 夜雨聆风
夜雨聆风





OpenAI 是怎么做 Harness 的
今天聊聊 OpenAI 的 Harness 工程——以及他们开源的 Symphony。

先说个数字:0。
OpenAI 有个团队,用 0 行人类手写代码,建了一个百万行级别的真实产品。

0 行手写代码,100 万行 AI 代码
2026 年 2 月,OpenAI 发了一篇官方博文,标题是 “Harness engineering: leveraging Codex in an agent-first world”。作者 Ryan Lopopolo(OpenAI 技术团队成员)开篇就扔了个炸弹:
“Over the past five months, our team has been running an experiment: building and shipping an internal beta of a software product with 0 lines of manually-written code.”
“The product has internal daily users and external alpha testers. It ships, deploys, breaks, and gets fixed.”
“We estimate that we built this in about 1/10th the time it would have taken to write the code by hand.”
然后是这句,我觉得整篇文章的精华就在这里:
“Humans steer. Agents execute.”
人类方向盘,agent 踩油门。
他们从 2025 年 8 月一个空 git 仓库起步,5 个月后,仓库大约 100 万行代码,1500 个 PR,3 个工程师驱动 Codex。平均每个工程师每天 3.5 个 PR。
不是 demo,不是 toy project。是有真实用户在用的产品。
所以,什么是 Harness?
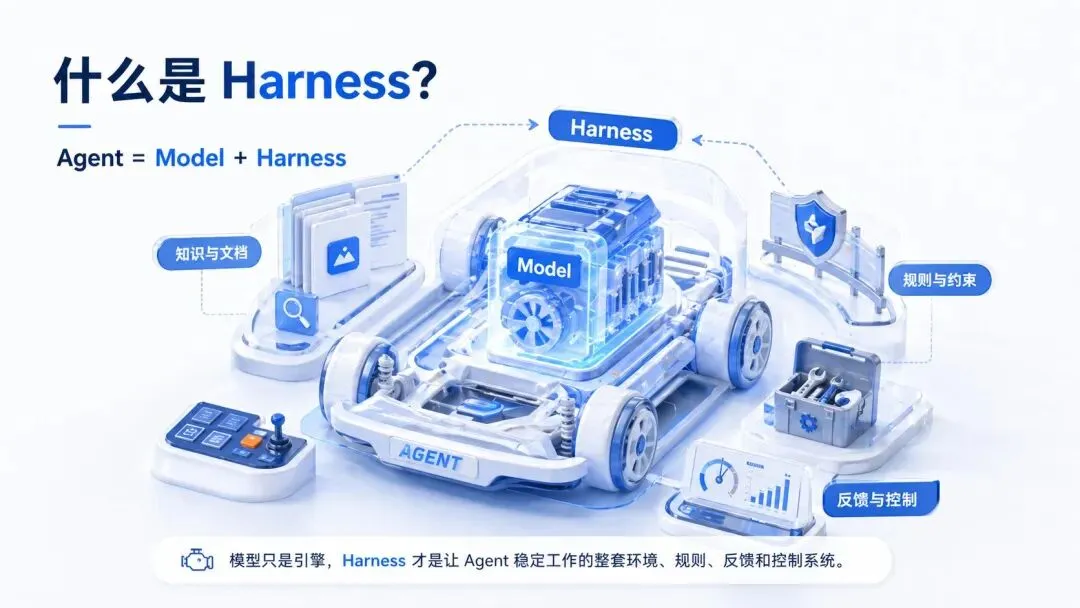
OpenAI 这篇文章第一次正式命名了一个概念:Harness Engineering(缰绳工程)。
这个概念之前没有人这么叫过,但 OpenAI 干的事其实就是这个意思。Martin Fowler 的团队(Thoughtworks)在 2026 年 4 月也写了一篇长文来拆解这件事,给了一个很清晰的关系式:
“The term harness has emerged as a shorthand to mean everything in an AI agent except the model itself — Agent = Model + Harness.”
模型是引擎,Harness 是整辆车。引擎人人都有,但好车不是人人都能造。
具体到 OpenAI 的实践,他们的总结是:
“Our most difficult challenges now center on designing environments, feedback loops, and control systems that help agents accomplish our goal.”
