 夜雨聆风
夜雨聆风





论文解析l人类与AI在连续学习中的“迁移-干扰”权衡



引言
Introduction
近年来,AI 的快速进步让许多人开始相信 AGI 已近在眼前,但一个关键问题仍未解决:当前主流 AI 还不具备真正稳定的持续学习能力。对大多数神经网络而言,学习主要发生在集中训练阶段;一旦训练结束,模型参数基本固定。如果继续学习新任务,就很容易遇到经典难题——灾难性遗忘。
从机制上看,神经网络学会任务 A 后,相关知识并不是单独存放的,而是分布式地写入大量连接权重中。当模型继续学习任务 B 时,反向传播会根据新任务的误差更新参数,目标是让模型更适应当前任务,但这些被改动的参数往往也同时支撑着旧任务 A。于是,模型在学会任务 B 的同时,也可能破坏原先在任务 A 上形成的能力。
相比之下,人类虽然也会遗忘、也会受到干扰,但通常能够在保留既有经验的基础上吸收新知识,并把旧策略迁移到新情境中,实现长期积累与持续成长。
正因如此,人们往往倾向于认为:人类能够持续学习,而神经网络更容易在学习新内容时覆盖旧知识。但这种二元对立的理解,真的足够准确吗?带着这个问题,本文将以 Eleanor Holton 团队发表于 Nature Human Behavior 的研究 Humans and neural networks show similar patterns of transfer and interference during continual learning 为例,重新审视持续学习、知识迁移与任务干扰之间的关系。
摘要:
持续学习的核心难点在于学习新任务时,旧知识常常会被覆盖;这种现象被称为“灾难性遗忘”,而人类则通常被认为可以很好的避免这一问题。本文通过让人类与配对的神经网络完成同一套 A–B–A 顺序学习任务,重新挑战了这一传统看法。其结果表明:
1
人类和神经网络表现出相似的总体规律,即当前后两个任务越相似时,学习者越容易借助已有经验更快进入新任务,但在重新回到旧任务时,也越容易受到新任务的影响。
2
神经网络表现出这样的相似现象是因为它会根据任务关系组织内部表征,这里的“表征子空间”可以简单理解为网络在隐藏层中编码某类任务规则所使用的内部表示空间。当两个任务相似时,网络倾向于复用原有子空间,因此新任务学得更快,但旧知识也更容易被覆盖,而当任务差异较大时,网络则更可能建立彼此分离、近乎正交的表示,从而减少干扰。
3
人类本身也并非单一模式,而是分成两类学习模式,一类更倾向于抓住共同结构,因此迁移更强、泛化更好,但也更容易受到干扰;另一类更倾向于保留任务差异,因此更能避免干扰,却在迁移和泛化上有所牺牲。
这篇文章挑战了“人类与线性神经网络依赖根本不同学习机制”的常见假设,并指出二者在持续学习中可能都受到同一种基本约束:即越能利用旧知识促进新学习,往往也越要承担旧知识被新经验“带跑偏”-即干扰的代价。

1
实验设计
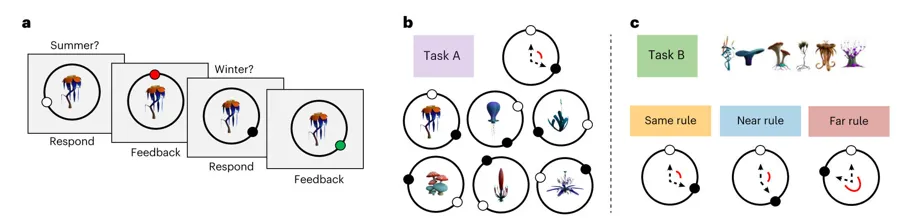
一、【任务A】
1.询问夏季位置 (图a1)
屏幕上会出现任务A刺激中的一种植物,系统会首先询问这个植物在夏季应该在圆环的哪个位置。学习者需要自己在圆环上选一个点。
2.给出反馈 (图a2)
当学习者做出回答后,系统告知夏季位置是否正确,并且反馈正确位置。
