 夜雨聆风
夜雨聆风





SeaTunnel + AI:一句“我要做什么”,能不能直接变成一份能跑的配置?

https://github.com/apache/seatunnel
点击蓝字
关注我们
围绕 Apache SeaTunnel Discussion #10651 的一些思考:AI 写配置,难的从来不是“写出来”,而是“写出来以后真能用。”
这两年,几乎所有数据工具都会被问到一个问题:配置,能不能别再手写了?
放到 SeaTunnel 里,这个问题会更具体一点:
一句“我要做什么”,能不能直接变成一份配置?
再进一步,这份配置能不能不是“看起来差不多”,而是真的能跑、能审、能改?
手写 SeaTunnel 配置这件事,很多人都不陌生。真正麻烦的,往往不是“把配置写出来”,而是下面这些事:
-
写完能不能跑; -
出错以后好不好排查; -
换个人接手能不能看懂; -
需求一变,能不能低成本改。
AI 当然可以帮忙。但如果目标只是“生成一段 HOCON”,价值其实没那么大。因为真正麻烦的,从来不是把字敲出来,而是写完以后别坑自己,也别坑下一个接手的人。
所以更值得做的,不是“AI 帮我写配置”这件事本身,而是把自然语言里的“我要做什么”,稳定地翻成一份能跑、可审、可迭代的 SeaTunnel 配置。
这篇文章主要想讲三件事:
-
为什么这件事值得做; -
一条比较稳的实现路径是什么; -
社区最近的讨论和原型,已经走到了哪一步。
1. AI 写配置这件事,
真正的需求在哪里
1.1 手写配置为什么会成为瓶颈
SeaTunnel 的任务配置本质上是一门 DSL(常见为 HOCON,也支持 JSON/SQL),由env / source / transform / sink四段拼成一条可执行的数据管道。它的表达力很强,但也正因为表达力强,配置编写天然带有“工程门槛”。当团队规模、数据源种类、任务数量一起上来后,手写配置几乎一定会稳定地产生四类成本:
-
语法细节密集:嵌套层级、数组/对象结构、字段类型、引号与转义,任何一个点错了都在运行时爆炸。 -
易错且难排:错误往往体现在“任务启动失败”或“运行中失败”,定位时需要同时理解引擎侧约束、连接器参数语义、变量替换规则与默认约定。 -
学习成本高:新人要学 HOCON 写法、SeaTunnel 约定(如 plugin_output/plugin_input)、连接器能力边界、以及引擎差异。 -
多源异构适配慢:一旦从“单表同步”升级到“多源 join / 入湖 / CDC / 多表同步”,配置复杂度非线性增长,模板很快失效。
SeaTunnel 官方对配置文件结构与变量替换的说明见:https://seatunnel.apache.org/docs/2.3.8/concept/config/
1.2 Discussion #10651 真正在问什么
Discussion #10651 里提到的问题,我理解核心是这一类工程诉求:
我不想再从 0 开始写 DSL;我希望输入“我要做什么 + 我有什么数据源 + 我有哪些约束”,系统就能生成一份能跑、可审、可迭代的 SeaTunnel 配置,并在失败时给出可操作的修复建议。
讨论入口:https://github.com/apache/seatunnel/discussions/10651
1.3 我先说结论
我不太关心“AI 能不能直接写一段 HOCON”。这个问题演示起来不难,难的是生成结果能不能进入日常使用。我的判断是,这件事要走一条更工程化的路:先把自然语言变成结构化 IR,再渲染成 SeaTunnel HOCON,最后补上可机器检查的校验报告。这样做,至少有三个直接好处:
-
能跑:生成结果满足 SeaTunnel 配置结构、连接器必填参数和引擎约束。 -
可审:敏感信息变量化,关键决策进入 IR,默认值和待确认项清晰可见。 -
可迭代:校验失败时能回到 IR 或 patch 层做最小修复,而不是重新生成整份配置。
有了这个判断,下面的问题就比较清楚了:这条链路到底该怎么搭。
2. 真要做,这条链路该怎么搭
2.1 先别急着让模型直接吐 HOCON
直接让模型吐一段 HOCON,演示效果通常会不错,但工程上不太够。更稳的做法,是把配置生成拆成几个明确阶段,每个阶段都能检查。一个最小闭环大概是这样:
-
意图识别(Intent Parsing):从自然语言提取任务类型、源/目标、模式(批/流)、SLA、容错需求。 -
元数据感知(Metadata Awareness):获取源端 schema、主键/增量位点、目标端约束(字段类型、分区、写入模式)。 -