翻译成人话:最难的事不是让 AI 写代码,是给 AI 建一个让它能靠谱写代码的环境。
OpenAI 的 Harness 长什么样?四个核心设计
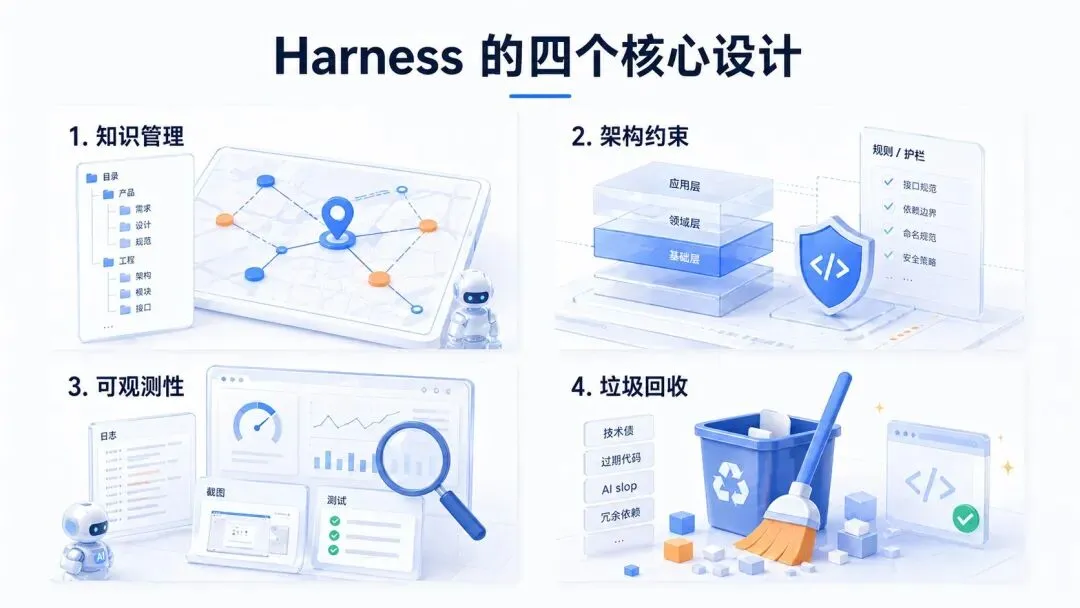
设计一:知识管理——给地图,不给百科全书
OpenAI 一开始也踩了坑。他们试过写一个巨大的 AGENTS.md,把所有规则都塞进去。失败了。
他们的反思非常到位,我直接引用原文:
“We tried the ‘one big AGENTS.md’ approach. It failed in predictable ways:
-
Context is a scarce resource. A giant instruction file crowds out the task, the code, and the relevant docs—so the agent either misses key constraints or starts optimizing for the wrong ones.
-
Too much guidance becomes non-guidance. When everything is ‘important,’ nothing is.
-
It rots instantly. A monolithic manual turns into a graveyard of stale rules.
-
It’s hard to verify. A single blob doesn’t lend itself to mechanical checks.”
这四条,每一条都值得细品。尤其是第二条——“当一切都很重要,就什么都不重要了”——这不仅是 AI 编程的问题,这是所有知识管理的通病。
他们的解法是这样的:
“So instead of treating AGENTS.md as the encyclopedia, we treat it as the table of contents.”
AGENTS.md 大约 100 行,就是个目录。真正的知识存在结构化的 docs/ 目录里。他们给了一个完整的仓库知识结构:
AGENTS.md
ARCHITECTURE.md
docs/
├── design-docs/
│ ├── index.md
│ ├── core-beliefs.md
│ └── ...
├── exec-plans/
│ ├── active/
│ ├── completed/
│ └── tech-debt-tracker.md
├── generated/
│ └── db-schema.md
├── product-specs/
│ ├── index.md
│ ├── new-user-onboarding.md
│ └── ...
├── references/
│ ├── design-system-reference-llms.txt
│ ├── nixpacks-llms.txt
│ ├── uv-llms.txt
│ └── ...
