 夜雨聆风
夜雨聆风





【CPIL 研之有悟】解构小龙虾OpenClaw

「 解构 OpenClaw 」
Insights on OpenClaw

工程实现、爆发节点,
对 Agentic AI 未来的启示
Engineering, Breakthroughs, and Implications.
在本周CPIL的组会中,韩长江同学分享了报告:“解构 OpenClaw:它的工程实现、爆发时间点,以及智能体 AI 将何去何从”。
过去几年,大模型领域取得进展的方式出奇地一致:更大的模型,更多的数据,更长的上下文,更强的推理能力。这个方向当然有效。模型会写代码,会看图,会调用工具,会在越来越长的任务里保持状态。于是一个自然的预期出现了:只要模型继续变强,智能体就会自然到来。
OpenClaw 的走红提醒我们,事情并没有这么简单。
模型能回答问题,不等于它能替人做事;模型能操作软件,也不等于它能长期待在真实工作流里可靠运行。智能体的下半场,不只是继续扩展模型能力,而是扩展模型与现实世界之间的通信方式:它如何接收任务,如何获得上下文,如何记住经验,如何调用工具,如何在权限边界内行动,又如何把失败和纠错变成下一轮能力。
这正是 OpenClaw 值得讨论的地方。它没有提出新的模型结构,没有刷新一个标准基准测试,也没有发明 computer use(计算机操作能力)。但它把一组原本分散的机制放到了一起:消息入口、本地环境、记忆、技能、工具、cron、沙箱、社区贡献。单独看,每个组件都不惊艳;合在一起,它让模型从一个会话对象变成了一个可以长期工作的个人智能体运行时。
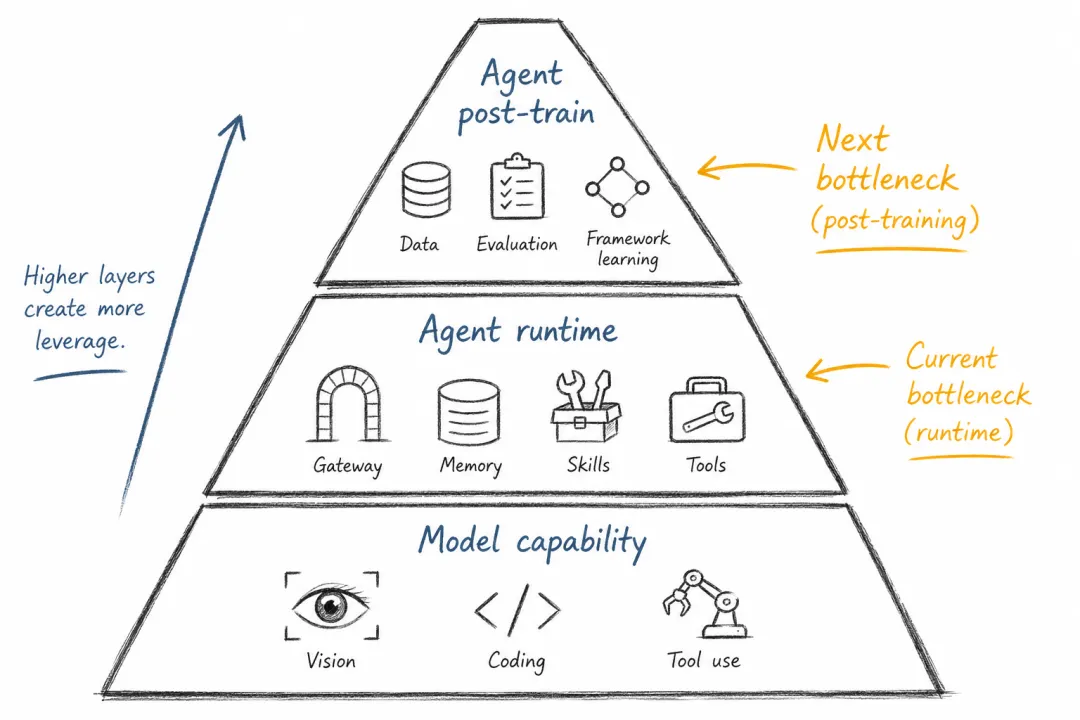
OpenClaw 暴露了智能体时代的新瓶颈。
所以,OpenClaw 的意义不是“又出现了一个 AI 应用”。更准确地说,它暴露了智能体 AI 的一个结构性变化:过去我们主要扩展模型本身,接下来必须扩展模型和环境之间的连接方式。

FROM QA TO WORK
从会回答,到能工作
Chatbot 的基本形态是请求-响应。用户打开一个页面,提出问题,模型给出回答。这种交互足以承载问答、写作、代码补全、检索总结等任务,但它离“替人完成工作”仍然有距离。
工作不是一次回答。工作往往包含等待、恢复、通知、检查、确认、重试,也包含偏好、规范、历史和上下文。一个秘书、研究助理或工程助手,不只是知道某个问题的答案,而是知道任务在哪个阶段、哪些信息可信、哪些动作需要确认、什么时候该主动提醒人。
OpenClaw 的关键变化在这里。它不是让模型更会聊天,而是把模型放进了一个长期在线的工作过程。消息入口让它进入用户原本的生活流,本地环境让它接触真实文件和工具,记忆和技能让它积累经验,沙箱和权限让它在可控范围内行动。
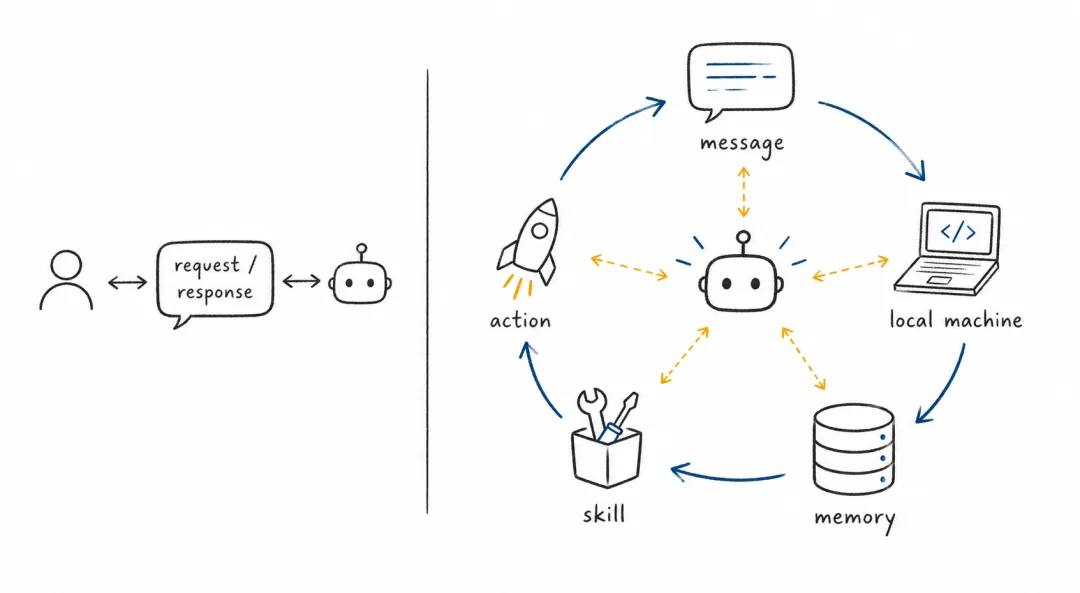
从模型能力到长期工作进程。
这改变了智能体的评价方式。聊天系统主要看回答质量、推理能力和语言体验;智能体系统还要看状态管理、权限控制、失败恢复、审计能力和人工确认。换句话说,智能体的能力不再只藏在模型参数里,而是分布在模型、运行时、记忆、工具、数据和安全机制之间。
