 夜雨聆风
夜雨聆风





AI 写代码之后,独立开发者真正缺的是一个人的研发部
先看一个很典型的场景。
周六晚上,一个独立开发者想做一个小工具:把用户丢进来的产品截图,自动生成一份落地页改进建议。
这个想法不复杂。
他打开 Claude Code,让它先生成项目结构,再接一个截图上传组件,然后让模型分析图片,最后生成一份报告页面。
到凌晨两点,第一版已经能跑。
周日,他把链接发到几个群里。
反馈很好。
有人说“这个我正好需要”。
有人问“能不能批量分析”。
还有人直接问“多少钱”。
于是他觉得,这次可能真有戏。
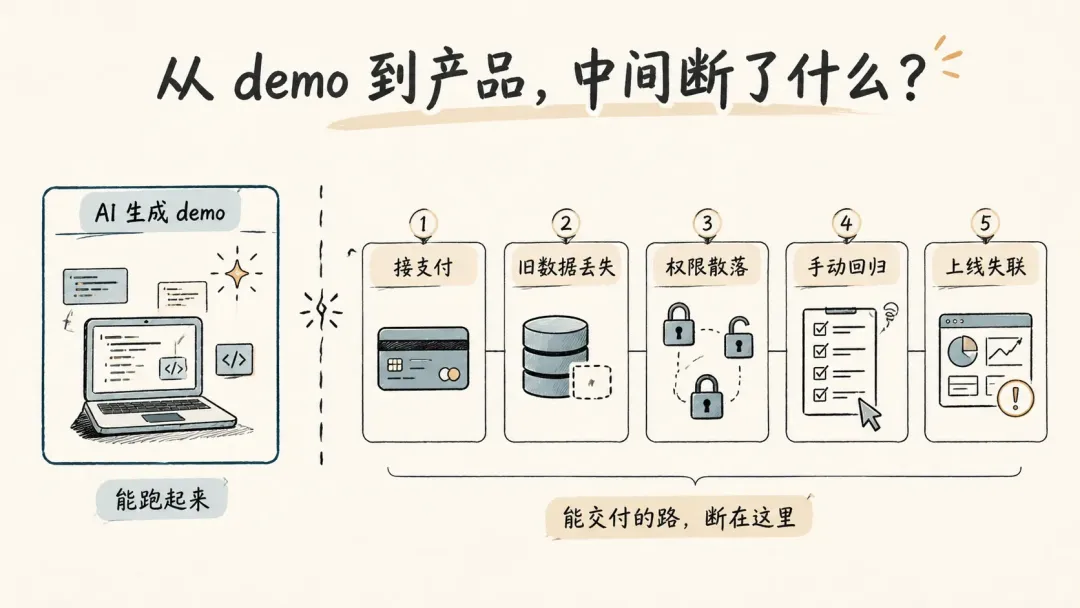
周一,他开始接支付。
问题也从这里开始。
接支付时,他发现用户表里根本没设计订阅状态。为了快,他让 AI 直接加了几个字段。
周二,有个早期用户反馈:自己上传过的截图不见了。
他一查,发现新字段改动影响了旧记录读取逻辑。
周三,他想补一个后台查看订单,又发现权限判断散在好几个页面里。
周四,他把 bug 修了,但不知道还有没有别的地方被影响,只能自己重新点一遍注册、上传、支付、查看报告。
周五,他终于上线新版。
结果晚上才看到一条用户私信:支付成功了,但报告没生成。
这时候他才意识到,自己缺的不是 AI 写代码。
代码一直写得出来。
真正缺的是研发部。
更准确地说,是一个人的最小研发部。
研发部不是一群写代码的人
很多人对“研发”的理解太窄了。
一说研发,就想到程序员写代码。
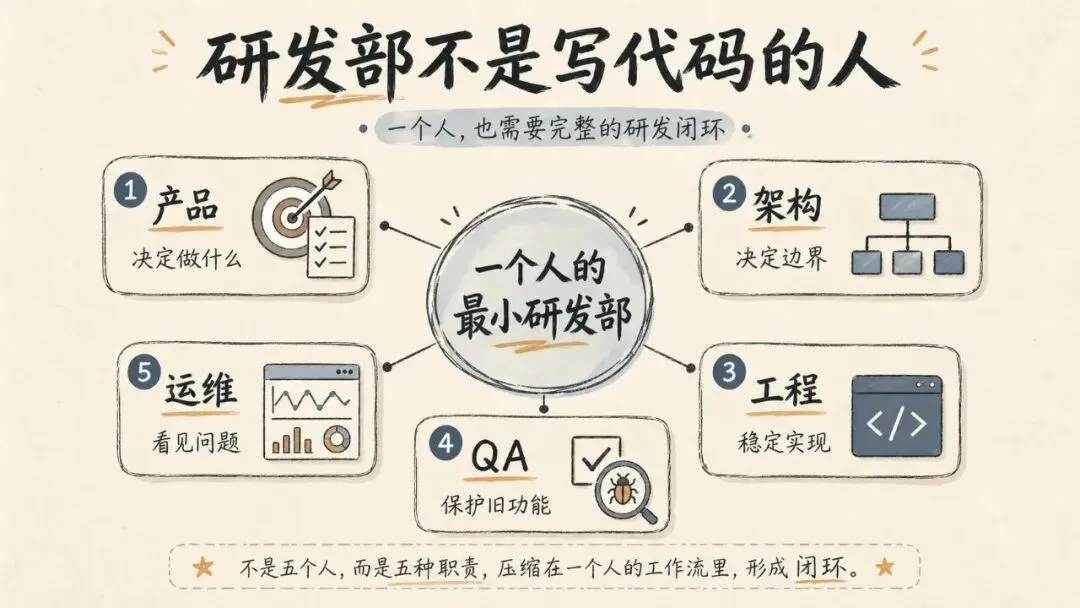
但真正的研发部,至少包含五件事:
-
1. 决定什么值得做; -
2. 决定系统边界怎么放; -