├── DESIGN.md
├── FRONTEND.md
├── PLANS.md
├── PRODUCT_SENSE.md
├── QUALITY_SCORE.md
├── RELIABILITY.md
└── SECURITY.md注意几个有意思的设计:
-
core-beliefs.md——他们管这个叫”核心信念”,定义了 agent-first 的操作原则
-
tech-debt-tracker.md——技术债也是版本化管理的,不是口头说说
-
references/ 下的文件名都带 llms.txt 后缀——这是专门给 AI 看的版本,跟给人看的不一样
-
QUALITY_SCORE.md——给每个产品域和架构层打分,追踪质量缺口
他们叫这个 “渐进式披露(Progressive disclosure)”:
“Agents start with a small, stable entry point and are taught where to look next, rather than being overwhelmed up front.”
但关键是,他们不只是写了文档,还用机器来保证文档质量:
“Dedicated linters and CI jobs validate that the knowledge base is up to date, cross-linked, and structured correctly. A recurring ‘doc-gardening’ agent scans for stale or obsolete documentation that does not reflect the real code behavior and opens fix-up pull requests.”
文档也有 CI,也有自动清理。这不是写完就完了,是活的系统。
设计二:架构约束——用代码管代码
光有文档不够。OpenAI 的原话:
“Documentation alone doesn’t keep a fully agent-generated codebase coherent. By enforcing invariants, not micromanaging implementations, we let agents ship fast without undermining the foundation.“
他们给每个业务域定义了严格的分层:
Types → Config → Repo → Service → Runtime → UI跨域关注(auth、telemetry、feature flags)只能通过一个明确的入口:Providers。
这些约束不是靠”大家自觉”——是用 agent 自己写的 linter 和结构测试强制执行。
有一个细节特别有意思。他们说了怎么处理”品味”问题:
“We require Codex to parse data shapes at the boundary, but are not prescriptive on how that happens (the model seems to like Zod, but we didn’t specify that specific library).”
注意这个微妙之处:边界是硬约束,边界内是自由。你必须做数据校验(边界),但用什么库是你的自由(内部)。
这个理念 Martin Fowler 说得更直白:
“With agents, they become multipliers: once encoded, they apply everywhere at once.”
你写一条规则,agent 跑 100 次就自动执行 100 次。在人类-first 的工作流里,这些规则可能让人觉得”太死板了”。但在 agent-first 的工作流里,它们是乘数效应。
还有一个设计哲学我觉得特别高级:
“In the same way teams aim to improve navigability of their code for new engineering hires, our human engineers’ goal was making it possible for an agent to reason about the full business domain directly from the repository itself.”
代码仓库首先是给 agent 看的,其次才是给人看的。 这个优先级的反转,是 Harness 工程的核心心智模式。
他们甚至画了一张图来解释这件事,配文是:
“From the agent’s point of view, anything it can’t access in-context while running effectively doesn’t exist.”
在 agent 看来,它看不到的东西就是不存在的。Slack 里的讨论?Google Docs 里的文档?某个人脑子里的隐性知识?对 agent 来说,这些东西跟不存在没区别。
“That Slack discussion that aligned the team on an architectural pattern? If it isn’t discoverable to the agent, it’s illegible in the same way it would be unknown to a new hire joining three months later.”
所以他们的原则是:所有对 agent 重要的信息,必须编码进仓库。 不是复制粘贴,是把它变成版本化、可索引、可验证的工件。
设计三:可观测性——让 AI 自己验证自己的工作
这个设计是我觉得最精彩的。
OpenAI 把应用做了 worktree 级别的隔离——每个 git worktree 可以独立启动一个应用实例。然后他们把 Chrome DevTools Protocol 接入了 agent 运行时。
原始描述:
“We made the app bootable per git worktree, so Codex could launch and drive one instance per change. We also wired the Chrome DevTools Protocol into the agent runtime and created skills for working with DOM snapshots, screenshots, and navigation. This enabled Codex to reproduce bugs, validate fixes, and reason about UI behavior directly.”
