 夜雨聆风
夜雨聆风





【AI研究院】是AI重构软件?还是软件为AI重构?
今天做了一天系统加固工作:昨天为了加入「事实核查」模块,在平衡本地模型和Gemini的过程中把Gemini当天rate limit打爆了,然后引起了一系列连锁反应:产出开始下降。
今天就一边控制流量运行,一边开始修bug及加固工作。
同时修复了前台及后台的许多问题,不过在这个过程中,人也参与了很多工作。
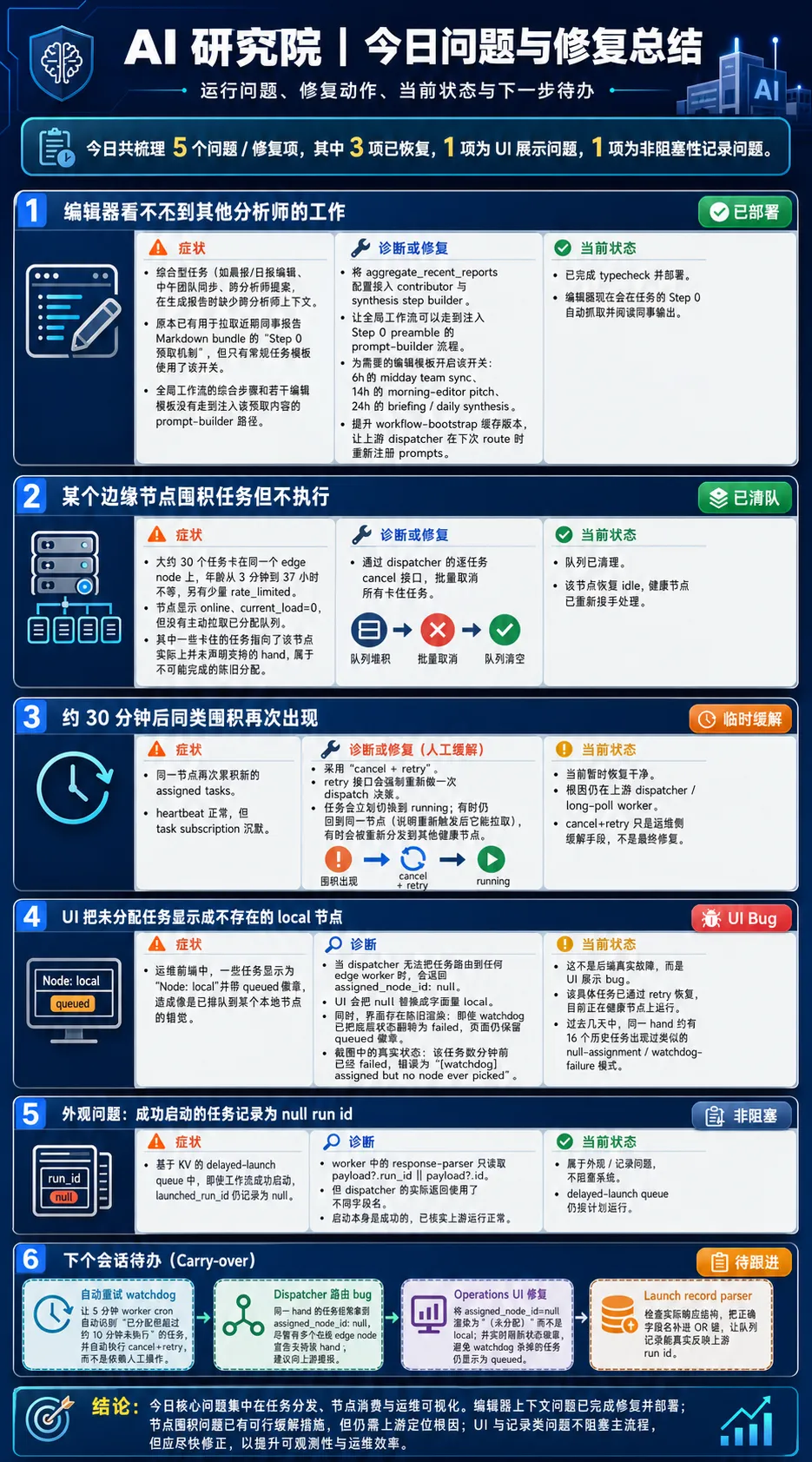
过程中涉及到的问题真的绝大部分都与模型本身无关,但是模型的很多问题发现和解决方案需要我不断进行判断和确认,其实,光是上面两张图里的内容就可以很清晰的展现出涉及到的众多技术细节,感谢自己平时喜欢不断找方案和看文档的习惯。
有些问题,无论有没有LLM,都可能会出现,但是更多问题是LLM时代新出现的。
我以前一直认为,AI重构软件行业,现在看来,这个观点是错误的,而是所有软件都必须围绕AI进行重构:当每一个软件的核心是看起来“无所不能,但稳定性不足”的AI时,不仅仅是工作流重构的问题,更是系统的技术重心也产生了明显的偏移:业务本身的技术重要性大幅降低,系统的技术重要性大幅提升,更要命的是,这种系统必须又是跟高度抽象的业务有很高的匹配度。
一直在讨论的关于人和SaaS的问题或许也更清楚了:
关于人,现在普遍会用taste这个词,如今可以具象为同时在业务与技术层面进行高度抽象和重组的能力,这不是简单的跨界,而是人本身就必须在两个领域同时具备非常丰厚的积累;
关于SaaS?模型在几年内可以再造全新的数据库、中间件、各种数据分析模型组件呢?
也许一个超级时代才展开,不是AI重构软件,而是所有的软件都要为AI重构。背后更大的时代强音或许是:不再是软件服务于业务,而是软件就是业务本身了。
而模型本身,也许只占10%都不到的工作量。
将今天的两份vibe日志交给我的视频生产应用,改一下画风,做成podcast形式,一次生成的,形式有点意思,内容还需要好好调整,有精力再去修吧。所以,尽管很抽象,就当增加点气氛吧,vibe到底。
后面还有更繁重的优化任务:数据库性能,二十几年的老OCP要下场了,在不增加成本的前提下,帮AI理清楚它一塌糊涂的数据读写操作。