 夜雨聆风
夜雨聆风





Claude Code源码分析——Claude Code Agent Loop 详细设计文档
Claude Code Agent Loop 详细设计文档
本文基于
claude-code/src/QueryEngine.ts与Claude-code-open-explain/02-agentic-loop/README.md,从软件架构视图、运行时流程视图、状态视图和关键逻辑视图分析 Claude Code 的 Agent Loop 设计。
1. 设计定位
Claude Code 的 Agent Loop 不是一个简单的 while 循环,也不是单个类完成所有事情。它采用了两层职责拆分:
-
QueryEngine.ts:会话级控制器,负责一轮请求前后的状态管理、参数组装、上下文准备、事件归一化、持久化与结果封装。 -
query.ts:请求级执行引擎,负责模型调用、工具执行、继续或终止判断、上下文压缩、错误恢复等真正的循环推进。
可以把 QueryEngine 理解成“会话控制面”,把 query() / queryLoop() 理解成“执行数据面”。前者决定本轮怎么开始、如何记账、如何把内部事件转成 SDK 消息;后者决定本轮如何一跳一跳地推进,直到模型不再需要工具或触发退出条件。
2. 总体架构视图
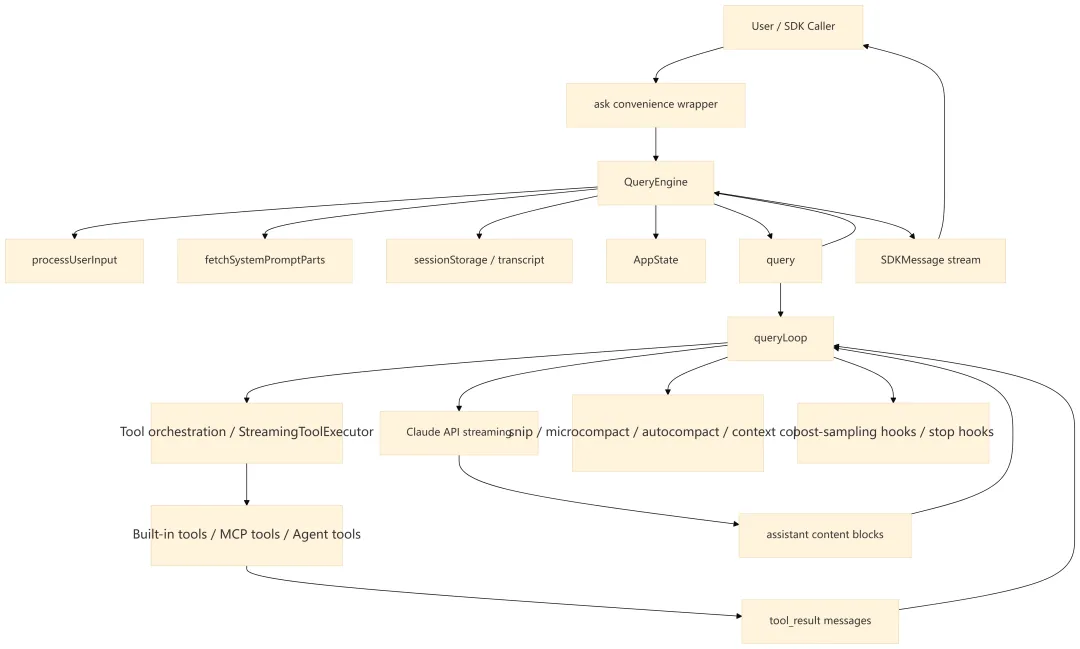
2.1 分层说明
|
|
|
|
|---|---|---|
|
|
ask()
QueryEngine.submitMessage() |
AsyncGenerator,支持流式输出、中断、SDK 结果封装 |
|
|
QueryEngine
submitMessage() |
|
|
|
processUserInput() |
|
|
|
fetchSystemPromptParts()
asSystemPrompt() |
|
|
|
query()
queryLoop() |
|
|
|
runTools()
StreamingToolExecutor |
tool_use、执行工具、生成 tool_result |
|
|
recordTranscript()
flushSessionStorage()、usage tracker |
|
|
|
normalizeMessage()
|
|
3. 关键对象视图
3.1 QueryEngineConfig
QueryEngineConfig 是会话控制器的依赖注入边界。它把环境、工具、命令、模型配置、状态读写函数、权限函数以及 SDK 选项集中传入。
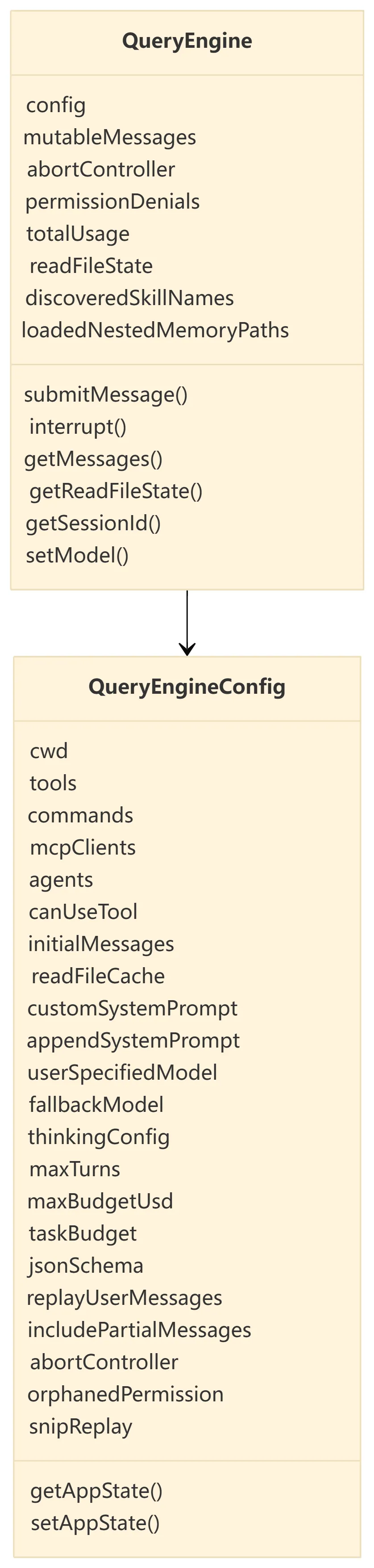
3.2 QueryEngine 持有的长期状态
|
|
|
|
|---|---|---|
mutableMessages |
submitMessage() |
|
abortController |
|
|
permissionDenials |
|
|
totalUsage |
|
|
readFileState |
ask() finally 写回 |
|
discoveredSkillNames |
|
was_discovered |
loadedNestedMemoryPaths |
