 夜雨聆风
夜雨聆风





给Hermes/openclaw/装一个大脑,它好像变聪明了

🗣️ 上周五晚上,跟一个用 AI 的朋友聊天。他跟我说:
“用龙虾1个月了,有个问题始终解决不了——我跟它聊过的项目背景、踩过的坑、做过的技术选型,下次开新对话全忘了。每次都要从头解释,一上午就交代背景了。”
💬 你一定遇到过这些时刻
AI 天然就没有长期记忆。
大模型靠”上下文窗口”工作——你可以理解为它的内存。每次对话,AI 只看你这次塞给它的内容。窗口关了,它就忘了。上下文窗口再大,也是临时的、短期的。
真正的问题是:
你希望 AI 记住的那些东西,不是这一轮对话里的信息,而是跨越时间积累下来的、关于你、你的项目、你的行业的”知识”。
这和 RAG 还不太一样。RAG 是”检索增强生成”,本质上是把文档扔给 AI 看。但你真正需要的不是让 AI 看到更多文档,而是让 AI 理解这个人、这家公司、这笔交易、这个项目,在过去发生了什么,现在处于什么状态。
这是两种完全不同的需求。
🧠 什么是 gbrain
gbrain 是 Garry Tan(Y Combinator 合伙人)做的一个开源工具,核心定位是:
🤯 AI 的外部记忆层
它解决的问题很简单:让 AI 在回答任何问题之前,先查一下它已经知道的东西。
听起来理所当然?但这件事以前没有人认真做好过。
GBrain想解决的就是这个事。
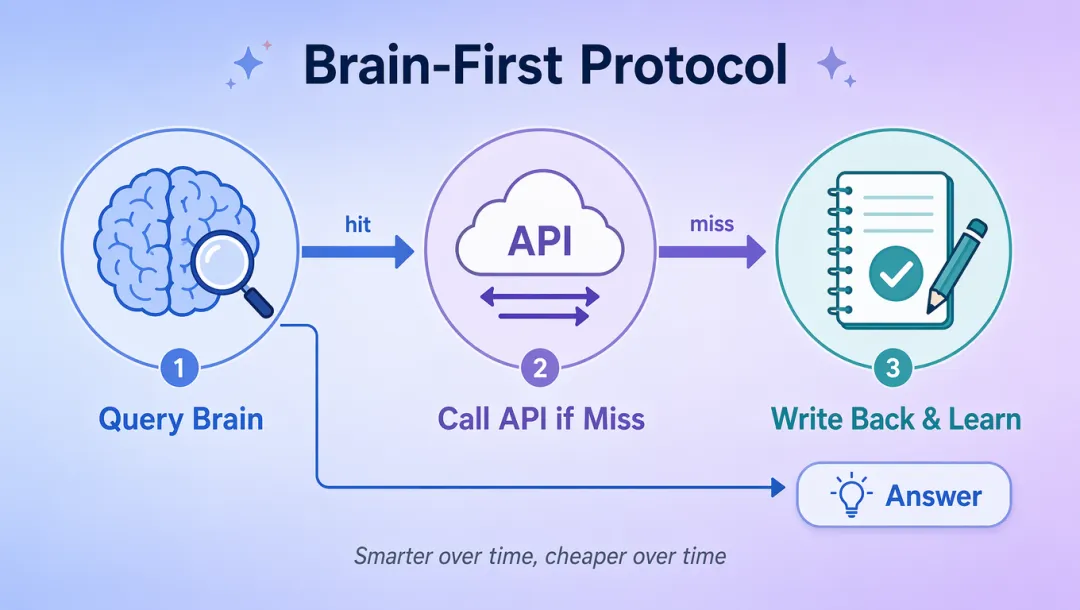
它的核心设计理念叫「脑优先」。就是收到问题之后,先查本地大脑。本地有就直接回答,没有再去调外部API,得到答案之后写回大脑。下次再问,直接命中。越用越聪明,越用越省钱。
📂 本地知识库结构
gbrain 的做法是:你在本地有一个知识库,目录结构长这样:
~/brain/ 📂 people/ 👤 人物 📂 companies/ 🏢 公司 📂 concepts/ 💡 概念 📂 deals/ 📋 交易/项目 📂 meetings/ 📅 会议记录 📂 ideas/ 💭 想法 📂 projects/ 🗂️ 项目 📂 media/ 🐦 X推文/文章/播客/视频每个实体都是一个 Markdown 文件,里面是这个实体的一切信息:背景、时间线、和其他实体之间的关系。
🔄 Brain-First Lookup 协议
当 AI 收到你的问题,它执行一套叫 Brain-First Lookup 的协议:
