 夜雨聆风
夜雨聆风





Milvus VTS 源码级拆解: 2 种写入模式与分片策略,带你实战向量数据迁移的最佳实践
🚩 2026 年「术哥无界」系列实战文档 X 篇原创计划 第 98 篇,Milvus 最佳实战「2026」系列第 7 篇
大家好,欢迎来到 术哥无界 | ShugeX | 运维有术。
我是术哥,一名专注于 AI 编程、AI 智能体、Agent Skills、MCP、云原生、AIOps、Milvus 向量数据库的技术实践者与开源布道者!
Talk is cheap, let’s explore。无界探索,有术而行。
做过向量数据库迁移的人都知道这事有多头疼。
不同向量数据库之间没有标准化的数据格式,Schema 互不兼容,传统 ETL 工具(比如 Airbyte、SeaTunnel 主线版本)压根不支持向量类型。写过迁移脚本的同学应该深有体会:光是处理 FloatVector 和 SparseFloatVector 的类型映射,就能耗掉一整天。
Zilliz 官方推出的 VTS(Vector Transport Service)试图从根本上解决这个问题。它基于 Apache SeaTunnel 框架,已经支持 Milvus、Pinecone、Qdrant、Elasticsearch、pgvector 等 8 种以上数据源之间的互相迁移。根据官方公布的基准测试数据,Pinecone → Milvus 迁移 1 亿向量,4 核 8GB 的机器上跑出了 2,961 vectors/s 的吞吐量。
翻了一圈 VTS 的源码(GitHub: zilliztech/vts),发现它的架构设计有不少值得细看的地方。今天这篇文章,就从源码层面拆解 VTS 的核心机制:分片策略怎么设计的、两种写入模式分别适合什么场景、错误处理有多完善、性能调优该怎么配参数。
说明:本文内容基于 VTS 源码(zilliztech/vts)和 Apache SeaTunnel 官方文档分析整理而成,源码分析基于笔者本地仓库版本,尚未在生产环境中完成全场景验证。文中的配置模板和参数建议仅供参考,实际效果请以你的业务数据和环境测试结果为准。如果有实际使用经验,欢迎在评论区分享交流。
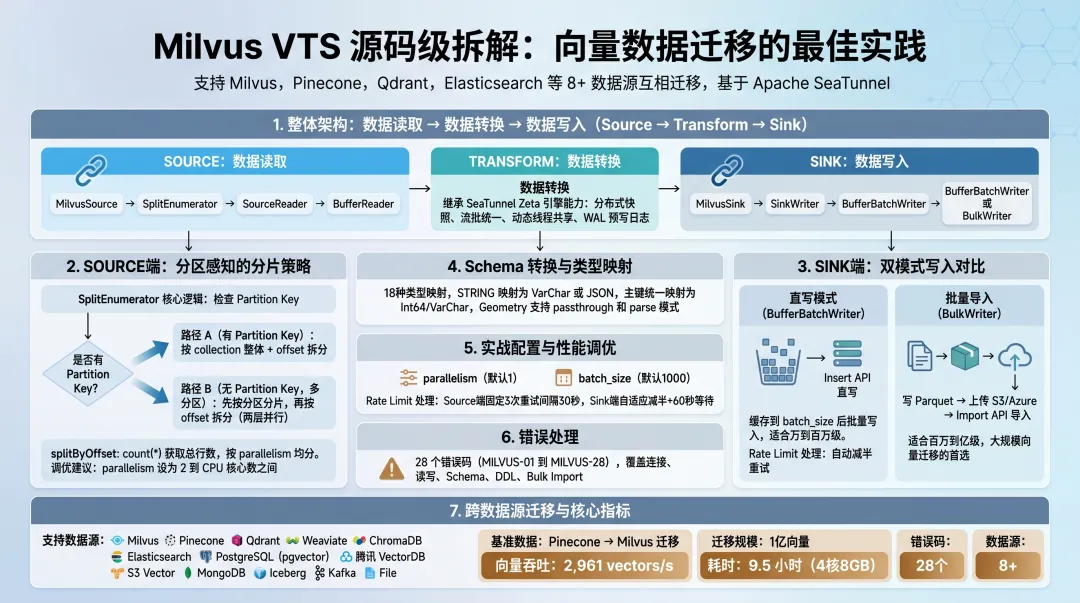
1. 整体架构:Source → Transform → Sink
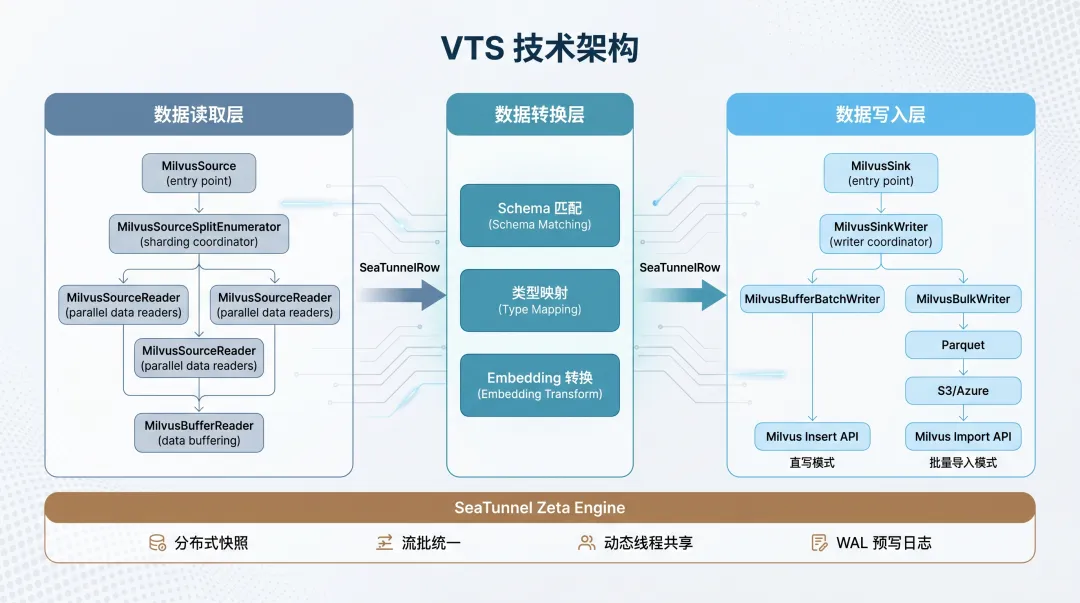
VTS 继承了 Apache SeaTunnel 的核心架构:Source(数据读取) → Transform(数据转换) → Sink(数据写入)。三段式设计的好处是每一段都可以独立扩展,新增一个数据源只需要实现对应的 Connector。
在 VTS 的 Java 代码里,Milvus Connector 的核心类结构如下:
Source 端:
-
MilvusSource→MilvusSourceSplitEnumerator→MilvusSourceReader→MilvusBufferReader
Sink 端:
-
MilvusSink→MilvusSinkWriter→MilvusBufferBatchWriter(直接写入)或MilvusBulkWriter(Bulk Import)
这个类层级不是随便设计的。SplitEnumerator 负责把数据切成多个分片,Reader 负责从每个分片里读数据,Writer 负责把数据写到目标端。SplitEnumerator 和 Reader 之间通过分片分配机制解耦,Reader 可以在多个节点上并行执行。