|
|
这些状态说明 QueryEngine 不是无状态函数,而是一个会话对象。它每次处理一条用户消息时,都会基于已有状态构建本轮请求。
4. 运行时流程视图
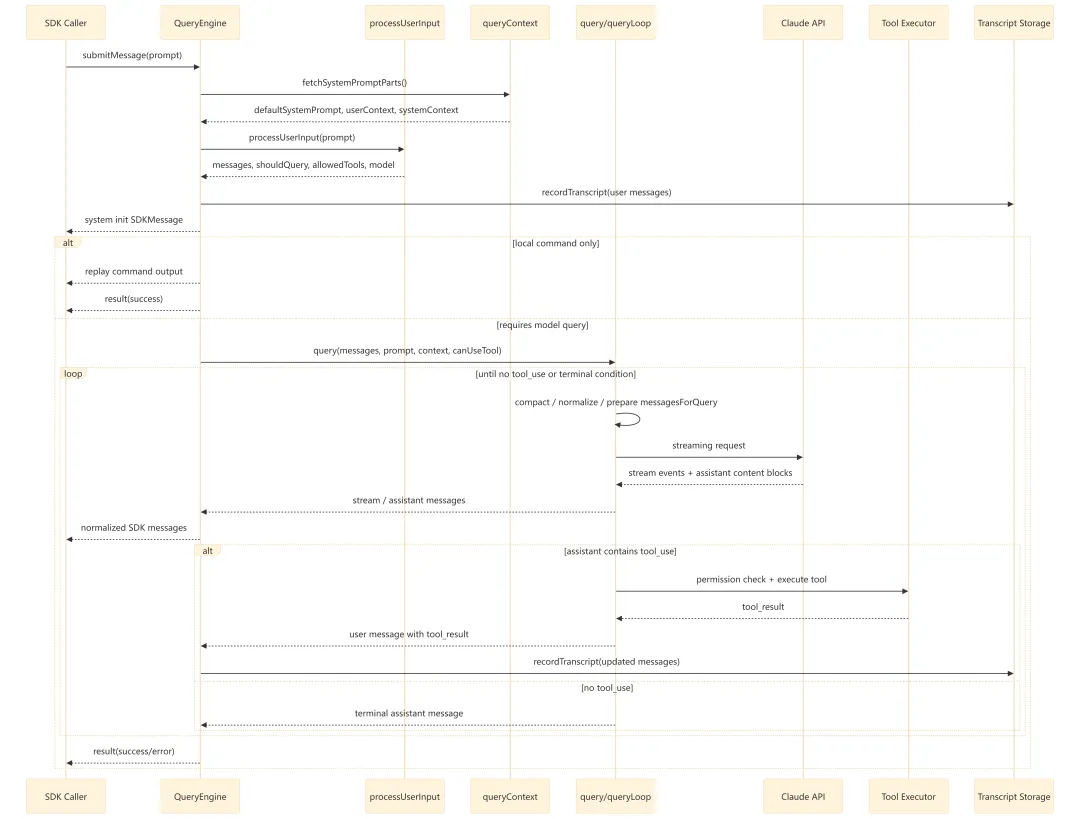
4.1 一轮 submitMessage() 的主流程

4.2 时序图
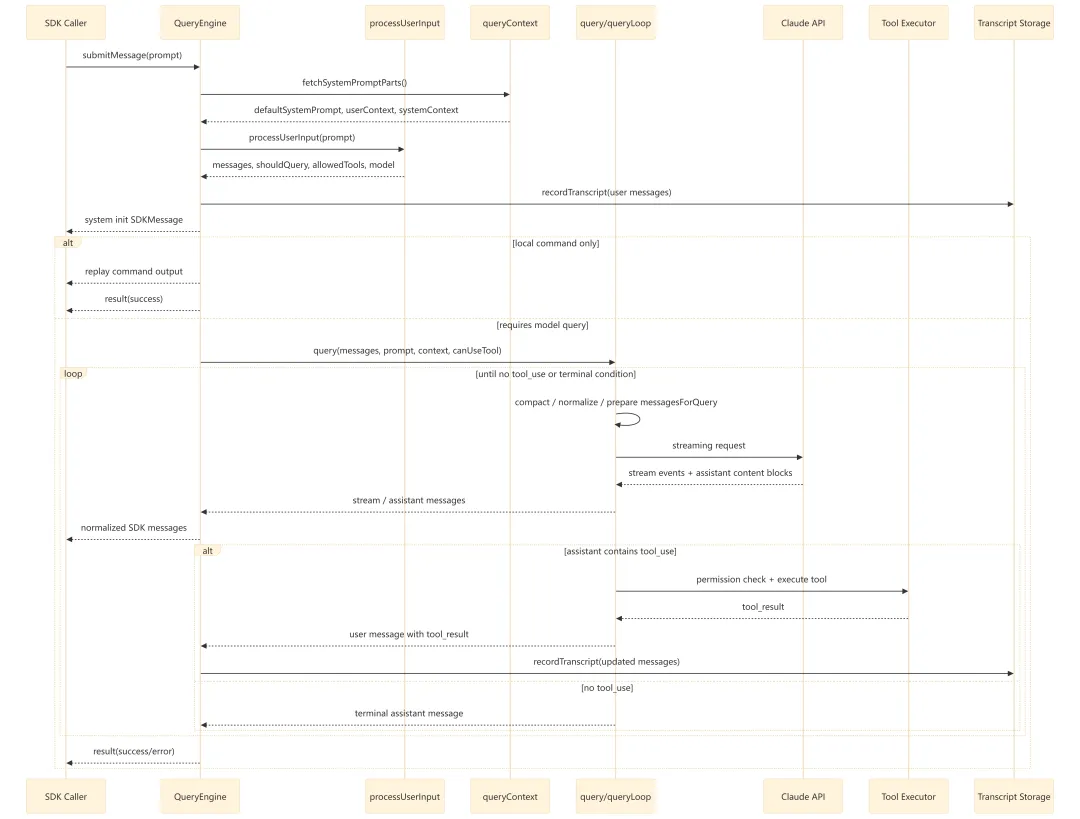
5. query.ts 循环执行视图
介绍文档里提到的关键点是:query() 本身只是生成器入口,真正的持续推进发生在 queryLoop() 的 while (true) 中。
5.1 query() 与 queryLoop() 的关系

query() 的职责很薄,主要是包住 queryLoop(),并在循环正常结束后通知被消费的命令完成。异常或 generator 被 .return() 关闭时,不会走完成通知,从而保留“已开始但未完成”的语义。
5.2 queryLoop() 单次迭代逻辑
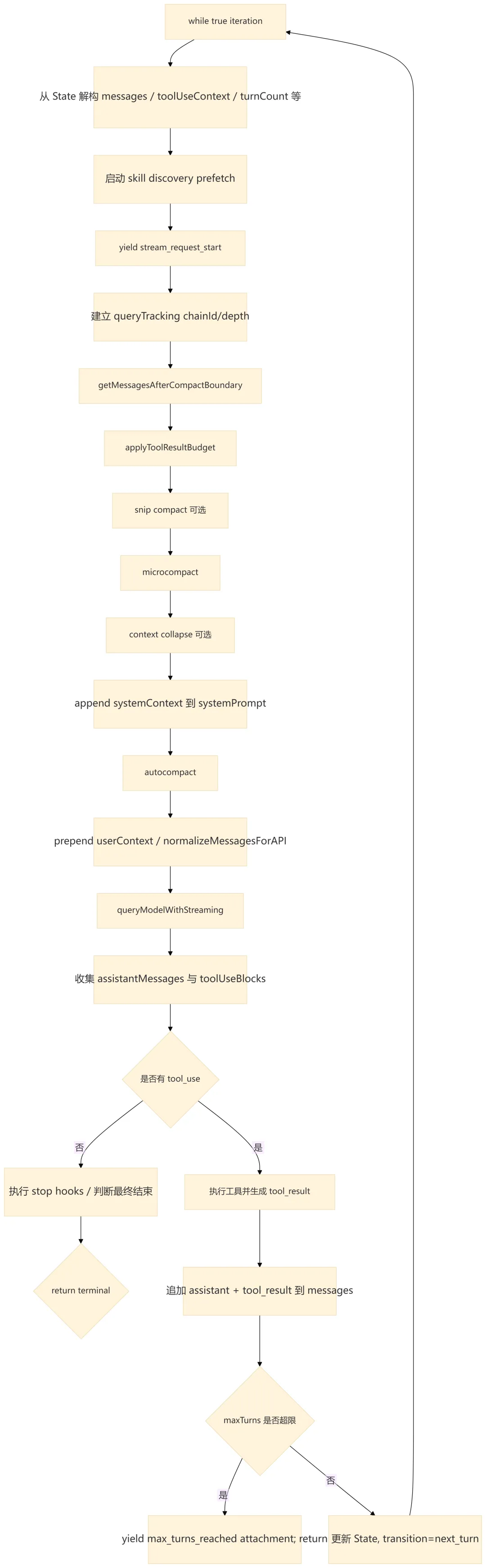
5.3 循环状态对象
queryLoop() 内部维护一个跨迭代 State,用不可变参数 + 可变状态的组合降低复杂度。

设计要点:
-
messages是每轮传给模型的基础,但进入模型前会经过 compact boundary、tool result budget、microcompact、context collapse、autocompact 等多层整理。 -
toolUseContext会在迭代中加入queryTracking,用于区分当前 loop chain 的深度。 -
turnCount用于maxTurns控制,工具回流后会进入下一 turn。 -
transition记录上一轮继续的原因,便于测试和诊断恢复路径。
6. 消息与数据流视图
6.1 消息闭环
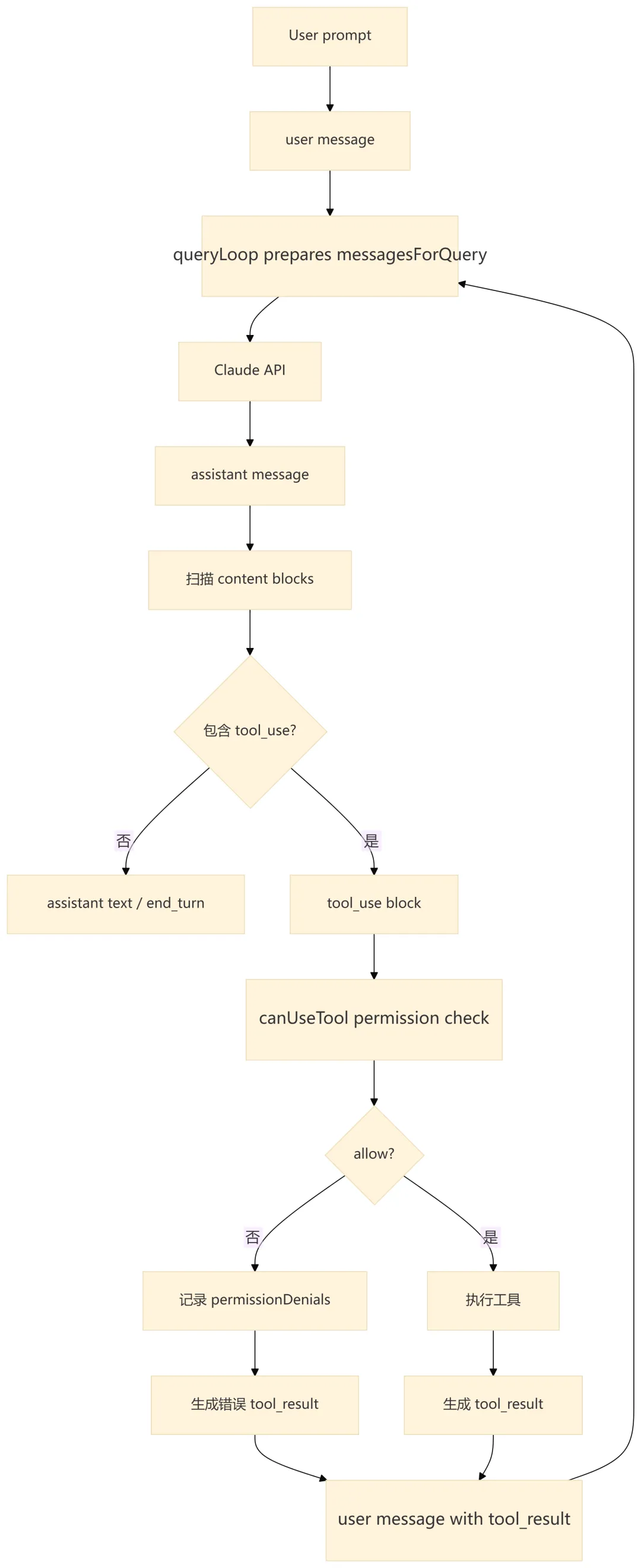
6.2 内部消息到 SDK 消息的转换
query() 产生的是内部 Message、StreamEvent、RequestStartEvent、AttachmentMessage 等。QueryEngine.submitMessage() 会按类型处理,再转换为 SDK 语义:
|
|
QueryEngine
|
|
|---|---|---|
assistant |
mutableMessages,归一化输出 |
|
user |
tool_result 回流,追加并输出 |
|
stream_event |
|
|
progress |
|
|
attachment |
|
|
system compact_boundary |
|
|
system api_error |
api_retry |
|
tool_use_summary |
|
|
tombstone |
|
|
7. 上下文构建与整形视图
7.1 QueryEngine 层的上下文准备
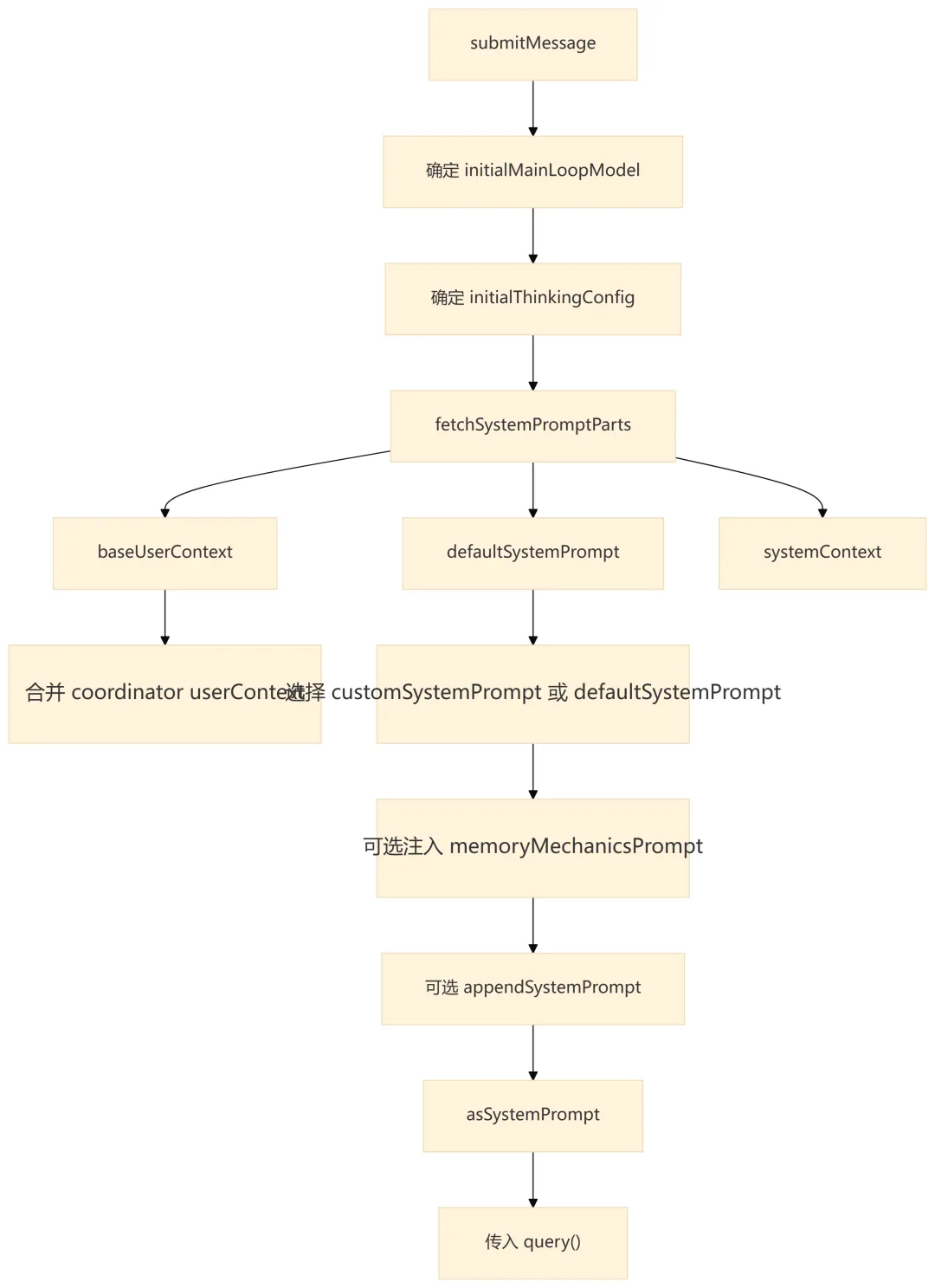
QueryEngine 这一层的上下文关注“来源”:
-
defaultSystemPrompt:默认系统规则。 -