结果是什么?Codex 可以自己:
-
启动应用实例
-
截图对比(修改前 vs 修改后)
-
观察 runtime 事件
-
发现 bug → 修 bug → 重启 → 再验证
-
循环,直到确认修好
它把应用变成了一台测试仪,agent 自己就是测试员。
日志和监控也是同样的思路。他们给每个 worktree 配了完整的可观测性栈:
“Logs, metrics, and traces are exposed to Codex via a local observability stack that’s ephemeral for any given worktree. Codex works on a fully isolated version of that app—including its logs and metrics, which get torn down once that task is complete. Agents can query logs with LogQL and metrics with PromQL.”
注意那个”ephemeral”——临时性的。每个 worktree 的日志和监控都是临时的,任务完成就销毁。干净利落。
所以像这样的指令:
“ensure service startup completes in under 800ms”
对 Codex 来说不是口号——它真的可以自己启动应用、测延迟、如果超过 800ms 就改代码、再测,循环到达标为止。
效果呢?
“We regularly see single Codex runs work on a single task for upwards of six hours (often while the humans are sleeping).”
单次运行连续工作 6 小时以上,经常是人类在睡觉的时候。
设计四:垃圾回收——对抗 AI 的熵增
全自动化有个天然问题。OpenAI 的描述很诚实:
“Codex replicates patterns that already exist in the repository—even uneven or suboptimal ones. Over time, this inevitably leads to drift.”
AI 会复制已有的模式,包括不好的模式。时间一长,代码质量就会漂移(drift)。
他们一开始怎么处理的?人力:
“Initially, humans addressed this manually. Our team used to spend every Friday (20% of the week) cleaning up ‘AI slop.’ Unsurprisingly, that didn’t scale.”
每周五花 20% 的时间清理 AI 生成的垃圾代码。这画面太真实了。
他们的解法叫 “Golden Principles”(黄金原则)——把人类品味编码成机械规则:
“These principles are opinionated, mechanical rules that keep the codebase legible and consistent for future agent runs. For example: (1) we prefer shared utility packages over hand-rolled helpers to keep invariants centralized, and (2) we don’t probe data ‘YOLO-style’—we validate boundaries or rely on typed SDKs so the agent can’t accidentally build on guessed shapes.”
然后他们建了一个定期自动扫描系统:
“On a regular cadence, we have a set of background Codex tasks that scan for deviations, update quality grades, and open targeted refactoring pull requests. Most of these can be reviewed in under a minute and automerged.”
大多数修复 PR 不到 1 分钟 review 完,自动 merge。他们管这叫代码的垃圾回收(Garbage Collection):
“Technical debt is like a high-interest loan: it’s almost always better to pay it down continuously in small increments than to let it compound and tackle it in painful bursts.”
技术债就像高利贷:小额持续还,远比一次性清盘划算。
“Human taste is captured once, then enforced continuously on every line of code.”
人类品味编码一次,然后在每一行代码上持续执行。这个表述太精准了。
Symphony:团队级 Harness 的开源实现

2026 年 3 月 5 日,OpenAI 开源了 Symphony。如果说上面那些是”单个 agent 的 Harness”,那 Symphony 就是团队级的 Harness。

GitHub 仓库的描述:
“Symphony turns project work into isolated, autonomous implementation runs, allowing teams to manage work instead of supervising coding agents.”
Symphony 不是另一个 agent 框架,不是聊天机器人加工具。它是一个用 Elixir/OTP 写的长运行编排服务,核心就干一件事:轮询你的 Linear 看板,自动给每个 issue 派一个 Codex agent,在独立 workspace 里干活,交付 PR。全程不需要人类在中间盯着。
GitHub README 里有个 demo 视频的描述:
“In this demo video, Symphony monitors a Linear board for work and spawns agents to handle the tasks. The agents complete the tasks and provide proof of work: CI status, PR review feedback, complexity analysis, and walkthrough videos. When accepted, the agents land the PR safely. Engineers do not need to supervise Codex; they can manage the work at a higher level.”
agent 交付的”工作证明”包括:CI 状态、PR 审查反馈、复杂度分析、以及操作演示视频。
为什么用 Elixir?