连接器推荐(Connector Resolution):根据“意图 + 引擎 + 环境约束”选择连接器组合,并确认版本兼容。 -
参数自动补全(Auto Fill):填充必填项与合理默认值;不确定项输出“待确认清单”,而不是瞎猜。 -
语法与语义校验(Lint + Semantic Check):HOCON 语法、连接器参数 schema、变量替换、敏感信息合规;失败时生成可执行的修复 patch。
模型负责先给方案,系统负责兜底和校验。
2.2 从结构上看,这套方案其实就是两条链路
从结构上看,这套方案可以拆成两条链路:控制链(意图→计划)和产物链(计划→配置→执行)。这么拆,读起来和实现起来都会更清楚。
2.2.1 模块划分
-
Intent Parser:自然语言 → IntentSpec(结构化 JSON) -
Metadata Provider:从 JDBC/Catalog/信息模式拉取 schema 与约束 -
Connector Resolver:连接器能力矩阵匹配(引擎兼容、是否支持 CDC、是否支持 Exactly-Once 等) -
Plan Builder:生成 JobPlanIR(强类型 IR,类似 AST) -
Config Renderer: JobPlanIR→ HOCON/JSON(默认 HOCON) -
Config Linter:语法 + 参数校验 + 安全策略校验 -
Submitter(可选):提交作业、查询状态、停止作业、回滚
2.2.2 执行流程图(文字时序)
-
用户输入自然语言 + 环境约束 -
Intent Parser 输出 IntentSpec -
Metadata Provider 拉取 schema/主键/增量位点/目标约束 -
Connector Resolver 选择 Source/Sink/Transform 组合 -
Plan Builder 输出 JobPlanIR -
Config Renderer 生成 seatunnel.conf -
Config Linter 输出 validation_report(通过/失败 + 修复建议) -
通过后 Submitter 提交;失败则基于 report 进入“修复-再校验”循环
执行端这块其实不用从零开始。SeaTunnel MCP server 已经演示了 LLM 如何通过工具提交和管理 SeaTunnel 任务,做 MVP 时可以直接参考:https://github.com/apache/seatunnel-tools
2.3 社区里已经有人开始往前走了
PR #10789 做了一个独立的seatunnel-cli原型,用 Python CLI 把“自然语言 → 配置生成 → 校验 → 执行”串了起来。对我来说,它的意义很直接:这件事已经不是停留在想法上了,社区里已经有人开始把它做成工具。
这个 PR 对本文方案有几个很强的印证:
-
交互形态不一定要先做 Web,CLI + REPL 对 MVP 来说反而更顺手。 -
生成链路适合拆成多阶段 Agent,而不是单轮直接产出配置;PR 中采用的是 Planner → Generator → Validator → Auto-fix。 -
连接器知识库不必完全手工维护;PR 展示了“运行时 REST API → 自动生成 catalog → 关键词路由”的三层知识来源。 -
校验不能只做静态 lint;PR 已把本地语法检查、引擎 --check和 REST API 校验串起来,这比“只生成不校验”更接近真实使用场景。 -
如果想让大家真用起来,光会生成还不够, /check、/run、自动修复、自动保存这些也得一起补上。
这个 PR 还顺手提醒了另一件事:一旦系统支持会话记忆、连接信息记忆,安全约束必须一起跟上。默认脱敏、默认变量化、外部密钥管理,这些不能往后放。
方向说清楚了,再往下就不是“能不能做”,而是“先怎么落地”。
3. 如果做一个MVP,
第一版应该长什么样
3.1 输入输出格式:先把协议定下来
MVP 最怕的是输出一会儿一个样,字段今天这么叫、明天那么叫,出了问题也没法回放。最省事的办法,还是先把 I/O 协议定下来。
3.1.1 输入:IntentSpec(JSON)