customSystemPrompt:SDK 调用方显式覆盖系统提示词时使用。 -
appendSystemPrompt:在基础提示词后追加策略。 -
userContext:用户侧上下文,例如环境、工作区信息、coordinator 信息。 -
systemContext:系统侧上下文,在queryLoop()内被追加到 system prompt。
7.2 queryLoop() 层的上下文整形
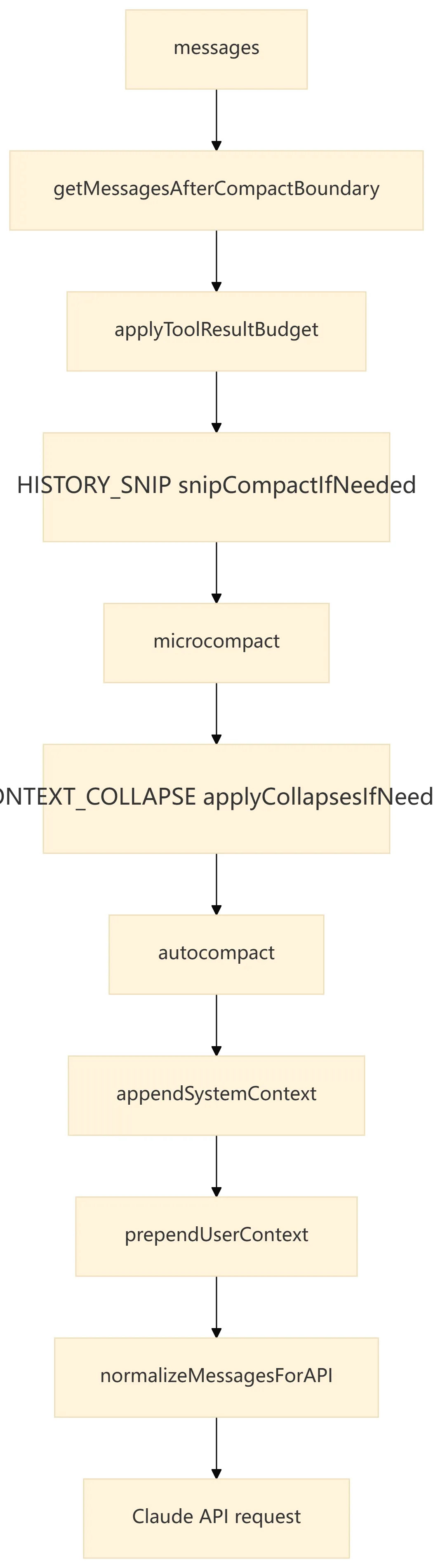
这说明 Claude Code 不会把内存里的所有消息原样丢给模型。每次 API 调用前都会构造一个“本轮可见视图”,它可能已经丢弃 compact boundary 之前的消息、替换超长工具结果、应用 snip/microcompact/autocompact 或 context collapse。
8. 工具调用逻辑视图
8.1 为什么不只看 stop_reason
query.ts 明确认为 stop_reason === 'tool_use' 不可靠,因此本地会直接扫描 assistant content block 中的 tool_use。这比依赖模型响应的 stop reason 更具体,因为真正决定是否继续循环的是:是否存在尚未回流的工具调用。
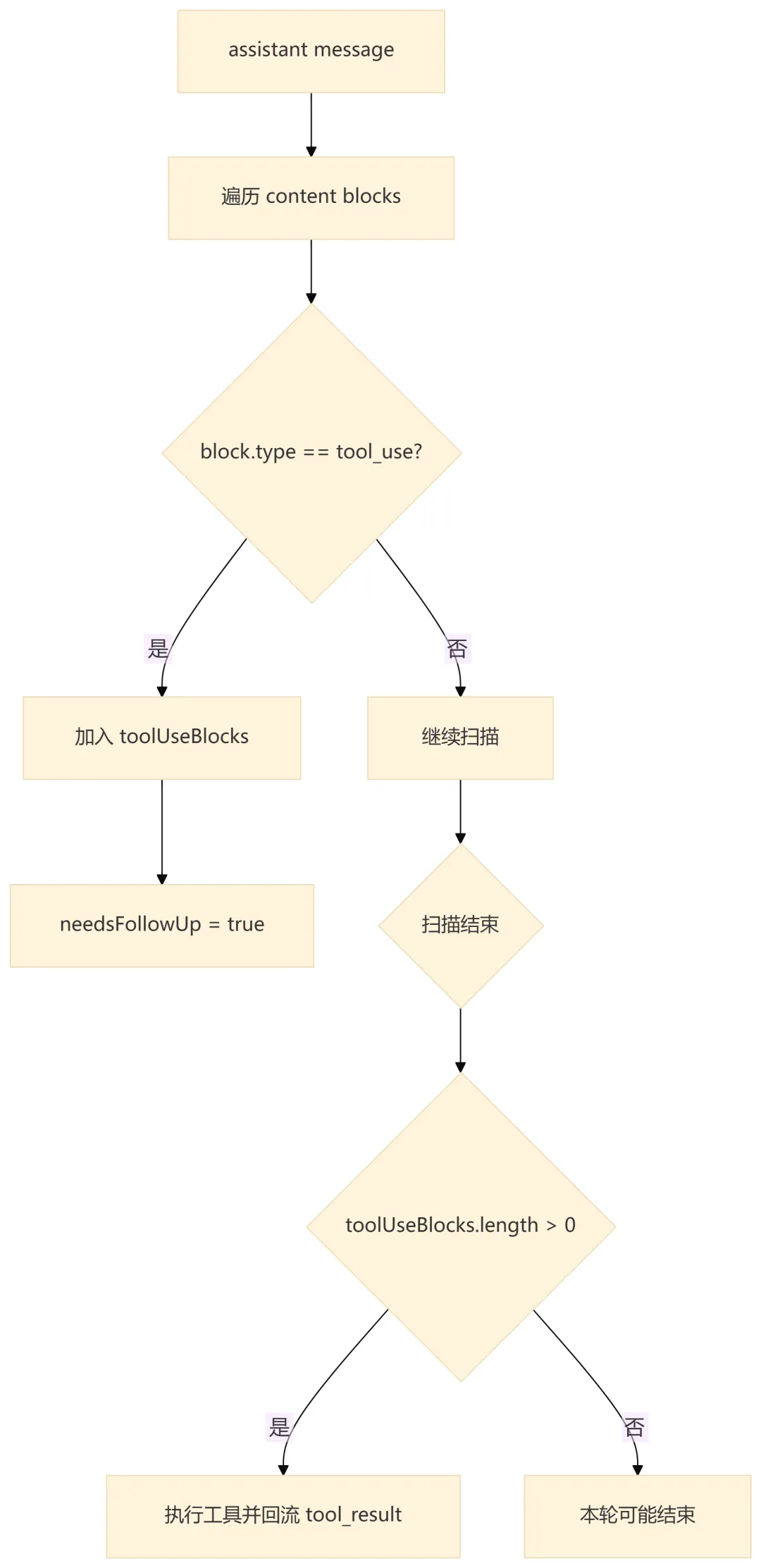
8.2 权限包装逻辑
QueryEngine 不直接决定工具权限,而是包装外部传入的 canUseTool。包装层只增加 SDK 需要的审计信息:
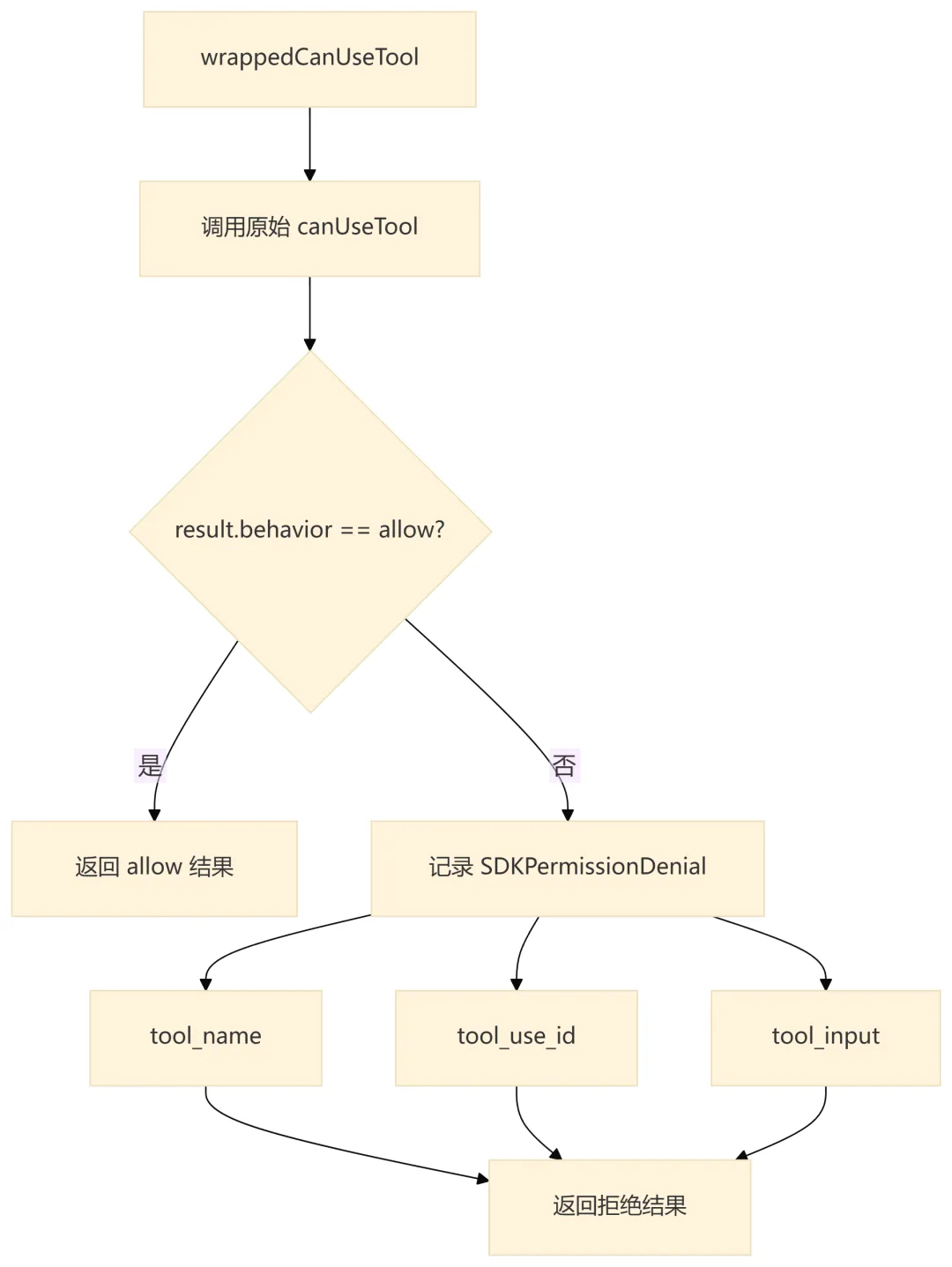
这个设计让权限策略与审计记录解耦:权限系统仍然由调用方或 AppState 决定,QueryEngine 只负责把拒绝事件纳入会话结果。
9. 状态机视图
9.1 QueryEngine 会话生命周期
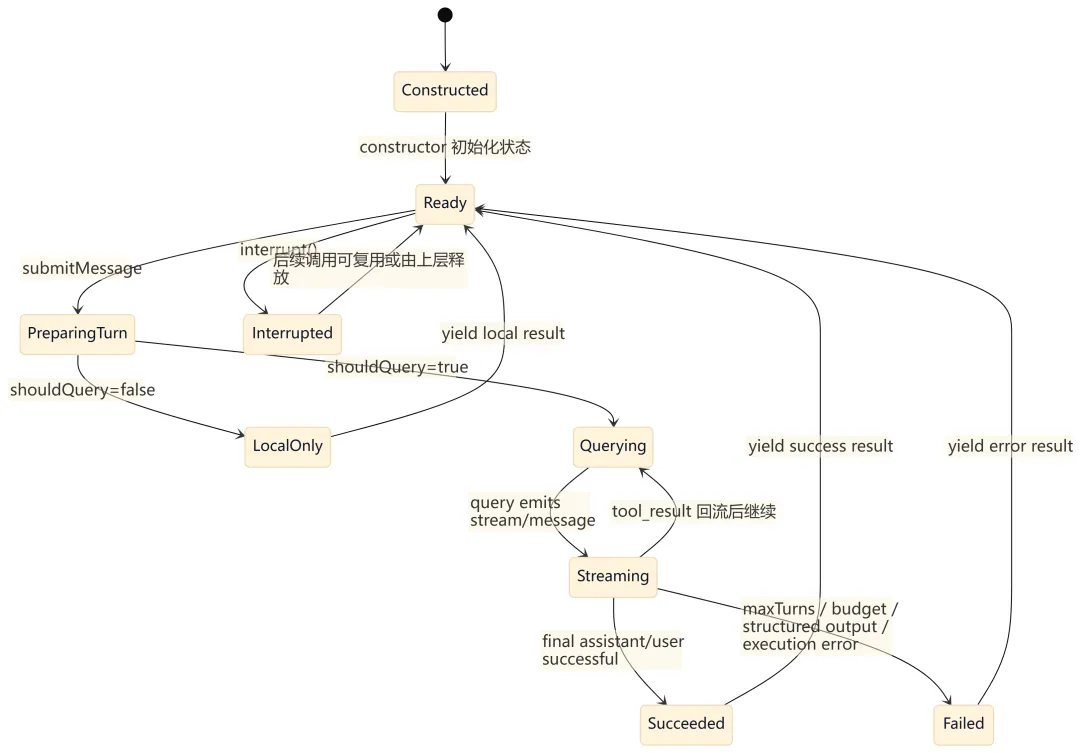
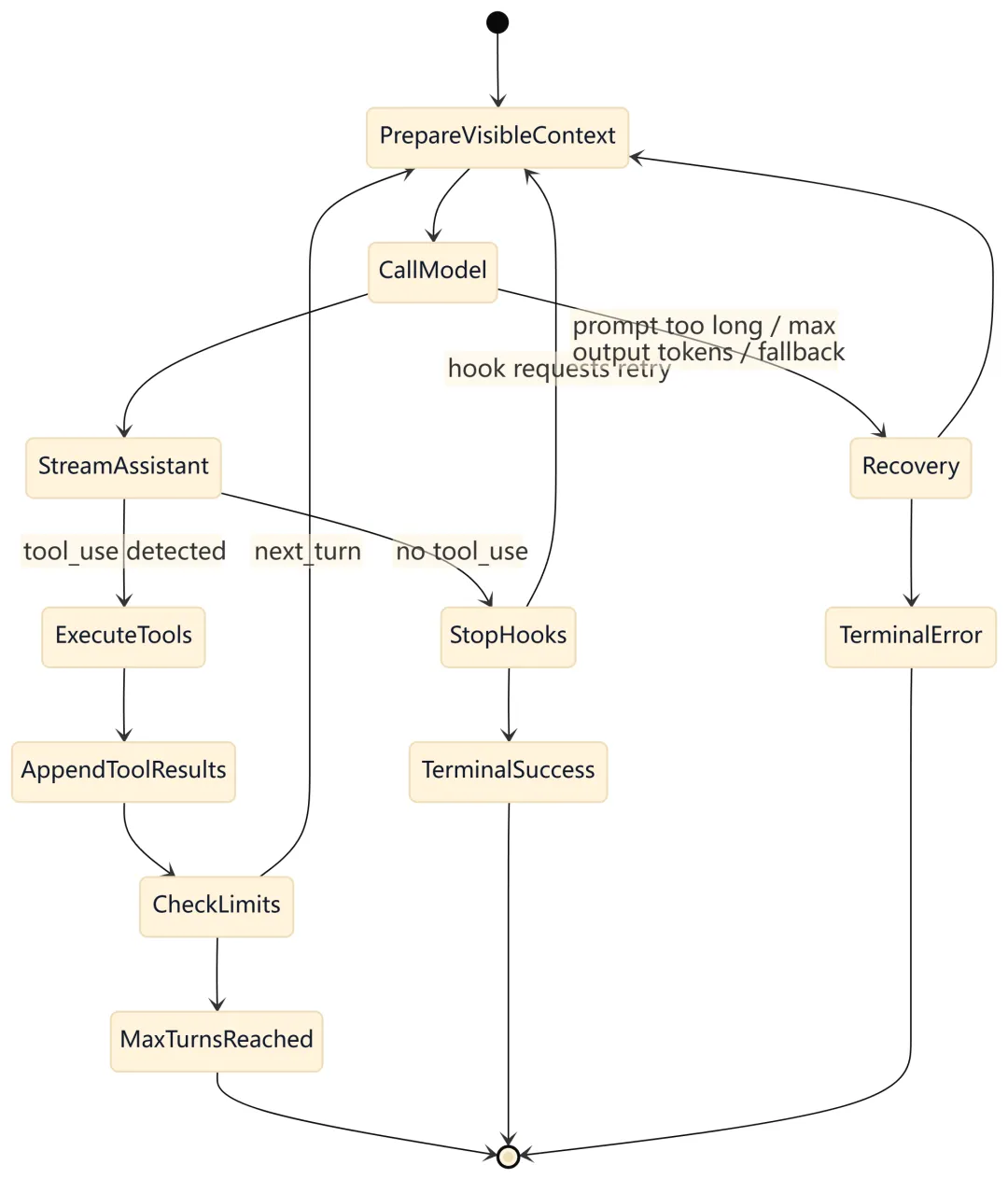
9.2 queryLoop() 迭代状态
10. 持久化与恢复视图
QueryEngine 很重视 transcript 写入时机。它会在用户消息被接受后、进入模型请求前提前写 transcript。这样即使进程在 API 返回前被杀掉,--resume 仍然能找到这次用户输入,而不是得到“没有对话”的状态。
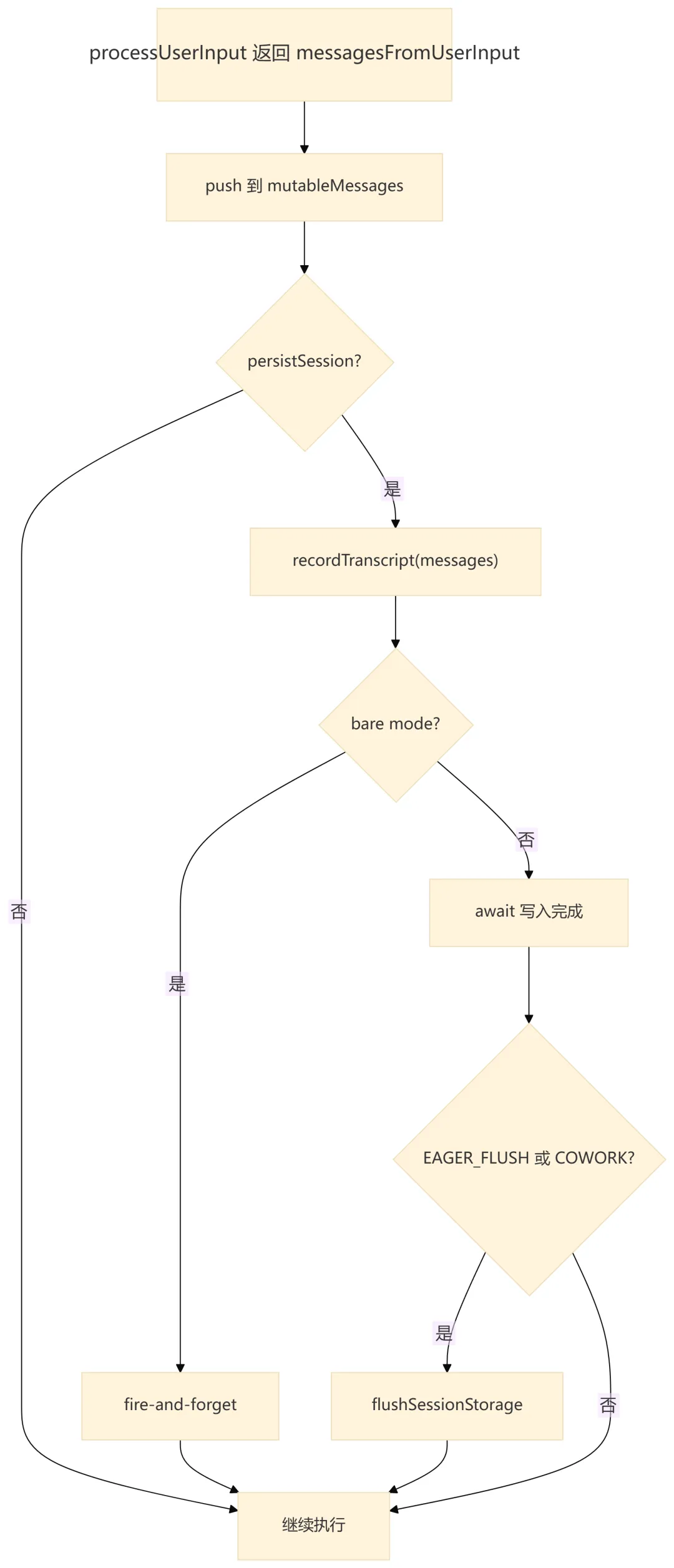
后续在 query() 输出 assistant、user、compact boundary、progress、attachment 时,QueryEngine 还会继续维护 transcript。对 assistant 消息,它倾向于 fire-and-forget,避免阻塞流式输出;对需要保证顺序和恢复正确性的消息,则会 await。
11. 退出条件与错误出口
11.1 QueryEngine 层的结果封装
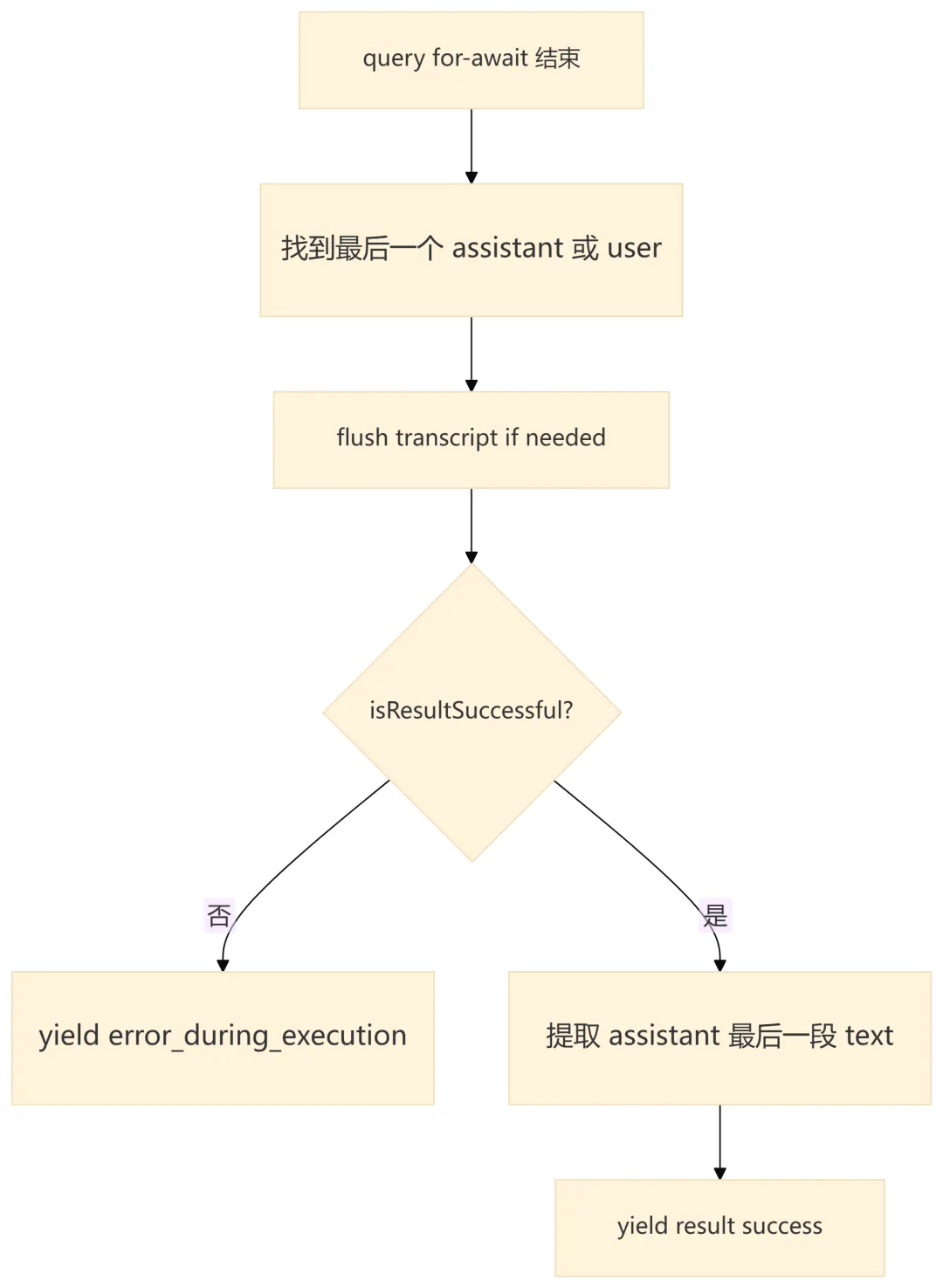
11.2 主要错误出口
|
|
|
|
|
|---|---|---|---|
|
|
shouldQuery=false |
success |
