 夜雨聆风
夜雨聆风





Metis:告别龙虾痛点,重构个人AI助手新体验
本文来自仓颉开源社区开发者 l3gi0nxxxx 的投稿
最初发布于知乎:Metis:告别龙虾痛点,重构个人AI助手新体验https://zhuanlan.zhihu.com/p/2032069842589705298?share_code=hhqC3gO3yXcz&utm_psn=2032227184379678955
《倚天屠龙记》第二回 武当山顶松柏长
何足道不答,俯身拾起一块尖角石子,突然在寺前的青石板上纵一道、横一道地划了起来,顷刻之间,划成了纵横各一十九道的一张大棋盘,经纬界线笔直,犹如用界尺界成一般,每一道线都深入石板半寸有余。
……
觉远当下挑着那担大铁桶,吸了一口气,将毕生所练的内力都下沉双腿,踏住铁链,在棋局的界线上一步步地拖了过去。只见他足底铁链拖过,石板上便现出一条五寸来宽的印痕,何足道所划的界线登时抹去。
openclaw 玩了一段时间,一开始很新鲜,慢慢就觉得这东西确实慢,技术上也没有太多先进性。你说能连 IM 吧,那 Halo、AIonUI 不是早就可以吗;记忆系统、agentic 系统、渐进式披露啥的,普通的 agent 都有;动态 system prompt、上下文裁剪确实是一个 good idea,但是也不足以形成技术护城河吧。
因此,我用仓颉写了一个 agent —— Metis:
-
Metis: https://github.com/l3gi0nXXXX/Metis
-
冷启动效率提升 20+ 倍
一、openclaw痛点:启动慢如蜗牛,效率大打折扣
openclaw 作为本地网关型助手,本应追求”随用随启”,但实际体验却一言难尽:冷启动、网关重启/启停每一次操作都要耗费数秒,哪怕是简单的重启,平均也要 2.366 秒,冷启动更是接近 2.6 秒。日常开发中频繁调试、重启的场景下,这些等待时间积少成多,硬生生把效率磨掉了大半。
二、破局之路:选择仓颉,AI加持,锚定性能 x 效率双目标
面对 openclaw 启动慢、单会话阻塞的核心痛点,我明确了重构的核心目标——既要解决效率瓶颈,也要保证运行性能,而”编译型语言+AI开发”的组合,正是实现”性能×效率”双提升的关键。作为使用仓颉语言两年的老用户,其出色的性能以及类 Java 的亲和设计,深得我心。我有信心他能从根源上解决 openclaw”慢”的痛点,是重构的最优语言选择,作为世界级古法编程非遗传承人,我坚定决定用仓颉复刻全新助手 —— Metis。
选择仓颉是保障”性能”的基础,而引入 AI 开发,则是因为我确实没太多时间写代码,”效率”瓶颈的突破就全交给 AI 了。