① 搜索相关实体② 混合向量检索,找到最相关的记忆③ 读取实体完整页面④ 检查反向链接(谁提到过这个实体?)⑤ 带着上下文回答整个过程对用户透明。AI 不会告诉你”我查了一下记忆”——它只是回答得更准了。
像一个真正的同事,而不是一个每次见面都要你重新自我介绍的陌生人。
💡 真实使用场景
说几个我自己用 gbrain 的场景,你感受一下:
👤 场景一:跟踪一个创始人
我把我关注的几个 AI 创业公司创始人加入 brain。gbrain 自动追踪:他们什么时候发过推、接受了什么采访、加入了什么新公司。
如果不用 gbrain,这条信息大概淹没在我几千条浏览记录里,永远找不回来。
📊 场景二:会议记录不是用来”记录”的
gbrain 的会议记录不只是存档——因为每次会议都会引用之前的人物和项目,gbrain 自动在这些实体之间建立链接。
这才是记忆该有的样子:不是一条一条孤立的信息,而是一个不断生长的知识图谱 🌐
请在微信客户端打开
🔬 为什么是现在
你可能会问:记忆这件事,这么简单,为什么现在才有人认真做?
原因是——技术终于成熟了。
① 向量数据库成本大幅下降 本地运行的 PGLite 已经能做到零配置、秒启动,不需要额外部署云服务。
② LLM Agent 爆发 “让 AI 自主管理记忆”变成了一个真实的工程需求。
③ Markdown 被证明是 AI 友好的格式 既适合人类读写,也适合 AI 解析。
三者叠加,gbrain 这样的工具才有可能出现。
还有一个更本质的原因:
🤯 当 AI 能做的事越来越多,记忆就变得越来越值钱。
你能让 AI 写代码、画图、写文章——但如果你每次都要重新教它背景,它永远只是一个响应速度快的搜索引擎,而不是一个真正懂你的助手。
记忆,是 AI 从”工具”变成”伙伴”的关键一步。
⚖️ gbrain 不是另一个 Notion
说清楚一件事:gbrain 不是另一个 Notion,也不是 Obsidian 的 AI 版本。
Notion 和 Obsidian 是给人用的 📝 它们的核心用户是你,你需要主动去整理、归档、标签化。
gbrain 的核心用户是 AI Agent 🤖 人是配角,负责提供原材料;AI 是主角,负责读写、更新、维护这个记忆库。
所以它的很多设计决策看起来很”奇怪”:
为什么用 Markdown 而不是数据库? 为什么不用标签系统? 为什么强调”环境式自动丰富”而不是手动整理?
因为 gbrain 想解决的不是 “我找不到那个文件” 的问题,而是:
“AI 在回答我问题的时候,根本不知道我之前说过什么” 的问题。
✨怎么用?