|
|
|
query.ts
max_turns_reached attachment |
error_max_turns |
|
|
|
getTotalCost() >= maxBudgetUsd |
error_max_budget_usd |
|
|
|
jsonSchema
|
error_max_structured_output_retries |
|
|
|
|
error_during_execution |
|
|
|
system
api_error |
api_retry
|
|
12. 并发与顺序性的设计
单个 queryLoop() 对工具调用采取偏顺序、偏保守的推进方式。即使模型一次给出多个 tool_use,系统也会围绕“assistant tool_use -> 本地 tool_result -> 下一轮 messages”的闭环推进。这样做有几个工程收益:
-
前一个工具结果可以影响下一步模型判断,避免过早并发造成无效工作。 -
消息链与 transcript 更容易保持一致,便于恢复。 -
UI 可以按顺序展示模型决策和工具结果,用户更容易理解。 -
权限拒绝、工具失败和中断更容易定位到具体 tool_use_id。
Claude Code 并不是没有并发,而是把并发放在更高层:例如 AgentTool 或团队/多 Agent 能力可以启动多个独立 loop。单个 loop 保持可推理,多 Agent 层负责并行。
13. 设计权衡
13.1 会话控制器与执行循环拆分
优点:
-
QueryEngine可以专注 SDK/会话语义,包括 transcript、usage、权限审计、消息归一化。 -
queryLoop()可以专注模型和工具之间的执行闭环。 -
测试边界更清晰:状态管理与循环推进可以分开验证。
代价:
-
一条用户请求会跨多个抽象层,初学者容易误以为 QueryEngine.ts就是全部 Agent Loop。 -
消息在内部格式、API 格式、SDK 格式之间多次转换,需要严格维护配对关系。
13.2 显式 tool_result 回流
优点:
-
模型不会“自动知道”工具结果,所有结果都在本地显式写回 messages。 -
transcript、resume、debug 都能看到完整因果链。 -
可以在中断或异常时补齐缺失的 tool_result,避免 API 看到不成对的工具消息。
代价:
-
工具执行、错误恢复和消息修复逻辑必须非常谨慎,尤其是流式 fallback 或 abort 场景。
13.3 每轮主动整理上下文
优点:
-
长会话可持续运行,不会无限膨胀。 -
tool result budget、microcompact、autocompact、context collapse 可以分别处理不同类型的上下文压力。
代价:
-
“内存中的完整历史”和“发给模型的可见视图”并不总是一致,调试时需要区分这两个概念。
14. 软件视图总结
从软件设计角度看,Claude Code 的 Agent Loop 成熟之处不在于 while (true) 本身,而在于它围绕这个循环建立了完整的工程外壳:上下文构建、工具闭环、权限审计、流式输出、持久化恢复、token/成本记账和多种压缩策略。QueryEngine 让一轮请求具备“产品会话”的完整语义,queryLoop() 则让模型和工具能在一个可控、可恢复、可观测的闭环中持续协作。
