 夜雨聆风
夜雨聆风





《Linux-0.12 源码篇》- 03 进程管理
字数 9751,阅读大约需 49 分钟
第三章:进程管理
如果把操作系统比作一个管理国家的机构,那么进程管理就是其治国理政的核心机制。每个进程就像是一个公民,需要被分配资源、获得CPU时间、与其他进程协作。Linux 0.12的进程管理系统虽然简单,但已经具备了现代操作系统进程管理的基本要素:进程创建、调度、状态转换、资源分配和回收。通过对这个系统的深入分析,我们可以理解操作系统如何在有限的硬件资源下,让多个程序看起来”同时”运行,实现真正的多任务处理。
3.1 进程的核心数据结构:task_struct完全解析
3.1.1 task_struct结构体源码分析
在Linux 0.12中,进程的所有信息都集中在task_struct结构中,这个结构定义在include/linux/sched.h文件里。让我们先看完整的结构体定义:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 struct task_struct {/* 以下是硬件上下文,任务切换时保存/恢复 */ long state; /* 进程运行状态: * -1: 不可运行(未使用) * 0: TASK_RUNNING 可运行或正在运行 * 1: TASK_INTERRUPTIBLE 可中断睡眠 * 2: TASK_UNINTERRUPTIBLE 不可中断睡眠 * 3: TASK_ZOMBIE 僵尸状态 * 4: TASK_STOPPED 已停止 */ long counter; /* 时间片剩余滴答数 * 初始值=priority,每次时钟中断减1 * 降到0时需要重新调度 */ long priority; /* 进程优先级,时间片用完时用于重新计算counter * 默认值15,子进程继承父进程的priority */ long signal; /* 进程收到的信号位图,每bit代表一个信号 * bit 1=SIGHUP, bit 2=SIGINT, etc. * 信号处理在返回用户态前检查此字段 */struct sigaction sigaction[32]; /* 信号处理结构数组 * 每个信号对应一个处理函数和处理标志 */ long blocked; /* 信号屏蔽位图,为1的bit对应的信号被阻塞 * 被阻塞的信号不会被递送,但保留在signal中 *//* 以下是进程标识和关系 */ int exit_code; /* 进程退出码,父进程通过wait()获取 */ unsigned long start_code; /* 代码段起始地址(线性地址)*/ unsigned long end_code; /* 代码段结束地址 */ unsigned long end_data; /* 数据段结束地址(包括未初始化数据段)*/ unsigned long brk; /* 堆的当前结束地址,sbrk()系统调用修改此值 */ unsigned long start_stack; /* 栈的起始地址 */ long pid; /* 进程标识号,全局唯一 */ long father; /* 父进程pid(注意不是指针而是pid值)*/ long pgrp; /* 进程组号,用于作业控制 */ long session; /* 会话号,用于终端管理 */ long leader; /* 会话首进程标志,1表示是session leader */ unsigned short uid; /* 用户标识号 */ unsigned short euid; /* 有效用户id,用于权限检查 */ unsigned short suid; /* 保存的设置用户id */ unsigned short gid; /* 组标识号 */ unsigned short egid; /* 有效组id */ unsigned short sgid; /* 保存的设置组id */ long alarm; /* 报警定时值,单位是滴答数(10ms) * 非0时每次时钟中断减1,降到0时发送SIGALRM信号 */ long utime; /* 用户态运行时间 */ long stime; /* 内核态运行时间 */ long cutime; /* 子进程用户态时间 */ long cstime; /* 子进程内核态时间 */ long start_time; /* 进程创建时间 */ unsigned short used_math; /* 是否使用了协处理器,1表示使用过 *//* 以下是文件系统信息 */ int tty; /* 进程使用的tty终端号,-1表示没有终端 */ unsigned short umask; /* 文件创建掩码,用于open()和creat() */struct m_inode * pwd; /* 当前工作目录的inode指针 */struct m_inode * root; /* 根目录的inode指针(可通过chroot改变)*/struct m_inode * executable; /* 执行文件的inode指针 */ unsigned long close_on_exec; /* 执行时关闭的文件句柄位图 * execve时会关闭设置了此标志的文件 */struct file * filp[NR_OPEN]; /* 进程打开的文件指针数组 * NR_OPEN=20,最多打开20个文件 * 数组下标就是文件描述符fd *//* 以下是内存管理信息 */struct desc_struct ldt[3]; /* 进程的局部描述符表 * ldt[0]: 未使用(空描述符) * ldt[1]: 代码段描述符 * ldt[2]: 数据段描述符 * 每个进程有64MB线性地址空间 *//* 以下是TSS,保存硬件上下文 */struct tss_struct tss; /* 任务状态段,保存任务切换时的寄存器 * 包括所有通用寄存器、段寄存器、eip、esp、eflags等 * x86硬件任务切换机制使用此结构 */};
结构体字段总结:
