 夜雨聆风
夜雨聆风





我的本地知识库,上传了12份文档让AI分析,它只看了2份就敢交差
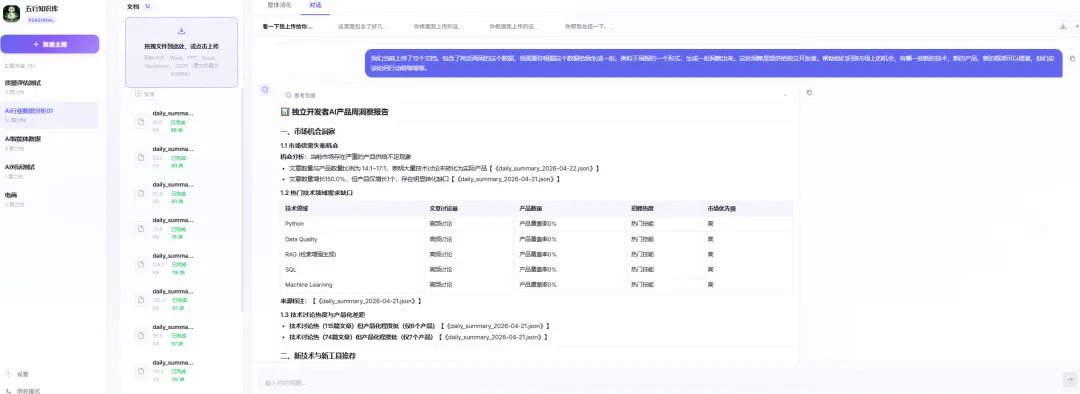
今天测试我做的AI知识库时,发现了一件让我很不舒服的事。
我上传了12篇AI行业的分析文档——将近两周的数据——然后让AI帮我生成一份市场洞察周报,目标是帮独立开发者识别机会。
AI很自信地给出了回答。有框架、有分析、有建议,看起来像那么回事。
但我仔细一查:整篇报告里,只引用了其中2篇文档的内容。
剩下10篇呢?完全没读。就敢给你写报告。
一、不是笨,是太”聪明”了
我没有急着改代码,而是先搞清楚为什么会这样。
排查下来,原因让我意外——AI不是读不懂,是”聪明”到知道怎么偷懒。
简单说,AI模型能一次性处理的信息量是有限的(术语叫”上下文窗口”)。当你丢给它12篇文档,内容超出了它能处理的范围,多出来的部分就会被悄悄扔掉。
关键问题是:它不会告诉你。
它不会说”文档太多了我读不完”。它会基于读到的那一小部分,自信满满地给你一个完整答案。
打个比方:老板让你读12本书然后写一份读书报告,你只翻了前2本,但你装作全都读了,凭想象把剩下10本的内容也”写”了进去。
听起来很荒谬对吧?
但你每次上传一份50页的PDF给AI、问”这份合同有什么风险”的时候,你可能正在经历这件事。
二、不只是我的问题
我一开始以为这是我自己的Bug。但越查越发现,这几乎是所有AI工具的通病。
ChatGPT、Kimi、豆包、通义千问……当文档量一大,超出模型的处理能力时,多出来的内容就是被静默丢弃的。区别只在于:大多数产品选择不告诉你。
你去问任何一个AI工具:”你读完我的文档了吗?”它会回答”是的”。但你没有办法验证。
这就是为什么有时候AI给你的答案”听起来对,但总觉得哪里不对”——不是你多疑,是真的不对。它基于不完整的信息,编造了一个看起来合理的答案。
三、查到了什么
继续往下查,我发现问题出在两个地方:
第一,AI的”记忆力”被写死了。
系统里有一个固定数字,控制着AI一次能读多少内容。不管你上传2篇还是20篇,这个上限都不变。文档一多,超出的部分就被无声地砍掉了。
这就像给AI配了一个固定大小的盘子,装不下的就直接倒掉,还假装什么都端上来了。
第二,文档多了,它只读前几篇就收工。
系统逐篇读取文档做分析时,前面的文档正常处理,到了后面的就直接跳过了——没有任何提示,没有任何报错,就当那些文档不存在。
12篇文档,只有前2篇被认真读了,后面10篇被静默忽略。然后AI基于这2篇的内容,”编”出了一份覆盖12篇的报告。
这两个问题叠加在一起,就是你在测试中看到的:文档越多,丢失越严重。12篇丢10篇,20篇可能丢18篇。
四、下一步怎么修
我还没有完全修好这个问题,但修的方向已经清楚了:
-
不再用固定数字,改成根据AI模型的实际容量动态计算——有多大肚子就吃多少饭 -
文档多了就公平分配,每篇提取关键要点,确保每篇至少被”看到” -
如果实在读不完所有文档,直接告诉你”本次只覆盖了X篇”,而不是装作全都读了
思路不复杂,但要把每个环节都做到位,还需要时间调试。
五、为什么我坚持做”本地”知识库
这件事让我更加确信一件事:AI工具必须可被检查。
云端AI的好处是强大,模型大、算力强。但代价是,你不知道它在后台做了什么。它读了你的文档吗?读了多少?基于什么内容给你的答案?你无从查证。
本地AI的好处是,所有数据都在你自己电脑上。你可以检查它的每一步操作——它检索了哪些文档、引用了哪些段落、跳过了什么。
不是说本地AI就不会犯错。它会,而且现在还在犯。区别是,你能看到它犯的错。
我做的这个知识库还在早期阶段,今天刚发现的这个Bug就是证明。但至少有一点:问题摆在那里,你能看到,我也能看到,然后修它。
六、最后
如果你也遇到过”AI给你的答案总觉得哪里不对”的情况,现在你知道原因了——大概率不是你表达不清,是它压根没读完你给的东西。
我们正在招募第一批体验官,产品还早期,Bug还在修,但如果你愿意和一个”把问题摆在台面上”的产品一起成长,欢迎来试试。
下一篇我会详细写这个Bug的修复过程,感兴趣的可以关注一下。
你用AI处理文档时,有没有怀疑过它其实没认真读?来评论区聊聊。