Claude Code Agent Loop 详细设计文档
本文基于
claude-code/src/QueryEngine.ts与Claude-code-open-explain/02-agentic-loop/README.md,从软件架构视图、运行时流程视图、状态视图和关键逻辑视图分析 Claude Code 的 Agent Loop 设计。
1. 设计定位
Claude Code 的 Agent Loop 不是一个简单的 while 循环,也不是单个类完成所有事情。它采用了两层职责拆分:
-
QueryEngine.ts:会话级控制器,负责一轮请求前后的状态管理、参数组装、上下文准备、事件归一化、持久化与结果封装。 -
query.ts:请求级执行引擎,负责模型调用、工具执行、继续或终止判断、上下文压缩、错误恢复等真正的循环推进。
可以把 QueryEngine 理解成“会话控制面”,把 query() / queryLoop() 理解成“执行数据面”。前者决定本轮怎么开始、如何记账、如何把内部事件转成 SDK 消息;后者决定本轮如何一跳一跳地推进,直到模型不再需要工具或触发退出条件。
2. 总体架构视图
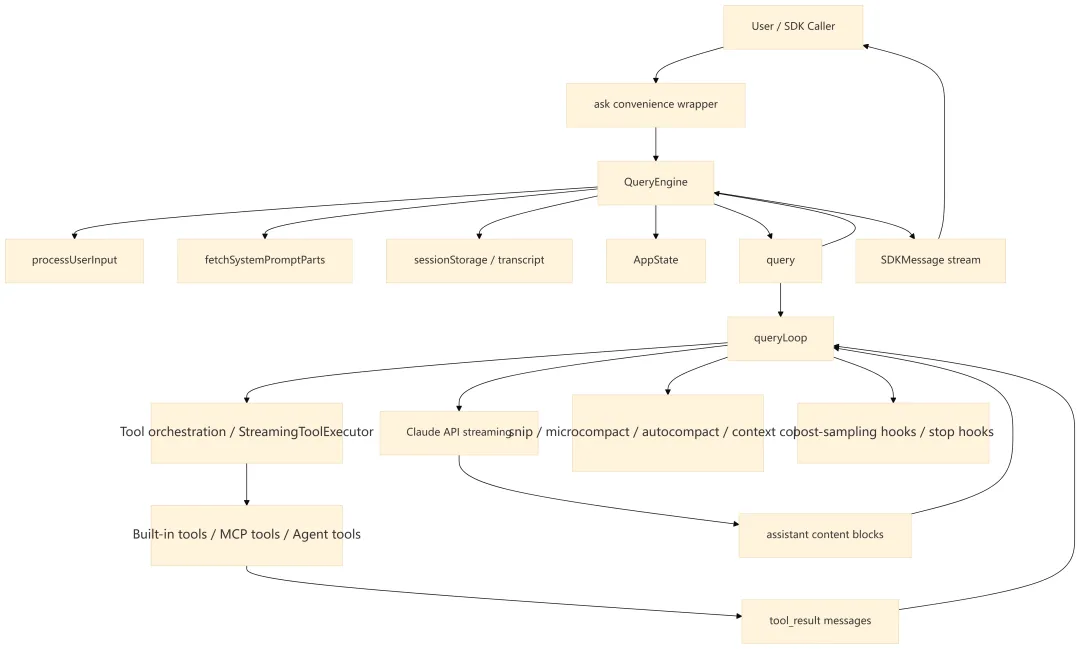
2.1 分层说明
|
|
|
|
|---|---|---|
|
|
ask()
QueryEngine.submitMessage() |
AsyncGenerator,支持流式输出、中断、SDK 结果封装 |
|
|
QueryEngine
submitMessage() |
|
|
|
processUserInput() |
|
|
|
fetchSystemPromptParts()
asSystemPrompt() |
|
|
|
query()
queryLoop() |
|
|
|
runTools()
StreamingToolExecutor |
tool_use、执行工具、生成 tool_result |
|
|
recordTranscript()
flushSessionStorage()、usage tracker |
|
|
|
normalizeMessage()
|
|
3. 关键对象视图
3.1 QueryEngineConfig
QueryEngineConfig 是会话控制器的依赖注入边界。它把环境、工具、命令、模型配置、状态读写函数、权限函数以及 SDK 选项集中传入。
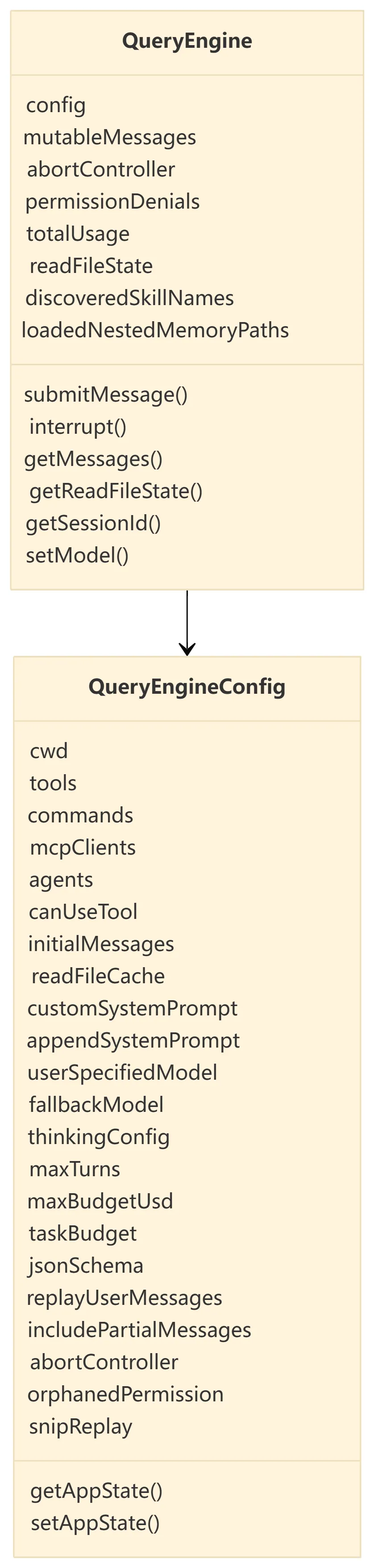
3.2 QueryEngine 持有的长期状态
|
|
|
|
|---|---|---|
mutableMessages |
submitMessage() |
|
abortController |
|
|
permissionDenials |
|
|
totalUsage |
|
|
readFileState |
ask() finally 写回 |
|
discoveredSkillNames |
|
was_discovered |
loadedNestedMemoryPaths |
|
|