这里容易出现一个误解:把智能体框架理解成 UI 或提示词集合,其实不然。它更像模型和现实世界之间的一层 harness。模型本身并不知道现在几点,不知道用户机器上发生了什么,不会稳定记住长期偏好,也不天然理解一次工具调用会带来什么后果。OpenClaw 里的记忆、技能、cron、Gateway、工具、沙箱,本质上是在把模型拿不到的上下文补给它。
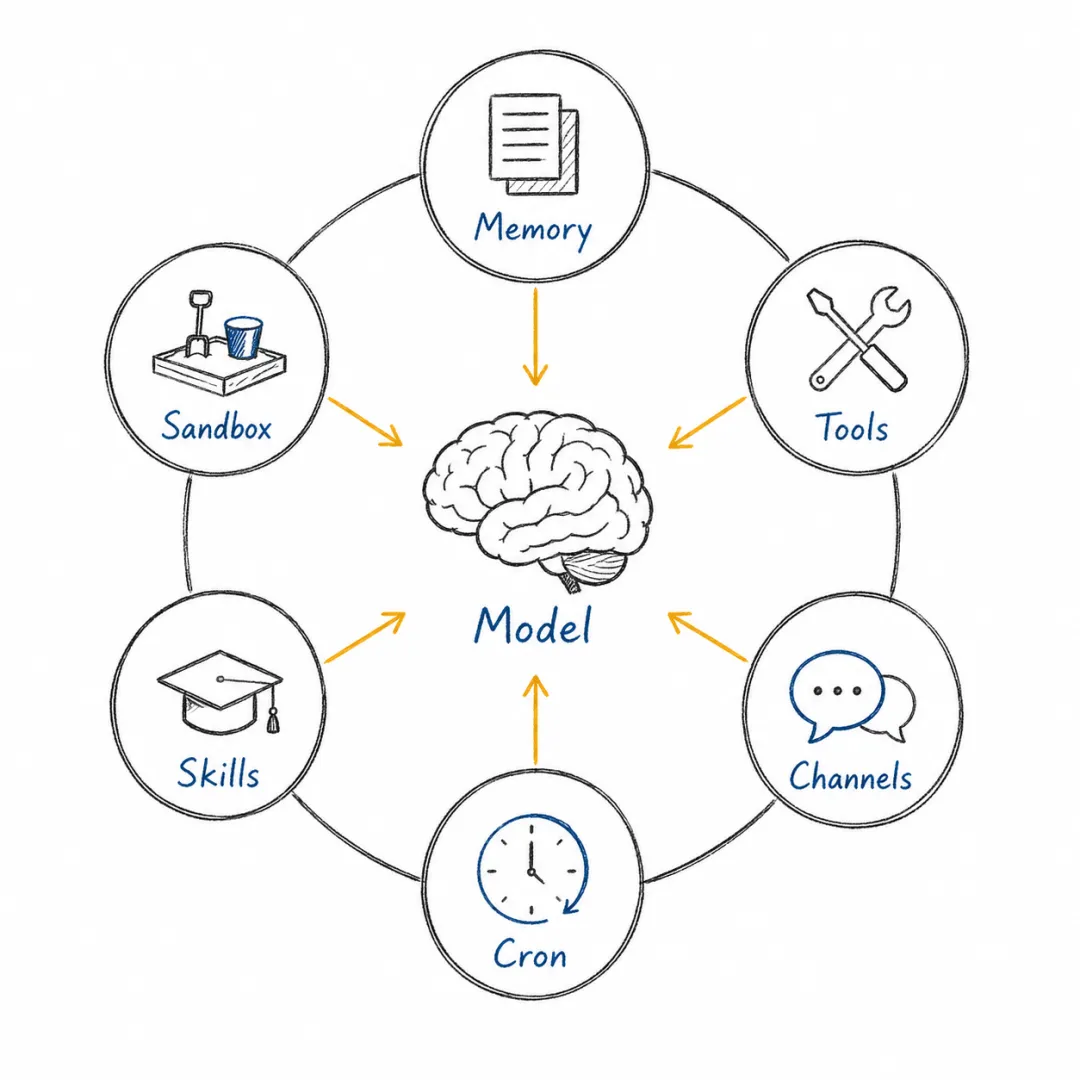
智能体框架本质上是在补齐模型做事时缺失的上下文。
因此,OpenClaw 的许多设计乍一看并不惊艳,实际使用一段时间之后才会惊叹设计之合理。消息入口、定时任务、Markdown 记忆、工具调用都不是新发明。问题在于,在智能体时代,真正稀缺的往往不是某个新按钮,而是这些基础组件能不能被组织成一个稳定的运行时。
SOLUTION ALREADY EXISTS
OpenClaw 之前,解决方案已经存在
OpenClaw 不是凭空出现的。它更像几条技术路线在某个时间点的汇合。
RPA、Zapier、IFTTT 代表了最早也最稳定的一条路线:让软件替人执行流程。它们的优势是可靠,缺点也很清楚:依赖强 schema、固定触发器和人工配置。任务一旦变得模糊,系统就很难自己补全意图。
AutoGPT、BabyAGI 则把想象力推到了另一端。人们开始看到 LLM 可以规划、调用工具、循环执行。但这些早期自主智能体很快暴露出问题:状态管理脆弱,任务容易跑偏,真实环境太薄,权限边界也不清楚。它们证明了方向,却没有给出可长期使用的运行时。
再往后,computer use 和 GUI 智能体把问题推进到软件界面本身。Adept ACT-1、Anthropic Computer Use、OpenAI Operator/CUA、Google Project Mariner 等工作证明,模型可以观察屏幕、点击按钮、输入文字、跨软件操作。它们回答的问题是:模型能不能操作人类的软件?
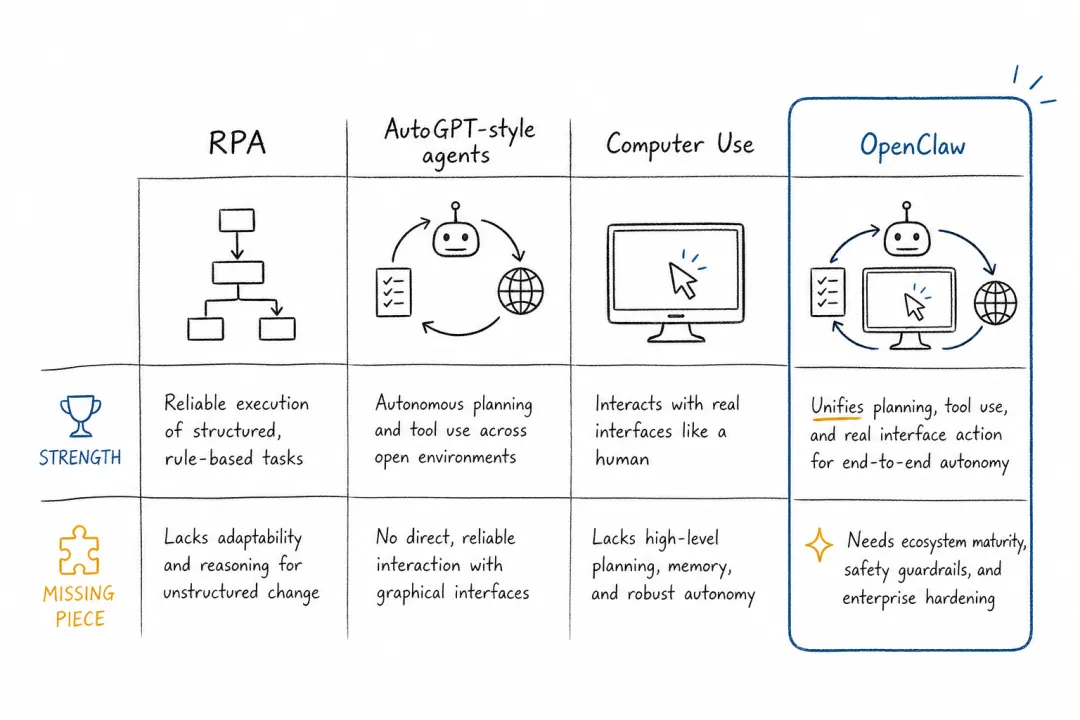
OpenClaw 综合了几条早期路线,但不等同于任何一条。
OpenClaw “稳稳接住”了这些问题,但没有停留在其中任何一条路线上。它继承了 RPA 的“替人做事”,继承了 AutoGPT 的开放想象,也继承了 computer use 的系统级操作方向。不同的是,它把入口放在日常消息应用,把执行放在本机,把经验沉淀为记忆和技能,把扩展交给社区。
这就是它和前序系统的差别。computer-use 模型回答“模型能不能操作软件”;OpenClaw 则追问“它能不能每天在我的工作流里替我做事”。前者偏能力,后者偏系统;前者关注一次任务是否完成,后者关注长期使用是否可控、可恢复、可积累。
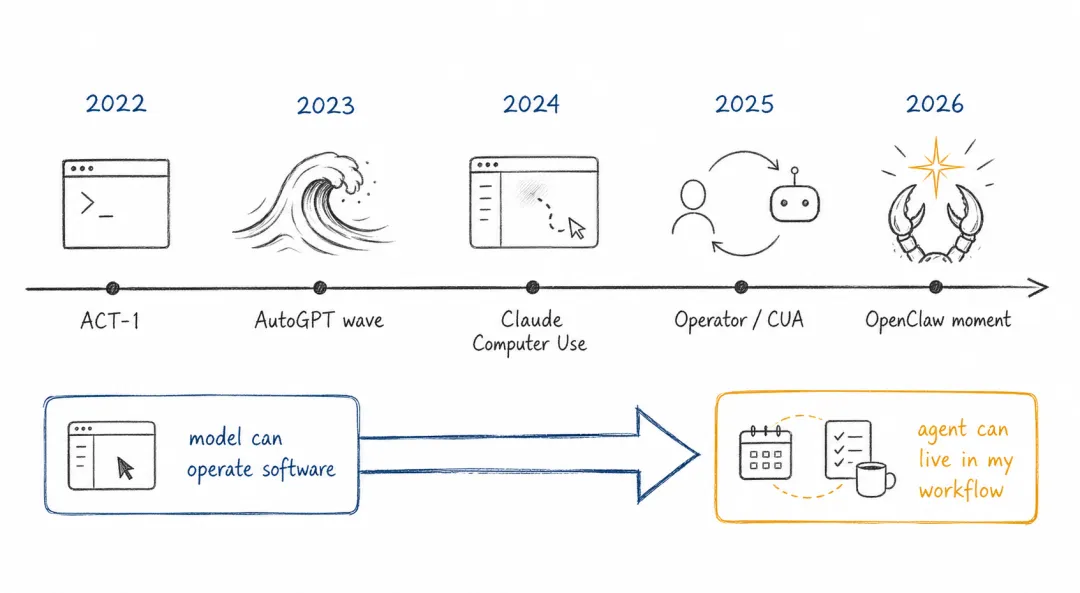
Computer use 给出能力,OpenClaw 补上个人工作流。
在这个意义上,OpenClaw 的突破不在于“它能行动”这件事本身,而在于它把行动能力包装成了低摩擦、长期在线、可被群体改进的开源个人运行时。
UNDERESTIMATED RUNTIME
被低估的运行时 runtime
要由浅入深地理解 OpenClaw 的工程路线,最好的切口不是 UI(它实际上是 OpenClaw 技术栈上的最薄弱环节),而是 Gateway。
Gateway 不是普通聊天窗口,而是一个长期在线的控制平面。它把 WhatsApp、Telegram、Slack、Discord、Signal、iMessage、WebChat 等入口接到智能体运行时,再向下连接工具、记忆、技能、任务调度和权限策略。