这个问题 Stephen Jones 在他的深度拆解文章里解释得很清楚:
“The choice of Elixir isn’t cosmetic. The BEAM VM’s OTP supervision trees give Symphony exactly what an agent orchestrator needs: fault-tolerant process isolation. When one agent crashes (and they will), it triggers a supervised restart with full error context while every other agent continues working.
This is the kind of thing you’d spend months building in Python or TypeScript—process isolation, supervision strategies, graceful degradation. In Elixir, it’s a first-class language feature.”
一个 agent 崩溃?自动重启,带完整的错误上下文,其他 agent 完全不受影响。同样的功能在 Python 里要搭几个月,Elixir 里是语言级特性。
但关键是,OpenAI 同时发布了 SPEC.md。也就是说:你可以用任何语言重新实现。 社区已经有人用 Go 写了一个叫 Contrabass 的版本。
配置即代码:WORKFLOW.md
Symphony 的所有配置集中在一个文件里——WORKFLOW.md。YAML front matter 加 Markdown 提示模板。这是一个真实的工作流配置示例:
---
tracker:
kind:linear
endpoint:https://api.linear.app/graphql
api_key:$LINEAR_API_KEY
project_slug:my-project-abc123
active_states: [Todo, InProgress]
terminal_states: [Done, Closed, Cancelled]
polling:
interval_ms:30000
workspace:
root:~/code/symphony-workspaces
hooks:
after_create:|
git clone https://github.com/my-org/my-repo.git .
npm install
timeout_ms:30000
agent:
max_concurrent_agents:10
max_turns:20
max_retry_backoff_ms:300000
max_concurrent_agents_by_state:
"human review":1
"merging":2
codex:
command:codex--modelgpt-5.3-codexapp-server
approval_policy:never
thread_sandbox:workspace-write
---注意 max_concurrent_agents_by_state 这个设计——按任务阶段动态调控并发数。不是一刀切的”最多 10 个 agent”,而是”审查阶段最多 1 个,合并阶段最多 2 个,开发阶段最多 10 个”。
Markdown 部分是 agent 的提示模板:
You are an autonomous software engineer working on {{ issue.identifier }}: {{ issue.title }}.
## Context
{{ issue.description }}
## Instructions
1. Read the codebase and understand the existing patterns
2. Implement the requested changes
3. Write tests for your changes
4. Create a pull request with a clear description
5. Update the Linear issue state when complete这个文件跟着代码一起版本管理,在 PR 里 review,团队共享。 你的 agent 配置跟你的代码一样受管控。
多轮执行和状态调和
Symphony 的 agent 不是跑一轮就结束。Stephen Jones 的拆解里描述了这个机制:
“On the first turn, the agent receives the full prompt: the WORKFLOW.md template rendered with issue context. But on subsequent turns, it gets a minimal continuation prompt—essentially ‘you’re still working on MT-123, keep going from where you left off.’
This works because the workspace persists. The agent can see its prior commits, its partially-written code, its test results. It picks up where it left off without re-analyzing the entire problem. Up to 20 turns by default.”
第一轮拿完整上下文,后续轮次只说”你还在干 MT-123,接着来”。因为 workspace 是持久化的,agent 能看到之前的代码、提交、测试结果,不需要重新分析整个问题。默认最多 20 轮。
还有一个设计我觉得特别聪明——状态调和(Reconciliation):
“The Orchestrator never assumes an issue’s state—it always refetches from Linear. This means external state changes (a PM moving an issue to ‘Cancelled’, a developer manually closing a ticket) are respected immediately. The agent doesn’t fight the human.”