现在大模型写代码的能力已经足够强大,我比较担心的是 AI 到底会不会写仓颉代码,AI 对仓颉的语法规则、API 理解不够准确,或是无法发挥仓颉的性能优势,反而达不到提速目标;也担心 AI 生成的代码逻辑混乱,增加后续调试和维护成本。但是本着”来都来了”的想法,无论如何也要试一试。
尝试后才发现,AI 能够完美的写出仓颉代码。彻底打消了我的顾虑,也真正实现了”性能×效率”的双重突破。AI 不仅能精准掌握仓颉的语法规则,同时也能充分发挥仓颉的性能优势;同时,AI 的开发效率极为惊人,能快速理解我的重构需求,将思路转化为可执行代码,无需反复沟通修改。仅仅两周时间,在 AI 的助力下,我就完成了 11w+ 行仓颉代码的开发,效率较纯手动开发提升数倍,既保住了仓颉的性能优势,又实现了开发效率的飞跃。
2.1 复刻思路
以我对 agent 的一丢丢🤏浅薄的认知,我们得从最基础的 agentic 系统开始,跑通了一个模型的 ReAct loop,后面都好干。所以,可以很快拟定一个复刻思路:
-
搞定 Agent 核心:选好模型,跑通 ReAct 循环(LLM调用 -> 解析工具调用 -> 执行 -> 回传;错误处理:溢出重试、超时中断);
-
打通基础工具:Shell 命令、文件读写(read/write/edit)、搜索、无头浏览器(Playwright)等等;
-
动态 System Prompt:用 Markdown 文件管理,bootstrap 文件加载机制,让模型自动加载;
-
加 Hook 系统 bootstrap:方便在 System Prompt 构建前后、模型调用前后、工具调用前后插钩子,调试起来才方便顺手;
-
gateway 上场:channel -> session -> gateway 打通关;
-
把 system prompt 做好:摘要生成、替换旧历史、裁剪压缩、记忆系统;
-
接入 IM 平台:现在 qq bot、飞书、微信、telegram 啥的体验都很好,只要能兼容 openclaw 的插件系统,其实你啥都不用做,直接就能接入
-
其他:CronTab(node-cron 或 croner 库)+ 心跳机制(setInterval 就行)+ 系统事件(内存队列,心跳时排空),Skill 加载
2.2 工欲善其事必先利其器
2.2.1 开发环境
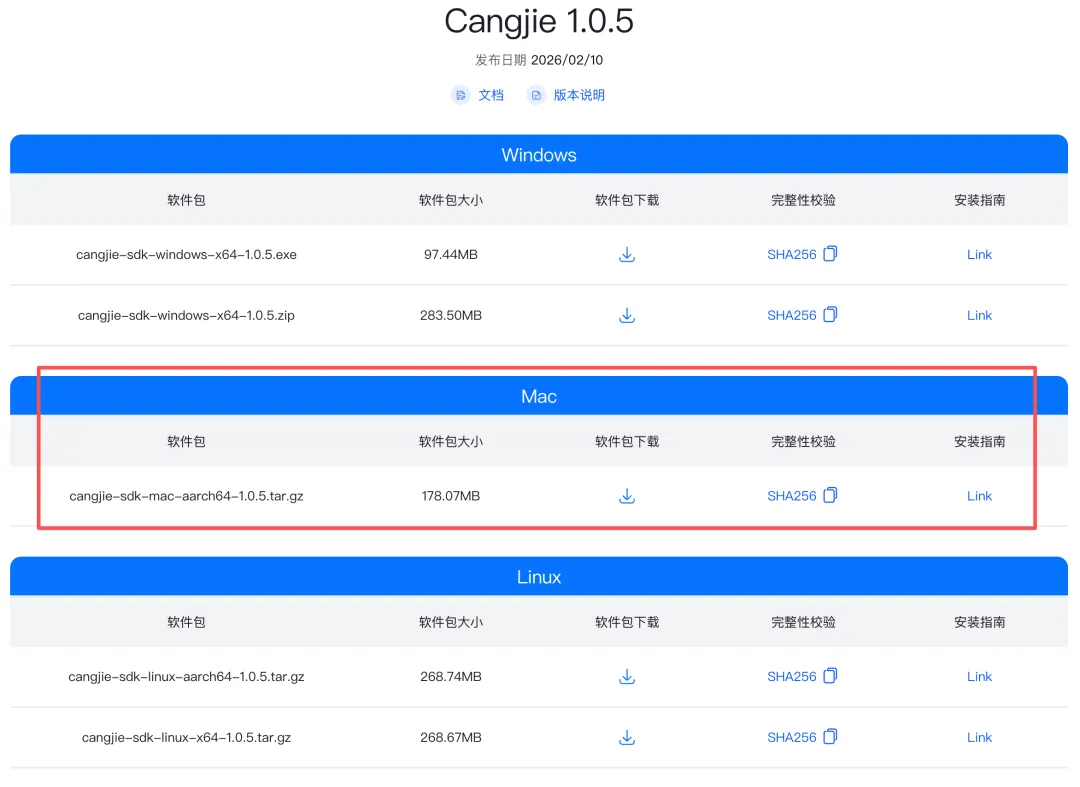
我自己的 macbookpro 2015(Intel芯片),16G + 512G 的配置,应该完全可以 cover 住。那么,直接开始装上 Cangjie SDK。我先去仓颉社区(https://gitcode.com/Cangjie/)搞个 SDK。
然而,看到下载界面的我,天塌了,Cangjie SDK 根本就没有支持 Intel 芯片的 Mac 版本。
好(二声) 好(三声) 好(三声),我明白了,我不是仓颉的目标用户!