VTS 还继承了 SeaTunnel Zeta 引擎的几个关键能力:
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
这些能力不是 VTS 自己实现的,而是 SeaTunnel 框架层提供的。VTS 在此基础上,增加了向量数据库专属的 Schema 匹配、类型映射和 Embedding Transform。
2. Source 端:分区感知的分片策略
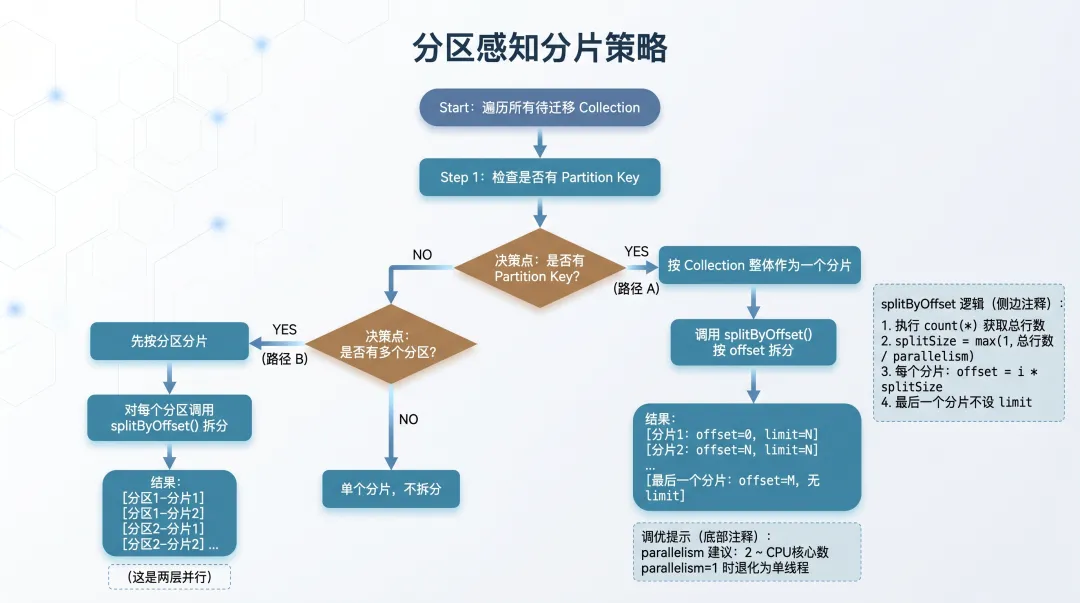
VTS 的 Source 端最值得分析的是它的分片策略。分片决定了数据读取的并行度,直接影响迁移速度。
分片枚举器的工作流程
MilvusSourceSplitEnumerator 是分片策略的核心。它的 run() 方法逻辑很清晰:
-
遍历所有待迁移的 collection -
对每个 collection 调用 generateSplits()生成分片 -
把分片分配给注册的 Reader
关键在 generateSplits() 方法里。源码里,它先做了一件事:检查 collection 是否有 Partition Key。
// MilvusSourceSplitEnumerator.java 第 116-118 行boolean hasPartitionKey = describeCollectionResp.getCollectionSchema().getFieldSchemaList().stream() .anyMatch(CreateCollectionReq.FieldSchema::getIsPartitionKey);两种分片路径
根据 hasPartitionKey 的结果,分片走两条不同的路径:
路径 A:有 Partition Key
如果 collection 设置了 partition key,Milvus 内部会自动管理分区,VTS 直接按 collection 整体作为一个分片,然后通过 splitByOffset() 按 offset 拆分。
路径 B:没有 Partition Key,但有多个分区
如果 collection 没有设置 partition key,但手动创建了多个分区(partition),VTS 会先按分区分片,再对每个分区按 offset 拆分。这是两层并行。
// MilvusSourceSplitEnumerator.java 第 126-137 行if (!hasPartitionKey && partitionList.size() > 1) {for (String partitionName : partitionList) { MilvusSourceSplit split = MilvusSourceSplit.builder() .tablePath(table.getTablePath()) .splitId(String.format("%s-%s", table.getTablePath(), partitionName)) .partitionName(partitionName) .build(); milvusSourceSplits.addAll(splitByOffset(split, parallelism)); }}splitByOffset:按行数均分
splitByOffset() 是分片的精细控制逻辑。它的实现方式很直接:
-
对 collection(或分区)执行 count(*)查询获取总行数 -
按 parallelism参数均分 -
最后一个分片不设 limit,兜底剩余数据
// MilvusSourceSplitEnumerator.java 第 151-205 行(简化)long numOfEntities = // count(*) 查询结果long splitSize = Math.max(1, numOfEntities / parallelism);for (int i = 0; i < parallelism; i++) {long offset = i * splitSize;if (i == parallelism - 1) {// 最后一个分片不设 limit newSplit = ...offset(offset).build(); } else { newSplit = ...offset(offset).limit(splitSize).build(); }}这里有个细节值得注意:如果 parallelism < 2,splitByOffset() 直接返回单个分片,不做拆分。也就是说,并行度设为 1 时退化为单线程读取。
实际调优建议:parallelism 不是越大越好。每个分片对应一个 Reader 线程,并行度太大会给 Milvus 服务端造成并发压力,反而容易触发 Rate Limit。从源码来看,一个合理的范围是 2 到 CPU 核心数之间。
3. Sink 端:双模式写入机制

VTS 的 Sink 端有两种写入模式,这是理解它性能特征的关键。两种模式分别对应 MilvusBufferBatchWriter 和 MilvusBulkWriter 两个类。
BufferBatchWriter:Insert API 直写
这是默认模式。工作方式是:数据缓存到 milvusDataCache(一个 List<JsonObject>),当缓存大小达到 batch_size 时,调用 Milvus Insert API 批量写入。
// MilvusBufferBatchWriter.java 第 102-119 行publicvoidwrite(SeaTunnelRow element){ JsonObject data = milvusSinkConverter.buildMilvusData( catalogTable, descriptionCollectionResp, milvusFieldMapper, element); milvusDataCache.add(data); writeCache.incrementAndGet(); writeCount.incrementAndGet();if (needCommit()) { commit(true); }}needCommit() 的判断逻辑很简单:writeCache >= batchSize。
优点:实现简单,延迟低,适合中小规模数据迁移。
缺点:数据量大时会给 Milvus 服务端造成写入压力;单条消息过大会报 received message larger than max 错误。
不过 VTS 在这里做了一个有意思的处理——遇到 Rate Limit 或消息过大的错误时,自动把 batch_size 减半重试:
// MilvusBufferBatchWriter.java 第 172-199 行(简化)if (e.getMessage().contains("rate limit exceeded") || e.getMessage().contains("received message larger than max")) {if (data.size() > 2) {this.batchSize = this.batchSize / 2; Thread.sleep(60000); // 等待 1 分钟// 对半拆分后递归重试 insertWrite(partitionName, firstHalf); insertWrite(partitionName, secondHalf); }}递归减半直到 data.size() <= 2,如果还失败就抛异常。这是一个实用但稍显粗暴的自适应策略。
BulkWriter:Parquet + Import API
这是面向大规模数据迁移的模式。工作方式完全不同:
-
数据写入 Parquet 文件 -
Parquet 文件上传到对象存储(S3 或 Azure Blob) -
调用 Milvus Import API 从对象存储导入
// MilvusBulkWriter.java 核心逻辑RemoteBulkWriterParam param = RemoteBulkWriterParam.newBuilder() .withCollectionSchema(describeCollectionResp.getCollectionSchema()) .withConnectParam(storageConnectParam) // S3 或 Azure .withChunkSize(stageBucket.getChunkSize() * 1024 * 1024) .withRemotePath(stageBucket.getPrefix() + "/" + collectionName + "/" + partitionName) .withFileType(BulkFileType.PARQUET) .build();remoteBulkWriter = new RemoteBulkWriter(param);BulkWriter 支持两种云存储:S3 兼容存储(通过 S3ConnectParam)和 Azure Blob(通过 AzureConnectParam)。选择逻辑基于 stageBucket.getCloudId() 判断是 az/azure 还是其他。
如果 stageBucket.getAutoImport() 为 true,写入完成后会自动调用 Milvus Import API 导入数据,并且会等待导入任务完成:
// MilvusBulkWriter.java 第 133-151 行publicvoidclose()throws Exception { remoteBulkWriter.close();if (stageBucket.getAutoImport()) { String objectFolder = ...; milvusImport.importFolder(objectFolder); }}publicvoidwaitJobFinish(){if (stageBucket.getAutoImport()) { milvusImport.waitImportFinish(); }}BulkWriter 适用场景:亿级向量的大规模迁移,尤其是 Milvus 集群间迁移。Import API 的吞吐远高于 Insert API。
两种模式怎么选?