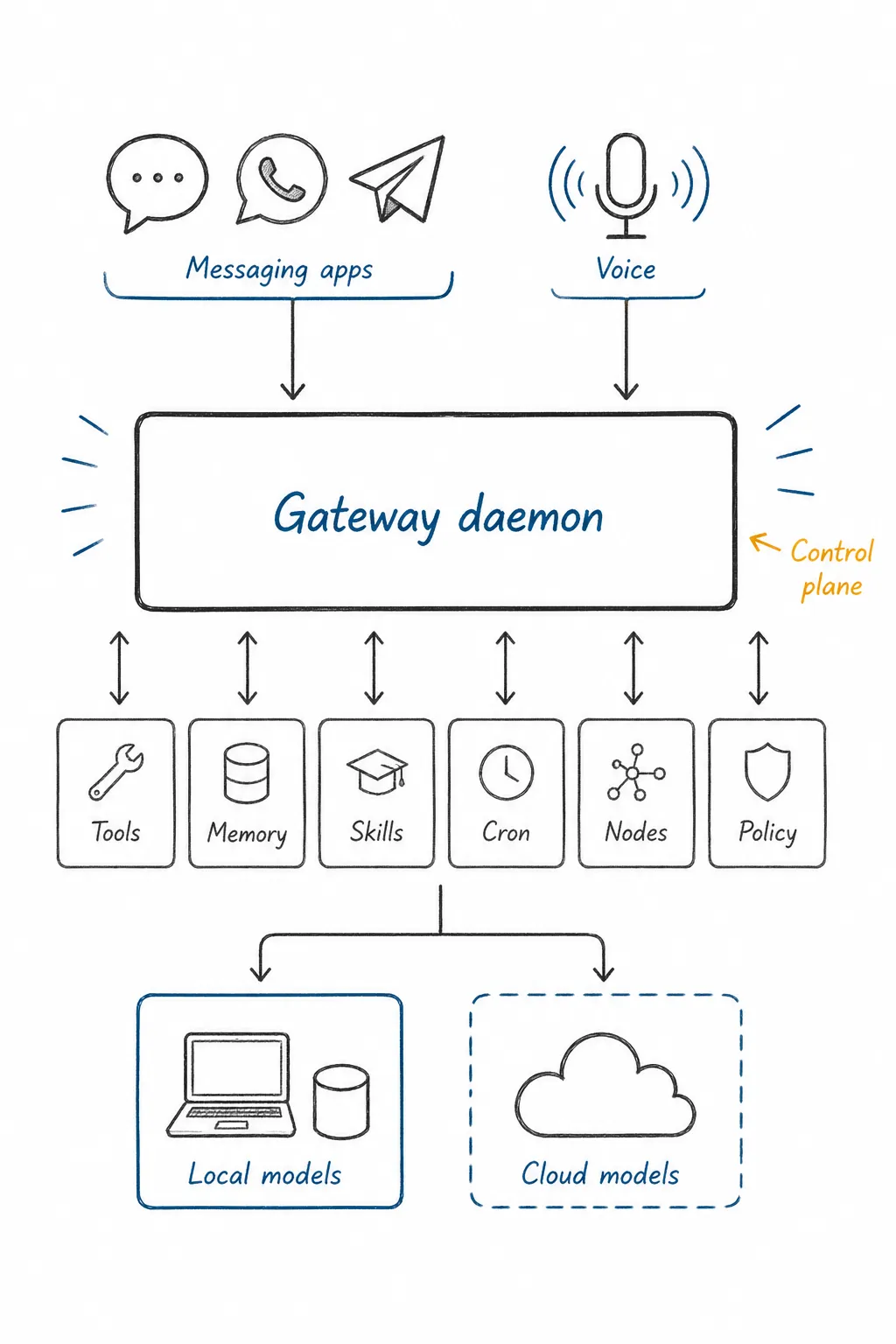
Gateway 把消息入口变成智能体控制平面。
消息应用看起来只是入口,实际上决定了智能体能否进入真实工作流。它天然异步,天然有通知,支持语音、图片、视频和群聊,也很适合人工确认。对个人智能体来说,最重要的界面未必是一个全新的网页,而可能就是用户每天已经打开几十次的消息流。
这件事降低的不只是学习成本,更是启动成本。一个独立的智能体 app 需要用户想起来、打开它、组织需求、等待结果;而日常通信 app 原本就处在用户的注意力流里。任务可以从一句语音、一张截图、一段转发消息开始,也可以在群聊里被多人补充和纠正。入口一旦变成 WhatsApp、Telegram、Slack、iMessage 或飞书,智能体就不再像一个需要被特意召唤的工具,而更像一个已经在场的协作者。
这也是 OpenClaw 比许多早期智能体更容易被高频使用的原因。它不是要求用户迁移到一个新的工作台,而是把智能体接到用户已有的工作流里。对消费者产品而言,这种摩擦的下降往往比单次能力提升更重要:只有当委托任务的成本足够低,用户才会把越来越多的小任务交出去,系统也才有机会积累真实交互。
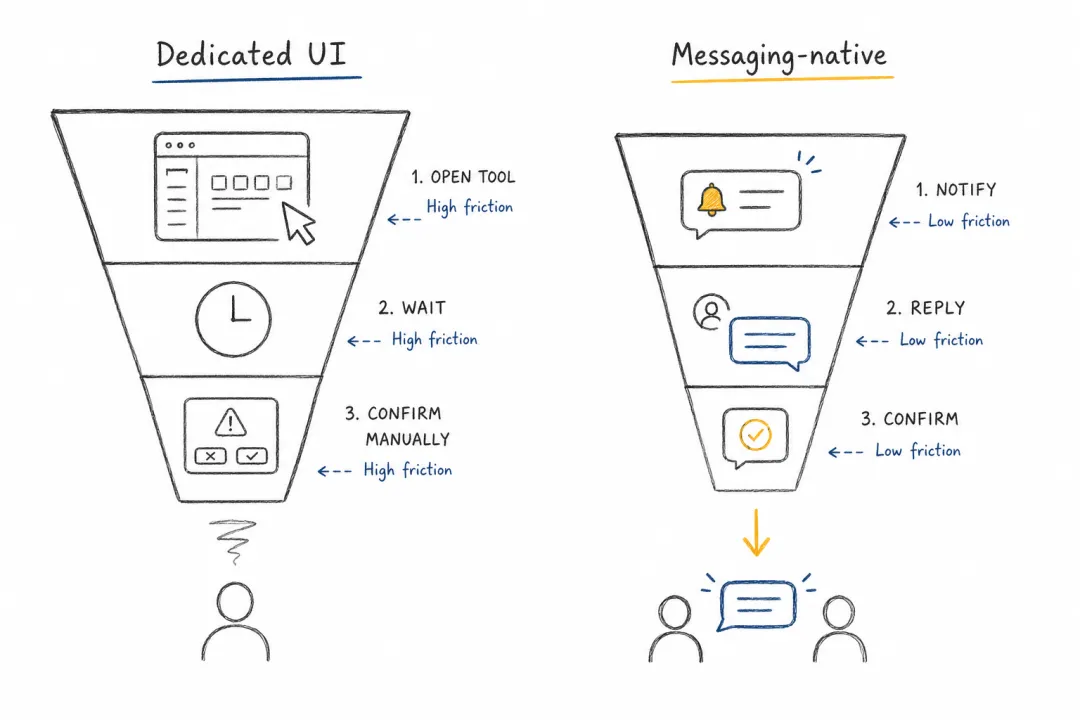
消息入口不是 UI 装饰,而是可靠交互机制。
沿着 Gateway 往下看,always-on 运行时是另一个容易被低估的部分。传统聊天系统在一次会话结束后就停止;真实任务却常常需要等待、轮询、恢复和回报。清理邮箱、跟踪新闻、处理 GitHub issue、生成日报、等待航班信息、监控系统状态,这些任务都不是一次问答。
因此,cron、会话、命令队列、唤醒、健康检查并不只是工程细节。它们是智能体进入日常工作的前提。一个只能在用户盯着屏幕时工作的智能体,本质上仍是高级聊天工具;一个能在后台等待、执行、恢复并主动汇报的智能体,才开始接近一个你的私人数字助理。
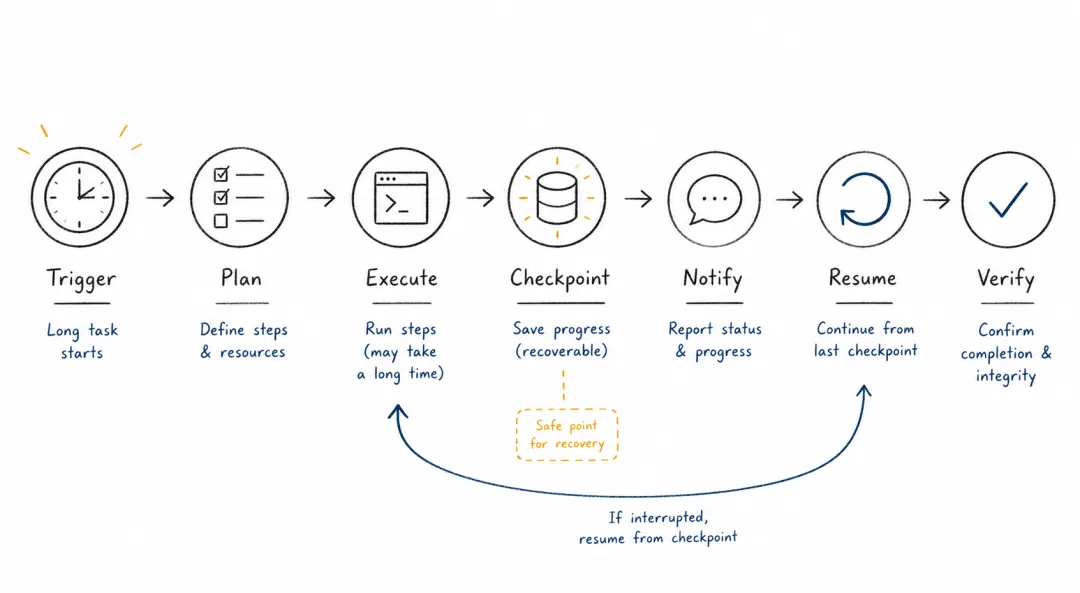
Always-on 运行时让智能体从会话变成进程。
记忆也是同样的逻辑。OpenClaw 把长期记忆写入 workspace 中可读、可改、可审计的 Markdown 文件,例如长期偏好、日常记录、项目规范和工作区约定。这种做法并不炫技,却非常关键:它让智能体的长期状态不再是不可见的会话魔法,而是用户可以检查、纠正和版本化的资产。
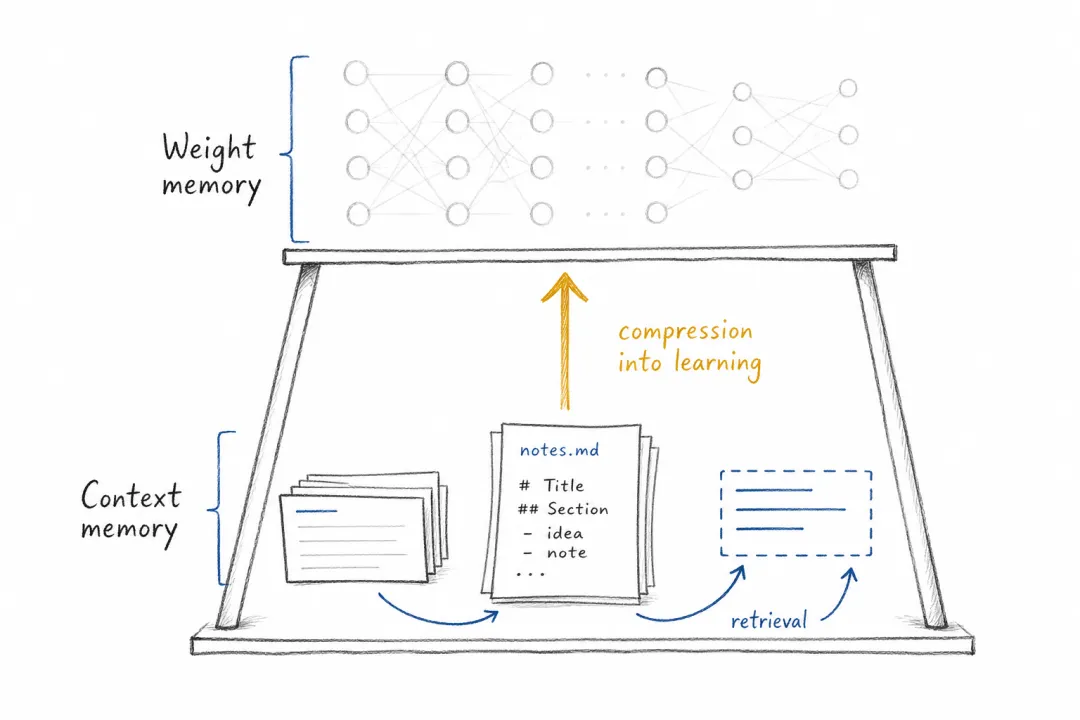
可审计记忆让长期状态从黑盒变成资产。
不过,当前这类记忆主要还是上下文记忆。它能帮助模型回忆事实、偏好和流程,但还不是模型权重里的长期知识。真正困难的问题仍在后面:如何把交互轨迹压缩成结构化记忆?如何区分事实、偏好、规则和临时状态?如何处理记忆冲突和过期?如何把成功与失败的任务轨迹变成训练数据?
Skills(技能)则提供了另一条路径。它不只是提示词市场,更像把人类隐性经验变成可执行经验的容器。
许多真正有价值的信息并不在公开预训练语料里:公司的内部流程、研究员的判断标准、团队的代码规范、某类任务的失败经验、个人长期形成的偏好。这些知识很难靠一次提示词注入模型,却可以沉淀为 SKILL.md、脚本、工作流、检查清单和权限策略。