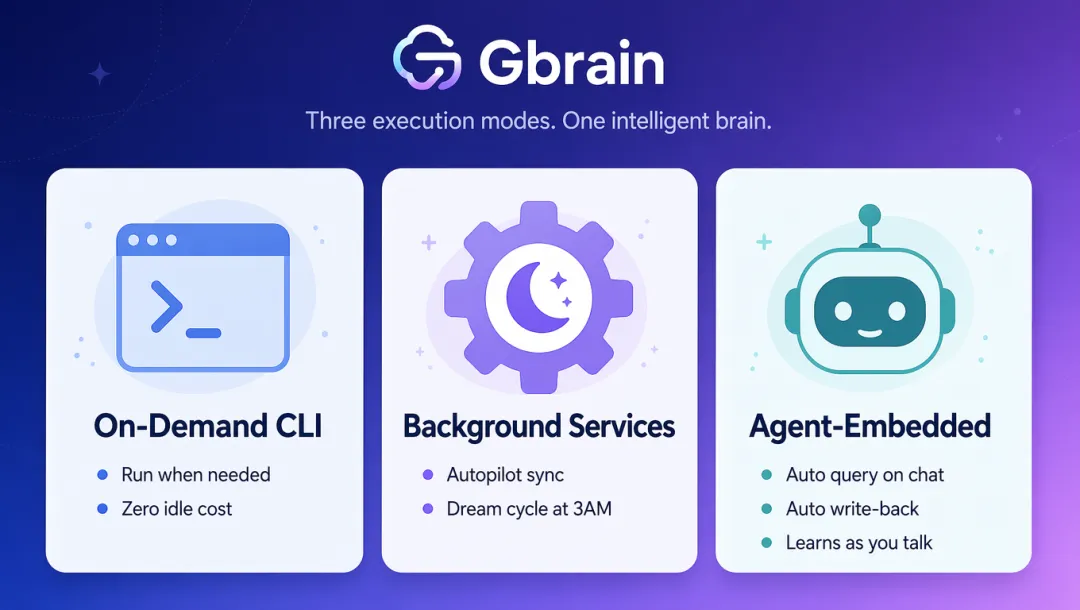
装好之后怎么用,有三种方式。
第一种是按需执行。就是你需要的时候跑一下命令,跑完就退。想搜个东西跑gbrain search,想导一批文件跑gbrain import。用的时候才叫它,不用的时候它不占资源。
第二种是后台常驻。有autopilot模式,装好了就在后台一直跑,自动同步文件、刷新索引、提取链接。还有一个「梦境维护」,每天凌晨自动跑一轮,修复引用、合并碎片信息、整理跨会话的记忆。你在睡觉,你的知识库在变聪明。
第三种是Agent内嵌。这是最核心的玩法。你每次跟Agent聊天的时候,Agent自动查大脑再回答,有新信息自动写回去。你的Agent等于有了一块长期记忆,越聊越懂你。
三种模式不互斥,可以同时开。我目前把后两种都配好了。
这几类人会特别适合GBrain
第一类,投资人或者重度人脉管理者。你要记谁跟谁什么关系、哪家公司什么情况、上次聊了什么。GBrain的知识图谱自动连线功能就是为你设计的。
第二类,独立研究者和写作者。你每天要读大量资料、做大量笔记、在多个主题之间来回跳。GBrain能让你的跨会话知识积累起来,不会读了一堆等于白读。
第三类,Obsidian重度用户。如果你已经在用Markdown管理知识库,GBrain可以直接对接你的笔记目录。相当于给你的笔记库加了一层AI检索和知识图谱能力。
第四类,AI Agent开发者。你在给自己或者客户开发Agent,需要让它有持久记忆。GBrain提供了一整套开箱即用的基础设施,不用自己造轮子。
第五类,单纯好奇的极客。就想玩玩新鲜东西,折腾一下自己的AI工具链。30分钟装一个,体验一下顶级VC怎么管知识的,也挺有意思的。
gbrain 想做的是:
🧠 给 AI 一个持久的大脑,让它记住你说过的每一句话、见过的每一个人、做过的每一个决定。
不是噱头。
是我见过最接近 “AI 同事” 这个概念的东西。
现在这个大脑你也能装。
把这个扔给你的龙虾助手:https://github.com/garrytan/gbrain
如果觉得不错,随手点个赞、在看、转发三连
纯属扯虾,如有雷同,我先瑞思拜!
OpenClaw Hermes Codex等用户必看:一个软件搞定大模型切换,再也不用改配置文件了
强烈推荐资源帖:2000+ GPT Image 2提示词,够用到年底!
强烈推荐-skill大比拼-Evolver vs OpenSpace:谁才是AIAgent的”记忆大师”?
强烈推荐skill-gstack :从单一Agent到多角色协作,gstack如何重新定义AI辅助开发
强烈推荐skill-OpenSpace:龙虾(openclaw)装上自我进化引擎,从笨手笨脚到独当一面 🦞(适用各种虾,workbuddy,Qclaw,JVSclaw等)