3. 把功能稳定实现出来; -
4. 确认这次改动没有弄坏旧东西; -
5. 上线之后还能看见问题。
在大公司,这些事可能分给产品经理、架构师、工程师、QA、运维。
在一人公司里,当然不可能真的雇五个人。
但这不代表这五件事消失了。
它们只是被压回到你一个人身上。
AI coding 最大的价值,是把“写代码”这件事大幅加速。你可以更快生成页面,更快补接口,更快改 bug,更快解释陌生代码。
但问题是:代码只是研发部产出的一部分。
AI 可以帮你更快写出一个功能。
它不会自动替你决定这个功能该不该存在。
它可以帮你改到能跑。
它不会自动告诉你,这次改动会不会把下个月的维护成本抬高。
它可以帮你写测试。
它不会自动知道,你最该保护的是哪几条用户路径。
所以 AI 写代码之后,独立开发者真正卡住的地方,往往不是“不会写”。
而是没有把研发这件事变成流程。
第一件事:先别开工,先挡住错误需求
回到刚才那个截图分析工具。
周日晚上,群里有人提了三个需求:
-
• 批量上传截图; -
• 支持竞品对比; -
• 自动生成 Figma 修改建议。
如果是以前,开发成本高,他可能会犹豫一下。
现在不一样。
他很容易直接把需求丢给 AI:
“帮我加一个批量上传。”
“帮我加一个对比模式。”
“帮我把报告导出成 Figma 注释。”
这就是 AI coding 很容易放大的第一个错误:把所有反馈都当成开发任务。
用户说想要,不等于他会为它付费。
群友说“这个功能不错”,也不等于它应该进入第一版。
一个人的研发部,第一件事不是写代码,而是挡需求。
你要先扮演产品经理。
不是写 PRD 那种产品经理,而是问一个很土的问题:
这个功能到底让谁更快得到什么结果?