3.询问冬季位置 (图a3)
随后系统继续询问学习者该植物对应的冬季位置。
4.再次反馈 (图a4)
当学习者再次回答后系统再次给出反馈,告知冬季的位置是否正确。
在任务A中,每种植物在夏季(白色圆圈)与冬季(黑色圆圈)的位置关系对应一个固定的角规则(例如顺时针旋转120°),该规则在不同被试间随机分配。(图b)
二、【任务B】
随后学习者会被切换到第二组全新刺激(另一组6个完全不同的植物),继续学习夏季与冬季的相对位置。
任务B相对任务A的规则关系被设为不同条件(相同、接近、差异大),所有被试均需学习将一组新刺激映射至各自的夏季与冬季位置。然而,定义季节间关系的规则在不同被试组之间有所不同(图c):
1.在相同Same条件下,任务B的季节关系沿用任务A中已习得的同一规则;
2.在相近Near条件下,规则偏移30°;
3.在相远Far条件下,规则偏移180°。
三、【回测任务A】
在被试完成任务 A 训练和任务 B 训练之后,再次对任务 A 进行测试。其目的是评估在学习任务 B 之后,任务 A 中已形成的规则表征是否受到后续学习的干扰。在这一阶段,被试仍需对任务 A 刺激的夏季位置和冬季位置作出判断,但实验不再对冬季反应提供反馈。
因此研究者可以更有效地区分:被试在回到旧任务时,究竟是在继续使用原有的任务 A 规则,还是已经错误地将任务 B 的规则迁移到任务 A 上。基于此,重测任务 A 主要用于衡量新任务学习对旧任务表征所造成的干扰程度。
四、ANN网络
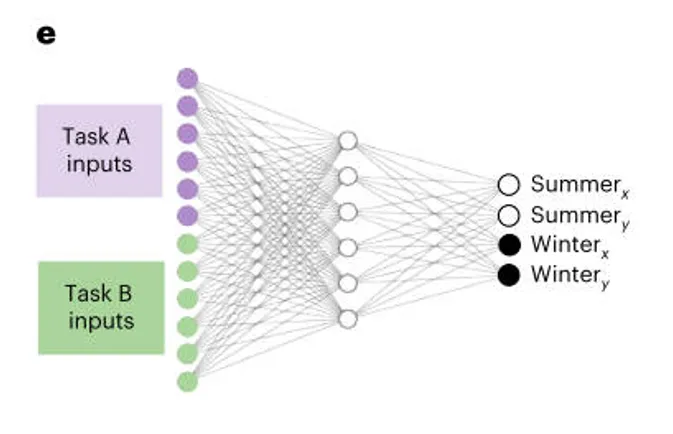
人工神经网络(ANN)的基本结构与输入—输出映射方式。采用一个简单的前馈架构,输入层分别对应 task A 和 task B 的刺激,两个任务各自包含 6 个独立输入单元,因此整个输入层以 one-hot 方式编码不同刺激类型;
隐藏层用于形成任务表征;输出层则对应圆形任务中的位置坐标信息。目的在于:尽可能剥离复杂感知加工的影响,使网络面对的核心问题直接聚焦于刺激-位置映射以及季节规则的连续学习,从而能够与人类被试在 task A→task B→task A 重测流程中的学习表现进行一一对应比较。(图e)
整体流程如图d所示:
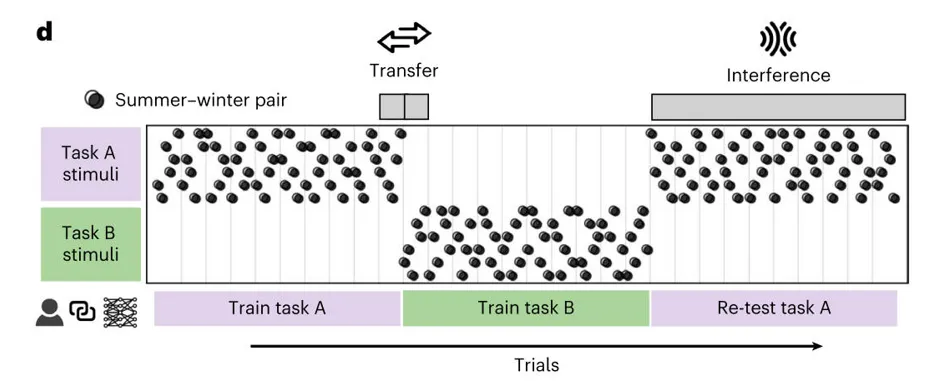
该实验的共包含 360试次,分为 30 个 block。整个流程分为三个阶段:
1.任务 A 训练,共 120 次试验(10 个 block);
2.任务 B 训练,120 次试验(10 个 block);
3.任务 A 重测,共 120 次试验(10 个 block)。
在每个 block(1 个 block = 6 × 2 = 12 次,夏季和冬季 条件下各出现一次)中,6 个植物刺激都会依次呈现,并分别要求被试判断其在 夏季 和 冬季 的位置,因此实验实际上是围绕不同季节条件下的位置学习与重测展开的。除一个探针刺激外,其余均有反馈。
和人类被试相比,每个网络都和一名人类参与者配对,也有一套 任务 A 120 次、任务 B 120 次、任务 A 重测 120 次 的试次表,并且接受相同的刺激顺序、试次顺序和反馈安排——但它并不是像人类那样把这套流程只做一遍,而是为了达到稳定表现,把每个阶段的 120 个试次都重复训练 100 遍。
2
量化指标与分析