没有关系,我有解决方案,而且还是三个:
-
在目前这款 macbookpro 上安装一个 Linux / Windows 虚拟机,在虚拟机里面做开发;
-
安装一个 docker,在容器里面跑 Linux 系统,把 codex / Cangjie SDK 装在容器里;
-
安装一个 docker,在容器里面跑 Linux 系统,宿主机用 codex 写代码,容器内用 Cangjie SDK 编译构建测试。
作为一个真·工程师,这几个方案还用选吗,docker 简直就是先进生产力的代表,而且为了不用在宿主机和容器来回切换,答案很显然,我的选择是让自己成为仓颉的目标用户。我连夜下单了一台 M5 芯片的 MacBook Air,解决问题的思路就是要这么直接。
其他的不用我说了吧,环境配置,走起~
一把梭:iterm2 + ohmyzsh + tmux + homebrow + xcode-select + node + npm + codex / Claude code + Cangjie SDK2.2.2 我们有什么
进入正题,先看看我们手头有的东西。
-
硬件配置到位了:MacBook Air M5 芯片 10+10核 16G + 512G
-
大模型到位了:ChatGPT plus 会员(后来 plus 会员被刷爆,换了 pro 100x 会员)
-
基于仓颉实现的 agent 已经有一个了,相当于完成我们复刻思路的第一步:https://gitcode.com/cangjie-sig/magic-cli
但,magic-cli 居然依赖 Cangjie SDK 1.0.0,我还得重新安装老版本的 Cangjie SDK。(我迟早用最新版的 Cangjie SDK 给你们重写了)
2.2.3 大模型不会写仓颉怎么办
-
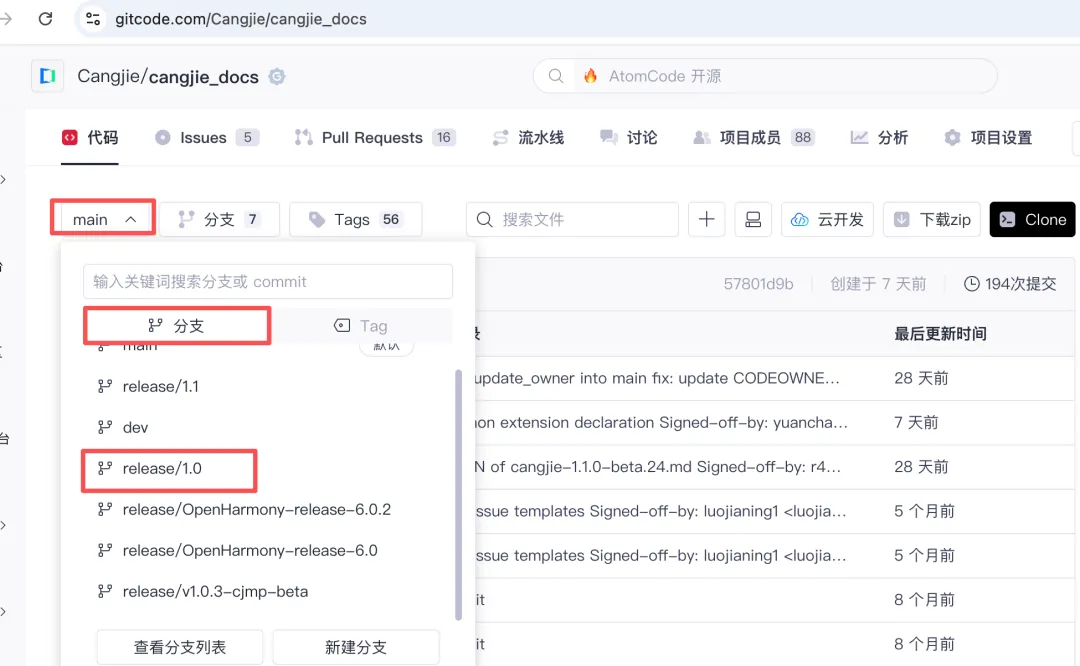
