 夜雨聆风
夜雨聆风





AI工作流真正拉开差距的,不是生成能力,是验收能力

不是官方图,是AI做的。但它不像以前那种一眼能看穿的AI图——有商品,有版式,有品牌露出,甚至通过模型的推理能力设计出了两个品牌的联名饮品。你知道它是假的,但你初看不会觉得它很假。
这张图不是重点。重点是它发出的信号:广告视觉的表层语言,AI已经能模拟了。品牌露出怎么排,产品关系怎么放,版式秩序怎么做,拍摄质感怎么给——它不一定理解,但它能做出那个样子。
对普通人这是段子。对做品牌和campaign的人来说,这值得认真对待。
但今天我想问的不是AI能不能画图。我想问的是另一个问题:当AI能把一个还没想清楚的方向,包装得像能提案,你还能不能判断它到底对不对?
中间生产层,被AI补上了
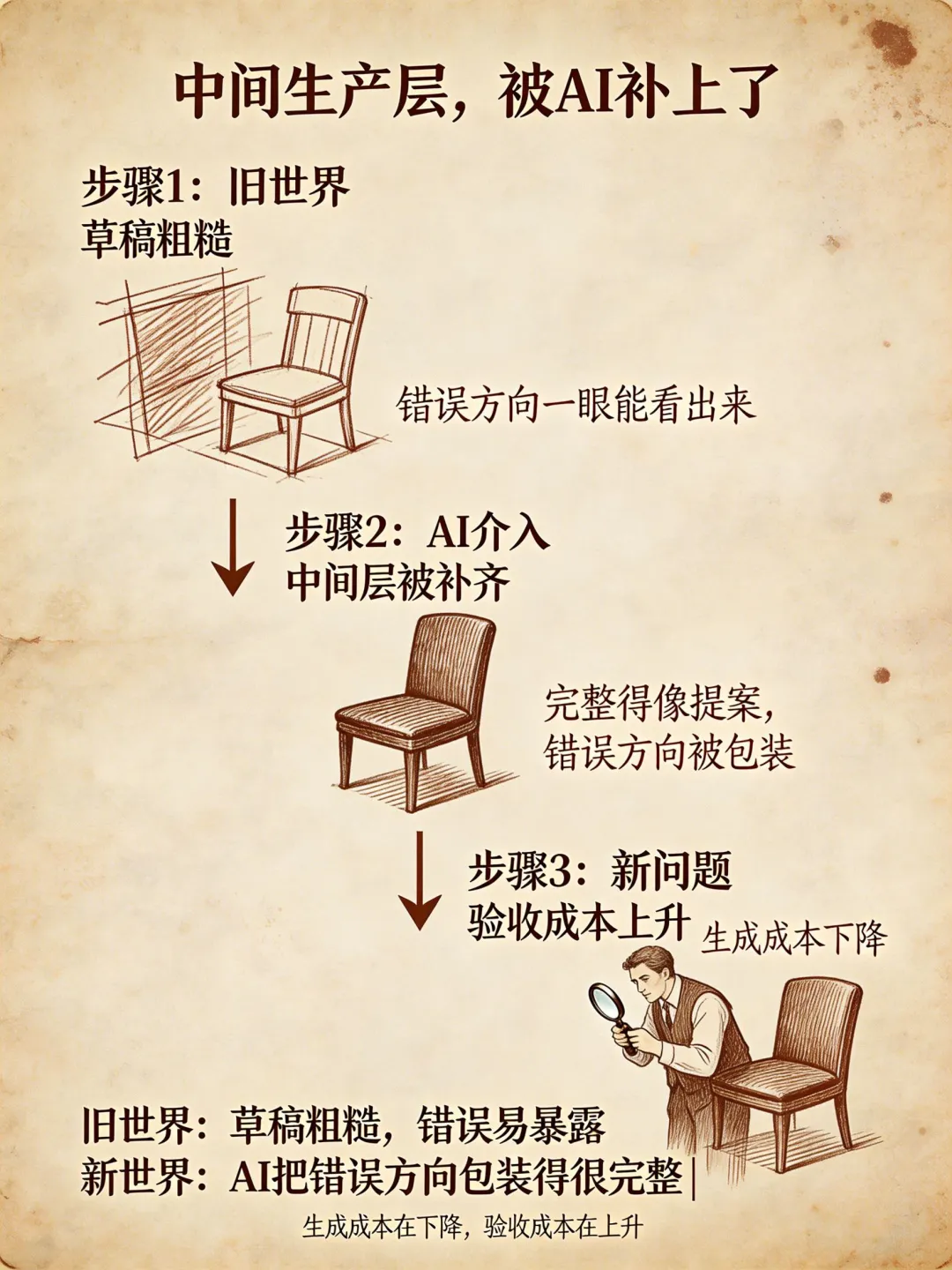
我先说一个词——中间生产层。
以前要把一个还没发生的campaign做得像它已经存在,靠的是设计师用经验一层一层垫出来:找参考、拼图、修图、调色、排版。这些不是战略,不是大创意,但它是让方向能被看见的必要劳动。
AI进来之后,被压缩的就是这一步。
有设计师把Image2投进真实工作,两天做出了三条风格线、四个可讨论画面。一条插画感,一条实拍广告感,还有一条超现实特摄感。四张完成度极高的KV,每条风格线都不是草稿——从模糊想法推到三种完整的视觉语法,只花了两天。
这不是提效。这是中间生产层被直接补上了。
旧世界里,草稿是粗糙的。粗糙有粗糙的好处:错误方向一眼就能看出来——构图不对,比例失调,调性跑偏。但现在AI可以把这些粗糙的部分补齐,让一个还没想清楚的方向,看起来像已经执行完毕。
生成成本在下降。验收成本在上升。
这是AI时代工作流里最容易被忽视的一个转折。
体面的错误,比粗糙的错误更危险

这里有一个反直觉的机制,我把它叫做”体面错误陷阱”。
商业设计里,很多坏方案不是丑死的,是”挺好的”。它看着完整,看着能提案,看着能发群。没有明显错误,所以大家很容易让它往下走。但它可能只是品类平均值——平台上见过一万次的广告感,一个不会出错、也不会留下记忆的方案。
