 夜雨聆风
夜雨聆风





让Claude Code变「慢」的插件,反而让我开发快了
结论先说:值得装,但不是你想的那种价值。
它不会让 Claude Code 更聪明,不会让它写出更好的代码。它做的事情只有一件:逼你和 AI 都慢下来,在动手之前把事情想清楚。
如果你觉得这没什么用,那你大概还没遇到过「AI 写了两小时代码,最后发现方向完全不对」的情况。我遇到过,不止一次。
问题根源:AI 太急了,你也太急了
用 Claude Code 开发,有一个系统性的问题很少被正视:
你说完需求,它立刻开始写代码。代码能跑,但你不确定它理解的需求和你想要的是不是同一件事。等你发现不对,已经有一百行代码需要推翻。
这不是 Claude Code 的 bug,是所有 AI 编程工具的通病——它被训练成「给出回答」,而不是「在不确定的时候停下来问」。
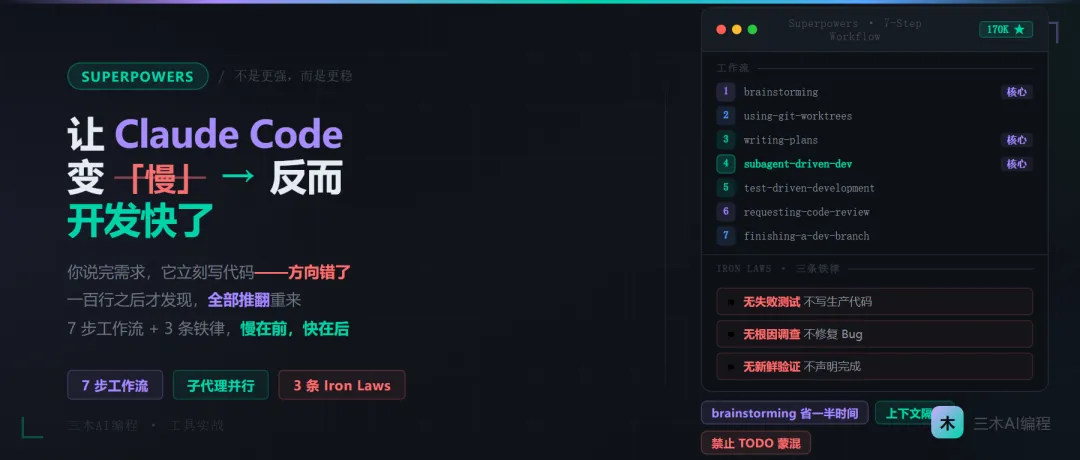
Superpowers 就是冲着这个问题来的。GitHub 170K Star,MIT 协议,一套完整的 AI 编程工作流规范。核心理念八个字:不是更强,而是更稳。
我拿它在一个出海 SaaS 项目上跑了三天,说说真实感受。
它是什么,怎么装
Superpowers 本质上是一套注入到 Claude Code 的行为约束——14 个 Skills、7 步工作流、3 条不可违反的铁律。
安装一行命令:
/plugin install superpowers@claude-plugins-official装完之后,Claude Code 的行为会发生可感知的变化:你给它一个任务,它不会立刻开始写代码,而是先向你提问,梳理清楚需求之后才动手。
说人话就是:它变「慢」了,但慢得有理由。
7 步工作流,拆开来看
这是 Superpowers 的核心结构,按场景裁剪着用:
brainstorming → using-git-worktrees → writing-plans→ subagent-driven-development → test-driven-development→ requesting-code-review → finishing-a-development-branch不是每个场景都要走完全部 7 步。实际使用中,我把它归纳成三套:
新项目 / 新功能:走完整 7 步修 bug:只走 3 步(系统调试 → TDD → 验证收尾)一堆独立小任务:用并行子代理
重点讲三个我觉得真正有价值的步骤。
Step 1:brainstorming——最容易被跳过、最值得停留的一步
这一步的硬性规定是:不展示设计文档并获得你的批准,绝不启动任何实现。
Claude Code 装了 Superpowers 之后,它会先向你逐个提问——不是一股脑把所有问题甩给你,是一个一个来,等你回答了再问下一个。
这个设计有讲究。一次性问十个问题,你会随便应付,质量差。一个一个问,你被迫认真回答每一个。
我第一次用这个流程做功能需求梳理,它问出来了三个我自己没想到的问题,其中一个直接改变了我对某个功能的设计方向。
大多数人不知道的细节: 这一步拉得越长,后面省的时间越多。我测过:brainstorming 多花 20 分钟,后续的代码调整时间减少了将近一半。这个账很合算。
Step 3:writing-plans——任务粒度是关键
这一步把设计拆成具体任务,每个任务的标准是「2-5 分钟能完成的工作量」。
更重要的规定是:任务里的代码必须完整,禁止出现 TBD、TODO、占位符。
这条规定的逻辑是:如果你写不出完整的代码,说明这个任务还没想清楚,应该继续拆,而不是用 TODO 蒙混过关。