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
一句话:数据量小(百万以下)用 BufferBatchWriter,数据量大(百万以上)用 BulkWriter。
4. Schema 转换与类型映射
跨向量数据库迁移,Schema 映射是最容易出问题的一环。VTS 通过 MilvusSchemaConverter 处理从 SeaTunnel 内部类型到 Milvus 类型的转换。
完整的类型映射表
从 MilvusSchemaConverter.convertSqlTypeToDataType() 方法可以提取出完整的映射关系:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
有几个点值得注意:
-
STRING 不一定是 VarChar。源码里有个判断:如果列的 options 里标记了 JSON = true,STRING 会被映射为JSON类型 -
ARRAY[Struct] 有特殊处理。如果数组元素类型是 ROW,元素类型会被设为Struct而不是按常规映射 -
主键类型会被统一处理。不管源端是 INT 还是 BIGINT,只要是主键,都会被映射为 Int64;如果是字符串类型主键,映射为VarChar
Geometry 字段的处理
VTS 对 Geometry(地理空间)字段有专门的配置。源码中定义了两个相关参数:
-
geometry_convert_mode(默认passthrough):控制是否对 Geometry 字符串做格式转换。passthrough模式直接透传,适合 Milvus → Milvus 迁移;parse模式会自动检测 WKT/EWKT/GeoJSON/WKB 等格式并转换,适合从 Elasticsearch 或 PostgreSQL 迁移 -
geometry_string_coord_order(默认lat_lon):控制裸坐标字符串(如"31.23,121.47")的解析顺序。Elasticsearch 的geo_point习惯 lat 在前,PostgreSQL 某些输出格式 lon 在前。配错会导致坐标全部反转
5. 实战配置与性能调优
基础配置示例
一个完整的 Milvus → Milvus 迁移配置如下:
env { parallelism = 4 job.mode = "BATCH"}source { Milvus { url = "https://source-milvus:19530" token = "root:Milvus" database = "default" collections = ["articles", "products"] batch_size = 1000 }}sink { Milvus { url = "https://target-milvus:19530" token = "root:Milvus" database = "default" batch_size = 1000 enable_dynamic_field = true schema_save_mode = "CREATE_SCHEMA_WHEN_NOT_EXIST" data_save_mode = "APPEND_DATA" }}如果不指定 collections,VTS 会读取整个 database 的所有 collection。
parallelism 与 batch_size 的权衡
这两个参数是性能调优的核心:
parallelism(源码中 MilvusSourceConfig.PARALLELISM,默认值 1):
-
控制每个 collection 的分片数量 -
每个分片由一个独立 Reader 读取 -
设为 1 时不做 offset 拆分,退化为单线程 -
建议设为 2 ~ CPU 核心数 -
