 夜雨聆风
夜雨聆风





个人 AI 开发配置(2605-6):你该买什么,三类用户的完整推荐方案
五篇读完,是时候把结论给出来了。Intel Core Ultra + RTX 5090 台式机,还是高配 Mac mini——哪个对,取决于你主要用来做什么。这篇不绕弯,直接按用户类型给推荐,再对 RTX 5090 这个具体配置做一个直接评价。
决策树:从用途出发
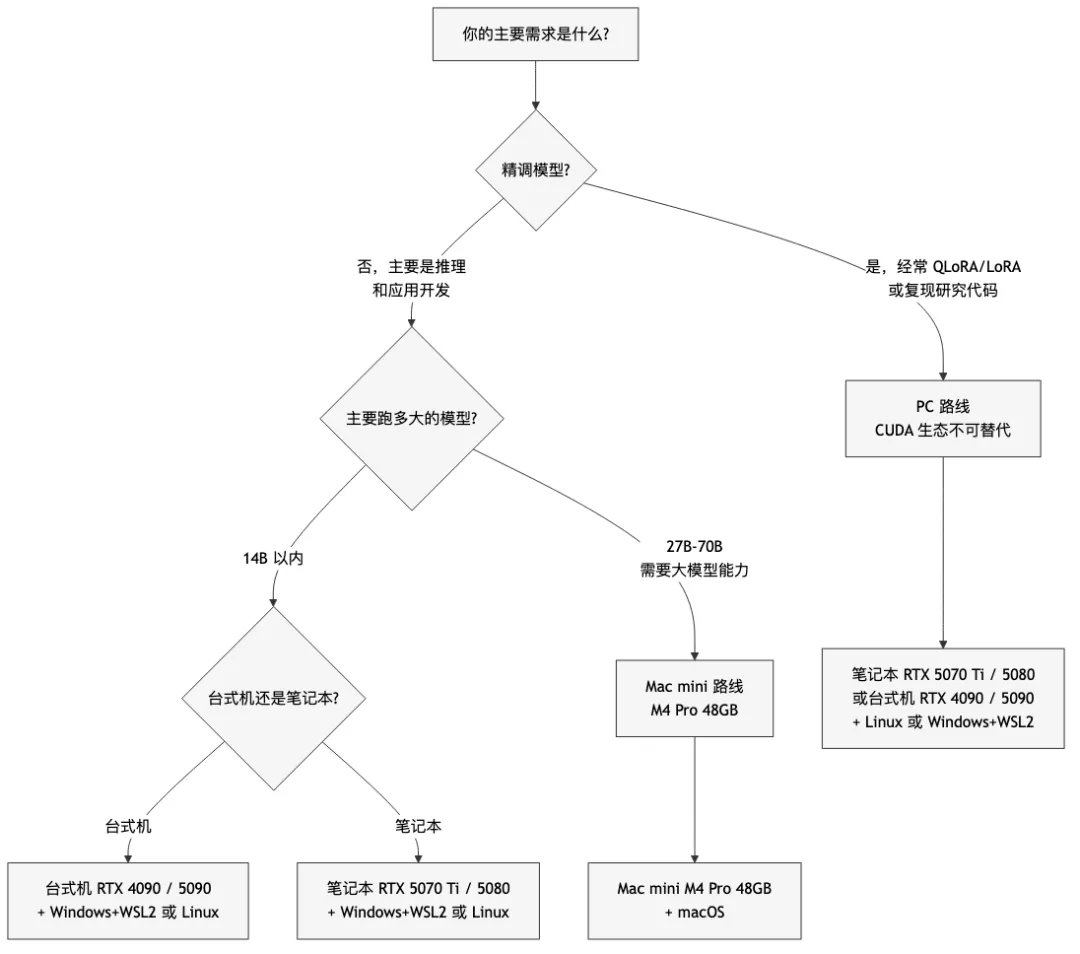
A 类:AI 应用开发者
你是谁:用 AI 做产品,写 AI 应用,调用模型做 RAG、Agent、文档分析,主要关心效果和开发效率,不做底层研究,不经常精调大模型。
推荐方案:Mac mini M4 Pro 48GB + macOS
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
为什么不推荐 PC + RTX 5070:
5070 的 12GB 只能跑 14B 以内模型。当前主流场景——代码生成用 Qwen3.6-27B、文档分析用 70B 模型——PC 路线要么跑不了,要么 offload 后速度不可用。Mac mini 的内存优势在这个场景是决定性的。
关于 CUDA 工具链的不足:
做应用开发,你大概率不需要改 GPU kernel,不需要跑 Flash Attention,不需要深入 PyTorch 底层。Ollama、LangChain、本地 API 调用——这些 macOS 上全部没问题。CUDA 的缺失在这个用途下感受不强。
预算:Mac mini M4 Pro 48GB,中国官网约 13999 元(截至 2026 年 4 月)
B 类:AI 研究者 / 需要精调的工程师
你是谁:复现论文代码,用 QLoRA/LoRA 精调 7B-34B 模型,需要 Flash Attention、bitsandbytes、各种 CUDA kernel,经常跑不知名的 GitHub 仓库。
推荐方案:PC + CUDA 显卡,形态分两条路
笔记本路线:RTX 5070 Ti(16GB)或 RTX 5080(16GB)
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
便携,不占桌面空间。5070 Ti 和 5080 均为 16GB GDDR7、896 GB/s 带宽,5080 CUDA 核心更多、算力更强,精调速度有感;价差约 2500-3000 元(国内),不在意速度选 5070 Ti。
台式机路线:RTX 4090(24GB)或 RTX 5090(32GB)
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
RTX 4090(24GB,二手约 8000-12000 元):27B Q4 全装入显存,是台式机路线的性价比首选。RTX 5090(32GB,新品约 16000 元):Blackwell 架构新卡,27B 速度更快,32GB 也能装下更大模型,适合追求性能上限。 操作系统推荐:
-
专职研究:Linux(Ubuntu 22.04 LTS),零摩擦,CUDA 驱动最稳 -
需要兼顾日常:Windows 11 + WSL2,满足日常需求,AI 工具链可用
关于 Mac 路线的放弃:
MLX 精调生态在持续改善,但 2026 年的现实是:大量精调工具(Unsloth、LLaMA-Factory、Axolotl)深度依赖 CUDA,在 Mac 上不可用或功能受限。如果精调是你的核心需求,选 Mac 会持续踩坑。
预算:笔记本(含 RTX 5070 Ti)约 14000-20000 元;台式机整机(含 RTX 4090)约 20000-26000 元,含 RTX 5090 约 30000 元以上