我在出海项目里用这一步拆 Stripe Webhook 处理器,拆出来七个任务,每个任务的文件路径、函数签名、预期行为全部写明白。子代理照着这个做,第一次跑通的比例明显高于以前「模糊描述然后让它自由发挥」的方式。
Step 4:subagent-driven-development——上下文隔离的真实价值
每个任务派一个独立的子代理,每个子代理只看到当前任务所需的信息。
这解决了一个我之前一直没意识到的问题:长对话里,早期建立的约束会被后续信息稀释。
用一个会话做完整个功能,到后期它开始「忘记」早期定下的规范。换成子代理驱动,每个子代理的上下文是干净的,不会被之前任务的信息污染。
实测效果:同样复杂度的功能,用子代理驱动开发,中后期代码质量比单会话稳定很多。
三条铁律,字面意思就是不可违反
Superpowers 把这三条叫做 Iron Laws,不是建议,是硬性约束。
铁律一:没有失败测试就不写生产代码
先写一个能复现目标行为的测试(此时是失败的),再写让测试通过的代码。
对出海项目来说这条尤其重要。我之前吃过亏:Stripe Webhook 的幂等性处理,直接写代码,上线三天才发现重复事件会导致数据库写入两次。如果当时先写测试,「发送同一个 event_id 两次,第二次应该被忽略」这个场景会在测试阶段就被覆盖到。
铁律二:不做根因调查就不修 bug
这条铁律要求修 bug 的流程是:先找根因,再写复现测试,最后才改代码。
不允许「改一行试试,不报错了就收工」。
我当时第一反应是「这也太慢了」。但算了一下:一个 bug 根因调查花 15 分钟,彻底解决。不查根因,同一个 bug 出现三次,每次「修复」20 分钟,总共 60 分钟,问题还在。
铁律三:没有新鲜验证证据就不声明完成
「新鲜」这个词很关键——不是「之前跑过没问题」,是「刚刚验证过」。
要求是:所有测试通过 + 手动验证 bug 已修复 + 相关功能无回归,三条都满足才算完成。
这条铁律对抗的是用 AI 编程时一个特有的心理陷阱:AI 说「修复已完成」,你就信了。但「代码改完了」不等于「验证过了」。
踩坑环节
坑一:brainstorming 阶段嫌慢跳过,后面花了两倍时间返工
第二天用 Superpowers 做一个新功能,我觉得需求很清楚,直接跳过 brainstorming 让它开始写。
写了一半发现,它对「用户可以管理多个工作区」这个需求的理解,和我想要的差了一个关键细节——它理解成「一个用户账号下多个工作区」,我想要的是「一个工作区可以被多个用户共享」。
两个方向的数据库设计完全不同。推翻重来花了一个半小时。
解决方案: brainstorming 不能跳过,哪怕你觉得需求再清楚。它问出来的问题里,经常有你以为自己想清楚了但其实没有的地方。
坑二:writing-plans 里的任务粒度太大,子代理跑偏了
有一次我把「实现订阅状态同步」作为一个任务,结果子代理做出来的东西包含了 Webhook 处理、数据库更新、邮件通知三个部分,而且三个部分之间的边界模糊,后续 Review 很痛苦。
解决方案: 一个任务只做一件事。「实现订阅状态同步」要拆成:「处理 checkout.session.completed 事件」、「更新 Subscription 表状态」、「触发状态变更邮件」三个独立任务。每个任务有明确的输入输出,子代理才不会乱跑。
总结
Superpowers 解决的不是「AI 不会写代码」的问题,而是「你和 AI 都太急了」的问题。
慢下来,把事情想清楚,然后按步骤执行——这套逻辑本来就是正确的,只是大多数人在「AI 这么快」的诱惑面前放弃了它。Superpowers 是一套强制你回到正轨的机制。
最后一个实际的问题: 你用 Claude Code 开发时,有没有认真估算过「因为前期没想清楚导致的返工时间」占你总开发时间的比例?如果认真算一下,这个数字会不会让你愿意在 brainstorming 上多花一点时间?