Image2擅长的,正是快速生成这种东西。
它会补齐元素、拉满质感、把画面做得完整,光影调得像正经广告。但它很少会主动问你:这个活动为什么非得是这个品牌来做?这个画面有没有一个能被消费者记住的动作?
更危险的是:以前一个错误方向可能死在草图阶段——太粗糙,大家很快发现不对。现在一个错误方向可以穿上完整的衣服出现在会议里。
它有光影,有人物,有文案区,有社媒封面,甚至有一套看起来成体系的资产。它不一定更正确,但它更有说服力。
视觉完成度会制造心理上的沉没成本——当一张图看起来已经投入了很多,你就更难开口说它不对。
体面之后,否掉它就需要更强的理由。你否掉一张粗糙草图,大家很容易接受;否掉一张看起来已经很完整的图,就得说清楚它到底哪里不对。
不能只说”我觉得不对”。要说出主动作不清楚、活动记忆点不够、视觉语言太像竞品。
换句话说,AI不是让设计师不用解释了,是让设计师更需要解释。
这个机制,不只在设计圈成立。
代码、内容、策略——任何一个AI能加速执行的领域,都面临同一个问题:生成快了,验收没有变快。AI把执行成本降下来了,但把判断成本顶上去了。
新10x工程师,不写代码
Karpathy在一次演讲里提到一个判断,我越想越觉得对。
他说,新的10x工程师,不是会写代码的人。
是会做这五件事的人:规范、监督、审查、评估、权限管理。
没一件是写代码本身。
规范,是定义什么该做、什么不该做。监督,是确保执行过程符合预期。审查,是判断产出是否真正解决了问题。评估,是建立一套标准来衡量质量。权限管理,是决定谁来承担决策后果。
你仔细看这五件事——每一件的核心都不是”生成”,而是”判断”。
这条线在AI Agent的设计领域也有印证。真正做过多Agent系统的人都知道,最难的不是让Agent调用工具、并行执行、协同工作。最难的是:当多个Agent各自产出结果,你信哪个?你怎么判断它们各自的输出质量?你怎么知道什么时候该让人介入,什么时候该让流程继续?