{"intent": "把 mysql.shop.orders 全量同步到 Doris ods.orders,每天跑一次","engine": "zeta","mode": "BATCH","source": {"type": "mysql","jdbc_url": "${MYSQL_URL}","username": "${MYSQL_USERNAME}","password": "${MYSQL_PASSWORD}","database": "shop","table": "orders"},"sink": {"type": "doris","fenodes": "${DORIS_FENODES}","username": "${DORIS_USERNAME}","password": "${DORIS_PASSWORD}","database": "ods","table": "orders"},"constraints": {"parallelism": 4,"no_plaintext_secret": true,"target_ddl_policy": "validate_only"}}
3.1.2 输出:配置 + 校验报告
seatunnel.conf:
HOCON(默认),敏感信息必须变量化 ${...}validation_report.json:
错误/告警/待确认参数清单/修复建议(可生成 patch)
3.2 提示词不是主角,边界才是
这里没必要把提示词讲得太玄。重点只有一个:把不确定性关进可验证的范围里。MVP 用“三段式 Prompt”就够了:
3.2.1 Prompt A:意图 → 计划(只产 IR,不产配置)
目标:输出JobPlanIR(JSON),固定字段、固定枚举、禁止自然语言解释。
关键约束:
-
明确 job.mode、引擎、source/sink plugin_name -
确定 plugin_output/plugin_input引用关系;旧版result_table_name/source_table_name只作为兼容输入处理 -
不允许出现明文密钥 -
不确定项必须落在 todo_items[]
3.2.2 Prompt B:计划 → HOCON 渲染
目标:只输出 HOCON,并严格限制段落为env/source/transform/sink。
关键约束:
-
所有敏感字段必须写 ${VAR}或${VAR:default} -
不允许输出不存在的参数名(参数名必须来自规则库)
3.2.3 Prompt C:自检(Lint + Semantic)
目标:输出结构化的validation_report.json:
{"errors": [],"warnings": [],"todo_items": [],"patch_suggestion": ""}
3.3 模型怎么选:本地开源还是云端大模型
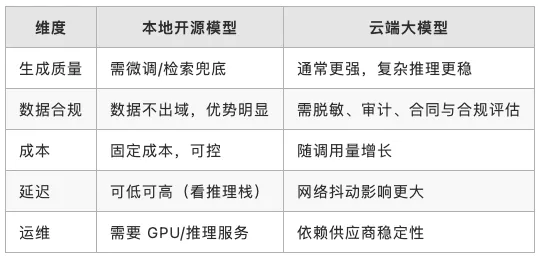
MVP 阶段一般还是先用云端把“生成 → 校验 → 提交 → 回滚”这条链路跑通,再根据企业合规和成本情况,往本地或混合部署迁。
3.4 哪些兼容规则最好一开始就定死
兼容规则如果不提前写清楚,后面会很乱。下面这些我更倾向于直接当成硬约束:
-
默认输出 HOCON;需要 JSON/SQL 时必须显式声明,并遵守扩展名约束( .json)参考官方说明:https://seatunnel.apache.org/docs/2.3.8/concept/config/ -
段落固定: env → source → transform → sink plugin_output/plugin_input
只在跨段落引用、多个 source/sink 或 transform 链路中显式写;单链路场景尽量减少噪音 -
变量替换使用 ${var}、${var:default},并统一由运行注入(不写死环境差异) -
禁止输出明文密码/AK/SK;统一走变量或外部密钥管理系统
这些边界先定住以后,下面一个更现实的问题就是:连接器规则到底从哪儿来。
3.5 规则库不一定要全手写
PR #10789 有个点我觉得挺实用:它没有把连接器规则全压在人工维护上,而是去扫 SeaTunnel Java 源码里的*Factory.java和*Options.java,自动生成 connector catalog,再去处理 option inheritance chain。这对规则库设计很有帮助。
更实际的做法,不是全靠手写 rules,而是分两层:
-
自动生成层:从源码抽取 connector 名称、 OptionRule、默认值、必填参数、参数别名。 -
人工增强层:补充静态代码里不容易表达的知识,例如 CDC 能力、推荐引擎、典型组合、常见误配、企业安全策略。
如果运行中的 SeaTunnel 集群还能暴露/option-rules这类接口,那么知识获取链路可以进一步升级为:
-
运行时接口优先:获取当前版本最准确的 connector 规则; -