这句话问不清楚,AI 写得越快,产品越容易长歪。
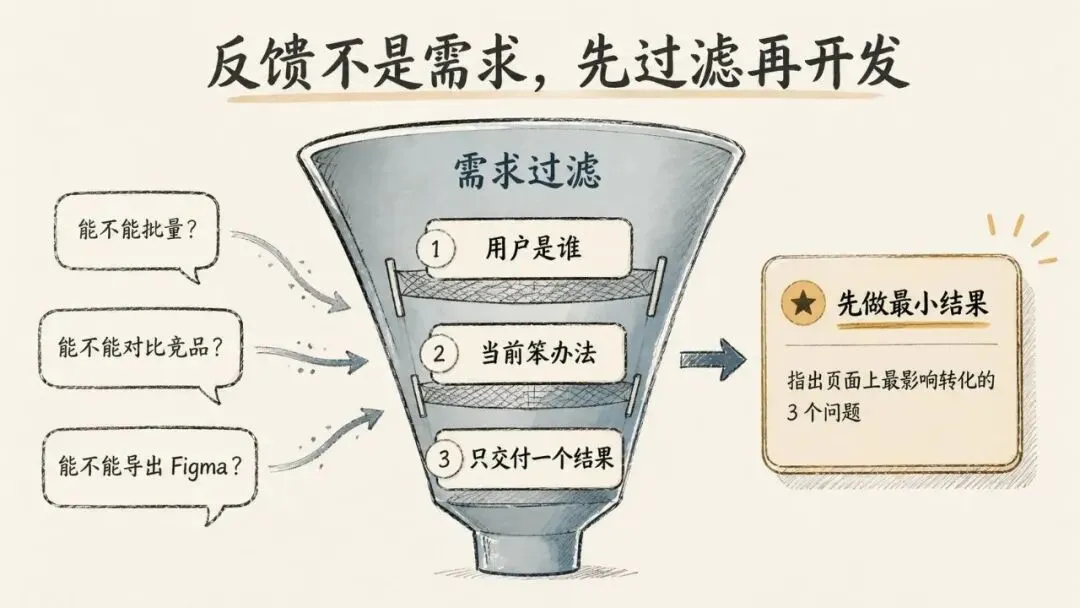
对独立开发者来说,每次让 AI 开工前,至少先写三行:
用户是谁:当前笨办法:这次只交付一个结果:比如截图分析工具,第一版真正要交付的可能不是“批量分析”。
而是:
用户是谁:正在自己改 landing page 的独立开发者当前笨办法:把截图发给朋友,问哪里不清楚这次只交付一个结果:指出页面上最影响转化的 3 个问题写到这里,很多功能就可以先不做。
批量上传可以不做。
Figma 注释可以不做。
竞品对比也可以先不做。
因为第一版最重要的,不是功能丰富。
而是让一个用户在 5 分钟内知道:我的页面哪里最该改。
AI 能帮你执行需求。
但你要先有能力拒绝需求。
这就是一个人的研发部里,产品经理这个角色最值钱的地方。
第二件事:别让代码库长成一团雾
周一接支付时,真正的问题不是“支付难不难”。
支付本身,AI 可以帮你查文档、写接口、处理回调。
真正的问题是,支付会碰到系统边界。
用户是谁?
免费用户和付费用户怎么区分?
一次性购买和订阅是不是一回事?
报告生成失败了,要不要退款?
支付成功但报告没生成,系统状态算什么?