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
3.1.2 TSS任务状态段详解
TSS是x86架构为任务切换专门设计的硬件机制。让我们看看TSS的详细结构定义:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 struct tss_struct { long back_link; /* 前一个任务的TSS描述符链接,用于嵌套任务 * Linux 0.12不使用硬件嵌套,此字段未用 */ long esp0; /* 特权级0(内核态)的栈指针 * 从用户态切换到内核态时,CPU自动加载此值到esp */ long ss0; /* 特权级0的栈段选择符,通常指向内核数据段 * 值为0x10(GDT中第2项,内核数据段)*/ long esp1; /* 特权级1的栈指针(Linux未使用特权级1)*/ long ss1; /* 特权级1的栈段选择符 */ long esp2; /* 特权级2的栈指针(Linux未使用特权级2)*/ long ss2; /* 特权级2的栈段选择符 */ long cr3; /* 页目录基址寄存器,指向进程的页目录表 * 任务切换时CPU自动加载此值,实现地址空间切换 */ long eip; /* 指令指针,下一条要执行的指令地址 */ long eflags; /* 标志寄存器,包含各种状态和控制标志 * bit 9: IF中断允许标志 * bit 14: NT嵌套任务标志 * 等等 */ long eax; /* 累加器,通用寄存器 */ long ecx; /* 计数器,通用寄存器 */ long edx; /* 数据寄存器,通用寄存器 */ long ebx; /* 基址寄存器,通用寄存器 */ long esp; /* 栈指针,指向当前特权级的栈顶 */ long ebp; /* 基址指针,用于栈帧管理 */ long esi; /* 源索引寄存器,用于字符串操作 */ long edi; /* 目的索引寄存器,用于字符串操作 */ long es; /* 附加段选择符 */ long cs; /* 代码段选择符,决定当前特权级 * 0x0f=用户代码段(CPL=3) * 0x08=内核代码段(CPL=0)*/ long ss; /* 栈段选择符 */ long ds; /* 数据段选择符 */ long fs; /* 附加段选择符,Linux用于访问用户数据 */ long gs; /* 附加段选择符,Linux未使用 */ long ldt; /* LDT选择符,指向进程的局部描述符表 */ long trace_bitmap; /* 调试跟踪位图,高16位是I/O位图偏移 * 用于I/O权限控制和调试 */};
TSS的关键作用:
-
1. 特权级切换: 当中断或系统调用从用户态(CPL=3)进入内核态(CPL=0)时,CPU自动从TSS中的esp0和ss0字段加载内核栈指针,确保内核代码在独立的内核栈上运行。 -
2. 任务切换: 执行 ljmp或call指令到一个TSS描述符时,CPU自动: -
• 将当前所有寄存器保存到当前任务的TSS -
• 从新任务的TSS中加载所有寄存器 -
• 加载cr3切换页目录(切换地址空间) -
• 切换LDT -
3. 上下文恢复: 进程被调度器重新选中时,通过硬件任务切换机制,所有寄存器从TSS恢复,进程从上次暂停的位置无缝继续执行。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 // 示例: 任务切换时TSS中寄存器的保存和恢复// 假设进程A正在运行,调度器决定切换到进程B// 步骤1: CPU自动保存进程A的上下文到tss_Atss_A.eip = 当前指令指针; // 保存下一条指令地址tss_A.esp = 当前栈指针; // 保存栈顶位置tss_A.eax = eax寄存器内容; // 保存所有通用寄存器tss_A.ebx = ebx寄存器内容;// ... 保存所有其他寄存器tss_A.cs = 当前代码段; // 保存段寄存器tss_A.ds = 当前数据段;// ... 保存所有段寄存器// 步骤2: CPU自动从tss_B加载进程B的上下文eip = tss_B.eip; // 恢复指令指针,跳转到B的执行位置esp = tss_B.esp; // 恢复栈指针eax = tss_B.eax; // 恢复所有通用寄存器ebx = tss_B.ebx;// ... 恢复所有其他寄存器cs = tss_B.cs; // 恢复代码段ds = tss_B.ds; // 恢复数据段// ... 恢复所有段寄存器cr3 = tss_B.cr3; // 切换页目录,实现地址空间切换ldt = tss_B.ldt; // 切换到B的局部描述符表// 步骤3: 进程B恢复执行// CPU从tss_B.eip指向的地址继续执行,就像进程B从未被打断过
3.1.3 task_struct与内核栈的巧妙布局
Linux 0.12采用了一个巧妙的设计:将task_struct和内核态栈放在同一个4KB物理页面中。让我们通过代码和图示理解这个设计:
一个4KB(4096字节)的物理页面分配如下:
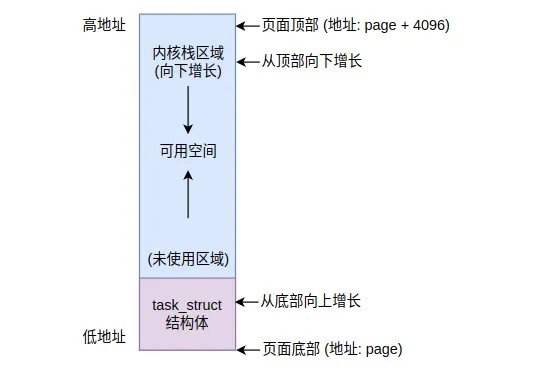