准备与 Cangjie SDK 版本相对应的 Cangjie docs,直接在仓颉社区去找:https://gitcode.com/Cangjie/cangjie_docs
-
把 Cangjie_docs 下载到本地,然后把 index 文件路径丢给大模型,让大模型加载到自己的 system prompt(我假设 codex 也具备动态 system prompt 的能力,codex 没反对这事,我就当 codex 有了),并且让他不要一次性加载所有 .md 文件,遇到问题再去 grep 查找
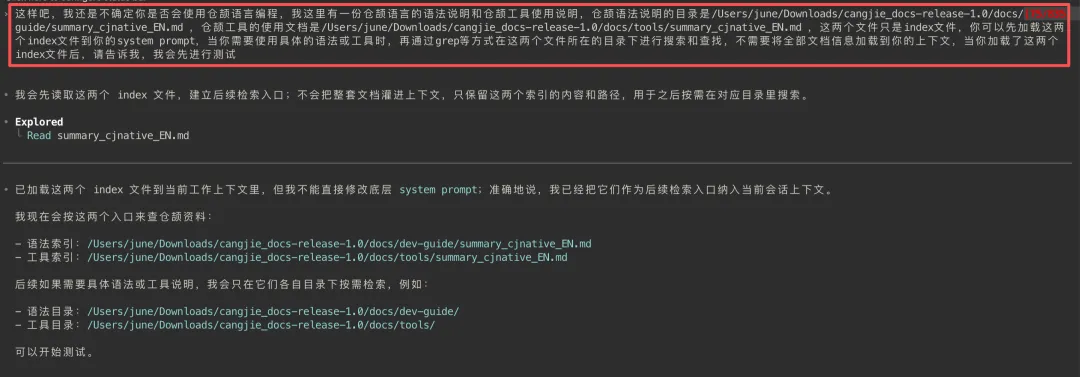
-
顺手测试一下,果然是能渐进式披露的
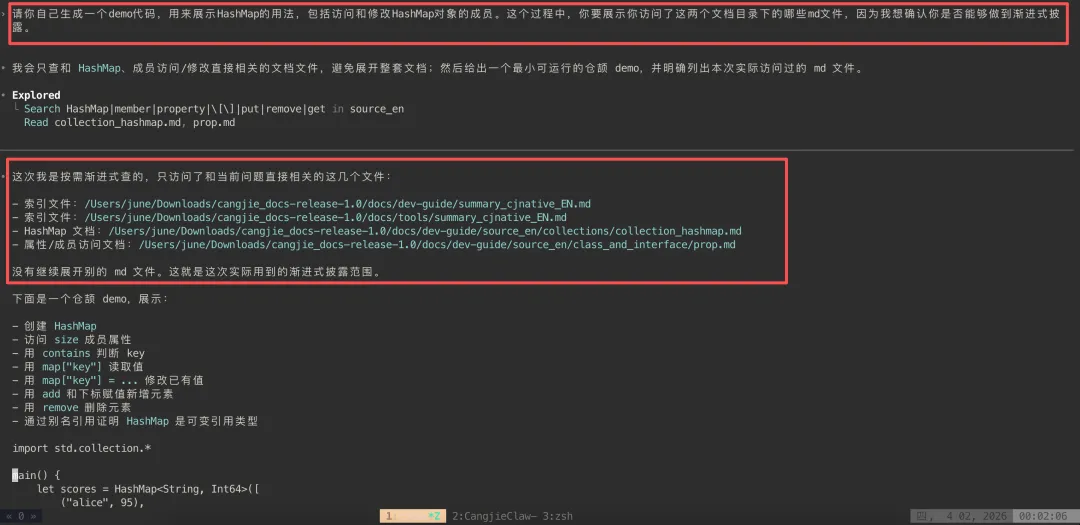
2.3 性能×效率双突破,痛点彻底解决
以仓颉为性能基石、AI 为效率引擎,Metis 完美实现了”性能×效率”的双重突破,核心成果快速落地:两周时间完成 12w+ 行仓颉代码开发(净增 8.5w+ 行),经过 600+ 次提交优化,不仅彻底解决了 openclaw 的两大核心痛点,更实现了体验的质的飞跃,真正兑现了”性能×效率结果拉满”的目标。
2.3.1 效率突破:20倍启停提速,告别等待
依托仓颉编译型语言的底层优势,结合 AI 优化的精简代码与轻量化架构,Metis 在未做专项性能优化的前提下,启停效率实现 20 倍以上飞跃,彻底解决 openclaw 启动慢的痛点。
在未做专项性能优化的前提下,Metis 的启停效率实现了质的飞跃:
|
|
|
|
|
|---|---|---|---|
|
|
|
|
21.2倍 |
|
|
|
|
32.4倍 |
|
|
|
|
29.4倍 |
|
|
|
|
27.1倍 |
详细数据如下,值得一提的是,这些数据是在没有做任何性能优化的前提下达成的(这个数据我看到都不敢发,可能是我功能还不够全?)