设太大会导致大量并发 count(*)查询和 QueryIterator 请求
batch_size(源码中默认值 1000):
-
Source 端: QueryIteratorReq的批量读取大小 -
Sink 端:Insert API 的批量写入大小 -
源码中 BufferBatchWriter 在遇到 Rate Limit 时会自动减半,初始值可以设大一些
一个务实的调优思路:先按默认配置跑,观察日志里有没有 rate limit exceeded 的警告。有就把 batch_size 调小,没有就逐步调大,直到找到吞吐量和稳定性的平衡点。
Rate Limit 处理策略
从源码看,VTS 在 Source 和 Sink 两端都有 Rate Limit 处理:
Source 端(MilvusBufferReader):
-
检测到 rate limit exceeded后最多重试 3 次 -
每次重试间隔 30 秒( rateLimitRetryIntervalMs = 30000) -
3 次重试用尽后抛出 READ_DATA_FAIL异常
Sink 端(MilvusBufferBatchWriter):
-
检测到 Rate Limit 或消息过大后,batch_size 自动减半 -
等待 60 秒后递归重试 -
减半直到 data.size() <= 2还失败则抛异常
两端的策略不一样:Source 端是固定次数重试,Sink 端是自适应降级。Sink 端的策略更实用,因为 batch_size 过大本身可能是问题的根源。
自定义 Schema 的场景
VTS 的 Sink 端支持通过 field_schema 参数完全覆盖源端 Schema。这在源端和目标端 Schema 不一致的场景下很有用:
sink { Milvus { url = "https://target-milvus:19530" token = "root:Milvus" field_schema = [ {field_name = "id", data_type = 5, is_primary_key = true, auto_id = true} {field_name = "embedding", data_type = 101, dimension = 768} {field_name = "category", data_type = 21, max_length = 100, is_partition_key = true} ] }}源码注释里写得很明确:当提供了 field_schema 时,只有其中定义的字段会被使用,源端 Schema 不再参考。data_type 使用 Milvus 的数字编码,比如 5 = Int64,21 = VarChar,101 = FloatVector。
还支持从动态字段中提取数据,用 source_field_name 指定源端字段路径:
field_schema = [ {source_field_name = "metadata.title", field_name = "title", data_type = 21, max_length = 200} {source_field_name = "metadata.tags", field_name = "tags", data_type = 22, element_type = 21}]6. 错误处理体系
VTS 定义了从 MILVUS-01 到 MILVUS-28 共 28 个错误码,覆盖了连接、读写、Schema 操作等各个环节。按类型梳理如下:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
有几个错误码在实际使用中比较常见:
MILVUS-06 COLLECTION_NOT_LOADED:Source 端在读取前会检查 Collection 的 LoadState,如果没加载就直接报错。迁移前确保 Collection 已 Load。