这些状态说明 QueryEngine 不是无状态函数,而是一个会话对象。它每次处理一条用户消息时,都会基于已有状态构建本轮请求。
4. 运行时流程视图
4.1 一轮 submitMessage() 的主流程

4.2 时序图
5. query.ts 循环执行视图
介绍文档里提到的关键点是:query() 本身只是生成器入口,真正的持续推进发生在 queryLoop() 的 while (true) 中。
5.1 query() 与 queryLoop() 的关系

query() 的职责很薄,主要是包住 queryLoop(),并在循环正常结束后通知被消费的命令完成。异常或 generator 被 .return() 关闭时,不会走完成通知,从而保留“已开始但未完成”的语义。
5.2 queryLoop() 单次迭代逻辑
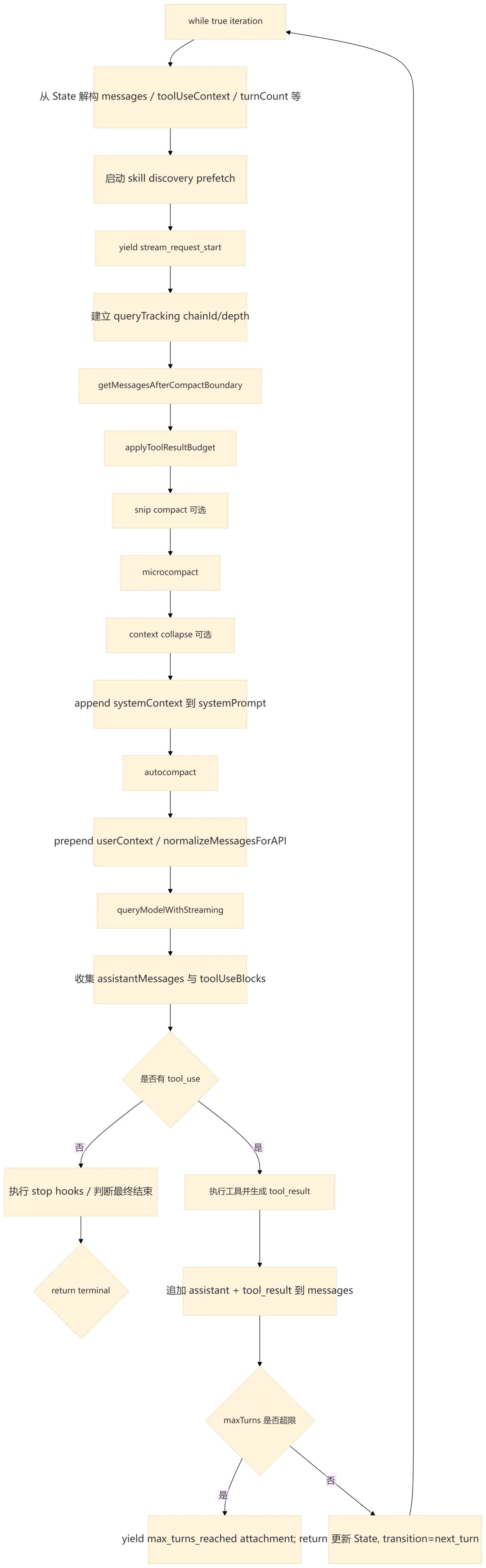
5.3 循环状态对象
queryLoop() 内部维护一个跨迭代 State,用不可变参数 + 可变状态的组合降低复杂度。

设计要点:
-
messages是每轮传给模型的基础,但进入模型前会经过 compact boundary、tool result budget、microcompact、context collapse、autocompact 等多层整理。 -
toolUseContext会在迭代中加入queryTracking,用于区分当前 loop chain 的深度。 -
turnCount用于maxTurns控制,工具回流后会进入下一 turn。 -
transition记录上一轮继续的原因,便于测试和诊断恢复路径。
6. 消息与数据流视图
6.1 消息闭环
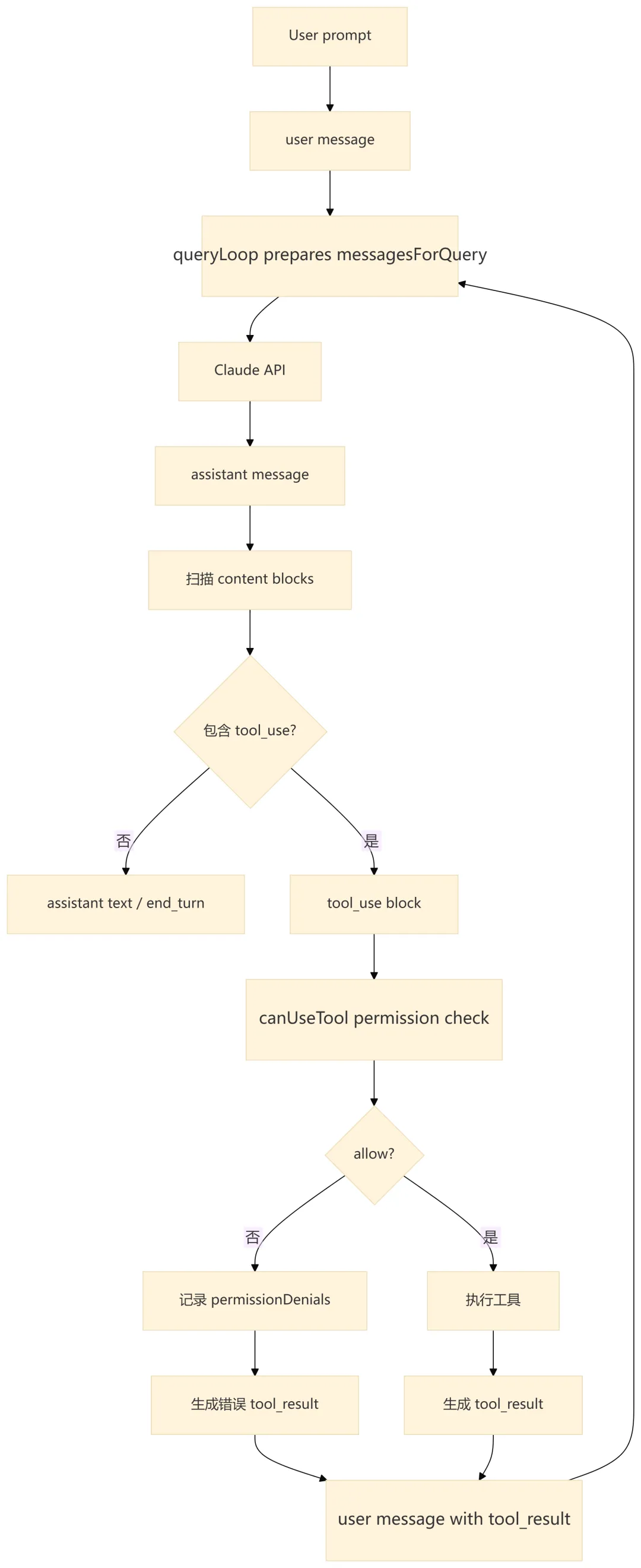
6.2 内部消息到 SDK 消息的转换
query() 产生的是内部 Message、StreamEvent、RequestStartEvent、AttachmentMessage 等。QueryEngine.submitMessage() 会按类型处理,再转换为 SDK 语义:
|
|
QueryEngine
|
|
|---|---|---|
assistant |
mutableMessages,归一化输出 |
|
user |
tool_result 回流,追加并输出 |
|
stream_event |
|
|
progress |
|
|
attachment |
|
|
system compact_boundary |
|
|
system api_error |
api_retry |
|
tool_use_summary |
|
|
tombstone |
|
|
7. 上下文构建与整形视图
7.1 QueryEngine 层的上下文准备
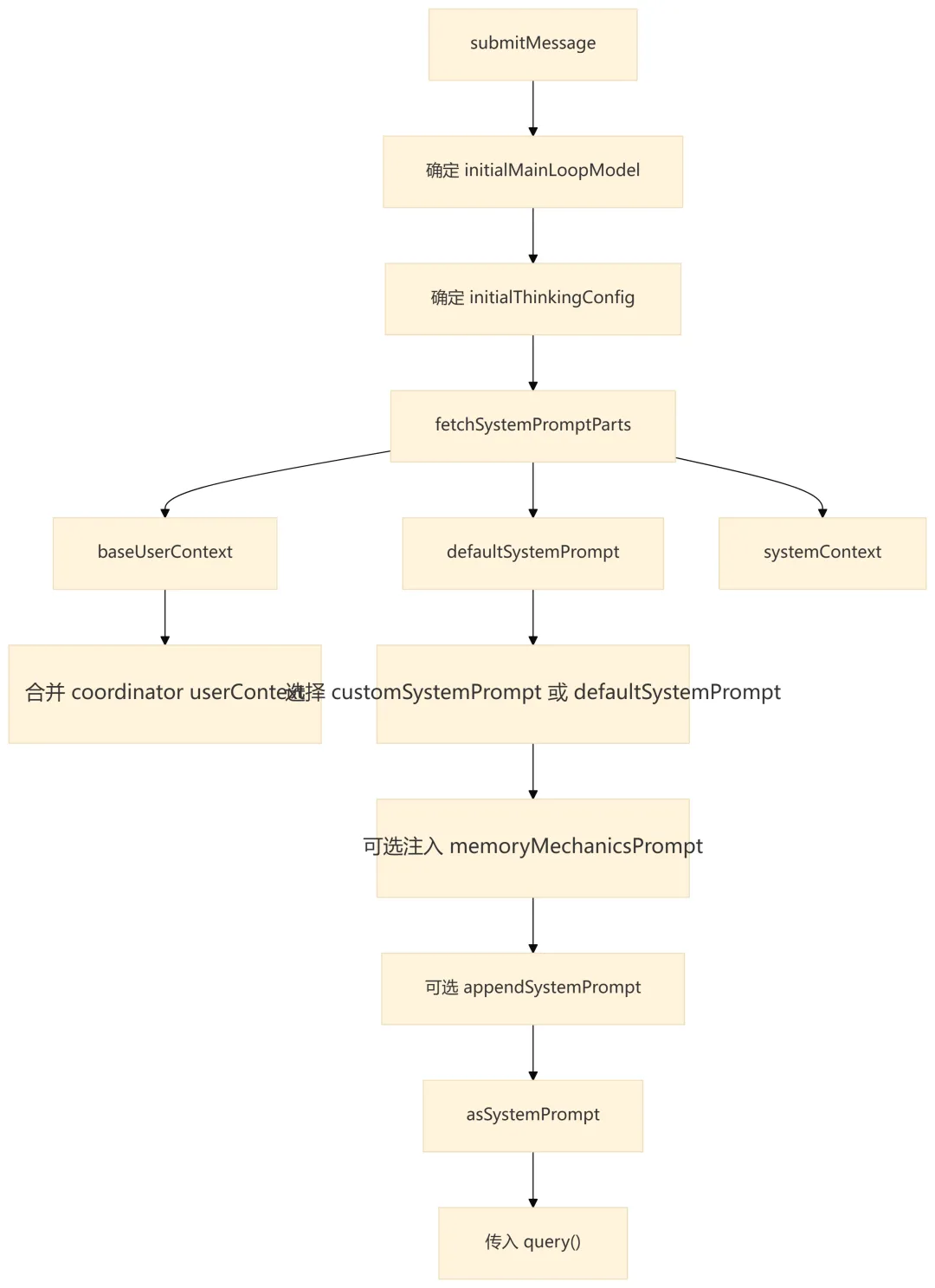
QueryEngine 这一层的上下文关注“来源”:
-
defaultSystemPrompt:默认系统规则。 -
customSystemPrompt:SDK 调用方显式覆盖系统提示词时使用。 -
appendSystemPrompt:在基础提示词后追加策略。 -
userContext:用户侧上下文,例如环境、工作区信息、coordinator 信息。 -
