 | 发布日期 | 类型 | 参数 | 上下文 | 编程能力 | 定价(输入/输出) | 许可证 |
|---|---|---|---|---|---|---|---|
| GPT-5.5
|
|
|
|
|
|
|
|
| DeepSeek-V4 Pro |
|
|
|
|
|
|
|
| DeepSeek-V4 Flash |
|
|
|
|
|
|
|
| Claude Opus 4.7 |
|
|
|
|
|
|
|
| GPT-6 |
|
|
|
|
|
|
|
| 文心5.0 |
|
|
|
|
|
|
|
| Kimi K2.6 |
|
|
|
|
|
|
|
| Qwen3.6-Max |
|
|
|
|
|
|
|
| Qwen3.6-27B |
|
|
|
|
|
|
|
| 混元Hy3 |
|
|
|
|
|
|
|
| Llama 4 Scout |
|
|
|
|
|
|
|
| GPT-Image-2 |
|
|
|
|
|
|
|
💡 开发者选型建议
场景一:企业级商业应用
这三个是目前综合能力最强的模型,GPT-5.5成本大降,Claude编程能力最强,文心5.0多模态领先。根据你的预算和具体需求选择。
场景二:预算有限,追求性价比
DeepSeek-V4 Flash版本1元/百万token的价格简直是白菜价,Pro版本性能更强也才12元/百万token。如果需要本地部署,Qwen3.6-27B是28B级别最值得跑的模型。
场景三:需要本地部署 / 隐私敏感
这三个都是开源可本地部署的。Qwen3.6-27B在27B级别Agent编程最强;混元Hy3快慢思考融合架构有意思;Llama 4 Scout的10M上下文是长文档处理的核武器。
场景四:中文场景优先
国产模型在中文理解、文化背景知识方面有天然优势。文心5.0多模态最强,Kimi K2.6长程能力出色,Qwen3.6-Max智能体编程领先,DeepSeek-V4性价比最高。
场景五:追求极致编程能力
Claude Opus 4.7的80.9% SWE-bench是目前公开模型的天花板,GPT-5.5自主编程+GUI操控是未来方向,Kimi K2.6的58.6%在国产模型中表现亮眼。
🔮 展望5月
4月的AI圈已经卷成这样了,5月会怎样?我斗胆预测:
-
上下文窗口:可能还有更长的,但10M可能真的是一个坎
-
价格战:DeepSeek-V4开了个好头,预计会有更多模型跟进降价
-
多模态原生:GPT-Image-2开了个头,文本+图像+视频原生融合是趋势
-
端侧模型:27B级别能跑的效果越来越好,端侧AI可能在年中迎来爆发
-
Agent生态:各家都在推Agent能力,5月可能看到更多落地案例
📢 写在最后
兄弟们,2026年的AI发展速度真的超乎想象。就在去年这个时候,100K上下文还是”遥遥领先”,现在1M上下文已经成为标配。DeepSeek-V4的MIT开源 + 1元定价,或许标志着一个新时代的开始——不是”AI能力稀缺”的时代,而是”AI能力普惠”的时代。对于我们开发者来说,这是最好的时代。选择越来越多,价格越来越低,质量越来越好。与其焦虑被AI取代,不如学会驾驭AI。5月,我们继续关注。
❤️ 码字不易,如果这篇文章对你有帮助,点个在看、转发给需要的同学吧!
关注公众号 「程序员之路」
带你一起探索AI时代的开发之道