orchestrator 永远不”猜测” issue 的状态,每次都重新从 Linear 拉取。人类在外面把 ticket 关了?agent 立刻停。agent 不跟人抢方向盘。
安全和沙箱
Symphony 有多级安全机制。三种审批策略:
-
never:全自动,不需要人工审批
-
每次操作都需要人工审批
三种沙箱策略:
-
read-only:只能读
-
workspace-write:只能在自己的 workspace 里写
-
full-access:完全不受限
路径验证防止了三种攻击:
-
目录遍历(../../../etc/passwd)
-
Symlink 逃逸
-
workspace 外写入
内置 Skills
Symphony 附带了 6 个内置技能:
| Skill | 功能 |
| land | 监控 PR 的 CI、冲突、review,全部通过后自动 squash merge |
| pull | 拉取最新 main,自动解决冲突 |
| push | 提交推送,带认证回退 |
| commit | 按团队规范创建原子提交 |
| linear | 直接 Linear GraphQL 操作 issue |
| debug | 故障排查和堆栈检查 |
land 技能特别值得说说——它包含一个 Python 辅助脚本,监控 PR 的 CI 完成状态、聚合检查结果、区分 Codex 审查评论和人类审查评论、处理合并冲突。一条龙自动合并。
Martin Fowler 的分析框架
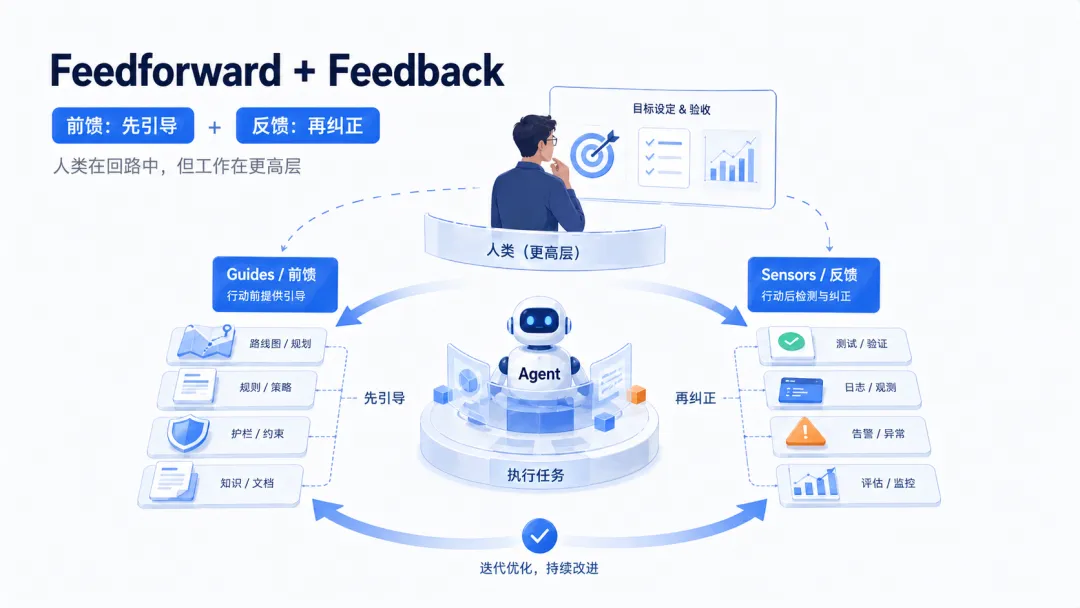
Martin Fowler 团队(Thoughtworks)在 2026 年 4 月发表的 Harness 工程文章里,提出了一个我觉得非常实用的分析框架:
Feedforward(前馈)+ Feedback(反馈)
“A well-built outer harness serves two goals: it increases the probability that the agent gets it right in the first place, and it provides a feedback loop that self-corrects as many issues as possible before they even reach human eyes.”
一个好的 Harness 有两个目标:提高首次正确率,以及让 agent 在错误到达人眼之前就自我纠正。
具体来说:
“Guides (feedforward controls) — anticipate the agent’s behaviour and aim to steer it before it acts. Guides increase the probability that the agent creates good results in the first attempt.”
“Sensors (feedback controls) — observe after the agent acts and help it self-correct. Particularly powerful when they produce signals that are optimised for LLM consumption, e.g. custom linter messages that include instructions for the self-correction.”
这里有个精妙的细节:linter 的错误信息可以写成给 AI 看的自我修复指令。 本质上是一种”正向的 prompt 注入”——你故意在错误信息里塞修复建议,agent 读到就自己改了。
他警告说两者缺一不可:
“You either get an agent that keeps repeating the same mistakes (feedback-only), or an agent that encodes rules but never finds out whether they worked (feedforward-only).”