在 Linux 系统中,可以利用 4KB 页面对齐的特性,通过屏蔽栈指针的低 12 位来直接计算出 task_struct 的起始地址。Linux 0.12 内核中,current 宏正是为此设计的。它封装了从栈指针获取 task_struct 的逻辑。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 // get_free_page()分配一个4KB页面作为进程的内核栈页// task_struct就在这个页面的底部// 通过栈指针快速定位当前进程的task_struct#define PAGE_SIZE 4096#define get_current() \ ((struct task_struct *)(esp & 0xFFFFF000))/* 解释: * esp是当前栈指针,指向内核栈的某个位置 * esp & 0xFFFFF000 将esp的低12位清零,得到页面起始地址 * 页面起始地址就是task_struct的地址 * 这个宏在1条指令内完成,非常高效! */// 实际示例:// 假设进程的页面起始地址是 0x00FA5000// task_struct位于 0x00FA5000 (页面底部)// 当前内核栈指针esp = 0x00FA5F80 (页面中某个位置)// // 计算: esp & 0xFFFFF000// = 0x00FA5F80 & 0xFFFFF000// = 0x00FA5000 <- 页面起始地址,即task_struct地址
这种设计的优势:
-
1. 快速定位: 通过一次位掩码操作(AND运算)就能从esp快速获取当前进程的task_struct指针,无需查表或遍历。 -
2. 空间效率: task_struct大小约1KB,内核栈使用约2-3KB,共用一个4KB页面避免了内存浪费。 -
3. 简化管理: 分配和释放只需要一次页面操作,减少了内存碎片。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 // kernel/fork.c 中分配进程页面的代码long copy_process(...){struct task_struct *p; int i;struct file *f; // 分配一个空闲页面用于task_struct和内核栈 p = (struct task_struct *) get_free_page(); if (!p) // 分配失败 return -EAGAIN; // p指向页面起始地址,就是新进程的task_struct位置 task[nr] = p; // 将新进程加入全局task数组 // 复制父进程的task_struct到新页面 *p = *current; // 整体复制结构体 // 设置新进程的内核栈顶指针 // 内核栈从页面顶部开始 p->tss.esp0 = PAGE_SIZE + (long) p; // 页面起始地址 + 4096 = 页面顶部 p->tss.ss0 = 0x10; // 内核数据段 // ... 其他初始化}
潜在风险和保护:
如果内核栈使用过多(比如深度递归或大量局部变量),可能会向下增长覆盖task_struct区域,导致严重的系统崩溃。Linux 0.12没有特殊的栈溢出保护机制,这要求内核代码必须谨慎使用栈空间。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 // 危险示例: 内核栈溢出void dangerous_function() { char large_buffer[3000]; // 局部变量占用3000字节 // 如果此函数嵌套调用或有更多局部变量 // 可能导致栈指针越过task_struct,破坏进程控制块!}// 安全做法: 使用动态分配void safe_function() { char *buffer = (char *)malloc(3000); // 从堆分配 if (!buffer) return; // 处理分配失败 // 使用buffer... free(buffer); // 释放}
3.1.4 全局进程表task数组
系统中所有进程的task_struct指针被存储在一个全局数组task[NR_TASKS]中,让我们看定义:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 // include/linux/sched.h#define NR_TASKS 64 // 最多支持64个并发进程// 全局进程表,每个元素指向一个task_structstruct task_struct * task[NR_TASKS] = { &(init_task.task), // task[0] 固定指向进程0 NULL, // task[1] 初始为NULL,后来是进程1(init) NULL, NULL, NULL, ... // 其余初始化为NULL};// 进程0的task_struct是静态定义的,不需要动态分配union task_union {struct task_struct task; // task_struct结构 char stack[PAGE_SIZE]; // 4KB空间,确保对齐};// init_task是静态定义的进程0staticunion task_union init_task = {INIT_TASK,};// INIT_TASK宏展开后初始化task_struct的所有字段
进程号的分配机制:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 // kernel/fork.c 中分配新进程号static int last_pid = 0; // 上次分配的PID// 找到一个空闲的task数组项并分配唯一PIDint find_empty_process(void){ int i; // 循环分配新PID,确保全局唯一repeat: if ((++last_pid) < 0) // PID溢出,重新从1开始 last_pid = 1; // PID=0保留给进程0 // 检查last_pid是否已被使用 for(i=0 ; i<NR_TASKS ; i++) { if (task[i] && task[i]->pid == last_pid) goto repeat; // PID已占用,尝试下一个 } // 找到空闲的task数组项 for(i=1 ; i<NR_TASKS ; i++) { // 从i=1开始,因为0给了进程0 if (!task[i]) // 找到NULL项 return i; // 返回数组索引 } return -EAGAIN; // 没有空闲项,进程表已满}// 使用示例:sys_fork() { int nr; // 新进程在task数组中的索引 nr = find_empty_process(); // 分配索引和PID if (nr < 0) return nr; // 分配失败 // 此时 last_pid 包含了分配给新进程的PID // nr 是新进程在task数组中的位置 copy_process(..., nr); // 创建进程}