C 类:内容创作者 / 轻量 AI 用户
你是谁:主要用 Claude/GPT 等云服务,偶尔想在本地跑个模型,AI 是辅助工具,不是核心工作内容。不想折腾,希望即插即用。
推荐方案:先评估是否真的需要本地模型
路线一:继续用云服务,不买本地 GPU
如果你每天用 AI 的时间不超过 2 小时,而且用的是 Claude、Kimi、通义这类成熟商业服务,你不需要本地 GPU。当前主流商业大模型的云端版本效果优于任何你能在本地 14GB 显存里跑的量化模型。买本地硬件,钱花了,效果还不如云端服务。
路线二:Mac mini M4 基础款(24GB)
|
|
|
|
|---|---|---|
|
|
|
|
这个配置跑 Qwen3-14B 非常流畅,用来做离线写作辅助、代码补全、翻译,体验很好。不买 48GB 是因为这类用户的主力场景用不到 70B 模型,多花 5000 元性价比不高。
不建议这类用户买 PC + RTX 5070:
主要原因是日常摩擦。PC 需要维护操作系统环境,驱动更新,CUDA 版本管理——对于把 AI 当工具用的用户,这些维护成本比 Mac mini 高得多。Mac mini 的开箱即用体验在 C 类用户这里是决定性优势。
直接回答:台式机 AI 显卡,RTX 4090 还是 RTX 5090
RTX 4090(24GB):上一代 Ada Lovelace 架构,二手市场成熟(国内约 8000-12000 元),450W TDP。24GB 可以完整装下 Qwen3.6-27B Q4,推理约 30 t/s。CUDA 成熟度极高,所有工具链均稳定支持。对大多数个人 AI 用户,这是台式机路线的性价比终点。
RTX 5090(32GB):Blackwell 架构新卡(2025 年初发布),新品约 16000 元(美国),575W TDP。32GB 装 27B 有很大余量,推理约 50 t/s,带宽 1792 GB/s。额外的 8GB 在超长上下文场景下有明显优势。如果你有明确的”需要比 4090 多的 VRAM”场景,5090 值得考虑;否则 4090 的性价比更高。
CPU 无所谓:AI 推理的瓶颈是 GPU,CPU 负责调度和预处理,Intel Core Ultra 和 AMD Ryzen 在 AI 工作负载下没有明显差别。
最终判断:
台式机 AI 配置的选择起点就是 RTX 4090,不是 5070。5070 系列(12GB)适合预算有限的入门场景或笔记本;台式机一旦拆开机箱认真配 AI,24GB 是最低合理起点。
三条路的完整配置参考
|
|
|
|
|
|---|---|---|---|
| A类 AI 应用开发 |
|
|
|
| B类 AI 研究/精调(笔记本) |
|
|
|
| B类 AI 研究/精调(台式机) |
|
|
|
| C类 轻量用户 |
|
|
|
没有一个配置适合所有人。清楚自己属于哪类用户,选择就不难。
系列总结
这个系列的核心逻辑是:
- 内存容量决定你能跑什么
,算力决定跑多快——顺序不能反 - Mac mini M4 Pro 48GB
是内存大、能装大模型的个人首选,代价是 CUDA 生态不可用 - PC 路线按形态分两类
:笔记本 RTX 5070 Ti / 5080(16GB),台式机 RTX 4090(24GB)/ RTX 5090(32GB)——台式机没理由选 12GB - 操作系统是约束,不是偏好
——Mac mini 锁定 macOS,PC 根据用途选 Linux 或 Win+WSL2 - 买本地 vs 租云
:日常推理买本地,偶尔精调大模型租云,不是非此即彼
本系列文章数据截至 2026 年 4 月,GPU 市场和定价变动较快,以购买时实际情况为准。