一 、得分 (point)
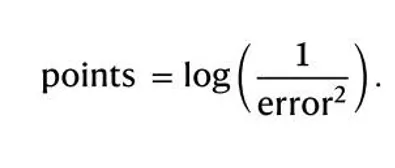
在研究中,point 得分仅是实验过程中的一种在线反馈和激励机制。参与者每次回答后,系统会根据“回答位置与正确位置之间的角度误差”给分。反馈会显示为一个表示真实位置的圆圈:如果回答足够准确、能得分,圆圈是绿色;否则是红色。
二、 行为指标
1)准确率
基于每个试次的响应误差计算。响应误差为参与者响应角度与正确角度之间的绝对差值。
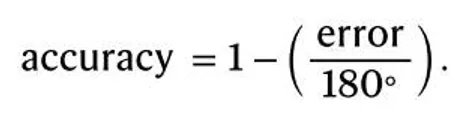
其中,Accuracy = 1 表示完全正确,Accuracy = 0 表示达到最大误差(即与正确位置相差 180°)。准确率在这里是一个 0 到 1 之间的连续指标能够衡量在规则学习中的渐进变化,为后续对迁移和泛化的分析提供更多的行为依据。
其次,实验中task A 有一个专门的 test stimulus,对这个刺激,研究者始终不给 winter feedback。也就是说,参与者如果仍然能够在这个刺激上给出较高的 winter 准确率,就不能简单解释为记住了正确位置,更说明他们已经掌握了 task A 的规则,并能把该规则推广到未被直接学过的位置上。
2)迁移:
观察并计算task A 最后一个 block(block 10) 和 task B 第一个 block(block 11) 之间的 winter accuracy 变化。此处的一个 block 就是“六个刺激各出现一轮”,所以实际比较的是:A 的六个刺激最后一次完整呈现时的六个 winter 反应,和 B 的六个新刺激第一次完整呈现时的六个 winter 反应。
3)干扰
为了判断参与者在重新回到旧任务时,是否把新学到的规则带了回来。作者没有直接用 accuracy 来定义干扰,而是进一步分析每个 winter 回答背后所反映的“规则偏移”。
具体来说,作者根据 task A 重测阶段每个 winter response 相对于前一个 summer feedback 的角度偏移,判断参与者更接近使用 rule A 还是 rule B,再将所有试次的偏移量用一个以和为中心的 双 von Mises 混合模型 拟合,从而量化其受 task B 干扰的程度。
两个关键自由参数:
1.混合权重 ,表示回答中来自 rule B 成分的相对比例;
2.集中度参数 ,表示所有回答围绕各自规则中心分布的集中程度。 越大,说明回答越稳定地聚集在某一规则附近; 越小,则说明回答更分散。
4) 泛化准确率
在任务A的6个刺激中,有1个被随机指定为探针刺激(test stimulus)。
对于这个刺激,被试始终只能获得夏季反馈,永远不会得到冬季反馈。
因此,它的冬季回答不能靠记忆,必须靠对任务A规则的抽象掌握来推断。
计算方法:取任务A后半段(比如最后几个block)中探针刺激的winter准确率(用同样的连续公式)。高泛化准确率 代表 被试真正掌握了规则,而不是记住了6个具体答案。
一个有趣的发现:作者根据干扰模式把Near条件下的被试分成两类:
Lumpers(聚合型):π高(容易受B规则干扰),但同时泛化准确率也高
Splitters(分离型):π低(坚持用A规则),泛化准确率较低
