夜雨聆风
夜雨聆风





《桃花源记》转AI视频V4:角色一致性

主角终于不再“变脸”了
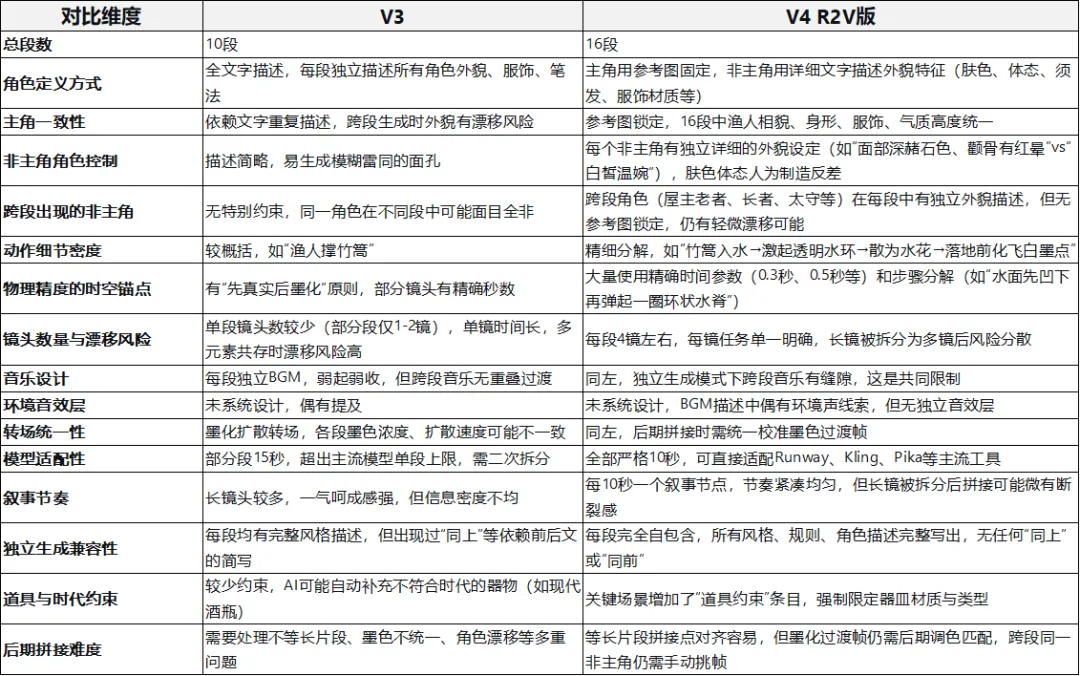
做过AI多段视频的人应该都有体会,最头疼的问题就是主角的长相稳不住。上一段还是清瘦的渔人,下一段可能就变成了圆脸大叔,甚至胡茬都莫名其妙长出来了。在V3版本里,我只能在每一段都用大段文字去描述这位渔人——什么年龄、什么脸型、穿什么衣服、用什么笔法勾线。即便如此,AI还是会跑偏,因为每次生成都是独立的,它并不真正“记得”上一段渔人长什么样。
在1V4版本里,我用了参考图模式。渔人从一开始就被一张固定的人物图锁定了,每一段开头只需要调用这个参考图就可以,不必再花大量篇幅去重复他的长相特征。省下来的描述篇幅,全部给了动作和表情。于是你会在画面里看见:他撑船时手臂肌肉轻轻跳动,呼吸时胸膛微微起伏;遇见桃花时惊讶得半张着嘴,告别时喉结上下滑动过一次——这些在10段版里根本不敢写这么细,因为没有那么多字数空间。
动作描写分解得更细了
整部视频有一个贯穿始终的风格规则,叫做“先真实后墨化”。意思是什么东西都得先像真的一样运动,然后再逐渐变成水墨的笔触和墨迹。V3版已经有这个意识了,比如花朵先粉嫩飘落,然后才化成胭脂墨点;水花先溅起,再变成飞白墨点。
V4版在这个基础上把很多关键动作的物理过程拆得更细了。举个例子,有一组“露珠入水”的镜头,描述是这样写的:露珠沿着叶脉往下滑,由于重力被拉得变形,尾部还紧贴着叶面;滑到叶尖停了0.5秒,攒够重量之后,底部与叶面的附着力突然断开,露珠坠落,在空中保持球形,表面反射光斑;砸进水里时,水面先被压出一个极短暂的凹坑,紧接着弹起一圈环状水脊;水脊向外扩散的过程中,顶部从透明逐渐变成淡墨色,最终化为一圈墨环继续扩散。这些精确的步骤分解和时间标记,不是为了炫技,而是为了让AI在生成时有一个清晰的执行顺序,不至于把“墨化”做成一个生硬的滤镜切换。
发现并解决了很多“AI幻觉”问题
在反复生成的过程中,我发现了一些很有意思的“AI幻觉”。比如在夜宿桃源的片段里,残席的木桌上明明应该只有粗陶碗和瓦罐,但AI好几次自动生成了一个现代玻璃酒瓶——因为在它的训练数据里,“宴席+酒”最常见的就是酒瓶。这个问题在V3版里是没有额外约束的,AI想当然就加了进去。