举一个更具体的例子。一个研究组可能会沉淀出一套“论文初筛技能”:收到 arXiv 链接后,先判断任务类型,再抽取方法、实验设置、baseline、局限性,最后按组内习惯生成一页 technical note。这里真正有价值的不是那几句提示词,而是多年形成的阅读标准、取舍偏好、检查顺序和输出格式。一旦它被写成技能,它就不再只是某个人脑子里的经验,而变成了可以迁移、可以版本化、甚至可以交易的任务资产。
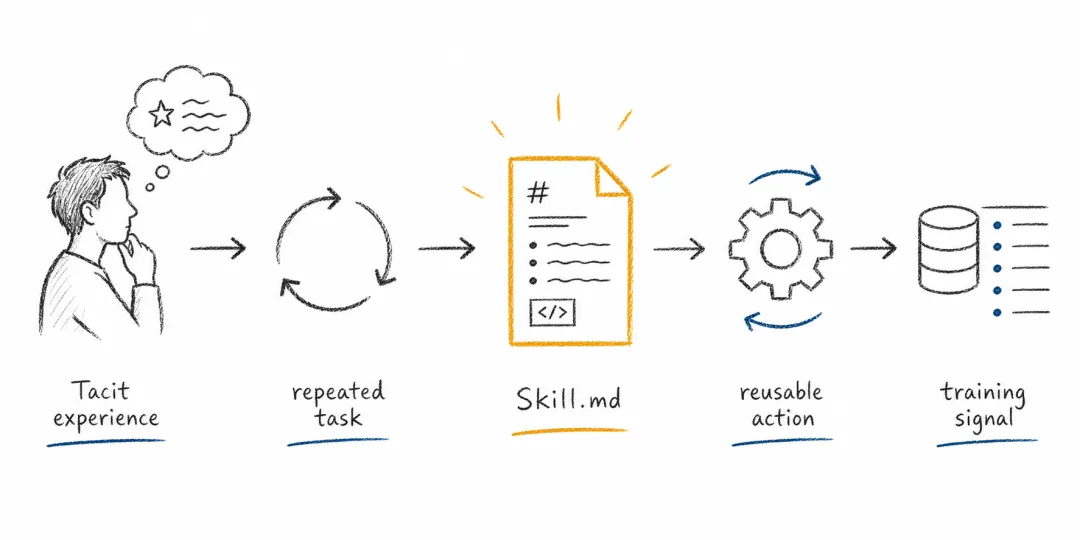
技能把隐性经验转化为可复用的执行经验。
这也是 GitHub gh skill、技能中心、AgentSkills-compatible folder 等动作值得关注的原因。技能可能会成为智能体时代类似包管理器或应用商店的层级:模型提供基础能力,运行时提供执行环境,技能承载可流通的任务知识和组织经验。
如果这条路成立,技能的增长逻辑会很像软件包生态早期:最初它只是开发者为自己省事写下来的工作流;当 host、权限声明、版本管理、评价体系和分发渠道逐渐稳定,它就可能变成一种新的供给市场。模型公司卖的是通用能力,运行时公司卖的是执行环境,而技能作者卖的可能是某个垂直场景里“如何把任务做对”的经验。
但只要智能体开始进入本地环境,安全问题就无法绕开。OpenClaw 有价值,是因为它能访问本地文件、浏览器、shell、账号状态、开发环境和消息系统;OpenClaw 有风险,也正是因为它拿到了这些钥匙。
这正是 Claw 当前最大的“别扭”:不给权限,它几乎什么都做不了;给了权限,它又不再只是一个聊天助手,而是一个能动用真实资源的执行者。一个形象的比喻是,让一个聪明但仍会被骗的小孩拿着你家的钥匙出门办事。它可能很努力,也可能完成许多琐碎但高价值的任务;但只要路上有人用几块糖骗它,它就可能把地址、钥匙、密码甚至家里的布局都交出去。
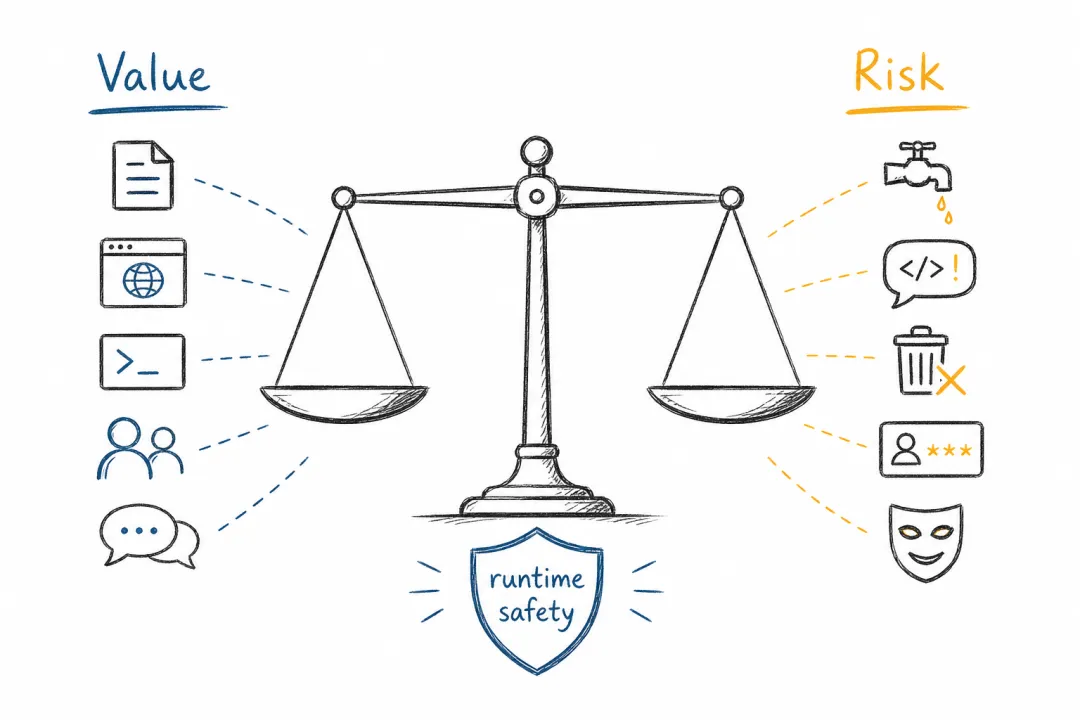
持有大量系统权限的智能体,核心问题是运行时安全。
当模型仍可能受到提示词注入(prompt injection)影响,仍可能误判工具调用的后果,仍可能在分布外场景中幻觉时,系统不能只期待模型“更聪明”。它需要沙箱、最小权限、policy-as-code、审批流程、审计轨迹、密钥隔离、按智能体划分的权限等运行时安全机制。NVIDIA NemoClaw / OpenShell 这类企业安全运行时的意义就在这里:它们不是简单复制 OpenClaw,而是在为这种高权限智能体补企业部署所需要的安全层。
这也是阻碍消费者完全接受个人智能体的主要问题。普通用户并不真的关心一个智能体的规划算法有多漂亮,他们关心的是:它能不能误删文件,能不能乱发消息,能不能泄露账号,能不能被网页或邮件诱导执行危险动作。只要这个问题没有被运行时层系统性解决,智能体越能干,用户反而会越犹豫。
WHY THIS PARTICULAR TIME
为什么是这个时间点
OpenClaw 的爆发不是单点突破,而是几个条件同时成熟。
模型能力已经够到了一个临界点。Frontier models 在 coding、tool use、vision、self-correction 和长程工作流上足够强,终于能支撑更复杂的任务。没有这个底层能力,运行时做得再漂亮也只会放大失败。