自动生成 catalog 兜底:避免离线或无集群时完全失能; -
关键词/示例路由补充:提升自然语言到 connector 的命中率。
所以这里的rules/connectors.yaml,更像是自动生成规则之上的人工校正层,不太像一份从头到尾手写维护的“参数大全”。
说到这里,抽象的东西已经差不多了。下面直接看一个完整例子。
4. 看一个完整例子:
从“我要做什么”到配置真跑起来
下面直接看一个完整样例,把“自然语言 → IR → HOCON → 校验报告”串起来。
把mysql.shop.orders全量同步到 Dorisods.orders,每天跑一次,使用 zeta 引擎,并行度 4。
生成器不应该只输出一段 HOCON,而应该同时输出JobPlanIR、seatunnel.conf和validation_report。IR 用来审查意图,HOCON 用来执行,校验报告用来暴露风险和待确认项。
这里顺手解释一个读者很容易疑惑的点:示例里 source 的业务类型写的是mysql,但真正渲染出来的plugin_name是Jdbc。原因不是写错了,而是这个例子描述的是“全量读取 MySQL 单表”,在 SeaTunnel 里更贴近 JDBC Source 的使用场景;如果目标是 MySQL CDC,同一类意图最后落出来的 source plugin 往往会变成MySQL-CDC。
4.1 先看 JobPlanIR:它负责把意图固定下来
可以把JobPlanIR理解成生成器内部的一层中间表示,作用有点像 AST。它不直接执行,主要用来做连接器匹配、参数检查和后续渲染。
{"job_mode": "BATCH","engine": "zeta","source": {"type": "mysql","plugin_name": "Jdbc","sync_mode": "full","jdbc_url": "${MYSQL_JDBC_URL}","driver": "com.mysql.cj.jdbc.Driver","username": "${MYSQL_USERNAME}","password": "${MYSQL_PASSWORD}","database": "shop","table": "orders","table_path": "shop.orders"},"sink": {"type": "doris","plugin_name": "Doris","fenodes": "${DORIS_FENODES}","username": "${DORIS_USERNAME}","password": "${DORIS_PASSWORD}","database": "ods","table": "orders","data_save_mode": "${DORIS_DATA_SAVE_MODE:APPEND_DATA}","schema_save_mode": "${DORIS_SCHEMA_SAVE_MODE:CREATE_SCHEMA_WHEN_NOT_EXIST}","sink_label_prefix": "${DORIS_LABEL_PREFIX:orders_full_sync}","doris_config": {"format": "json","read_json_by_line": "true"}},"transform": [],"constraints": {"parallelism": 4,"schedule": "daily_external","no_plaintext_secret": true,"engine_compatibility": "Jdbc source + Doris sink are supported on SeaTunnel Zeta","secret_placeholders": ["MYSQL_JDBC_URL","MYSQL_USERNAME","MYSQL_PASSWORD","DORIS_FENODES","DORIS_USERNAME","DORIS_PASSWORD"]},"todo_items": ["确认每日调度方式;SeaTunnel HOCON 本身不内置 cron,需由外部调度器每天触发一次","确认 Doris 写入语义;当前为可运行兜底 APPEND_DATA,若需要覆盖式全量请改为 DROP_DATA","确认 mysql.shop.orders 存在主键或可切分列;否则 Jdbc Source 可能退化为单并发读取"]}
4.2 再看 seatunnel.conf:它负责真正执行