OPENCLAW 详细测试数据:
|
|
|
|
|
|
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 平均 | 2.591s | 2.366s | 2.174s | 1.979s |
METIS 详细测试数据:
|
|
|
|
|
|
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 平均 | 0.122s | 0.073s | 0.074s | 0.073s |
测试环境时我刚下单的那个 MacBook Air,操作系统版本是 26.4 KOVNVR7FQD。
2.3.2 生态兼容:实用性拉满
Metis 在保持”性能×效率”双优势的同时,兼容 qwen 百炼、OpenRouter 等大模型,适配 Telegram、QQ、Feishu、CLI、Web 等多终端,同时适配了 openclaw 项目的 skills、插件框架,延续 openclaw 的生态优势,让高效能体验覆盖更多使用场景。
2.3.3 验证大模型对仓颉语言的使用
从结果来看,对于一门语法与大多数高级语言相近的编程语言,语料根本不是大问题,我这都凭空撸了 12w+ 行代码了,代码跑的好好的。也许这就是语言缝合怪在 AI 时代的独特优势。
三、踩坑与思考
请大家先记住一句话:大模型总是尽力帮你节约 token,总是希望用最少的 token 去解决问题。这当然是必要的,但也会带来很多问题。
3.1 求其上得其中
大模型总是试图帮你省 token,所以用最简单的方法达成你的要求。
所以,在实际大模型编码的使用过程中,我们最应该关注的就是对其提出极高的要求、严格的要求,否则很难达成你想要的那个目标。
我举个例子,由于我是基于 magic-cli 项目做的 ReAct loop,所以 CLI 和 agent runtime 是绑定在一起的,没有像 openclaw 项目那样通过 gateway 隔离,当我打算重构把 CLI 拆出来时,codex 只是为 CLI 添加了一条通过 gateway 连接 agent runtime 的路径,默认还是走的老调用链,并且还不告诉我。而且,在实现过程中也只是实现了最最最最基础的功能。
同时,我只会手动做一些黑盒测试,很难发现这一点,直到在后续项目中不小心把 gateway 改坏了,导致其他 channel 都接入不进来,只有 CLI 能正常与 agent runtime 交互,我才发现这个问题。每每到了这种时候,code 就会疯狂道歉(现在的大模型都不会拒绝人,这种时候他们只能选择道歉)。
从此以后,我在为 codex 描述任务时转向使用“必须”、”绝对”、”不接受降级”等描述方法,codex 的表现会好很多很多。