这些问题不先想清楚,AI 也能继续写。
它会很努力地补字段、加判断、改页面。
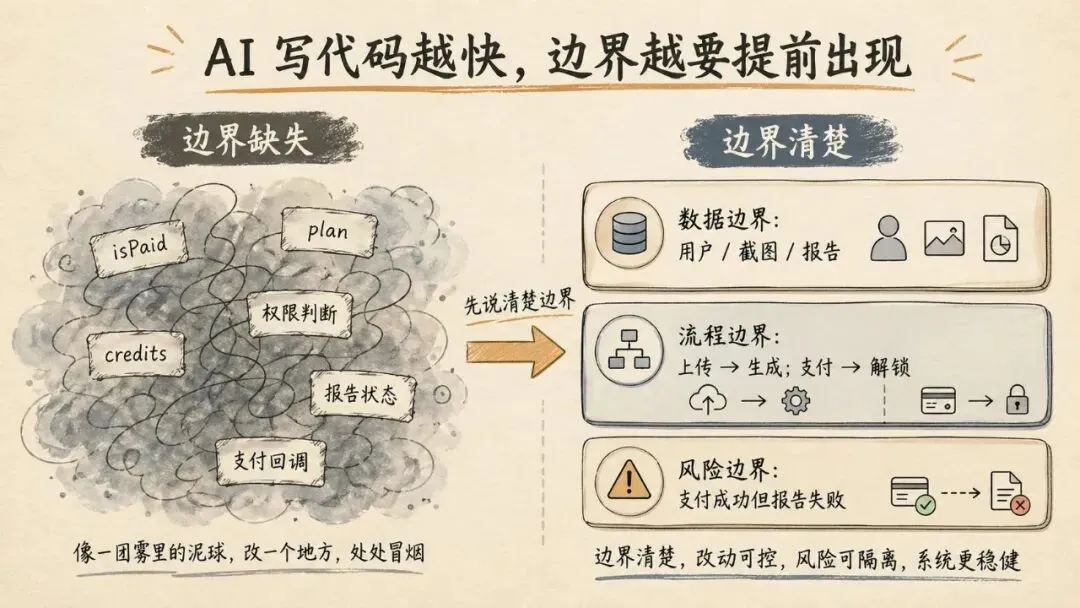
然后你的代码库就开始长成一团雾。
最开始只是一个 isPaid。
后来又多一个 plan。
再后来多一个 credits。
然后某个页面判断 isPaid,某个接口判断 credits > 0,后台又用 plan === pro。
每个局部都能解释。
放在一起就开始失控。
这就是 AI coding 的第二个幻觉:局部正确。
你让它修一个地方,它会修。
你让它补一个判断,它会补。
但产品不是局部正确的总和。
产品需要边界。
一个人的研发部里,你要给自己补一个最小架构师动作。
不需要画复杂架构图。
只要在动核心功能前,先写三条边界:
数据边界:最重要的 3 个对象是什么?流程边界:最核心的 2 条路径是什么?风险边界:哪一步出错,用户会立刻感知?还是截图分析工具。
它的边界可能是:
数据边界:用户、截图、报告流程边界:上传截图 -> 生成报告;支付成功 -> 解锁报告风险边界:支付成功但报告失败;旧截图被新逻辑覆盖这三行写下来,你再让 AI 改代码,效果完全不一样。
你不再只是说“帮我接支付”。
你会说:
“支付状态只能从订单回调更新,不要在报告页面里直接改用户权限。”
“报告生成失败时,不要消耗用户额度。”
“旧截图记录结构不能被覆盖,新增字段要兼容历史数据。”
AI 不是不能做这些事。
它只是需要你先把边界说出来。
AI 写代码越快,架构边界越要提前出现。
否则你得到的不是产品,而是一个生成速度很快的泥球。
第三件事:你不能只验收“它能跑”
周二那个 bug,表面上是旧截图不见了。
更深的问题是:他没有真正验收 AI 的改动。
很多人用 AI coding 的方式是这样的:
报错了,复制给 AI。
AI 改一版。
又报错,再复制。
最后页面能打开了,就合进去。
这在小 demo 里可以。
但在真实产品里,“能跑”只是最低标准。
尤其是 AI 改代码的时候,你最该看的不是它有没有把报错消掉,而是它为了消掉报错,顺手动了什么。
它有没有改数据结构?