这一层尽量短一点,只保留运行必需参数。连接信息和密码都用变量占位,不写死。因为这是单链路任务,没有 transform,所以也不用额外声明plugin_output/plugin_input。这里保留空的transform {},只是为了让例子和 SeaTunnel 常见的env → source → transform → sink结构保持一致;真实生成时,如果没有 transform,也可以按团队习惯省略。
env {parallelism = 4job.mode = "BATCH"}source {Jdbc {url = ${MYSQL_JDBC_URL}driver = "com.mysql.cj.jdbc.Driver"username = ${MYSQL_USERNAME}password = ${MYSQL_PASSWORD}table_path = "shop.orders"}}transform {}sink {Doris {fenodes = ${DORIS_FENODES}username = ${DORIS_USERNAME}password = ${DORIS_PASSWORD}database = "ods"table = "orders"sink.label-prefix = "${DORIS_LABEL_PREFIX:orders_full_sync}"schema_save_mode = "${DORIS_SCHEMA_SAVE_MODE:CREATE_SCHEMA_WHEN_NOT_EXIST}"data_save_mode = "${DORIS_DATA_SAVE_MODE:APPEND_DATA}"doris.config {format = "json"read_json_by_line = "true"}}}
4.3 最后看 validation_report:它负责把问题说清楚
校验报告不是点缀,它主要回答两件事:哪里已经能跑,哪里还要人确认。
{"errors": [],"warnings": ["按示例意图生成:mysql.shop.orders 全量同步到 Doris ods.orders,每天跑一次,使用 zeta 引擎,并行度 4","为保证配置可运行,Doris data_save_mode 使用兜底默认值 APPEND_DATA;若目标是覆盖式全量,请改为 DROP_DATA","当前任务调度频率未编码在 SeaTunnel 配置中,需由外部调度系统实现每天一次触发","未显式设置 Jdbc 分片参数;若源表缺少主键或唯一索引,实际读取并发可能低于 env.parallelism=4"],"todo_items": ["补充外部调度器配置(如 cron、Airflow、DolphinScheduler)","确认 DORIS_DATA_SAVE_MODE 取值是否应为 DROP_DATA","确认 orders 表的主键/唯一键或 partition_column"],"patch_suggestion": ""}
这个例子里我最想强调的是三点:敏感信息不落盘,连接器参数有来源,不确定项不硬猜。
讲到这里,方案、协议和例子都已经看过了。最后回到一个更现实的问题:这样做,到底值不值。
5. 这样做,最后能省下什么
5.1 三组典型场景
5.1.1 数据库同步(MySQL → Doris)
-
手写:大量连接器参数与表映射细节 -
AI 生成:输入意图 + 连接信息 → 输出可运行 HOCON + 待确认项
5.1.2 湖仓入湖(Hive → Iceberg)
-
手写:catalog/warehouse/partition/commit 等参数组合复杂 -
AI 生成:按规则库补全必填项,并将不确定项列为待确认清单
5.1.3 日志采集(S3/Local → Elasticsearch)
-
手写:格式解析、字段映射、索引命名、错误重试策略容易漏 -
AI 生成:先产“最小可跑版本”,再根据校验/运行反馈迭代增强
5.2 对比维度(直观、非学术)
下面这些数值更多是经验估计,主要是为了给读者一个量级感,不是严格实验数据。具体收益还是要看团队对 SeaTunnel 的熟悉程度、元数据接入情况和连接器复杂度。
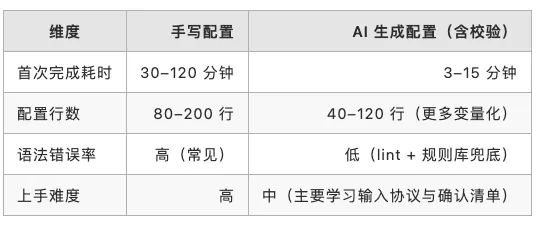
6. 这件事接下来还能怎么往前推
6.1 如果想在社区里继续推进,可以怎么协作
-
在 Discussion #10651 下补充:输入输出协议、MVP 里程碑、可复现 examples -