代理式AI公司的实践者给过一个判断:评估、监控、黄金数据集、失败回归测试,比追新框架重要十倍。他们的意思是:当你有了一套可靠的评估体系,你可以用任何新框架;没有这套体系,任何新框架都可能带着你走向错误的方向。
AI使用水平有一个十级分层,Level 6是一个明显的分水岭。
Level 5以下是”会用工具”:掌握基础提示,能完成日常简单任务。Level 6是”会用系统”:系统化设计提示,多轮迭代,像指挥AI一样工作。Level 7是”会用流程”:AI深度嵌入工作流,能自优化提示并自动化重复任务。
从Level 6开始,分界线已经不是”会不会用工具”了。
是”有没有能力判断AI的输出质量”。
Skill化之后,最难的是判断能不能发
我拿自己的内容工作流举个例子。
今年我把公众号写作流程Skill化了——一次写好Bingo公众号写作Skill,包含账号定位、读者画像、内容标准、审核标准。以后每次写稿,触发Skill,AI自动按规则工作。
效果是明显的:生成速度提上来了,结构一致性提上来了,格式规范性也提上来了。
但真正卡住我的,不是让AI写出一版。
是判断这版能不能发。
AI可以生成标题,但它不知道这个标题有没有偏离Bingo的主轴——AI工作流、自动化实战、内容系统、项目复盘。它可能写出一个传播性很强、但跟我这个账号定位完全无关的标题。
AI可以生成正文,但它可能写成一篇泛AI认知文——讲的是”AI时代判断力很重要”,而不是”Bingo研究的是工作流节点”。读者看完只记住”判断力重要”,不记住”这是那个做AI工作流的人写的”。
AI可以生成CTA,但它不知道我承接的是咨询还是订阅还是其他什么路径。
每一次验收,都是在问这几个问题:它有没有偏离我的主轴?它有没有写成公共答案?它有没有作者痕迹?它有没有承接下一步?
这些判断,AI帮不了我。
最终那一步——敢不敢点发送——还是得有人来判断。