systemContext:系统侧上下文,在queryLoop()内被追加到 system prompt。
7.2 queryLoop() 层的上下文整形
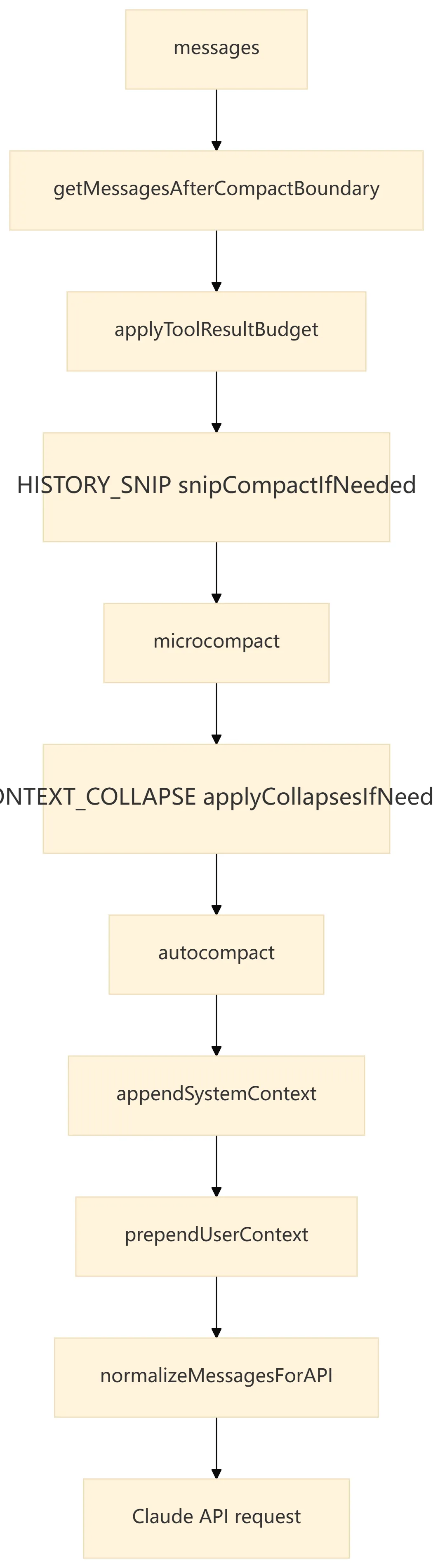
这说明 Claude Code 不会把内存里的所有消息原样丢给模型。每次 API 调用前都会构造一个“本轮可见视图”,它可能已经丢弃 compact boundary 之前的消息、替换超长工具结果、应用 snip/microcompact/autocompact 或 context collapse。
8. 工具调用逻辑视图
8.1 为什么不只看 stop_reason
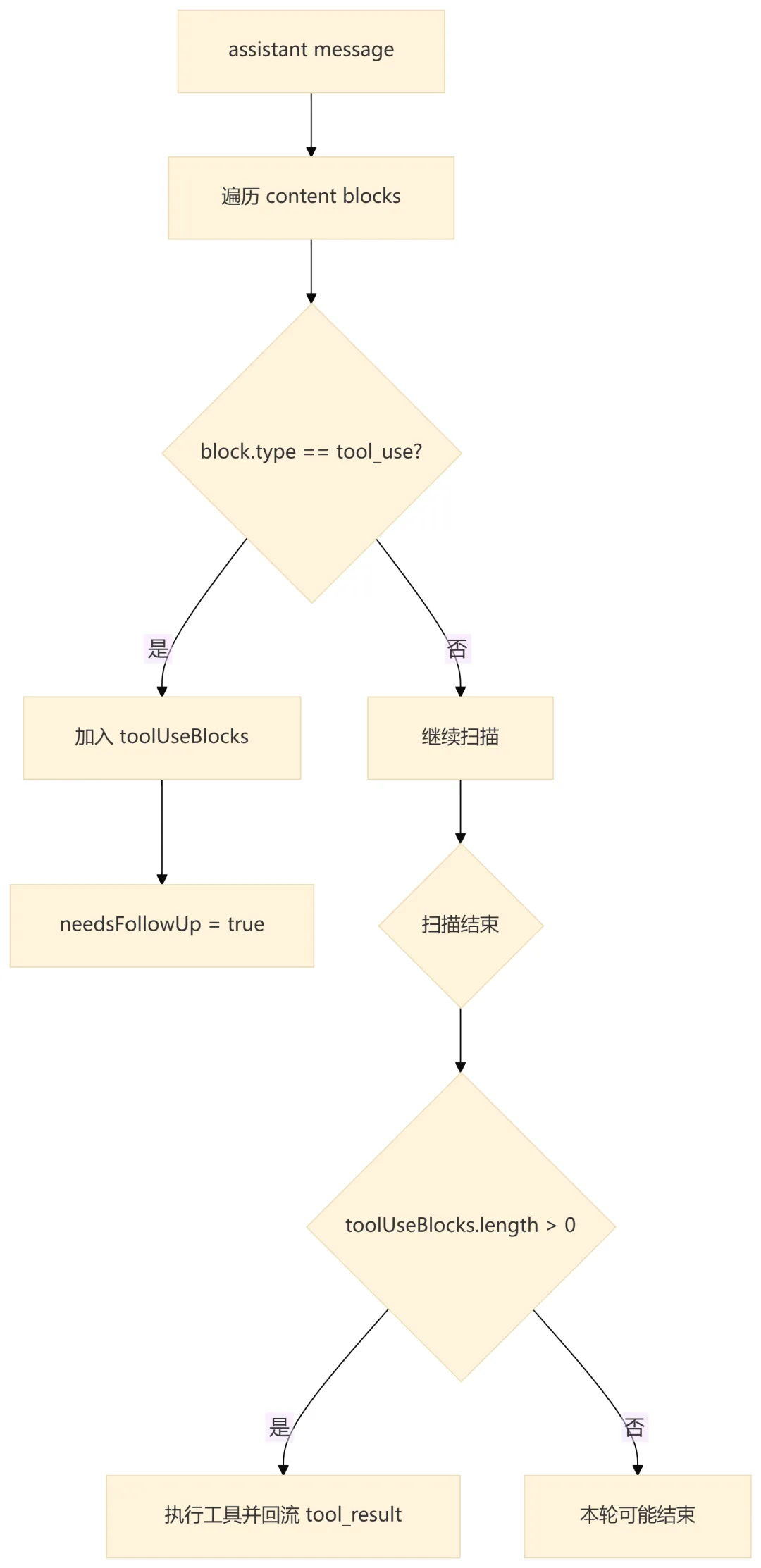
query.ts 明确认为 stop_reason === 'tool_use' 不可靠,因此本地会直接扫描 assistant content block 中的 tool_use。这比依赖模型响应的 stop reason 更具体,因为真正决定是否继续循环的是:是否存在尚未回流的工具调用。
8.2 权限包装逻辑
QueryEngine 不直接决定工具权限,而是包装外部传入的 canUseTool。包装层只增加 SDK 需要的审计信息:
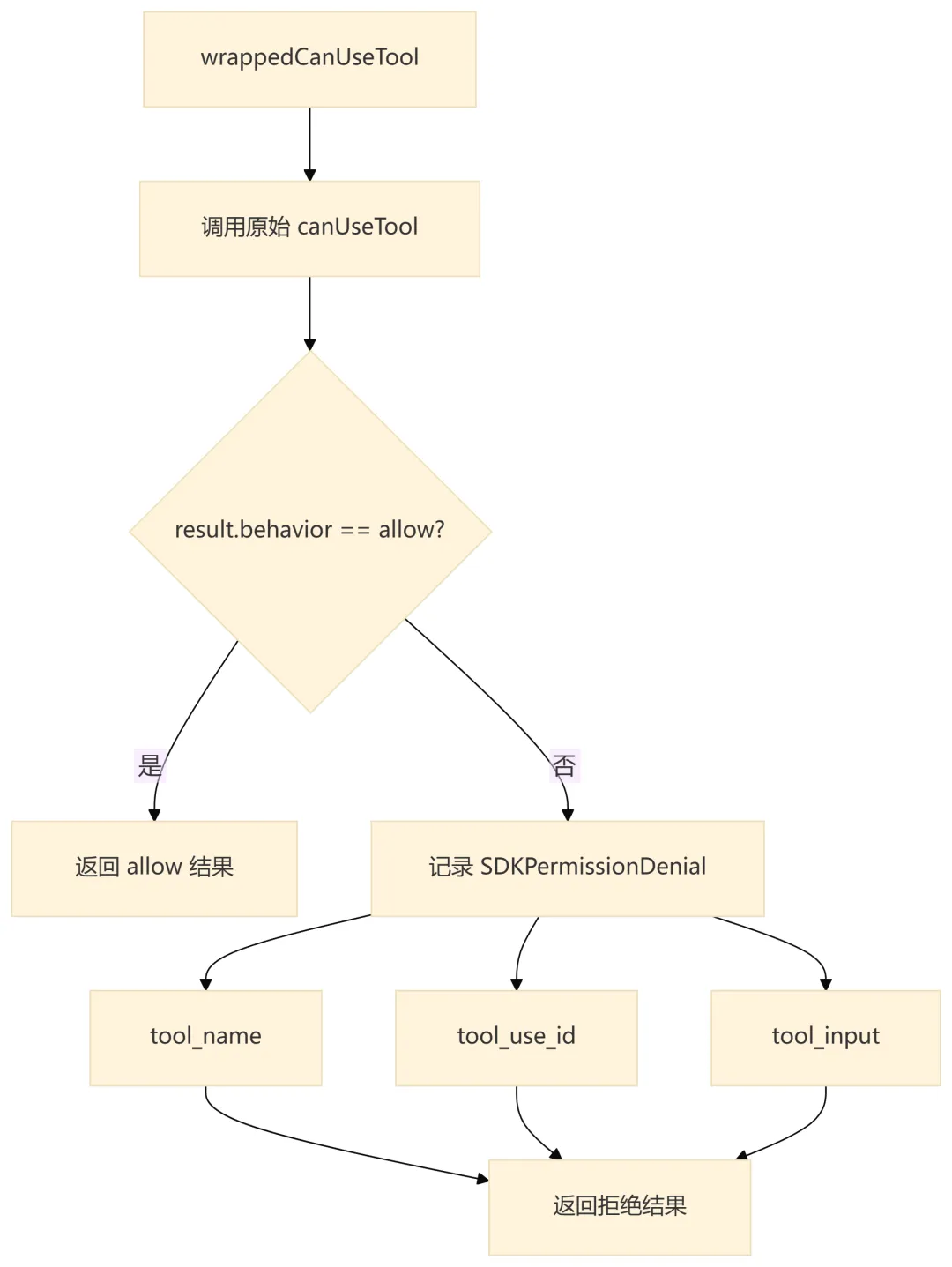
这个设计让权限策略与审计记录解耦:权限系统仍然由调用方或 AppState 决定,QueryEngine 只负责把拒绝事件纳入会话结果。
9. 状态机视图
9.1 QueryEngine 会话生命周期
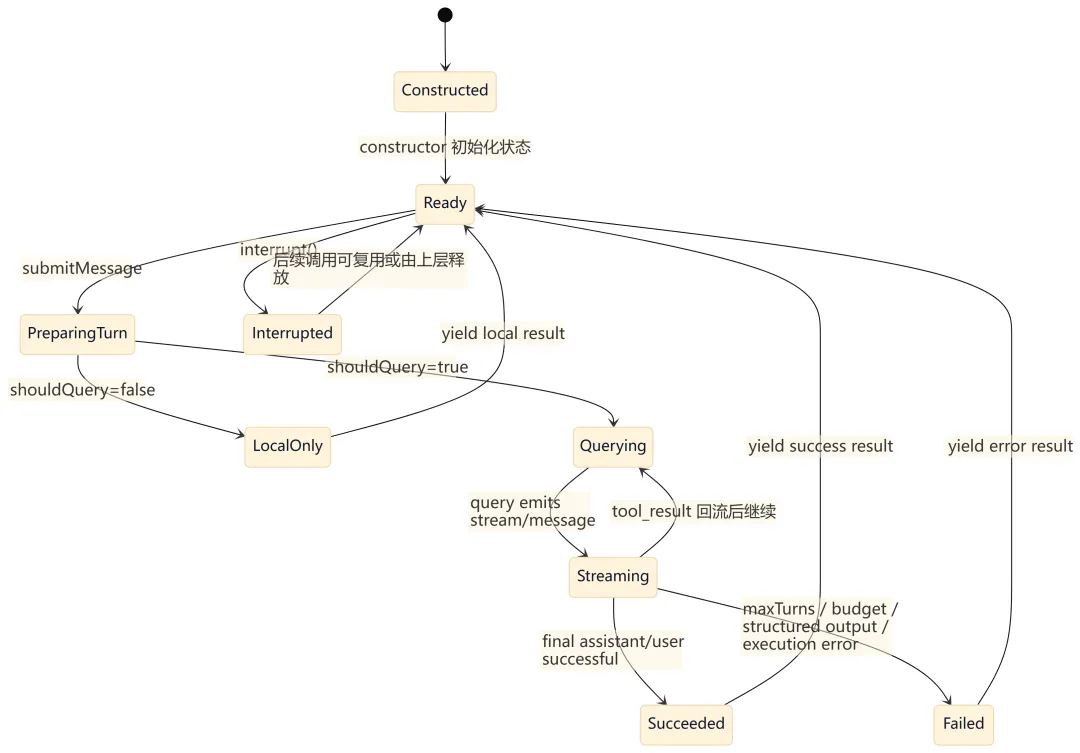
9.2 queryLoop() 迭代状态
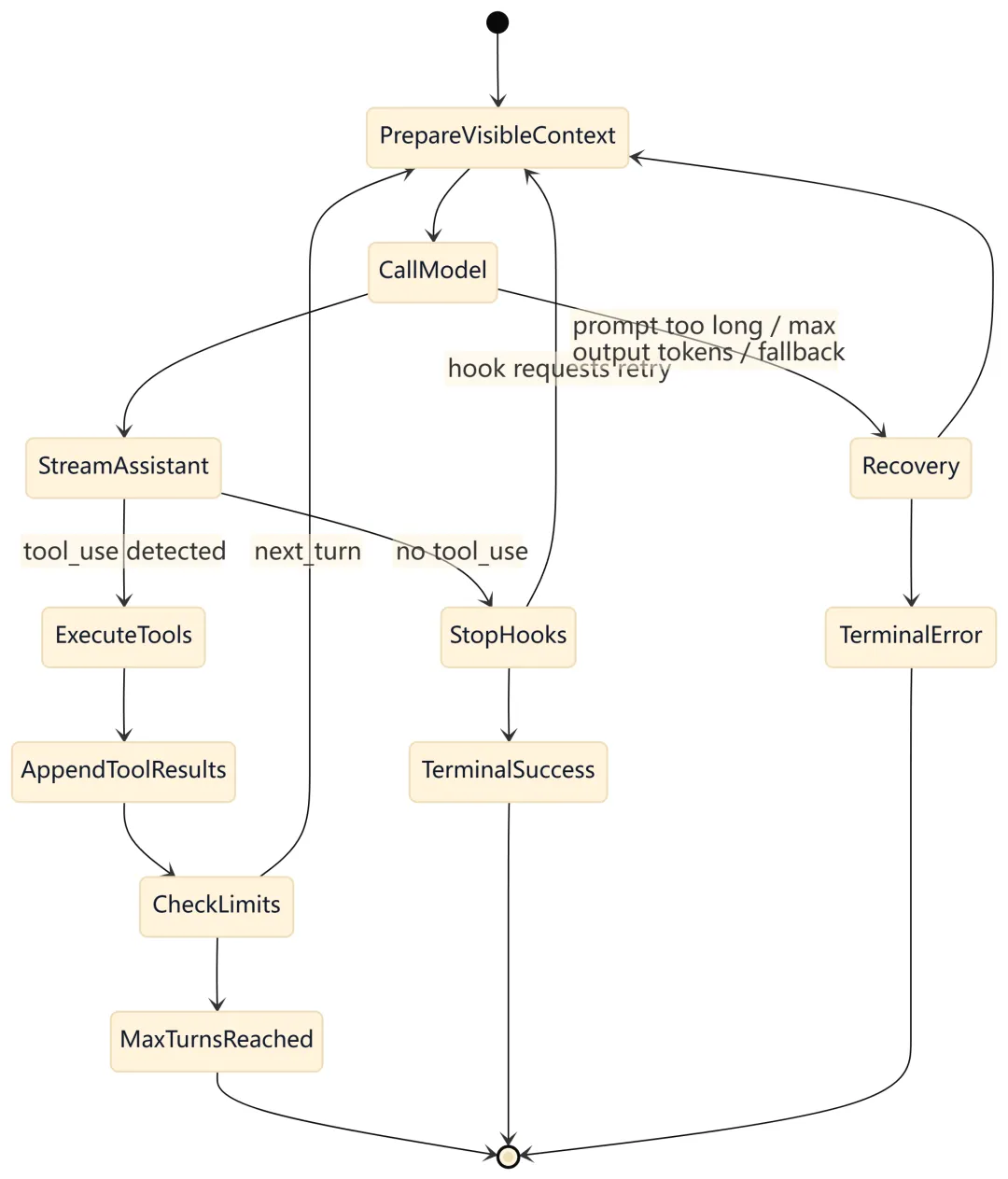
10. 持久化与恢复视图
QueryEngine 很重视 transcript 写入时机。它会在用户消息被接受后、进入模型请求前提前写 transcript。这样即使进程在 API 返回前被杀掉,--resume 仍然能找到这次用户输入,而不是得到“没有对话”的状态。
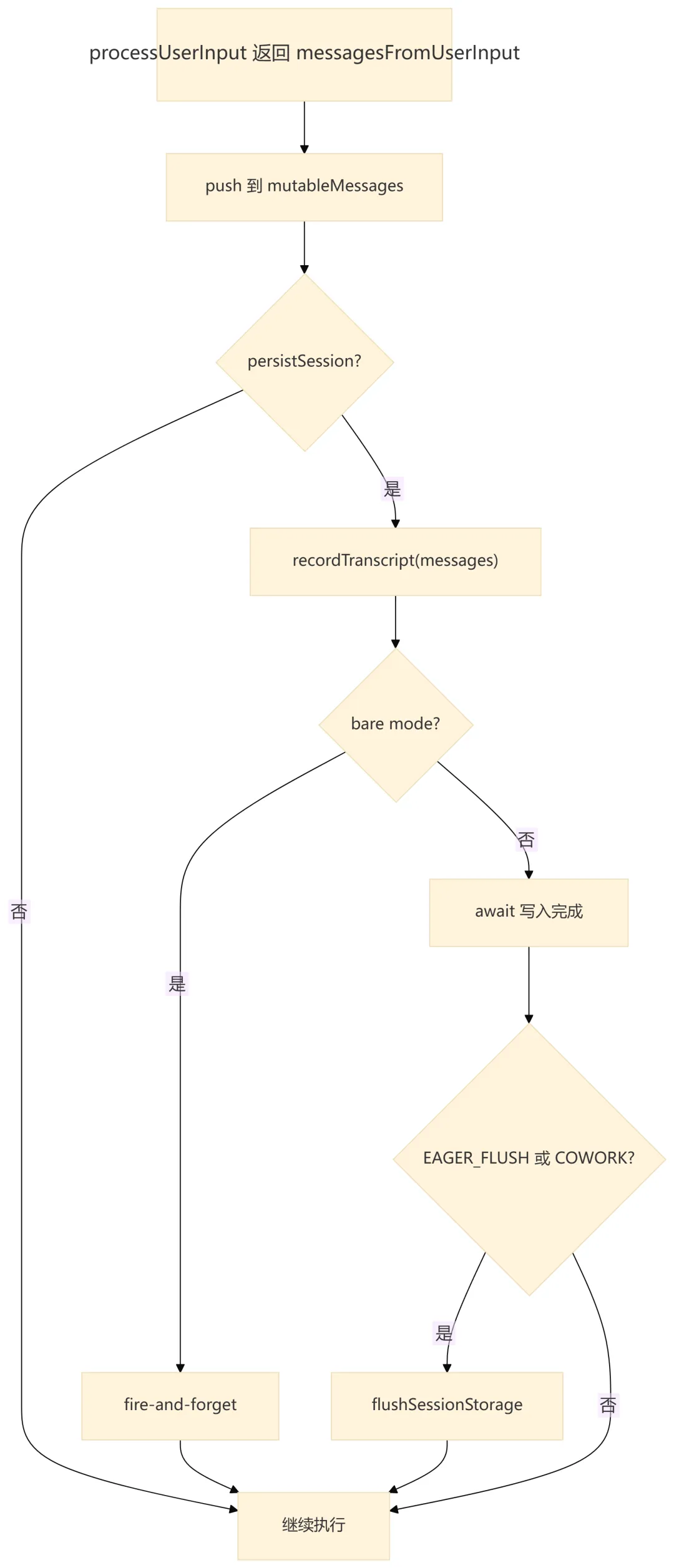
后续在 query() 输出 assistant、user、compact boundary、progress、attachment 时,QueryEngine 还会继续维护 transcript。对 assistant 消息,它倾向于 fire-and-forget,避免阻塞流式输出;对需要保证顺序和恢复正确性的消息,则会 await。
11. 退出条件与错误出口
11.1 QueryEngine 层的结果封装
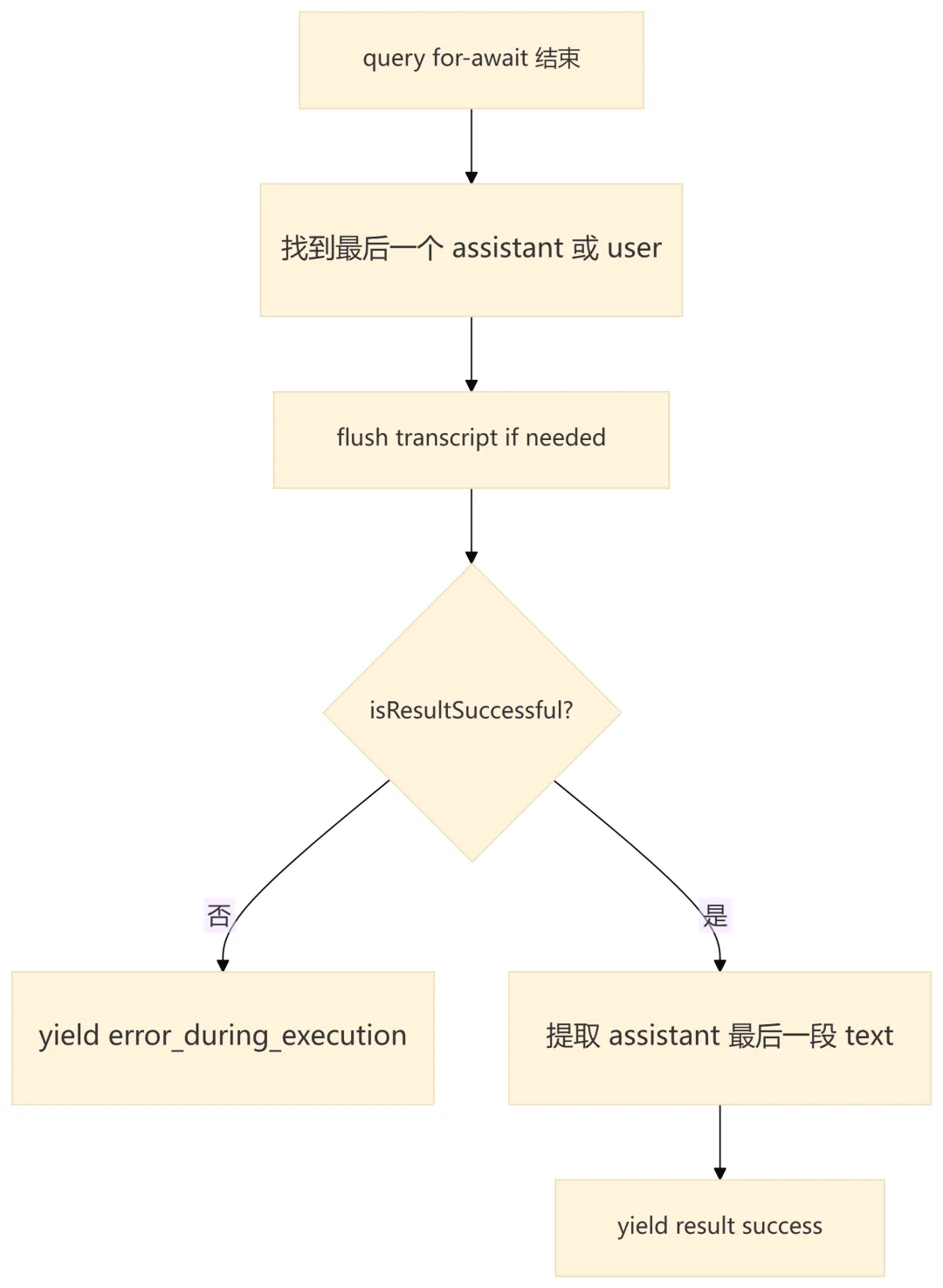
11.2 主要错误出口
|
|
|
|
|
|---|---|---|---|
|
|
shouldQuery=false |
success |
|
|
|
query.ts
max_turns_reached attachment |
error_max_turns |
|
|
|
getTotalCost() >= maxBudgetUsd |