这说明:Lumpers并不是“学得差”,而是更倾向于用抽象规则来组织知识,因此既容易被新规则带跑(高干扰),也能更好地推广到新刺激(高泛化)。
三 、ANN表征分析
本文对 ANN 的分析不只是比较其行为结果是否与人类相似,还进一步考察:网络在顺序学习 task A 与 task B 后,隐藏层表征结构是如何变化的。 作者关注的核心问题是:神经网络在学习新任务时,究竟是在复用 task A 的原有表征空间,还是为 task B 建立了新的表征空间。
为回答这一问题,作者提取不同刺激输入下的隐藏层激活,并分别构建 task A 与 task B 的隐藏层活动矩阵。随后,作者先对这些隐藏层活动做 PCA,用低维子空间来表征每个任务在隐藏层中的表示结构。这样做的目的,一方面是观察隐藏表征的维度是否变化,另一方面是比较两个任务的表征空间究竟是重叠还是分离。
结果表明,在 Same 和 Near 条件下,两个任务的表征空间更接近重叠,主夹角接近 0∘;而在 Far 条件下,两者更接近正交,主夹角接近90∘。这说明相似任务更容易共享表征,从而带来更强的迁移,但也更容易产生干扰;差异较大的任务则更容易形成分离表征,迁移较弱,但干扰也更小。
3
结果
一、 ANN结果
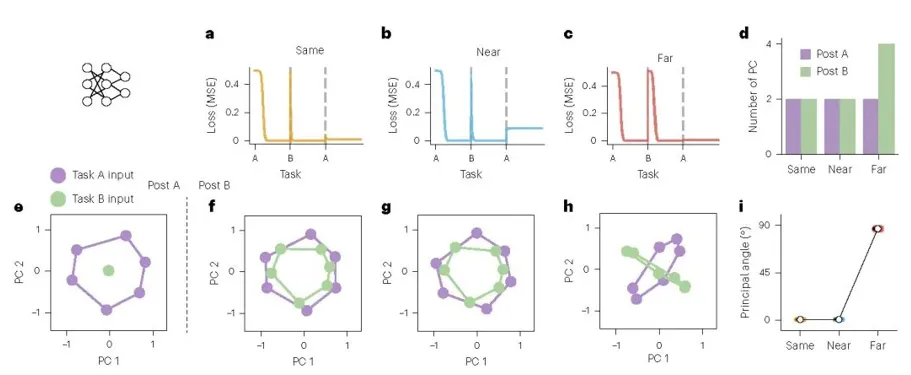
针对神经网络的结果表明,其在连续学习中的行为模式与人类被试呈现出高度一致的迁移—干扰之间的权衡。学习曲线显示:
在 Same 条件下,网络从 task A 切换到 task B 时损失几乎不重新升高,回到 task A 后表现也基本稳定,说明原有任务结构可被直接复用,且旧表征几乎未受破坏(图 a)。在 Near 条件下,网络切换到 task B 时仍有一定初始优势,但返回 task A 后出现更明显的残余误差,说明新任务学习已开始干扰旧任务表征(图 b)。在 Far 条件下,切换到 task B 时损失明显升高,说明旧知识对新任务的支持减弱;但回到 task A 时恢复较好,表明旧表征保留更稳定(图 c)。总体任务越相似,迁移越强,但也越容易引发对旧任务的干扰。
隐藏层表征分析进一步解释了这一现象。以解释 99% 方差所需的主成分数表征有效维度,结果表明相似任务更多依赖既有表征结构的复用,而差异较大的任务则更倾向于扩展新的表征空间(图 d)。二维 PCA 投影显示,在 Same 条件下,task A 与 task B 的表征几乎重合,说明二者共享高度一致的低维子空间;在 Near 条件下,两者虽不完全重叠,但仍保持接近,表明网络仍主要沿用原有表征框架;在 Far 条件下,两组表征明显分离,说明网络学习新任务时形成了新的表征组织方式(图 f–h)。主夹角分析进一步量化了这一差异:Same 与 Near 条件下主夹角接近 0°,表明两个任务的隐藏层子空间高度对齐;Far 条件下主夹角接近 90°,表明二者趋于正交分离(图 i)。这说明表征重叠越高,迁移越强但干扰也越大;表征分离越明显,迁移越弱但旧知识保留越稳定。
二、人类被试
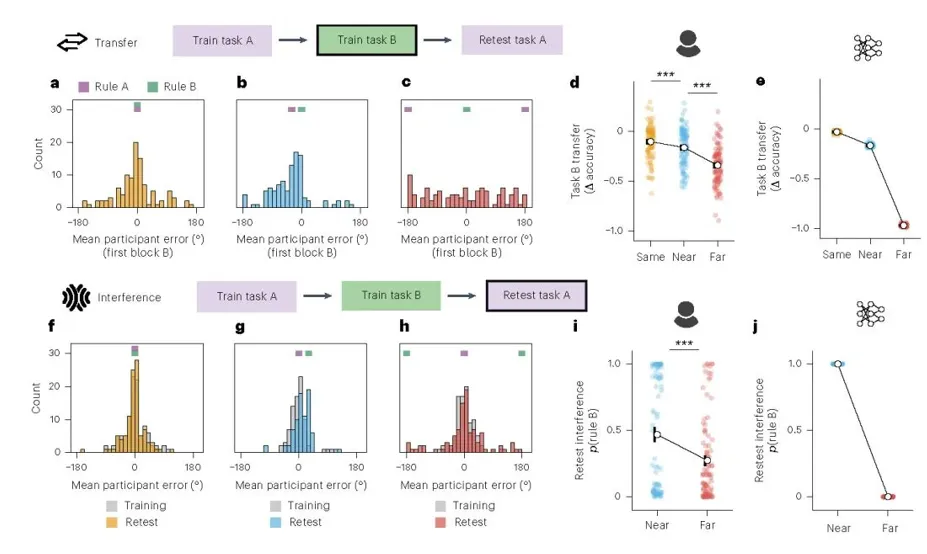
进一步地,若将同样的分析同时应用于人类被试和按参与者试次表训练的 ANN。当系统从 task A 切换到 task B时,其初始反应是否仍受旧规则影响?