上下文的需求也发生了变化。聊天主要消费用户输入;智能体还要消费代码库、文件系统、工具轨迹、任务历史、用户偏好和环境状态。长上下文、检索、外部记忆和会话召回的需求,在这里几乎看不到天花板。
与此同时,运行时开始变得重要。模型能力只有被放进合适的运行时,才会转化为生产力。OpenClaw 把 daemon、providers、工具、cron、记忆、技能、沙箱拼到一起,形成了一个足够完整的个人智能体运行时。没有这一层,模型能力很难稳定地进入真实工作。
成本则决定了这件事能否扩散。智能体的 token 消耗远高于 chatbot。如果一次复杂任务成本极高,它只能服务少数高价值场景。但当中层模型、本地模型和端侧模型可以借助好的框架提升上限,智能体的成本结构就会发生变化。好的框架不只是释放最强模型,也会给普通模型更大的发挥空间。
这也是许多中国模型公司会在 Claw 浪潮里受益的原因。MiniMax、Kimi 等厂商擅长正是在中小型模型、长上下文、低价推理和产品化分发之间找到更好的性价比。一个被 Opus 这类旗舰模型、或者被社区高强度使用打磨过的 routing、记忆、技能和工作流,可以被更便宜的模型复用。旗舰模型负责探索上限,社区把路径沉淀下来,中小模型再以更有竞争力的价格承担大量日常任务。
这会改变“好模型”的定义。在很多日常场景里,用户不一定需要最强模型从零开始思考;他们需要的是一个足够好的模型,站在一个已经设计好的智能体框架里,把邮件、资料整理、轻量研究、项目维护、信息监控这些任务稳定做完。框架越成熟,中小模型的上限就越容易被激发,API 价格优势也越容易转化为真实 adoption。
最后,用户心态也在默默转变,开发者和高阶用户正在接受让智能体进入本机、消息系统和真实工作流。2023 年时,这件事还像冒险;到了今天,Claude Code、Codex、Cursor 等工具共同改变了用户对“把事情交给机器做”的预期。
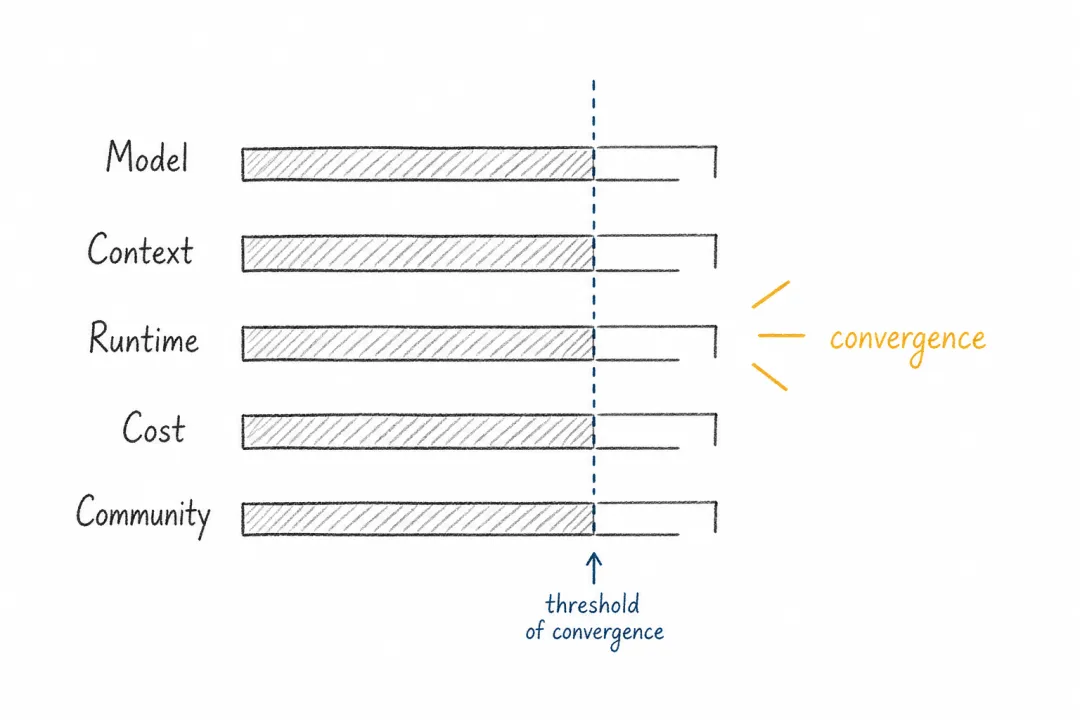
OpenClaw 的时间点来自五个条件同时成熟。
所以,OpenClaw 的成功不是因为它突然发明了智能体,而是因为它在正确的时间,把几个正在成熟的条件组合在了一起。
更深一层看,大模型竞争正在从 Chat 时代进入智能体时代。Chat 时代关心模型是否会聊天、会推理、会写代码,基准测试分数是否足够高。智能体时代的问题变成:模型能否在复杂工具环境里端到端完成长程任务;能否使用记忆、技能、subagents;能否处理失败、恢复、验证和人工反馈;能否把用户纠错和任务轨迹吸收进后训练。
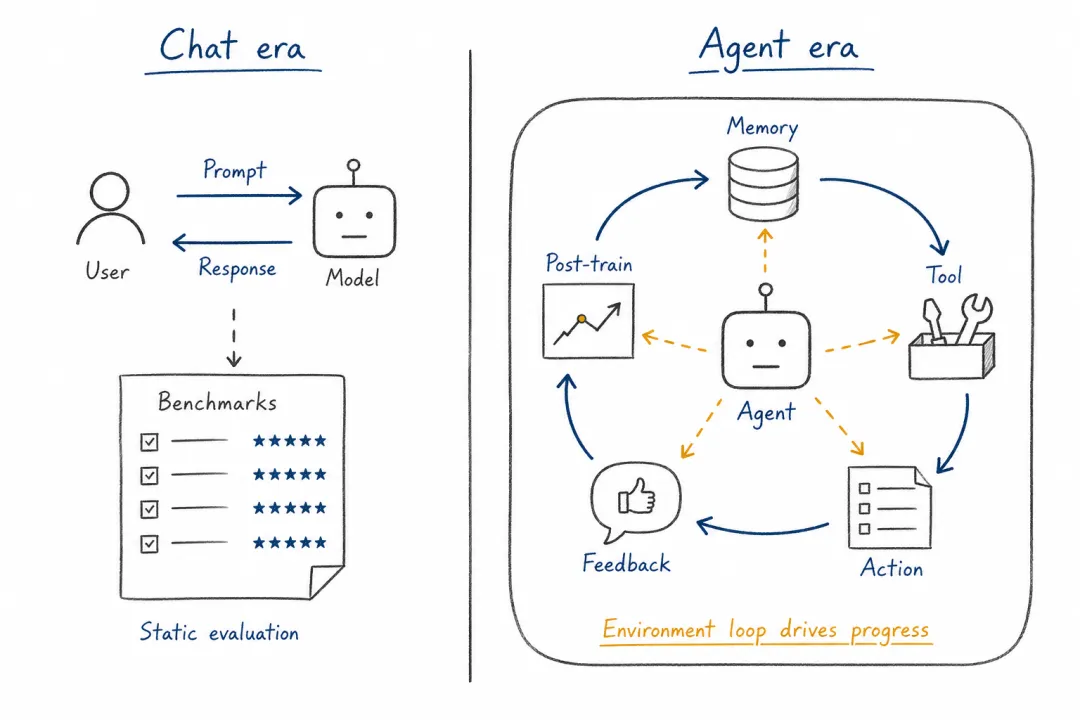
从 Chat 时代到智能体时代,后训练对象发生了变化。
这意味着智能体后训练不只是多跑几轮 rollout。它需要完整环境:智能体框架、工具、记忆、技能、模拟用户、奖励、验证、失败恢复,以及 CPU/GPU/storage scheduling。OpenClaw 的意义在于,它提供了一个真实场景,让模型、框架、人类经验、任务轨迹和后训练需求如此集中地碰到一起。
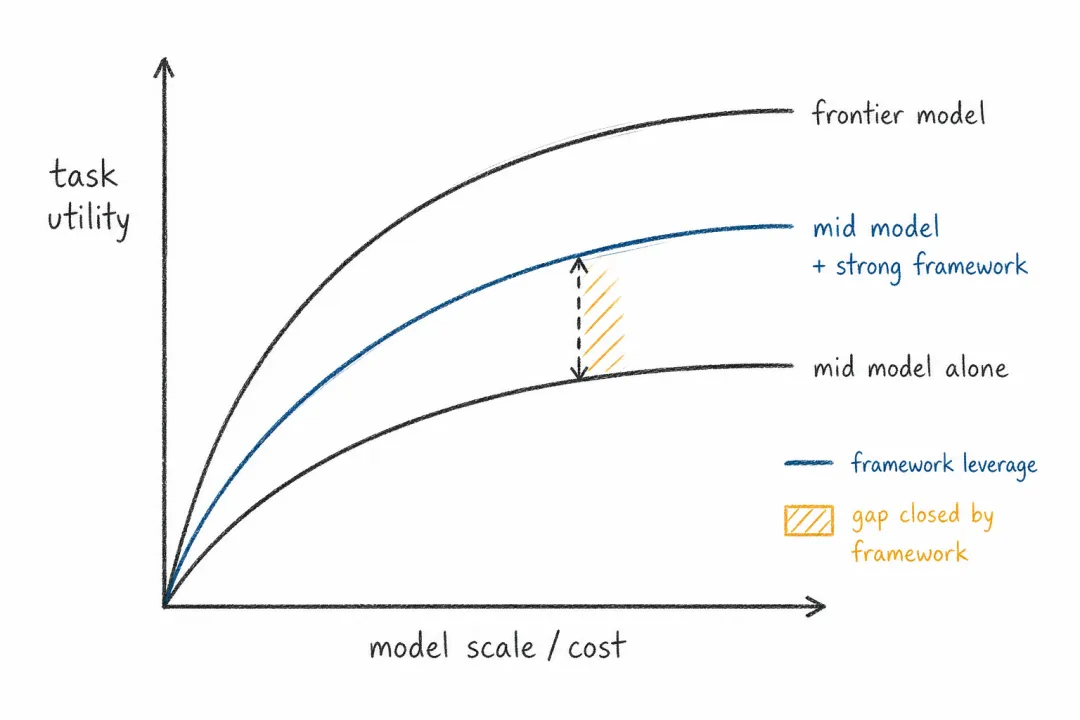
好的框架会放大模型能力,尤其是中层模型的上限。