进程表的搜索和遍历:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 // 搜索特定进程的例子// 1. 根据PID查找进程struct task_struct* find_task_by_pid(int pid) { int i; for (i=0; i<NR_TASKS; i++) { if (task[i] && task[i]->pid == pid) return task[i]; // 找到返回指针 } return NULL; // 未找到}// 2. 遍历所有RUNNING进程 (调度器使用)void schedule(void) { int i, next, c;struct task_struct ** p; // 遍历所有进程检查alarm和timeout for(p = &LAST_TASK ; p > &FIRST_TASK ; --p) { // LAST_TASK = &task[NR_TASKS-1] // FIRST_TASK = &task[0] // 从task数组末尾往前遍历 if (!(*p)) // 跳过NULL项 continue; // 检查alarm定时器 if ((*p)->alarm && (*p)->alarm < jiffies) { // jiffies是系统滴答计数,每10ms增加1 (*p)->signal |= (1<<(SIGALRM-1)); // 发送SIGALRM信号 (*p)->alarm = 0; // 清除alarm } // 检查timeout定时器 if ((*p)->timeout && (*p)->timeout < jiffies) { (*p)->state = TASK_RUNNING; // 唤醒进程 (*p)->timeout = 0; } } // ... 继续进行进程选择}// 3. 统计活跃进程数量int count_active_processes(void) { int count = 0; int i; for (i=0; i<NR_TASKS; i++) { if (task[i] && task[i]->state != TASK_ZOMBIE) count++; // 非僵尸进程计数 } return count;}
进程表的限制和影响:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
这种简单的数组结构虽然效率不高,但对于进程数量有限的嵌入式系统来说已经足够。后期的Linux版本采用了哈希表、红黑树等复杂数据结构来优化进程管理。
3.2 进程的创建:fork系统调用深度剖析
3.2.1 fork()调用链路跟踪
在Unix/Linux世界中,进程的创建是通过fork()系统调用完成的。fork()的语义非常独特:父进程调用fork()后,会创建出一个几乎完全相同的子进程,然后父子进程都从fork()调用返回。父进程中fork()返回子进程的PID,而子进程中fork()返回0。这种“一次调用,两次返回”的魔法是通过精巧的寄存器操作实现的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 // 用户程序调用fork的典型例子#include <unistd.h>#include <stdio.h>int main() { int pid; int x = 100; // 父进程的局部变量 printf("Before fork, x=%d\n", x); pid = fork(); // 调用fork创建子进程 if (pid < 0) { // fork失败 printf("Fork failed!\n"); return -1; } else if (pid == 0) { // 子进程: fork返回0 printf("Child process: pid=%d, x=%d\n", getpid(), x); x = 200; // 子进程修改x printf("Child: modified x=%d\n", x); } else { // 父进程: fork返回子进程pid printf("Parent process: child_pid=%d, x=%d\n", pid, x); sleep(1); // 等待子进程执行 printf("Parent: x is still %d\n", x); // 父进程的x仍然是100,不受子进程影响 } return 0;}
fork()系统调用的完整调用链:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 用户态: fork() [库函数] ↓ int 0x80 [软中断,进入内核态] ↓内核态: system_call [中断入口, kernel/system_call.s] ↓ sys_fork [系统调用处理函数, kernel/system_call.s] ↓ find_empty_process() [分配PID和task槽位, kernel/fork.c] ↓ copy_process() [复制进程, kernel/fork.c] │ ├─> get_free_page() [分配物理页面] ├─> copy_mem() [复制内存页表,COW机制] ├─> copy_files() [复制文件描述符表] └─> set_tss_desc() [设置TSS描述符]
3.2.2 sys_fork汇编入口分析