MILVUS-17 WRITE_DATA_FAIL:写入失败。最常见的原因是 Rate Limit 或单条消息过大。从源码看,BufferBatchWriter 会自动处理这两种情况。
MILVUS-27 COMPLETED_WITH_ERRORS:BulkWriter 的 Import 任务部分失败。这个错误码说明导入任务跑完了,但有些行没成功,需要关注错误行数是否超过阈值(MILVUS-28)。
你在迁移过程中遇到过类似的问题吗?欢迎在评论区聊聊你的踩坑经历。
7. 跨数据源迁移:从 Pinecone 到 Milvus
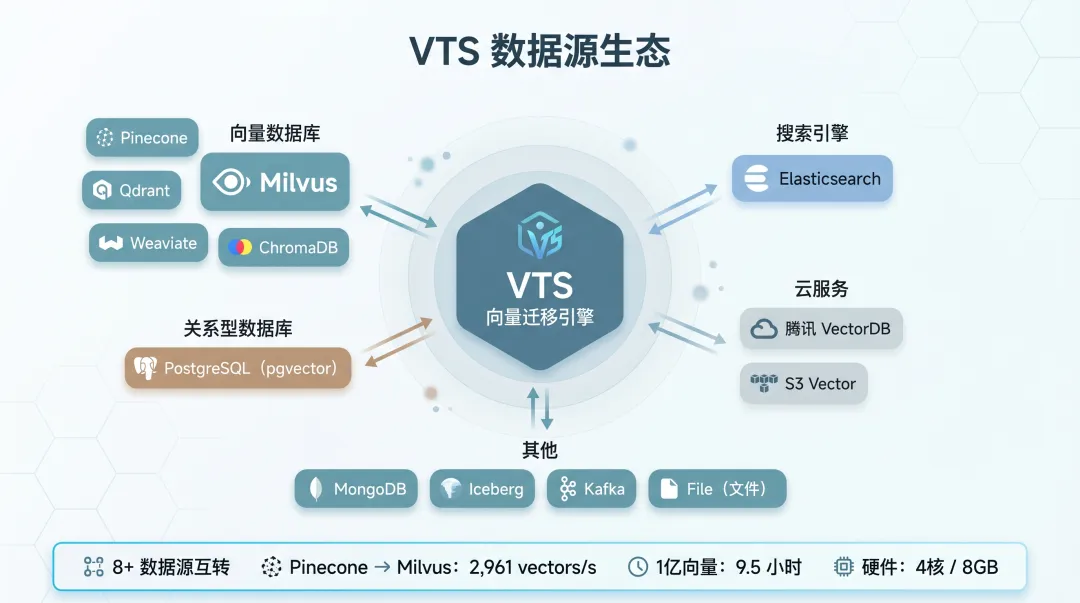
VTS 不只是 Milvus → Milvus 的迁移工具。从源码的 connector 目录结构看,它已经支持以下数据源作为 Source:
-
向量数据库:Milvus、Pinecone、Qdrant、Weaviate、ChromaDB -
搜索引擎:Elasticsearch -
关系型数据库:PostgreSQL(pgvector 扩展) -
云服务:腾讯 VectorDB、S3 Vector -
其他:MongoDB、Iceberg、Kafka、File
不同 Source 的 Connector 都遵循 SeaTunnel 的标准接口,差异主要在数据读取和 Schema 转换的实现上。以 Pinecone → Milvus 为例,VTS 会把 Pinecone 的向量数据转换为 SeaTunnel 内部的 SeaTunnelRow,再经过 MilvusSchemaConverter 转为 Milvus 的 Schema 定义,最终通过 Sink 写入。
官方基准测试数据:Pinecone → Milvus 迁移 1 亿向量,同步速率 2,961 vectors/s,总耗时约 9.5 小时,硬件配置仅 4 核 / 8GB 内存。这个数据说明 VTS 在有限资源下能保持不错的吞吐。
不过说实话,跨数据源迁移的坑主要集中在 Schema 不兼容 上。不同向量数据库对向量维度的约束、稀疏向量的表示方式、元数据的存储格式都不一样。VTS 的 Schema 转换能处理大部分情况,但遇到特殊的数据类型(比如某个数据库私有的向量编码格式),还是可能需要通过 field_schema 手动调整。
总结
从源码层面看,VTS 是一个设计比较务实的工具。它没有试图从零造轮子,而是站在 Apache SeaTunnel 的肩膀上,把精力集中在向量数据库的专属问题上。
几个关键设计决策值得肯定:
-
分区感知的分片策略:自动识别 Partition Key,根据分区信息做并行分片,对大规模数据迁移很关键 -
双模式写入:BufferBatchWriter 和 BulkWriter 分别覆盖小规模快速迁移和大规模批量导入两种场景 -
自适应错误恢复:Rate Limit 自动减半重试、固定次数重试等策略,在无人值守迁移时很实用 -
灵活的 Schema 控制: field_schema参数允许完全自定义目标端 Schema,包括动态字段提取
但也有需要注意的地方:项目在 GitHub 上只有 124 Star,社区规模还比较小,遇到问题可能得自己翻源码。好在代码结构清晰,核心类不超过 20 个,定位问题并不困难。
如果你的场景是 Milvus 内部迁移(比如集群升级),milvus-backup 可能更简单。但如果涉及跨数据源(从 Pinecone、ES、Qdrant 等迁到 Milvus),或者需要 Transform(字段映射、表名更改、Embedding 转换),VTS 是目前为数不多的选择。
好啦,谢谢你观看我的文章,如果喜欢可以点赞转发给需要的朋友,我们下一期再见!敬请期待!
扫码关注,获取更多 AI 工具的实战经验和最佳实践。不错过每一篇干货!

加入微信群,共同交流,共同进步!