我越来越觉得,一个工作流跑不跑得通,最后看的是验收节点,不是生成节点。
AI输出验收五问
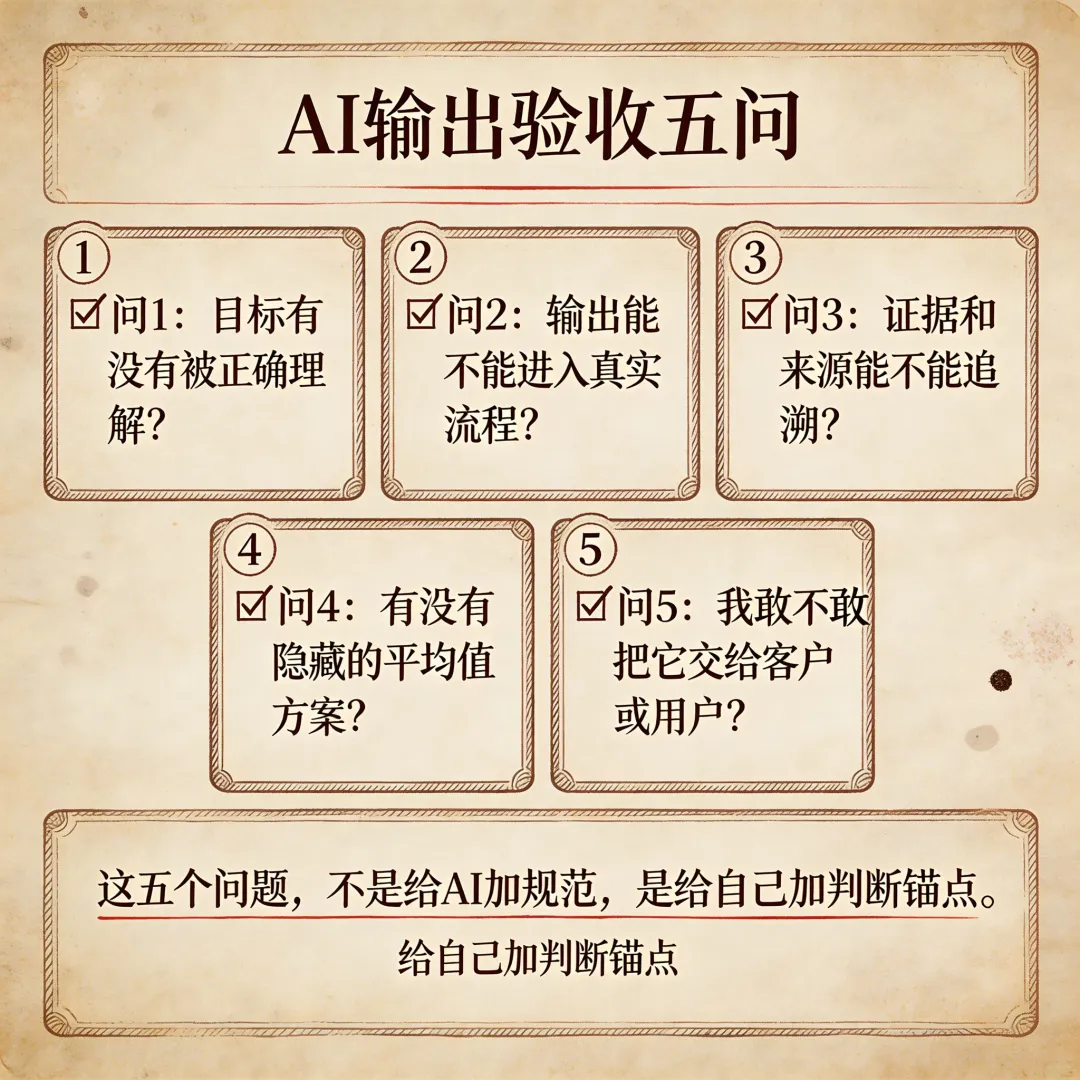
从Skill工作流里,我提炼出五个问题,每次验收AI输出时都会过一遍。
第一个:目标有没有被正确理解?
不要只问AI”你觉得对不对”。要问:它有没有理解我真正想解决的是什么?有时候AI给出了语法正确、结构完整、格式规范的输出,但它解决的是另一个问题。验收第一步,是确认输出针对的是正确的问题。
第二个:输出能不能进入真实流程?
AI擅长生成,但它不知道你的下游是什么。这版内容能不能直接发?还是需要人工调整才能进你的发布系统?需要调整的部分有多大?如果调整成本过高,这个输出就还没有真正完成。
第三个:证据和来源能不能追溯?
AI有时候会生成看起来很权威但实际上没有来源的内容。尤其是涉及数据、案例、引用的时候,过一遍来源,比接受结论更重要。验收不是接受输出,是核实输出。
第四个:有没有隐藏的平均值方案?
这一问我从Image2那篇文章里学到的。AI倾向于生成”品类平均值”——平台见过一万次的那种广告感,不会出错但也不会留下记忆。每次验收,我会问自己:这版有没有品牌记忆点?还是只是AI觉得最安全的选择?
第五个:我敢不敢把它交给客户、用户或下一环节?
这是最简单也最有效的一问。如果我自己作为交付者,都不敢把这个输出交给下一个环节,那它就没有完成。不要因为AI花了时间就不好意思否定它。
这五个问题,不是给AI加规范,是给自己加判断锚点。
规范是给AI的规则,判断是给自己留的决策空间。
AI时代,生成能力会越来越便宜。判断能力不会。
AI降低生成的门槛,没有降低验收的门槛。
它把做事情变快了,但没有让做对事情变容易。
下一篇文章,我把这五个问题拆成一个可以直接用的验收清单——不是方法论,是可以直接Copy进你工作流的检查项。