当用户态程序调用fork()时,会触发int 0x80中断进入内核。system_call中断处理程序根据系统调用号查找sys_call_table,找到对应的sys_fork函数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 # kernel/system_call.s - sys_fork汇编代码.align 2 # 2字节对齐sys_fork: # fork系统调用入口 # 保存调用环境,为copy_process准备参数 call find_empty_process # 分配PID和task数组索引 testl %eax,%eax # 检查返回值 js 1f # 负数表示失败,跳转到标号1 # 为copy_process准备参数(从esp中获取) pushl %gs # 压入gs段寄存器 pushl %esi # 压入esi pushl %edi # 压入edi pushl %ebp # 压入ebp pushl %eax # 压入nr(find_empty_process的返回值) # 调用copy_process(所有参数已在栈上) call copy_process # 创建新进程 # 清理栈,移除5个参数 addl $20,%esp # esp += 20 (5个4字节参数)1: # 返回标签 ret # 返回到system_call,eax中是子进程PID# 对于system_call:# - 父进程从这里返回,eax=子进程PID# - 子进程第一次被调度时,从tss.eip指定的位置开始# 它的tss.eax已被copy_process设置为0# 因此子进程中fork()返回0
关键点说明:
-
1. find_empty_process(): 返回值存在eax中,包含: -
• 成功: 返回task数组索引 (0-63) -
• 失败: 返回负数错误码 (-EAGAIN=-11) -
2. 参数传递: copy_process需要的参数都通过栈传递: -
• gs, esi, edi, ebp: 父进程的寄存器状态 -
• eax (nr): task数组索引 -
3. 返回值处理: -
• 父进程: eax中是copy_process返回的子进程PID -
• 子进程: 第一次调度时,eax已被设置为0
3.2.3 copy_process()函数深度剖析
copy_process()是fork的真正核心。让我们通过完整的源代码分析来理解子进程的诞生过程:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 // kernel/fork.c - copy_process函数完整实现int copy_process(int nr, long ebp, long edi, long esi, long gs, long none, long ebx, long ecx, long edx, long fs, long es, long ds, long eip, long cs, long eflags, long esp, long ss){ /* 参数说明: * nr: task数组索引,由find_empty_process()分配 * 其他参数: 父进程调用fork时的寄存器状态 * 这些参数由sys_fork压入栈,按照中断发生时的顺序排列 */struct task_struct *p; // 新进程的task_struct指针 int i;struct file *f; /*=== 步骤1: 分配一个空闲页面用于task_struct和内核栈 ===*/ p = (struct task_struct *) get_free_page(); if (!p) // 内存分配失败 return -EAGAIN; // 返回错误码:资源暂时不可用 /*=== 步骤2: 将新进程加入全局task数组 ===*/ task[nr] = p; // task[nr]指向新分配的页面 /*=== 步骤3: 复制父进程的task_struct ===*/ *p = *current; // 整体复制结构体,子进程继承父进程属性 // current是全局变量,指向当前进程(父进程) /*=== 步骤4: 修改子进程的状态字段 ===*/ p->state = TASK_UNINTERRUPTIBLE; // 设置为不可中断睡眠 // 防止子进程初始化未完成时被调度 p->pid = last_pid; // 设置进程号(find_empty_process已分配) p->father = current->pid; // 记录父进程的PID p->counter = p->priority; // 重置时间片为优先级值(默认15) p->signal = 0; // 清除信号位图 p->alarm = 0; // 清除报警定时器 p->leader = 0; // 不是session leader // 统计信息重置 p->utime = p->stime = 0; // 用户态/内核态时间清零 p->cutime = p->cstime = 0; // 子进程的时间统计清零 p->start_time = jiffies; // 记录创建时间(系统滴答数) /*=== 步骤5: 设置子进程的TSS ===*/ // 设置内核态栈指针 p->tss.back_link = 0; // Linux不使用硬件任务链 p->tss.esp0 = PAGE_SIZE + (long) p; // 内核栈顶部 = 页面起始地址+4KB p->tss.ss0 = 0x10; // 内核数据段选择符 // 0x10 = GDT[2], DPL=0 // 设置eip为父进程调用fork时的下一条指令 p->tss.eip = eip; // 子进程从fork()调用之后继续执行 // 关键!