在V4版里,我对这类关键场景增加了专门的“道具约束”。还是以夜宿桃源为例,我加了一条强制规定:所有器皿只能是粗陶碗、粗陶盘、瓦罐、竹筷、木勺,不得出现玻璃、瓷质、金属器皿,不得出现任何瓶状容器。并且把桌上每一件物品都列了出来。这样约束之后,生成的画面就完全符合魏晋时期的设定,不再冒出奇怪的现代物品了。
当然,目前还有不少不足之处
最遗憾的一点是音乐。因为是独立生成,每一段视频的配乐都是各自为政的,没办法像电影配乐那样让上一段的尾音自然地流进下一段。虽然我在设计时让每段音乐都“弱起弱收”,尽量做出收束感,但拼接在一起时还是能听出段落之间的缝隙。这个目前只能靠后期音频软件手动拼接来补救。
其次,那些极其精细的物理变化——比如“0.3秒后水纹转化为墨环”——在实际生成时,AI并不一定能完全精确地还原。有的片段水花墨化做得非常漂亮,有的就只是普通的扩散了一下。这种不稳定,目前没有太好的办法,只能多生成几次从中挑选质量最好的那一次。
还有,非主角的角色虽然在单个片段里描述得很详细,但因为毕竟没有参考图锁定,同一个老者在不同的片段里出现时,脸还是可能不完全一样。比如在“老幼怡然”那一段和后来“渐入告别”那一段,虽然都是我描述的那个“须发皆白、眼窝微陷”的老者,但AI两次生成的面部细节会有出入。一次性出现的角色问题不大,超过两次就需要参考图了。
转场虽然统一用了墨化扩散,但不同片段生成的墨色浓淡、扩散速度不太一样。V4拼在一起连续播放时,细心看会察觉到某些段落过渡的地方有一点点生硬。如果需要追求极致流畅,就需要在后期统一校色,或者给每一段的首尾连接处单独做一层淡墨过渡。
最后说两句:流程固化
做这套视频的整个过程,很像是在为AI写一本极其详细的导演分镜剧本,同时还要兼顾画家的水墨技法、道具师的时代考据和配乐师的谱曲。我最大的感受是:AI能理解诗意到哪一步,很大程度上取决于你给它的指令有多精确。当你说“花瓣飘落化为墨点”,它可能做得很粗糙;但当你把整个过程拆解成变形、停留、滴落、涟漪、拉伸、墨化这六个具体步骤,并且给每一步都标上时间的时候,它就真的有可能给你一处相当动人的水墨瞬间。
每次优化需要不少时间,有没有一种方式固化下来,让人的干预做到最少呢?
所以我做了一个平台,设计了20+智能体协作完成者一个过程,目前核心引擎已经完成开发。