在迁移分析中,作者考察了进入 task B 第一 block 时的平均 winter error 分布(图 a–c)。结果显示,在 Same 条件下,由于 A 与 B 规则一致,误差集中在接近 0° 的位置,说明参与者几乎可以直接沿用 task A 规则,切换代价极小。到了 Near 条件,误差分布明显朝向继续沿用 task A 规则时会产生的误差方向偏移,表明被试在 task B 初始阶段并非从零开始,而是带着 task A 的规则偏向进入新任务,这正是迁移的直接体现。相比之下,Far 条件下的误差分布更分散,说明旧规则对新任务初始表现的支持明显减弱。总体来看,随着任务差异增大,task A 对 task B 的迁移逐步下降。按参与者试次表训练的 ANN 复现了相同趋势(图 d–e)。
干扰分析考察的是系统完成 task B 后返回 task A 时,作答是否被新规则改变(图 f–h)。作者将 task A 重测阶段的误差分布与原训练阶段进行比较。结果发现在 Same 条件下,两者几乎重合,说明规则不变时几乎没有可检测的偏移;在 Near 条件下,重测误差分布明显朝向 rule B 所预测的方向偏移,说明参与者在重新作答 task A 时,会系统性地把刚学到的 task B 规则带回旧任务;而在 Far 条件下,这种向 rule B 的偏移显著减弱,说明新规则对旧任务的侵入较少。
随后进一步将这种现象量化为重测 task A 时使用 rule B 的概率(图 i–j)。在人类数据中 Near 条件下的 rule B 使用概率显著高于 Far 条件。这表明任务越相近,新规则越容易在返回旧任务时被误用;任务差异越大,这种侵入越弱。ANN 再次表现出与人类一致但更离散的模式:在 Near 条件下,网络返回 task A 时几乎完全表现为沿用 rule B 的倾向,而在 Far 条件下,这种倾向几乎降为零。
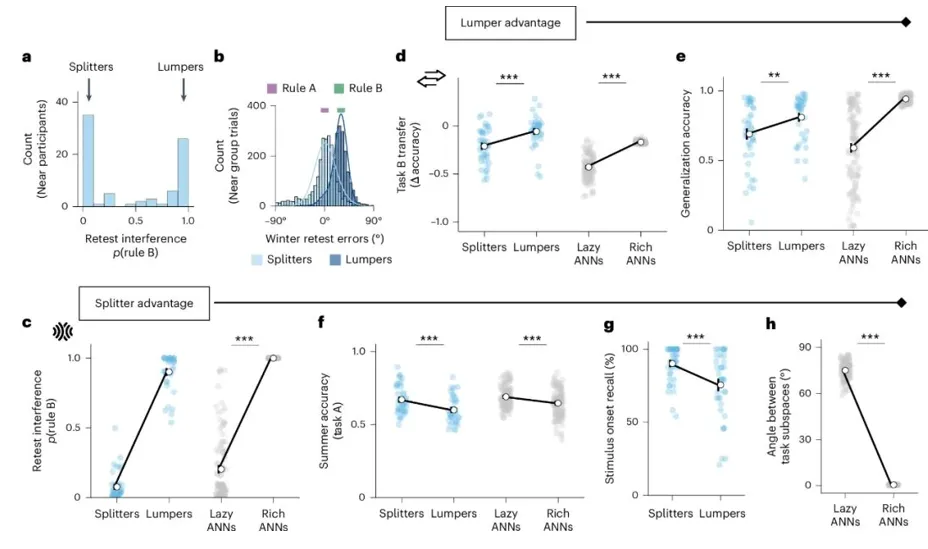
若聚焦于 Near 条件内部 的差异:为什么在面对相同的任务结构时,有些被试表现出更强的迁移与泛化?而另一些被试则更擅长保持任务分离、抵抗干扰?
文中认为这种人类内部的差异,与 ANN 中两类不同的学习状态进行对应:一类是 lazy ANNs,即形成较高维、较分离表征的网络;另一类是 rich ANNs,即形成较低维、较共享表征的网络。意图说明人类中的 splitters / lumpers 与网络中的 lazy / rich 在行为模式和表征结构上存在系统对应关系。
在 Near 条件下,参与者在重测阶段的干扰指标呈现明显双峰分布,而非单峰连续分布,提示人群中存在两类不同策略的学习者:一类在返回 task A 时几乎不使用 task B 规则,被定义为 splitters;另一类则明显混入 task B 规则,被定义为 lumpers(图 a,b)。
在此基础上,作者比较了两类被试在迁移、泛化与干扰上的差异,并与 ANN 中的 lazy/rich 网络并列分析。结果显示,lumpers 的迁移显著高于 splitters,而 rich ANNs 的迁移也高于 lazy ANNs,说明无论在人类还是网络中,共享表征更容易将 task A 的规则带入 task B 初始学习(图 d)。同时,lumpers/rich 的 generalization accuracy 更高,表明它们不仅切换时迁移更强,也更容易形成可推广到未反馈情形的抽象规则表征(图 e)。相对地,splitters/lazy 在定义性指标——重测干扰——上明显更低,说明它们更能保持任务分离、减少新规则对旧任务的侵入(图 c)。