结合 PR #10789 继续讨论:未来是以 seatunnel-cli/作为独立工具演进,还是沉淀成“生成器内核 + CLI/API 前端”的两层架构 -
贡献方式: -
增强 connector catalog 自动生成能力(源码抽取、继承链解析、版本差异对比) -
补充连接器规则库(必填参数、默认值、引擎兼容) -
增强 validator(更可读的错误信息与修复建议) -
加强 secret handling(会话记忆脱敏、占位符注入、外部密钥管理集成) -
增加 examples(覆盖 JDBC/CDC/文件/湖仓)
6.2 真要落地,哪些坑得先想清楚
-
最容易出问题的,还是模型“看起来懂了,其实没懂”。所以更稳的做法不是让它自由发挥,而是用 IR、规则库和 lint 把输出尽量限制在可验证的范围里;碰到拿不准的地方,就老老实实列进待确认清单。 -
元数据这件事也不能想当然。schema、表结构、字段信息确实能帮生成器少走很多弯路,但前提是默认脱敏、拉取范围可控,而且 prompt 里不要混进敏感字段值。 -
如果后面支持会话记忆,风险就不只是“记住了上下文”,还包括“顺手把连接信息也记住了”。更合适的做法是只记别名、引用关系或密钥位置,不记明文账号密码。 -
还有一层是企业环境里的合规问题。比如审计日志、权限隔离、能不能切本地模型、配置发布是不是要审批和回滚,这些平时不显眼,但真上线时一个都绕不过去。
7. 最后留几个问题,继续聊
写到这里,我自己最关心的点还是没变:AI 会不会写配置,其实不是最难的部分。更难的是,怎么把“生成 → 校验 → 修复 → 执行”这一整套链路做稳。
如果这件事只是偶尔演示一下,能生成就够了;但如果真想让它进入团队日常流程,就得把后面的兜底、审查和修复一起补齐。
如果你也在关注这个方向,欢迎继续讨论下面几个问题。
7.1 Q&A(欢迎留言)
-
你们团队写 SeaTunnel 配置最大痛点是:语法、参数、还是排错? -
你更希望 AI 先解决“生成配置”,还是“失败后自动修复”? -
你能接受的交互形态是:Chat(对话式)还是 Form(结构化表单)?
7.2 小投票(评论区回复编号)
-
A:我需要“意图→配置”一键生成 -
B:我需要“配置→校验→修复建议” -
C:我需要“生成 + 提交 + 失败自愈”闭环 -
D:我只想要“连接器参数自动补全 + 模板库”
参考链接
-
Discussion #10651:AI 自动生成 SeaTunnel 任务配置文件https://github.com/apache/seatunnel/discussions/10651 -
PR #10789:为自然语言配置生成引入 seatunnel-cli原型https://github.com/apache/seatunnel/pull/10789 -
SeaTunnel 配置文件结构与变量替换(HOCON/JSON/SQL)https://seatunnel.apache.org/docs/2.3.8/concept/config/ -
SeaTunnel Tools 仓库(含 MCP 相关内容)https://github.com/apache/seatunnel-tools

·END·
白鲸开源
白鲸开源是一家开源原生的DataOps商业公司,是国家高新技术企业,由多个Apache Foundation Member成立,80%员工都是 Apache Committer,运营2个全球Apache开源项目(DolphinScheduler, SeaTunnel)。白鲸开源已根据全球最佳实践发布商业版产品WhaleStudio(含白鲸数据调度平台WhaleScheduler和白鲸数据集成平台WhaleTunnel)。我们致力于打造下一代开源原生的DataOps 平台,助力企业在大数据和云时代,智能化地完成多数据源、多云及信创环境的数据集成、调度开发和治理,以提高企业解决数据问题的效率,提升企业分析洞察能力和决策能力。
了解更多

金融行业的应用实例
国内某头部理财服务提供商基于白鲸调度系统建立统一调度和监控运维
白鲸调度系统助力国内头部券商打造国产信创化 DataOps 平台
白鲸开源 DataOps 平台助力证券行业实现信创数字化转型
最佳实践 | 从Airflow迁移到Apache DolphinScheduler
Apache DolphinScheduler VS WhaleScheduler
代立冬:基于Apache Doris+WhaleTunnel 实现多源实时数据仓库解决方案探索实践
商业版技术解析实例
驾驭数据的未来:WhaleStudio与DataOps的完美结合
运营开源项目

点个在看你最好看