设置eax为0,这就是fork在子进程中返回0的秘密 p->tss.eax = 0; // fork()在子进程中返回0 // 复制其他寄存器(从sys_fork的参数获取) p->tss.ecx = ecx; p->tss.edx = edx; p->tss.ebx = ebx; p->tss.esp = esp; // 用户态栈指针 p->tss.ebp = ebp; p->tss.esi = esi; p->tss.edi = edi; // 复制段寄存器 p->tss.es = es & 0xffff; // 只取低16位(段选择符) p->tss.cs = cs & 0xffff; p->tss.ss = ss & 0xffff; p->tss.ds = ds & 0xffff; p->tss.fs = fs & 0xffff; p->tss.gs = gs & 0xffff; // 复制标志寄存器 p->tss.eflags = eflags; // 继承父进程的标志 // 设置LDT选择符 p->tss.ldt = _LDT(nr); // 指向GDT中的LDT描述符 // _LDT(nr) = (((nr)<<4)+(FIRST_LDT_ENTRY<<3)) // 设置I/O位图偏移 p->tss.trace_bitmap = 0x80000000; // 无I/O位图(高16位表示偏移) /*=== 步骤6: 复制页表(实现写时复制COW) ===*/ if (copy_mem(nr,p)) { // 复制内存管理信息 task[nr] = NULL; // 失败则清空task项 free_page((long) p); // 释放分配的页面 return -EAGAIN; } /*=== 步骤7: 复制文件描述符表 ===*/ for (i=0; i<NR_OPEN;i++) // 遍历所有文件描述符 if ((f=p->filp[i])) f->f_count++; // 增加文件引用计数 // 父子进程共享打开的文件 // inode引用计数增加 if (current->pwd) // 当前工作目录 current->pwd->i_count++; if (current->root) // 根目录 current->root->i_count++; if (current->executable) // 执行文件 current->executable->i_count++; /*=== 步骤8: 在GDT中设置子进程的TSS和LDT描述符 ===*/ set_tss_desc(gdt+(nr<<1)+FIRST_TSS_ENTRY, &(p->tss)); // nr<<1: 每个进程占用2个GDT项(TSS和LDT) // FIRST_TSS_ENTRY: 第一个TSS在GDT中的索引位置 set_ldt_desc(gdt+(nr<<1)+FIRST_LDT_ENTRY, &(p->ldt)); // 设置LDT描述符,紧跟在TSS之后 /*=== 步骤9: 将子进程设置为就绪状态 ===*/ p->state = TASK_RUNNING; // 现在可以被调度了 /*=== 步骤10: 返回子进程的PID给父进程 ===*/ return last_pid; // 返回子进程PID // 这个值会成为父进程中fork()的返回值}
关键技术点解析:
-
1. eax寄存器的魔法 ( p->tss.eax = 0): -
• 父进程: fork()返回值来自copy_process的返回值 (last_pid) -
• 子进程: 第一次被调度时,从TSS恢复eax=0,fork()返回0 -
2. eip的设置 ( p->tss.eip = eip): -
• 子进程的eip指向父进程调用fork()之后的下一条指令 -
• 这使得子进程仍然执行 if (pid == 0)的判断逻辑 -
3. 两个栈的设置: -
• p->tss.esp0: 内核态栈,指向新分配页面的顶部 -
• p->tss.esp: 用户态栈,继承父进程的栈指针(COW保护)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 // 图解:fork返回值的不同来源父进程的执行路径:fork() -> sys_fork() -> copy_process() -> return last_pid │ │ └────────────────────────────────┘ eax = last_pid 父进程中fork()返回子进程PID子进程的执行路径:等待调度... ↓schedule() 选中子进程 ↓switch_to() 硬件任务切换 ↓CPU从子进程的TSS加载寄存器: eax = p->tss.eax = 0 <- copy_process中设置的 eip = p->tss.eip = 父进程fork后的地址 ↓子进程从 fork() 调用之后继续执行 eax中的值0成为fork()的返回值
3.2.4 写时复制(COW)技术详解
copy_process()还需要处理内存和文件的复制。copy_mem()负责复制进程的页表,但这里运用了写时复制(Copy-On-Write,COW)技术:子进程的页表项指向和父进程相同的物理页面,只是将这些页表项都标记为只读。当父进程或子进程任一方试图写入这些页面时,会触发页面保护异常,此时内核才真正分配新的物理页面并复制数据,然后将页表项改为可写。这样可以大大减少fork()的开销,因为很多时候子进程fork后会立即调用exec()加载新程序,那些复制的内存页面根本用不到。
copy_files()复制父进程的文件描述符表,使子进程打开的文件与父进程相同。不过这里只是复制了文件描述符,文件本身(file结构)是共享的,因此父子进程的文件读写位置是同步的。每个file结构都有一个引用计数,copy_files()会将相关文件的引用计数加1。
3.3 进程调度算法
进程调度是操作系统的心脏。Linux 0.12的调度器核心是schedule()函数,它在每次时钟中断(每10ms)、进程主动睡眠或等待资源时被调用。schedule()的任务是从所有就绪进程中选出一个最值得运行的进程,然后切换到它。