此外,splitters 在 summer accuracy 上高于 lumpers,lazy ANNs 也优于 rich ANNs。由于 summer response 更多依赖对各刺激特异位置的记忆,而非共享规则推断,这说明 splitters/lazy 更擅长维持刺激特异性信息的分离性记忆(图 f)。进一步地,splitters 在 stimulus onset recall 上也更优,即更能准确记住某个刺激最早出现于实验前半段还是后半段。这个指标反映的是对刺激来源及时序的显式记忆,而非规则泛化,因此表明 splitters 的优势不仅体现在降低干扰,也体现在更强的任务来源与时序区分能力上(图 g)。总体而言,连续学习中的迁移—干扰权衡不仅存在于任务条件之间,也存在于不同学习策略之间。
4
讨论
在更早的源头上,这个问题其实并不属于机器学习,而属于人类记忆研究。Osgood 1948 关于 retroactive interference(逆向干扰) 的工作【1】,讨论的正是:为什么新学习会扰动旧知识,以及在什么条件下这种扰动会更严重。
到了 French 1999【2】,问题第一次以现代连接主义的形式被系统重述:当神经网络以顺序方式学习多个任务时,新任务训练会系统性覆盖旧任务所依赖的参数结构。于是,问题的重点不再只是“人会不会忘”,而变成了“为什么梯度下降驱动的网络在连续学习中如此脆弱”。
真正把这条问题线推进到人—机共同框架的,是 Flesch et al. 2018【3】。它的重要贡献在于,不再把人类学习和 ANN 学习看作两个彼此平行的领域,而是提出:持续学习可以成为一个共同的比较平台。
随后,Lee, Goldt 和 Saxe 2021【4】把研究焦点进一步推进:真正重要的问题,不只是顺序学习会不会遗忘,而是任务相似性本身是否决定了迁移与干扰的方向和强度。本文实际上正是沿着这条线继续展开:作者明确操纵 Same、Near、Far 三种任务关系,并在这一框架下同时测量 transfer 和 interference。
再往前一步,Lee et al. 2022【5】开始追问:这种现象在网络内部究竟是如何发生的?他们将注意力从外在行为结果推进到内部表征和资源分配方式。
如果把这条脉络连起来看,就会发现本文并不是重新发现“会干扰”这件事,而是把几个原本分散的问题重新组织到了一起更打动人的地方在于,这项工作并不是靠提出一个全新的名词来成立,而是通过重新组织几个长期分散的问题,让我们更清楚地看到:干扰、灾难性遗忘、任务相似性和表征复用,其实是同一个连续问题的不同侧面。
一些论文可讨论的小问题:
为什么Same条件不分析干扰? 如果两个规则完全相同,模型无法区分,这是合理的排除。但有没有可能Same条件下反而出现“负干扰”(即强化了原有规则)?
网络练100遍才稳定,人类只练1遍——这样的比较公平吗? 作者想模拟的是“稳定状态下的行为”,但人类可能永远达不到网络的稳定程度。