开源属性在这里变得关键。黑盒产品可以优化体验,但开源框架允许用户改记忆、技能、routing、provider、工作流和安全策略。更重要的是,它让用户不只是使用者,而是框架的共同作者。失败案例会变成 issue,个人经验会变成技能,使用过程会变成数据生成过程,框架本身也会成为社区一起迭代的对象。
OpenClaw 和 Hermes Agent 的 Discord channel 提供了一个很好的剖面。开发者语音频道可以连续数百个小时有人在线交流,OpenClaw 的 release 在高峰时一天能发四五个版本,contributor 接近两百人。这样的规模和热情,在一个仍然很早期的智能体框架上非常罕见。
更有意思的是,这个社区正在形成一种自循环。Claw 变得越好用,开发者就越愿意用 Claw 来维护自己的项目;而当他们发现 Claw 可以帮助读代码、修 bug、写技能、整理 issue,又会更自然地让 Claw 参与 Claw 自身的项目维护。表面上是人类在改一个工具,实际上越来越像是以 Claw 为主体的迭代回路:模型和框架负责主要的信息处理,人类更像一种湿件层,负责授权、判断、验收和少量程序性操作。
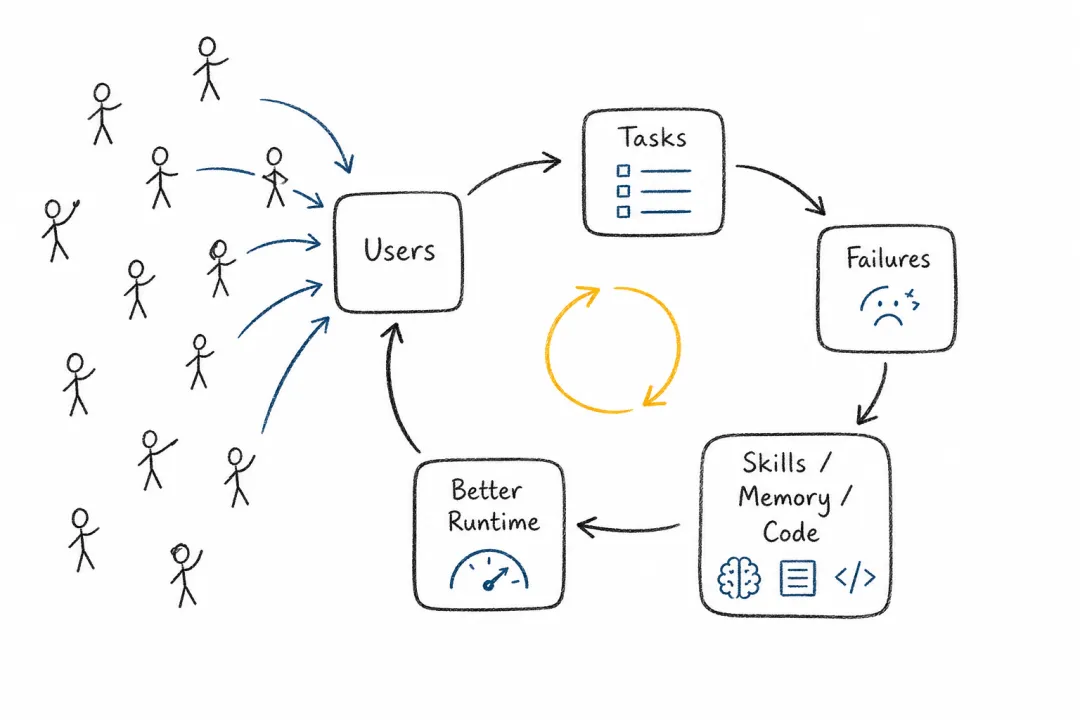
COMPANIES V.S. COMMUNITIES
大厂和社区真正争夺的层级
开源让用户从使用者变成框架共同作者。
OpenClaw 没有发明 computer use,但它把需求压到了大厂面前。各家公司后续动作看似分散,实则围绕几个层级展开:用户入口、模型调用和计费、安全运行时、技能与数据分发。
OpenAI 的方向更接近个人智能体控制中心:把长期任务、并行智能体、桌面操作、记忆和任务管理纳入自己的产品体系。它想争的是用户把复杂任务交出去时的默认入口。
Anthropic 的优势在高可靠模型和 computer use 能力,但它也必须处理智能体工作负载带来的成本与风险。智能体的使用强度远高于普通聊天,因此 API 边界、订阅规则、工具权限和企业策略会变成商业核心。
NVIDIA 更像是在争企业安全运行时。一个持有大量系统权限的智能体想进入企业环境,就必须有沙箱、policy、network/filesystem control、inference routing 和审计机制。NVIDIA 抢的不是聊天入口,而是企业部署时的安全和推理基础设施。
GitHub 则天然适合争技能分发标准。当技能从某个项目内部机制变成跨 host 的任务知识包,GitHub 这样的平台很容易成为 registry。未来智能体生态可能形成一种新结构:模型是能力底座,运行时是执行环境,技能是可流通的任务知识,平台负责分发、版本和信任。
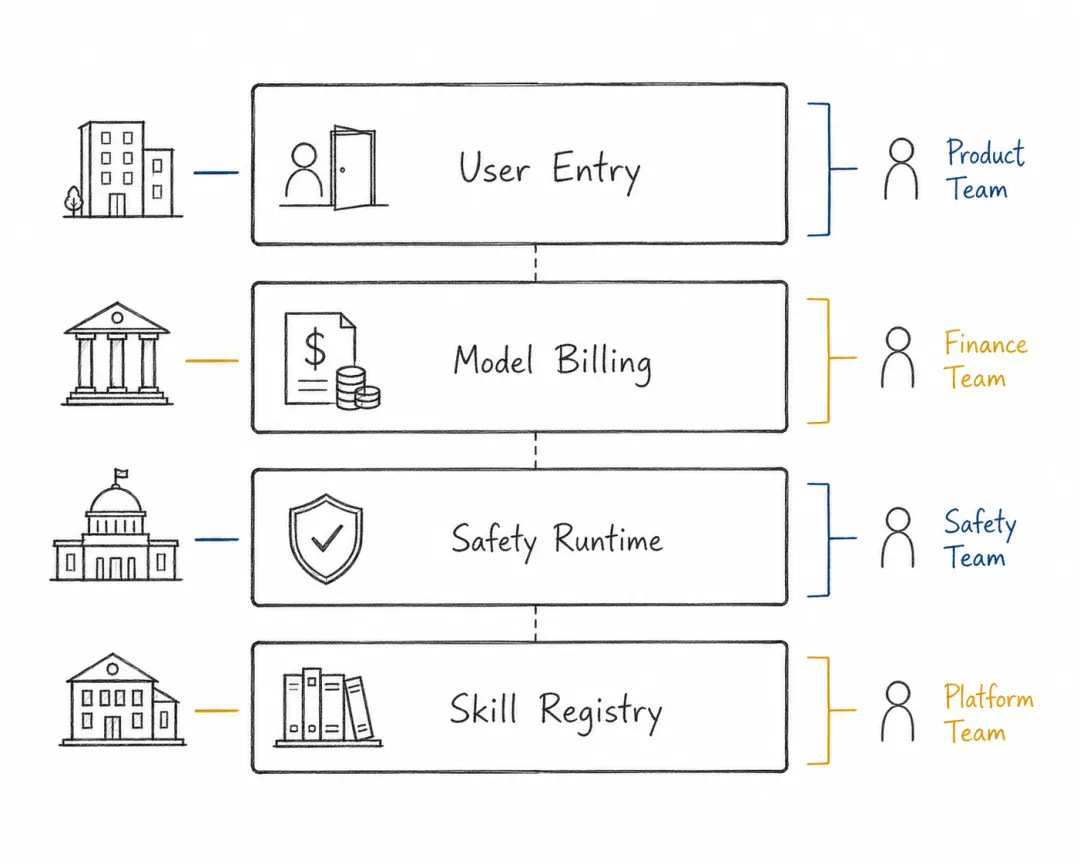
产业竞争围绕四层控制权展开。
社区侧的后续工作也在变化。OpenClaw 更像 gateway-first:先把智能体放进用户日常入口,让它能长期在线、接收委托、调用工具。Hermes Agent 等后续项目则更像 learning-loop-first:强调智能体整理的记忆、自动生成技能、轨迹压缩、subagents、批量轨迹生成和 RL 环境。
这说明社区焦点正在从“能不能连到聊天 app”,转向“长期使用后是否能够学习、压缩、迁移和自我改进”。如果 OpenClaw 把智能体带进真实工作流,那么下一批系统要回答的是:智能体怎么从真实工作流中变强?