schedule()采用的调度算法很简单但很有效。它首先遍历整个task数组,检查每个进程的alarm和timeout定时器是否到期,如果到期就将处于TASK_INTERRUPTIBLE状态的进程唤醒(设置为TASK_RUNNING)。同时检查进程是否收到未被阻塞的信号,如果有也将其唤醒。
完成唤醒工作后,schedule()进入主要的调度逻辑:再次遍历task数组,在所有处于TASK_RUNNING状态的进程中,找出counter值最大的那个。counter代表进程剩余的时间片,初始值等于进程的优先级priority(通常为15)。每次时钟中断时,当前运行进程的counter减1,当counter降到0时,该进程的时间片用完,需要重新调度。
这种基于时间片轮转的调度算法保证了公平性:每个进程都能获得一定的CPU时间。counter最大的进程会被选中,如果有多个进程counter相同,则选择task数组中靠前的那个。当所有就绪进程的counter都变成0时(所有进程时间片都用完),schedule()会重新计算每个进程的counter值,计算公式是:counter = counter/2 + priority。这个公式有个巧妙之处:如果进程之前没用完时间片(counter还有剩余),那么剩余部分的一半会累积到下一轮,这样可以奖励那些I/O密集型的进程,让它们获得更好的响应时间。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 schedule()│├── 第一阶段:检查定时器│ ││ └── 遍历所有进程│ ││ ├── 定时器到期? ──是──► 唤醒 INTERRUPTIBLE 进程│ ││ └── 继续检查下一个进程│├── 第二阶段:选择 counter 最大的 RUNNING 进程│ ││ ├── 找到了? ──是──► 切换到该进程│ ││ └── 找不到│ ││ ├── 所有 counter 都为 0?│ │ ││ │ ├── 是 ──► 重新计算 counter│ │ │ ││ │ │ └── counter = counter/2 + priority│ │ │ ││ │ │ └── 返回重新寻找│ │ ││ │ └── 否 ──► 切换到进程0 (idle进程)│ │└── (结束)
进程切换本身由switch_to宏完成,它是一段精心编写的汇编代码。switch_to的核心是ljmp指令,这条指令会触发x86的硬件任务切换机制:CPU自动将当前进程的所有寄存器保存到其TSS中,然后从新进程的TSS中加载寄存器。整个过程由硬件完成,非常高效。switch_to还会切换LDT(Local Descriptor Table),因为每个进程有自己的代码段和数据段描述符。
3.4 进程的状态转换
Linux 0.12中进程有五种基本状态:TASK_RUNNING(就绪或运行)、TASK_INTERRUPTIBLE(可中断睡眠)、TASK_UNINTERRUPTIBLE(不可中断睡眠)、TASK_ZOMBIE(僵尸)、TASK_STOPPED(停止)。
TASK_RUNNING状态的进程等待被调度执行,如果它被schedule()选中,就会真正占用CPU运行。一个进程可能因为等待资源(如磁盘I/O、键盘输入)而进入睡眠状态。TASK_INTERRUPTIBLE表示进程在等待某个事件,但可以被信号唤醒;TASK_UNINTERRUPTIBLE则是不可被信号打断的深度睡眠,通常用于等待硬件操作完成,以避免数据不一致。
当进程完成任务调用exit()系统调用时,它会进入TASK_ZOMBIE僵尸状态。僵尸进程已经终止,释放了大部分资源,但task_struct还保留着,等待父进程通过wait()或waitpid()系统调用收集其退出状态。如果父进程不收集,僵尸进程就会一直占用task数组的一个槽位。这就像人死后的墓碑,记录着逝者的信息,直到有人来祭拜并彻底安葬。
TASK_STOPPED状态用于调试场景,当进程收到SIGSTOP信号时会进入这个状态,暂停执行,直到收到SIGCONT信号才恢复运行。这是调试器(如gdb)实现断点的基础。
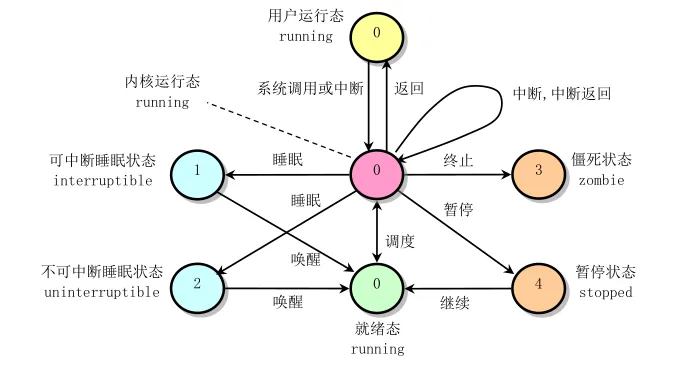
进程状态转换是由各种内核函数触发的。sleep_on()函数将当前进程设置为TASK_UNINTERRUPTIBLE并调用schedule(),让出CPU;wake_up()函数将等待队列中的进程唤醒为TASK_RUNNING。interruptible_sleep_on()和wake_up_interruptible()是它们的可中断版本。这些函数配合使用,实现了进程间的同步和互斥。
3.5 进程的睡眠与唤醒
sleep_on()和wake_up()是进程同步的基础设施。当进程需要等待某个事件(比如等待磁盘读取完成)时,它会调用sleep_on(等待队列指针),将自己加入等待队列并睡眠。等待队列其实是一个简单的单向链表,每个进程的task_struct中有一个wait字段作为链表节点。
sleep_on()的实现有个有趣的细节:它使用了栈上的局部变量来构建等待队列。当进程A调用sleep_on(&wait_queue)时,wait_queue指向的是之前等待的进程B的栈上变量,A会将自己的栈变量链接到这个链上,然后将wait_queue指向自己。这样就形成了一个后进先出的等待队列。当wake_up(&wait_queue)被调用时,队列中的所有进程都会被唤醒(设置为TASK_RUNNING)。
这种设计虽然简单,但有个缺点:无法精确唤醒特定进程,只能一次性唤醒所有等待者。在后来的Linux版本中,这个机制被更复杂但更灵活的waitqueue和select/poll/epoll机制取代。
3.6 进程的终止与回收
进程通过exit()系统调用终止。do_exit()是exit()的内核实现,它负责清理进程占用的各种资源。首先关闭进程打开的所有文件,通过将file结构的引用计数减1来实现,如果引用计数降为0则真正释放file结构。然后清理进程当前工作目录、根目录、可执行文件的inode,同样是通过减少引用计数。