Lumpers和Splitters是稳定的个体差异,还是状态依赖的? 如果换个任务,同一个人会切换类型吗?

参考文献
Reference
【1】Osgood, C. E. (1948). An investigation into the causes of retroactive interference. Journal of Experimental Psychology, 38(2), 132–154. doi:10.1037/h0055753
【2】French, R. M. (1999). Catastrophic forgetting in connectionist networks. Trends in Cognitive Sciences, 3(4), 128–135. doi:10.1016/S1364-6613(99)01294-2
【3】Flesch, T., Balaguer, J., Dekker, R., Nili, H., & Summerfield, C. (2018). Comparing continual task learning in minds and machines. Proceedings of the National Academy of Sciences, 115(44), E10313–E10322. doi:10.1073/pnas.1800755115
【4】Lee, S., Goldt, S., & Saxe, A. (2021). Continual learning in the teacher-student setup: Impact of task similarity. In Proceedings of the 38th International Conference on Machine Learning (pp. 6109–6119). PMLR. DOI:10.48550/arXiv.2107.04384
【5】Lee, S. S. Mannelli, S., Clopath, C., Goldt, S., & Saxe, A. M. (2022). Maslow’s hammer in catastrophic forgetting: Node re-use vs. node activation. In Proceedings of the 39th International Conference on Machine Learning (Vol. 162, pp. 12455–12477). PMLR. DOI:10.48550/arXiv.2205.09029


原文链接:
Holton, E., Braun, L., Thompson, J. A. F., Grohn, J., & Summerfield, C. (2026). Humans and neural networks show similar patterns of transfer and interference during continual learning. Nature Human Behaviour, 10, 111–125. doi:10.1038/s41562-025-02318-y.


ANDLAB
撰文丨邢智彬
审阅丨伍海燕
排版丨李婧铱