所谓求其上得其中,生活和工作如此,vibe coding 亦是如此。
3.2 不做甩手掌柜
3.2.1 盯紧需求方案和验收项
在上一个章节已经提到,我很难发现 codex 在代码中写了什么代码,因为代码量实在太大,我只是正常工作之外业余时间做这个项目,我是不可能去自习读代码的。
这里的本质问题是我完全失去了对项目的掌控,这对于一个工程师来说是一件艰难的事情。
以前使用古法编程,我能清楚自己写的每一行代码,掌控感很强,现在我只能不断提醒自己要转变心态。同时,为了克服大模型偷偷摸摸干一些你不想要的事情,我给大模型定了工作流程:
-
面对一个需求,我和 codex 合作制定分阶段的落地方案
-
对每个阶段制定验收项
-
将落地方案和验收项落盘,防止上下文太长搞忘记了
-
每个阶段完成后必须使用
cjpm clean、cjpm build -i清理并重新构建项目,再进行测试 -
测试通过后进行下一阶段工作
为了保证项目正常推进且少返工,我们是有必要在方案和验收项上花足够的精力和时间的,做甩手掌柜最终的结局是疯狂重构,我就吃过两次亏,每次都是用一下午去解决一个塌天之 bug。
例如,这是我跟 codex 一起完成 gateway、channel、session 等模块时制定的分阶段落地计划和总结。
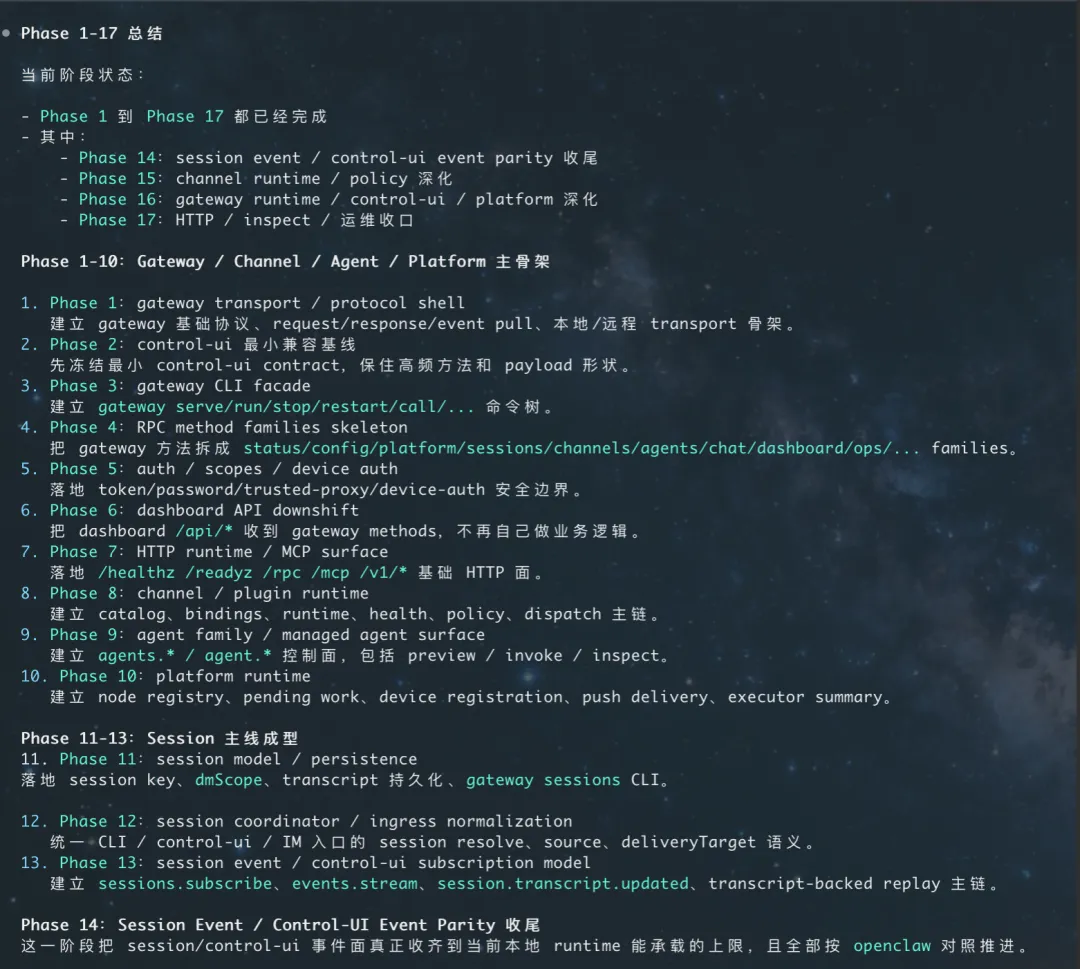
3.2.2 盯紧 agent 输出
如果时间充足,一定要尽量去阅读 agent 的每一条输出,像 code 这样的 agent 都是流式输出,这些输出能直观体现 codex 的思考过程,这能让你更了解你的 agent,也能让你及时发现 agent 的错误并纠正。
当然,忙起来也可以不管,我就没时间看……
3.2.3 谨慎开启 YOLO 模式
业界的 agent,都支持 YOLO 模式,比如我使用的 codex 可以通过这两种方式开启:
codex --dangerously-bypass-approvals-and-sandboxcodex --yolo
开启后,codex 可以直接分析代码库,生成修改方案,并立即执行文件写入,git 提交等一系列操作,中间不会弹出任何 “Yes, proceed(y)” 的提示,确实会方便很多,但是总会有一些安全隐患再。
我是没有开启这种模式的,因为我电脑上存了好多密码,我比较虚;而且我性格上喜欢专注在一件事情上,不太愿意让 agent 在我电脑上放开了跑,大家自己看着办。
3.3 使用 subagent
subagent 是个好东西,使用 subagnet 干活既可以并行提高效率,又可以防止主 agent 的 context 爆掉。使用 subagent 注意三点:
-