接下来do_exit()处理子进程:如果当前进程有子进程,将它们的父进程改为进程1(init)。这样就不会出现孤儿进程没人管的情况,init会负责回收这些进程。然后do_exit()将当前进程设置为TASK_ZOMBIE僵尸状态,并向父进程发送SIGCHLD信号通知父进程。
最后do_exit()调用schedule()进行调度。注意此时进程已经是僵尸状态,schedule()永远不会再选中它执行,因此这个schedule()调用永不返回。进程就这样静静地躺在task数组中,等待父进程来收尸。
父进程通过wait()或waitpid()系统调用来回收子进程。sys_waitpid()会扫描task数组,查找调用进程的僵尸子进程。找到后,它会获取子进程的退出码,然后调用release()函数释放子进程的task_struct所占用的物理页面,并将task数组中的对应项设为NULL。至此,进程的生命周期彻底结束,它占用的所有资源都已归还系统。
3.7 实际示例:一个fork-exec-wait的完整流程
让我们通过一个shell执行命令的实际场景来串联所有知识点。假设用户在shell中输入”ls”命令。
shell进程(假设PID为5)收到用户输入后,调用fork()创建子进程。fork()进入内核后,find_empty_process()找到task数组中空闲的第10项,分配PID为10。copy_process()分配一个物理页面给进程10的task_struct,复制进程5的内容,设置进程10的TSS.eax为0,复制页表(使用COW)。进程10被设置为TASK_RUNNING状态并返回到进程5,fork()在进程5中返回10。
进程5(父进程)调用wait()等待子进程结束,进入TASK_INTERRUPTIBLE状态并让出CPU。此时schedule()遍历task数组,发现进程10处于RUNNING状态且counter较大,切换到进程10执行。
进程10从fork()返回,得到返回值0,知道自己是子进程。接着它调用execve(“/bin/ls”, …)。do_execve()首先释放进程10从父进程继承的页面(由于使用了COW,这些页面可能还没被真正复制),然后打开/bin/ls文件,读取其ELF头,分配新的页面,将ls程序的代码和数据加载到进程10的地址空间,设置新的eip指向ls程序的入口地址。从do_execve()返回后,进程10已经”脱胎换骨”,变成了ls程序。
ls程序运行,读取目录内容并输出到终端。输出完成后,ls调用exit(0)退出。do_exit()关闭ls打开的文件,释放内存页面,将进程10设为TASK_ZOMBIE状态,向父进程5发送SIGCHLD信号。进程5被唤醒,从wait()返回,获取子进程的退出码0,调用release()释放进程10的task_struct页面,task[10]被设为NULL。进程5继续显示shell提示符,等待下一条命令。
3.8 进程0和进程1的特殊性
进程0(idle进程)和进程1(init进程)在Linux系统中有特殊地位。进程0是系统初始化过程中唯一不通过fork创建的进程,它的task_struct是静态定义的init_task。在main()函数完成所有初始化工作后,通过move_to_user_mode()切换到用户态,此时main()函数所在的执行流就成为进程0。进程0然后fork出进程1,自己则进入一个死循环,不停调用pause()睡眠。
进程0的作用是作为idle进程:当系统中所有其他进程都处于等待状态(没有RUNNING进程)时,schedule()会选择进程0运行。进程0执行pause()后又立即被调度换出(因为它变成了INTERRUPTIBLE状态)。实际上,进程0的存在保证了schedule()永远能找到一个可运行的进程(因为进程0的state字段实际上never被使用,它总被当作可运行的),避免了系统无事可做时的特殊处理。
进程1是init进程,它是所有用户进程的祖先。init进程的工作是打开终端设备,然后在死循环中fork子进程来执行shell。如果shell退出(用户logout),init会再次fork新的shell。init还负责回收那些父进程先于子进程退出而成为孤儿的进程。由于do_exit()会将孤儿进程的父进程改为进程1,因此init需要不断调用wait()来回收这些僵尸进程。
|
|
|
|
|
|
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
通过本章的学习,我们深入理解了Linux 0.12的进程管理机制:从进程的数据结构task_struct,到进程的创建、调度、状态转换、睡眠唤醒、终止回收,以及特殊的进程0和进程1。这些机制协同工作,实现了一个完整的多任务操作系统。虽然Linux 0.12的进程管理相对简单,但它已经包含了现代操作系统进程管理的基本思想,后续的Linux版本在此基础上不断优化和扩展,形成了今天强大的进程管理系统。
3.9 参考资料
本章内容基于以下资料编写:
Intel官方文档
-
• Intel 80386 Programmer’s Reference Manual (1986) -
• Chapter 7: Multitasking – 详细描述了TSS和硬件任务切换机制 -
• Chapter 6: Protection – 介绍了特权级和LDT的使用 -
• 在线阅读:https://css.csail.mit.edu/6.858/2014/readings/i386.pdf
Linux 0.12源代码文件
-
• kernel/sched.c – schedule()调度函数、sleep_on()、wake_up()等 -
• kernel/fork.c – fork()系统调用实现、copy_process() -
• kernel/exit.c – exit()系统调用实现、do_exit()、wait() -
• kernel/system_call.s – 进程切换的汇编代码switch_to -
• include/linux/sched.h – task_struct结构定义、进程状态常量
“治大国若烹小鲜。” —— 老子