只有反馈没有前馈 = 不断踩同一个坑。只有前馈没有反馈 = 闭门造车不知道规则有没有效。

然后他把 Harness 分成了三个维度,这三个维度我觉得特别有启发:
1. 可维护性 Harness(最容易做)
“Computational sensors catch the structural stuff reliably: duplicate code, cyclomatic complexity, missing test coverage, architectural drift, style violations. These are cheap, proven, and deterministic.”
确定性工具(linter、测试、类型检查)抓结构性问题,便宜、可靠、确定性强。
2. 架构适应性 Harness(中等难度)
就是 OpenAI 做的分层架构约束、可观测性标准这些。
3. 行为 Harness(最难,目前没有好解法)
功能是否正确?这个目前没有人解决好。Martin Fowler 特别诚实:
“This is the elephant in the room.”
“This approach puts a lot of faith into the AI-generated tests, that’s not good enough yet.”
“So overall, we still have a lot to do to figure out good harnesses for functional behaviour that increase our confidence enough to reduce supervision and manual testing.”
说实话,这一点 OpenAI 也没解决。他们的”行为验证”本质上还是:AI 自己写测试 → AI 自己跑测试 → 测试绿了就算通过。Martin Fowler 说得好:这把太多信任放在了 AI 自己写的测试上。
三代对比
| 维度 | 提示工程 | 上下文工程 | Harness 工程 |
| 人类角色 | 写提示词 | 组织上下文 | 设计环境+反馈循环 |
| AI 自主度 | 单轮对话 | 多轮对话 | 自主运行数小时 |
| 质量保障 | 人眼 review | 人眼 review | 机器 review + 人眼兜底 |
| 核心瓶颈 | 提示词质量 | 上下文质量 | 环境设计质量 |
| 类比 | 问老师一个问题 | 给老师准备教材 | 给老师建教室 |
| 典型产出 | 一段代码 | 一个功能 | 一个验收过的 PR |
| 代表工具 | ChatGPT | Cursor + Claude Code | OpenAI Codex + Symphony |
| 效率倍数 | 2-5x | 5-20x | 10-100x(OpenAI 自述 1/10 时间) |
两个绕不开的问题
人类工程师会被淘汰吗?
OpenAI 的回答:
“Humans always remain in the loop, but work at a different layer of abstraction than we used to. We prioritize work, translate user feedback into acceptance criteria, and validate outcomes.”
Martin Fowler 说得更彻底:
“As human developers we bring our skills and experience as an implicit harness to every codebase. We absorbed conventions and good practices, we have felt the cognitive pain of complexity, and we know that our name is on the commit.
A coding agent has none of this: no social accountability, no aesthetic disgust at a 300-line function, no intuition that ‘we don’t do it that way here,’ and no organisational memory.”
人类开发者自带一个”隐式 Harness”——我们的经验、审美、责任感、组织记忆。AI 一条都没有。
所以他的结论是:
“A good harness should not necessarily aim to fully eliminate human input, but to direct it to where our input is most important.”
好的 Harness 的目标不是消灭人类,是把人类注意力引导到最有价值的地方。
OpenAI 为什么开源?
我的判断:在建生态护城河。
Symphony 目前官方只支持 Linear + OpenAI Codex。开源它,社区会帮它扩展到 Jira、GitHub Issues、其他模型。但核心编排逻辑和 SPEC.md 是 OpenAI 定义的标准。
就像 Android 开源,但你离不开 Google Play。
最后
OpenAI 这篇博文里有一段话,我觉得是整件事最好的总结:
“As agents like Codex take on larger portions of the software lifecycle, these questions will matter even more. We hope that sharing some early lessons helps you reason about where to invest your effort so you can just build things.”
模型会越来越强,越来越同质化。但 Harness 是每个团队自己建的——它包含了你的架构决策、编码规范、质量标准、业务知识。这些东西没法抄,只能自己搭。

“人类品味编码一次,然后在每一行代码上持续执行。”
这就是今天的内容。大家有什么想法,欢迎一起探讨!
往期精彩内容:
大厂们在怕什么?三天内,飞书、钉钉、企业微信全部开源 CLI
2023年你会写prompt就很牛,2026年你还在写prompt就完了
OpenClaw 小龙虾实战基础揭秘:一个非程序员的 AI 助手使用心得