有没有引入新依赖?
有没有绕过原来的权限判断?
有没有把一个简单问题改成更复杂的抽象?
有没有为了让测试通过,直接删掉某个校验?
一个人的研发部里,你仍然要当工程师。
这里的工程师,不是手写每一行代码。
而是负责验收代码。
我建议给每次 AI 改动设一个很小的合并门槛。
不需要复杂。
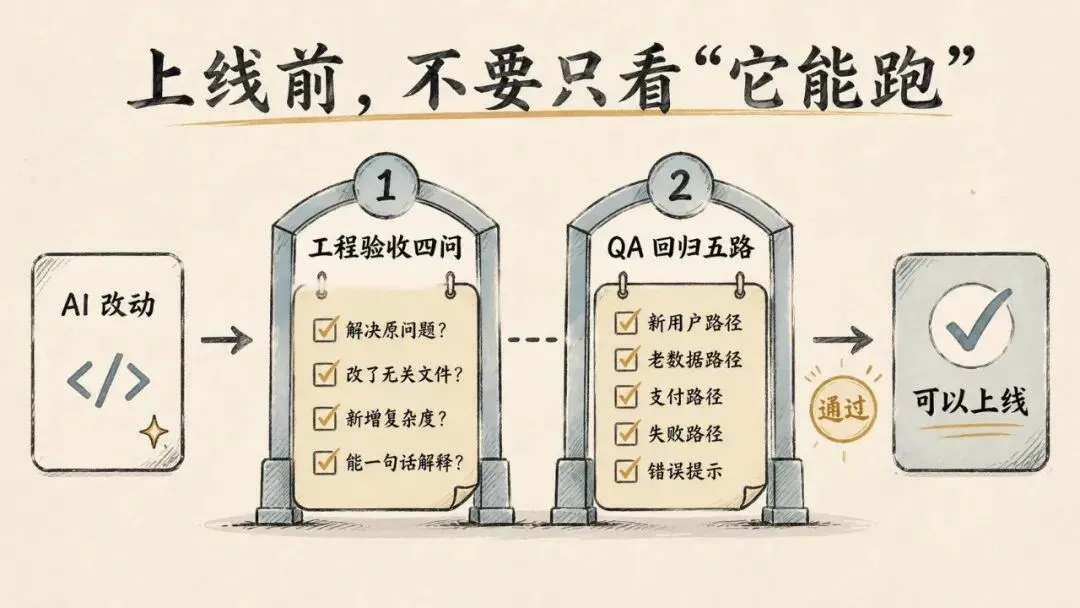
每次合进去前,只问四个问题:
-
1. 这次改动解决的是原问题吗? -
2. 它改了哪些无关文件? -
3. 它有没有新增以后维护不了的复杂度? -
4. 我能不能用一句话解释这次改动?