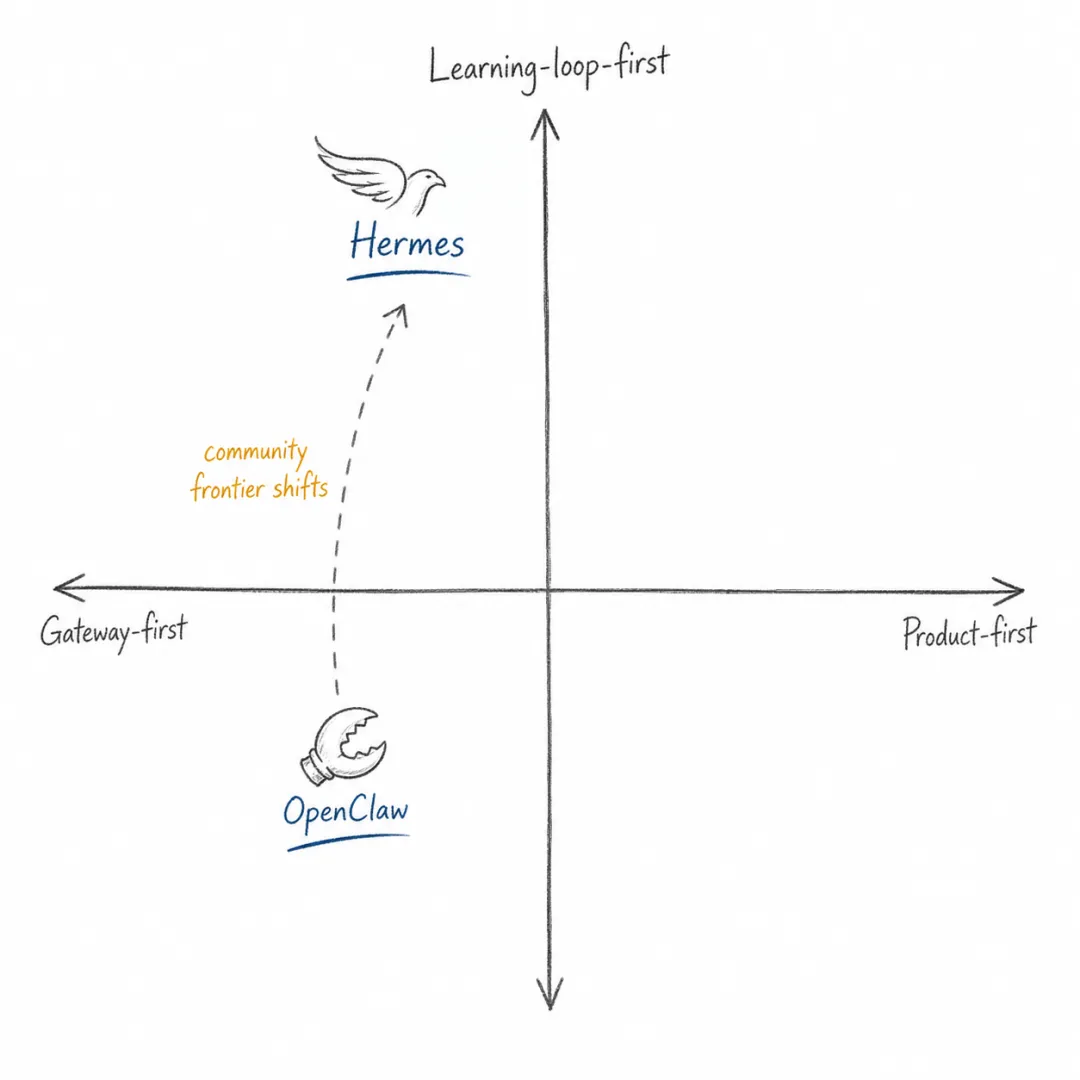
社区焦点正在从 gateway 转向 learning loop。
TASKS TRAJECTORIES
真正稀缺的是任务轨迹
下一阶段真正要 scaling 的对象,不是“再做一个 OpenClaw”,而是 OpenClaw 所暴露出难题的解决方案。
最直接的是智能体后训练。模型需要在复杂框架里端到端完成任务,而不是只在静态基准测试上得分。研究者需要真实长程任务、可复现环境、用户模拟、工具轨迹、成功/失败标签、人工纠错和奖励信号。
记忆也会成为长期问题。长期智能体不能无限堆上下文,也不能把所有旧信息都当作真理。它必须知道什么值得记、什么应该忘、什么已经过期、什么存在冲突,以及哪些记忆实际提高了任务成功率。
还有技能和工作流数据。预训练拿不到企业内部流程、个人偏好和团队规范。这些知识只有在真实任务中被显式化,才可能成为可复用资产。
而所有这些能力要真正进入高价值场景,运行时安全就绕不过去。权限被放大之后,提示词注入、credential leakage、工具误用和恶意网页都不再是小问题,而是系统风险。运行时必须在模型不完全可靠时,仍然保证不会造成不可接受的损害。
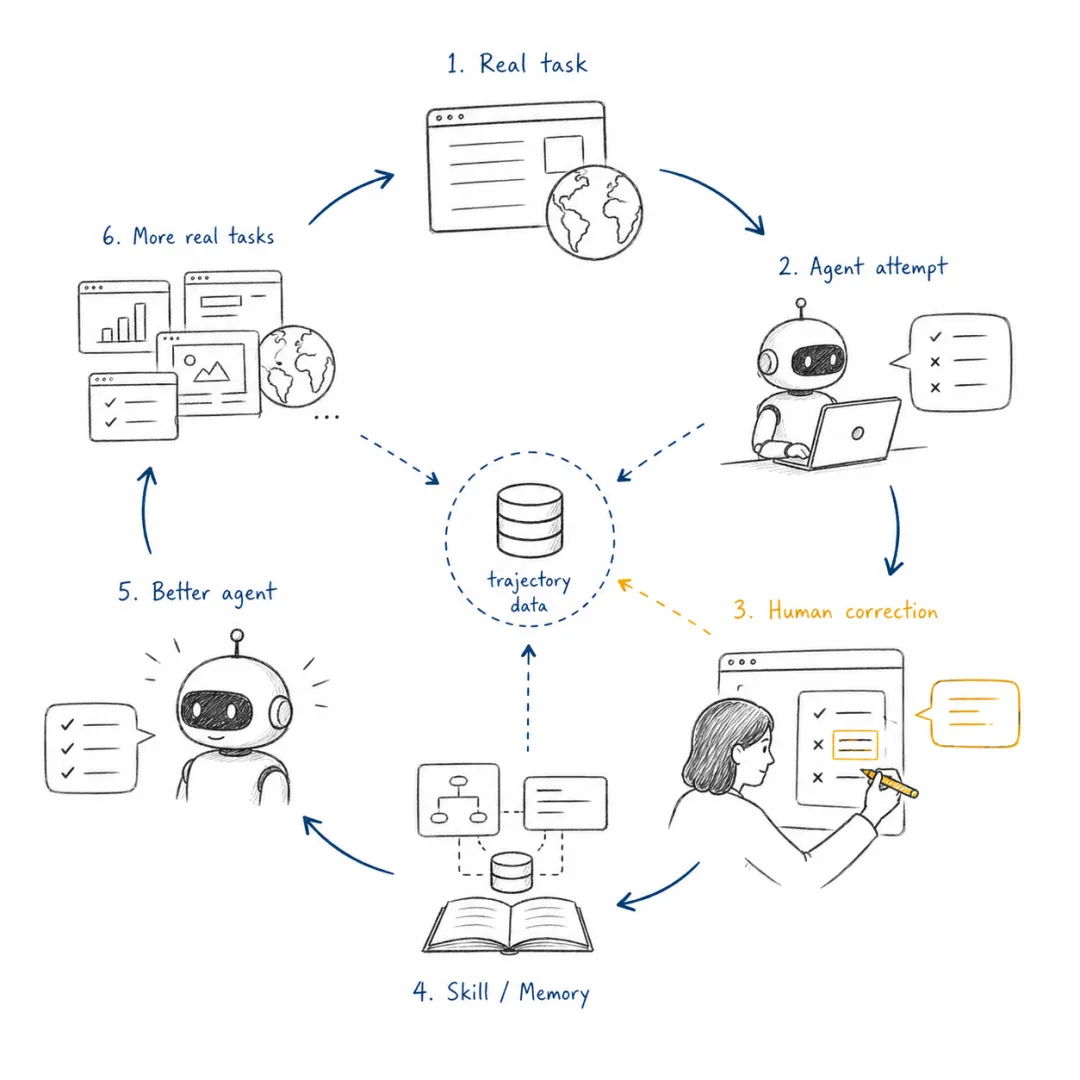
真实任务轨迹会成为智能体时代最稀缺的数据。
如果说 Chat 时代的关键数据是公开文本、代码和人类偏好反馈,那么智能体时代更稀缺的数据是任务轨迹:用户如何委托任务,智能体如何分解任务,工具调用在哪里失败,人如何纠正,哪些记忆被证明有用,哪些技能提高了成功率,哪些安全策略阻止了危险动作。
这类数据很难从互联网上直接抓取,也很难在静态数据集中完整构造。它只能来自真实使用、可复现环境和长期交互。这正是 OpenClaw、Hermes Agent 这类运行时的长期价值:它们不仅是应用入口,也是智能体时代数据生成和后训练问题生成的机器。
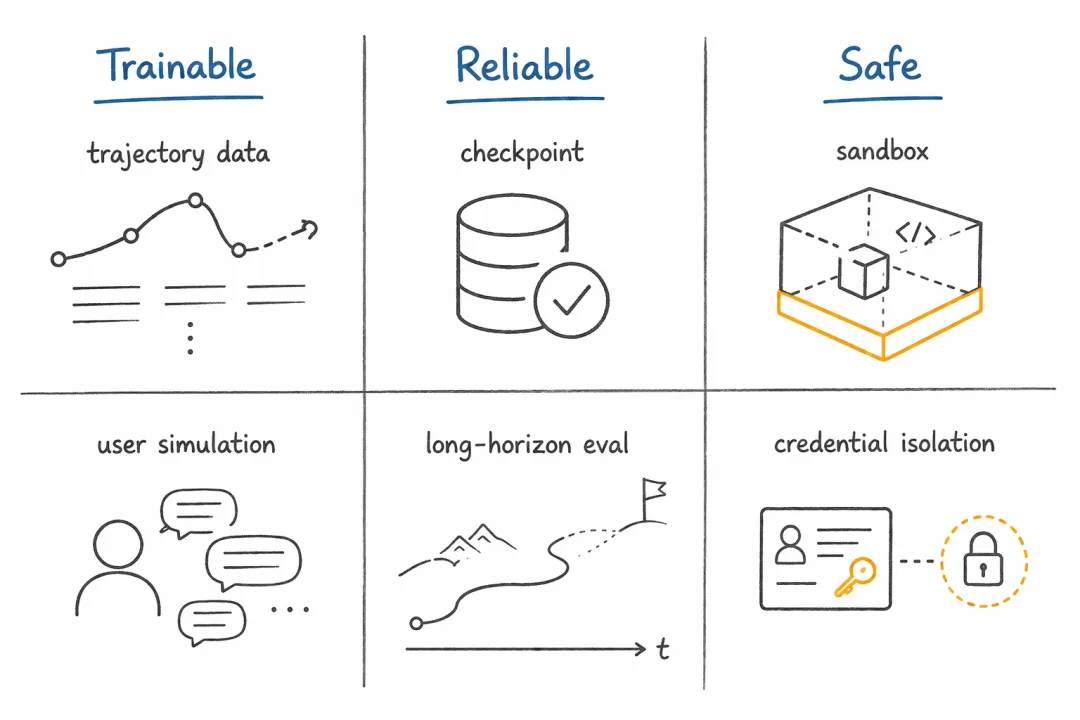
未来的智能体必须同时可训练、可靠和安全。
因此,后续值得做的工作其实非常具体。运行时安全需要权限 manifest、密钥隔离、审计轨迹、rollback 和审批流程;长程任务可靠性需要 checkpoint、retry、side-effect classification、verification 和 recovery;记忆评估需要判断记忆是否正确、过期、冲突、可召回、能降低成本;技能质量控制需要 provenance、versioning、capability declaration、eval harness、签名和信任模型;智能体后训练数据集需要真实长程任务、环境回放、多轮交互、用户模拟和轨迹压缩。