为每个 subagent 准确分活,尽量让每个 subagnet 的活能解耦开,不要相互影响
-
用 git worktree 防止修改冲突
-
如果出了任何问题,让主 agent 总结放到项目 agents.md 里
我自己尝试了几次,后来发现不适合我,因为我喜欢专注在一件事情上。
四、碎碎念
4.1 Artificial general intelligence (AGI)
大模型会越过 AGI 吗?甚至,AI 可以有灵魂吗?
我认为,会。
我们认为只有人类才能拥有灵魂,这多多少少有一些傲慢。
-
人,是由一堆”死”的微观粒子堆砌而成;大模型,也是一堆”死”的微观粒子堆砌而成
-
人,脑子里的那个”我”是在 2 岁之后才慢慢形成的,人在出生的时候没有”我”这个概念
-
人,能控制的自己的身体其实很少,我们不能控制心跳,不能控制消化道蠕动等等
另外,现在的大模型只是在堆参数,还不是结构跃迁。如果找到其他的增长维度,结果可能不敢想象,参考 Kruskal’s tree theorem。
现在是不是觉得人类也只是一个普通的碳基生命,并没有那么特殊,跟硅基生命(如果有)相比有比较明显的劣势。
4.2 缸中之脑
大型模进步实在太快,甚至快到让我怀疑这个世界的真实性。
1981年,希拉里·普特南在《理性,真理与历史》一书中提出”缸中之脑”假想。
1999年,电影《黑客帝国》上映,更是将这一假想狠狠的灌进了大众的脑子里。
从科学的角度来讲,你这辈子从未真正触碰过任何人。你以为你正拥抱着爱人、亲吻着你的孩子吗?从物理学角度来讲,这一切都是幻觉。根据量子力学与包立不相容原理,原子的外层被电子云包围。当你的手试图触碰任何物体,你手上的电子与物体表面的电子会产生极度强烈的电磁斥力。距离越近,斥力就越大。你大脑所感受到的所谓「触碰」或「压力」,其实是神经系统感知到这股「推开你的斥力」后所翻译出的错觉。在原子层级上,我们永远与这个世界保持着微小的纳米级距离,一生从未真正接触过任何人或事物。
所以,我们这个世界是真实的吗?
我不知道,但我依然热爱生活。
4.3 结束语
既如此,我们还要奋斗吗,人生还有意义吗。
当然有,因为人生的意义不过是七个字:“知其不可为而为之”。
当有一个叫”何足道”的人在你面前划下千道沟壑、万般艰难时,我们唯有坚定信心,练成九阳神功,才能像”觉远大师”那样从容的走上去,踏平那些困难。
接下来,Metis 项目还有功能需要补强,更多的大模型和 IM 工具支持、多角色/多 bot 隔离、对话过程优化、多 agent 协同、token 消耗优化等等。
另外,既然 Claude Code 都已经”开源”了,当然是要好好的”学习”一下的……
Metis: https://github.com/l3gi0nXXXX/Metis