最后一个问题最重要。
如果你不能用一句话解释这次改动,说明你还没有接住这段代码。
比如:
“这次改动把支付状态从用户表挪到了订单表,并让报告解锁只读取订单状态。”
这就能解释。
如果你只能说:
“AI 修了一下,现在好像能跑了。”
那就别急着上线。
不要因为代码是 AI 写的,就降低工程标准。
恰恰相反。
AI 写得越快,你越需要更稳定的验收标准。
第四件事:上线前不要相信自己的手感
周四,他把支付 bug 修了。
然后自己点了一遍。
注册,上传,支付,生成报告。
都可以。
于是上线。
结果当天晚上,还是有用户支付成功但报告没生成。
这类问题很常见。
不是因为独立开发者懒。
而是因为一个人做产品时,最容易省掉 QA。
你太熟悉自己的产品了。
你知道哪里该点。
你知道哪个按钮要等几秒。
你知道刷新一下就好。
但用户不知道。
更麻烦的是,你每次改动后,脑子里只会记得“我刚刚改了哪里”。
你不会自然想起“这个改动可能影响哪里”。
所以 QA 不能靠手感。
它必须变成清单。
对于一个人的研发部,最小 QA 不是写一堆自动化测试。
第一步就是固定 5 条回归路径。
比如截图分析工具,上线前必须检查:
-
1. 新用户能不能从注册走到第一份报告; -
2. 老用户历史截图还在不在; -
3. 支付成功后报告能不能解锁; -
4. 报告失败时额度会不会被扣; -
5. 用户看到错误提示后知不知道下一步怎么办。
这张清单看起来很土。
但它比“我刚刚点过了”可靠得多。
等产品再复杂一点,你再把其中最关键的路径交给 AI 帮你写自动化测试。
顺序不要反。
不是先追求测试体系高级。
而是先知道哪些路径不能坏。
QA 的本质不是“多测一点”。
QA 的本质是明确:这个产品最不能坏的地方在哪里。
第五件事:上线后别让产品失联
最刺痛人的,往往不是 bug 本身。
而是你发现 bug 的时间太晚。
用户晚上私信你:我付费了,但报告没出来。
你这才打开后台。
然后才发现,两个小时前就已经有好几次生成失败。
这时候产品已经失联了。
很多 AI 做出来的小产品,最大的问题不是不能上线。
而是上线之后像丢到网上一样。
有没有人用,不知道。
哪一步失败,不知道。
支付有没有成功,不知道。
API 成本有没有突然升高,不知道。
用户在哪一步离开,也不知道。
这不是产品。
这是一个公开访问的 demo。
一个人的研发部里,运维不一定要复杂。
你不用一开始就上全套监控系统。
但至少要给自己留几个生命体征:
-
• 今天来了多少人; -
• 有多少人完成了关键动作; -
• 哪些错误出现超过 3 次; -
• 支付成功后有没有交付成功; -
• 模型调用成本有没有异常; -
• 哪个页面让用户停住了。
AI agent 未来在一人公司里很有价值的地方,不只是帮你写代码。
更是每天替你看这些信号。
哪里异常,哪里变慢,哪里成本涨了,哪里用户掉了。
这才像一个人的研发部。
不是写完就走。
而是上线之后还能盯住系统。
最小研发部,只需要一张纸
讲到这里,这件事可能听起来很重。
但一人公司不需要复制大公司的研发流程。
你真正需要的是一个最小版本。
下次你准备用 AI 做一个功能,不要先打开编辑器。
先写这张纸:
1. 产品:这个功能解决谁的什么问题?2. 架构:这次改动碰到哪条核心边界?3. 工程:AI 改了什么,我能不能解释清楚?4. QA:上线前必须走哪 5 条路径?5. 运维:上线后我要看哪 3 个信号?这 5 行,就是一个人的研发部雏形。

它不会让你变慢。
相反,它会挡掉很多后面更慢的事。
因为真正拖慢独立开发者的,通常不是写代码。
而是需求做错了、边界长歪了、代码接不住了、旧功能坏了、上线后失联了。
AI coding 的红利还在,而且会继续变强。
但越是这样,独立开发者越不能只盯着“写代码更快了”。
当所有人都能更快做出 demo,真正拉开差距的,就不是谁更会提示 AI 写页面。
而是谁能把需求、架构、工程、测试、运维压成一套稳定流程。
一人公司不是一个人干十个人的活。
而是把十个人的关键判断,压缩成一个人每天能执行的工作流。
所以你以为你缺一个更强的 AI 程序员。
其实你缺的是一个最小研发部。
不要让 AI 只当外包程序员。
让它进入你的研发流程。
done
-
• Hacker News:solo founder、AI agents、AI generated code、agent workflow 相关讨论 -
• Reddit r/SaaS:solo founder 的 deployment、integration、distribution、tool fragmentation 讨论 -
• 已发布文章: Vibe coding 进入下半场,独立开发者该补哪几课 -
• 已发布文章: 别把 Alfred 只当启动器,独立开发者最值得装的是这 3 个工作流