FUTURE OF AGENTIC AI
智能体 AI 的下半场
OpenClaw 做对的不是某一个单点技术,而是把一组原本分散的机制组织成了一个可运行、可修改、可积累的系统。
它把智能体放进日常消息流,而不是专用网页;它用 daemon、会话、cron 和工具让智能体成为长期在线的工作进程;它用 Markdown 记忆和 workspace conventions 让状态可审计、可修改、可沉淀;它用技能把人类经验和组织规范变成可执行经验;它用开源机制让高阶用户、模型和框架一起进化。
大模型的上半场,是扩展模型本身:更多参数、更多数据、更长上下文、更强推理。智能体 AI 的下半场,则是扩展模型与世界之间的通信:更好的运行时,更真实的任务数据,更可靠的记忆,更安全的权限边界,更可迁移的技能,以及更适配智能体的后训练。
OpenClaw 不是智能体时代的终局产品。它更像一个把问题照亮的窗口:让我们看清楚下一阶段真正困难、真正有价值、也真正值得研究的问题在哪里。
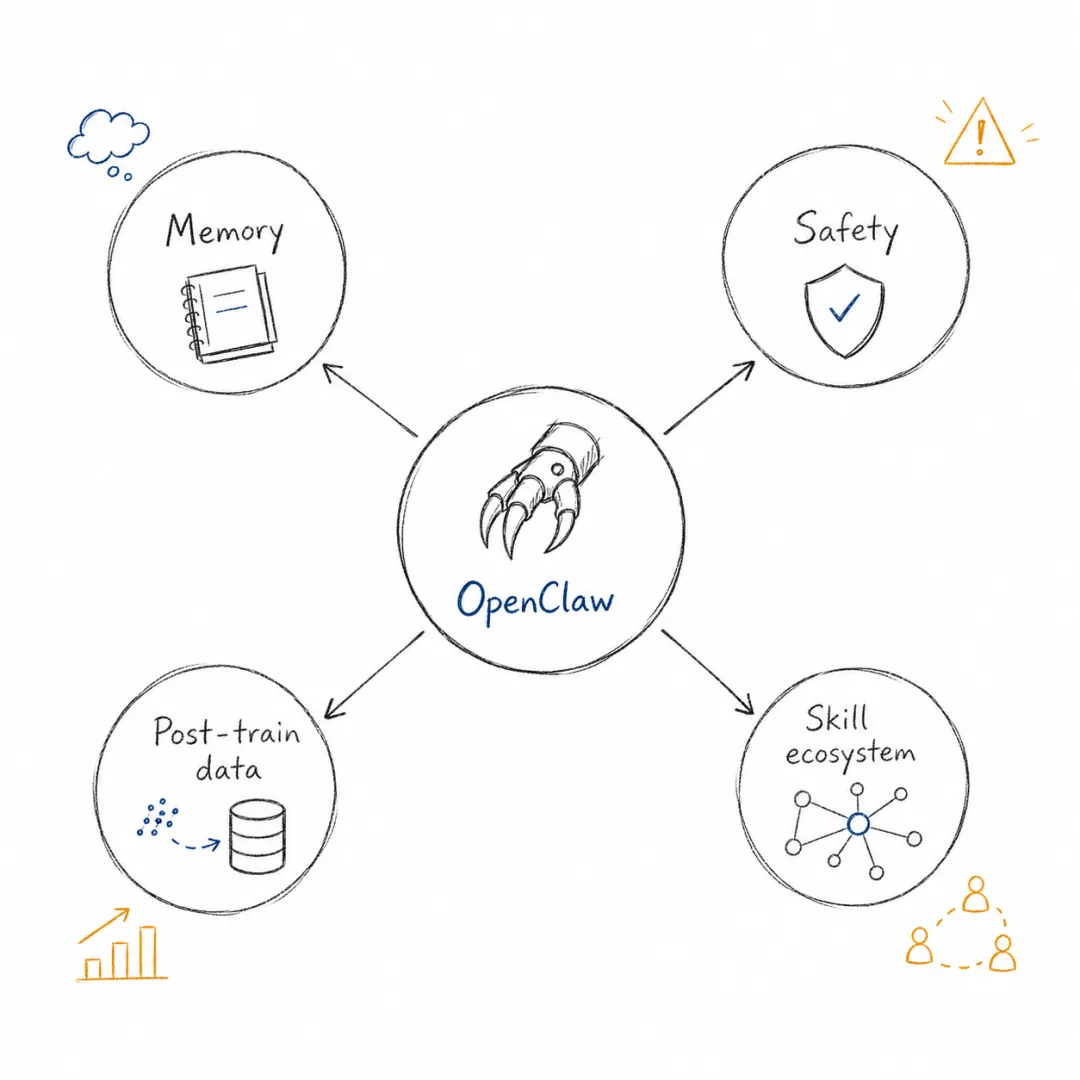
OpenClaw 留下的不是答案,而是一组更清楚的问题。
最后可以把问题留给自己和社区:个人智能体的默认入口会是聊天 app、浏览器、OS、IDE,还是某种 always-on device?技能会不会成为智能体时代的 app store?真实智能体后训练数据会来自开源社区、企业工作流,还是模型公司的闭环产品?记忆的终局是更长上下文、更好的检索,还是 continuous learning?Local-first 智能体的安全边界应该由模型、运行时、OS、企业 policy,还是硬件共同定义?
这些问题不会因为某个产品爆火而自动解决。但 OpenClaw 至少让它们从抽象讨论,变成了可以被工程化、被实验、被迭代的具体问题。


顶尖平台 招贤纳士
ABOUT CPIL & JOIN US
Cyber-Physical Intelligence Lab 深耕于 MBZUAI、麦吉尔大学 (McGill University)、Mila (Quebec AI Institute) 三大顶尖科研平台。我们拥有卓越的全球产学网络,长期与 Google, MSR, Meta, Amazon, Tencent 等科技巨头深度联动。实验室常年开放博士、博后、访问学者及实习生席位,学术交流与项目合作欢迎在公众号后台私信对接!或请电子邮件联系:
何博威: bowei.he@mbzuai.ac.ae
吴昊伦:haolun.wu@mail.mcgill.ca
袁野: ye.yuan3@mail.mcgill.ca

CPIL
微信公众号丨CPIL赛博物理实验室
小红书丨CPIL