error_max_budget_usd |
|
|
|
jsonSchema
|
error_max_structured_output_retries |
|
|
|
|
error_during_execution |
|
|
|
system
api_error |
api_retry
|
|
12. 并发与顺序性的设计
单个 queryLoop() 对工具调用采取偏顺序、偏保守的推进方式。即使模型一次给出多个 tool_use,系统也会围绕“assistant tool_use -> 本地 tool_result -> 下一轮 messages”的闭环推进。这样做有几个工程收益:
-
前一个工具结果可以影响下一步模型判断,避免过早并发造成无效工作。 -
消息链与 transcript 更容易保持一致,便于恢复。 -
UI 可以按顺序展示模型决策和工具结果,用户更容易理解。 -
权限拒绝、工具失败和中断更容易定位到具体 tool_use_id。
Claude Code 并不是没有并发,而是把并发放在更高层:例如 AgentTool 或团队/多 Agent 能力可以启动多个独立 loop。单个 loop 保持可推理,多 Agent 层负责并行。
13. 设计权衡
13.1 会话控制器与执行循环拆分
优点:
-
QueryEngine可以专注 SDK/会话语义,包括 transcript、usage、权限审计、消息归一化。 -
queryLoop()可以专注模型和工具之间的执行闭环。 -
测试边界更清晰:状态管理与循环推进可以分开验证。
代价:
-
一条用户请求会跨多个抽象层,初学者容易误以为 QueryEngine.ts就是全部 Agent Loop。 -
消息在内部格式、API 格式、SDK 格式之间多次转换,需要严格维护配对关系。
13.2 显式 tool_result 回流
优点:
-
模型不会“自动知道”工具结果,所有结果都在本地显式写回 messages。 -
transcript、resume、debug 都能看到完整因果链。 -
可以在中断或异常时补齐缺失的 tool_result,避免 API 看到不成对的工具消息。
代价:
-
工具执行、错误恢复和消息修复逻辑必须非常谨慎,尤其是流式 fallback 或 abort 场景。
13.3 每轮主动整理上下文
优点:
-
长会话可持续运行,不会无限膨胀。 -
tool result budget、microcompact、autocompact、context collapse 可以分别处理不同类型的上下文压力。
代价:
-
“内存中的完整历史”和“发给模型的可见视图”并不总是一致,调试时需要区分这两个概念。
14. 软件视图总结
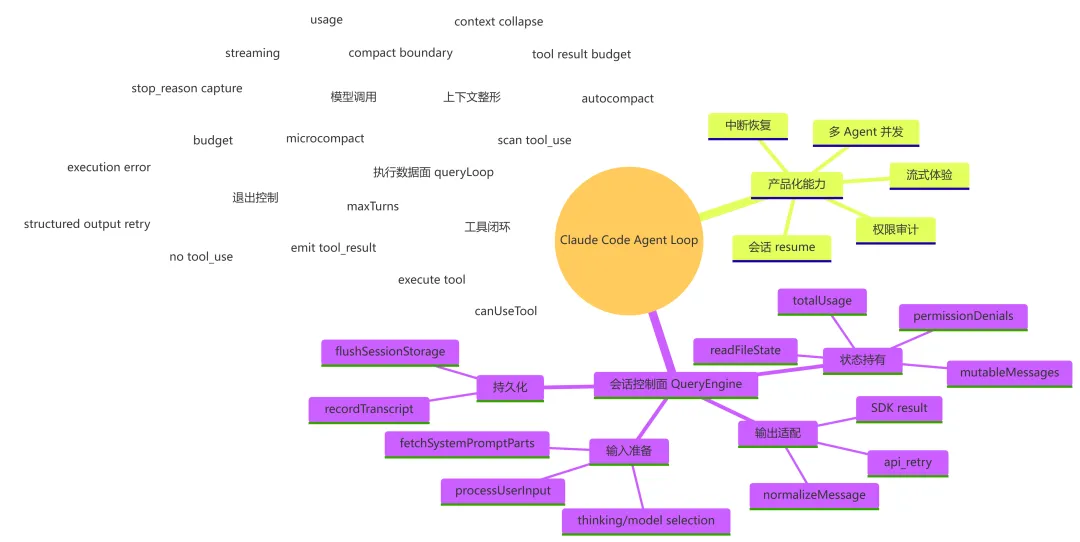
从软件设计角度看,Claude Code 的 Agent Loop 成熟之处不在于 while (true) 本身,而在于它围绕这个循环建立了完整的工程外壳:上下文构建、工具闭环、权限审计、流式输出、持久化恢复、token/成本记账和多种压缩策略。QueryEngine 让一轮请求具备“产品会话”的完整语义,queryLoop() 则让模型和工具能在一个可控、可恢复、可观测的闭环中持续协作。